 夜雨聆风
夜雨聆风凌晨两点,急诊室的灯还亮着。29岁的她刚刚在心脏骤停后被抢救回来。没有冠心病,没有明显结构性心脏病史,唯一的“异常”,只是几个小时前喝下的一罐红牛饮料。医生翻看病历时愣住了:这已经不是第一例。
当“提神续命”的能量饮料,开始出现在心脏骤停(SCA)幸存者的病史里,我们或许需要重新审视这个被年轻人高度日常化的消费选择。一项来自Mayo Clinic的研究发现,在一组144例心脏骤停幸存者中,有5%的事件发生在饮用能量饮料之后的时间窗口内,且多数患者存在潜在遗传性心律失常背景。
问题来了,一罐看似普通的能量饮料,究竟是“无辜的旁观者”,还是在某些人群中,悄然按下致命心律失常的“启动键”?
今天我们要深度剖析的这篇文献,恰恰打破了这一迷思。这篇近期发表在心血管电生理领域顶级期刊《Heart Rhythm》(PMID: 38842964)上的重磅文章,第一作者和通讯作者团队来自鼎鼎大名的梅奥诊所(Mayo Clinic)。令人震惊的是,这项研究最终的阳性目标病例只有区区7例!
我们也借此学习:他们是如何凭借简单的描述性统计,将日常的临床发现转化为高分论文的?这篇文章的研究逻辑、统计学抉择以及结果呈现,对于广大亟需利用临床数据发表论文、申请国自然基金的中国临床医生来说,堪称一份教科书级别的“突围指南”。
一、 破题思路:从临床“直觉”到“基因-环境”交互假说
这篇文章的切入点极其精准且接地气:功能饮料(Energy drinks)与心脏骤停(SCA)的关联。
研究逻辑深剖:临床医生在急诊或心内科查房时,可能会偶尔注意到某些发生不明原因心脏性猝死的年轻患者,在发病前有喝功能饮料的习惯。大多数医生可能只会把这当作一个“轶事”记录在病程中,或者最多写一篇孤立的个案报道(Case Report)。
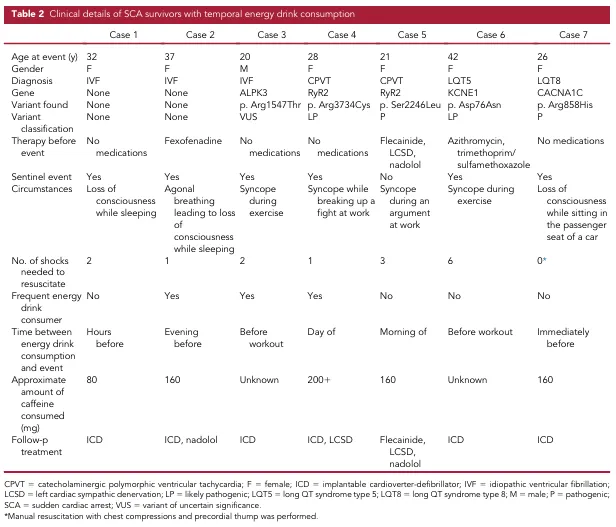
但梅奥的团队没有止步于此,他们展现了顶级的科研逻辑将偶然的临床现象,锚定到一个极具特异性的“强表型”队列中去验证。 他们没有在普通人群中漫无目的地寻找,而是直接调取了梅奥诊所“遗传性心律失常诊所”中144名心脏骤停幸存者的电子病历。在这个经过严格筛选、去除了大量混杂因素的特异性队列中,寻找“饮用功能饮料”这一特定环境暴露。最终,他们发现了7名(5%)患者的SCA发作与功能饮料消费存在明确的时间相关性。
这背后的核心科学逻辑是经典的“基因-环境交互作用(G × E Interaction)”:功能饮料中高浓度的咖啡因、牛磺酸等成分,在普通人身上可能只是引起心跳加速,但在携带有长QT综合征(LQTS)或儿茶酚胺敏感性多形性室性心动过速(CPVT)等遗传突变的患者身上,就成了致命的“电生理扳机”。
二、 统计方法的选择与结果解读:大道至简
中国医生在处理类似数据时,常犯的错误是“过度统计”。总觉得样本量有144人,是不是得做个多因素Logistic回归,算个P值,画个列线图(Nomogram)才显得高级?
本研究给出了完全相反的答案:当你的临床问题足够聚焦,且事件(SCA)具有极端的严重性时,最朴素的描述性统计(Descriptive Statistics)就是最有力的武器。
1. 统计方法的选择:本研究完全摒弃了复杂的推断性统计学模型。
连续变量: 仅使用均数±标准差(如患者发生SCA的平均年龄 29 ± 8岁)来刻画人群特征。
分类变量: 使用频数和百分比(如 7/144 [5%],其中女性占6例;LQTS 2例,CPVT 2例,特发性室颤 3例)。
为何如此选择? 因为在这个特定的临床场景下,试图用7个阳性病例去和剩下的137个病例做差异性检验(如卡方检验或Fisher精确检验)是缺乏统计学功效(Power)的,甚至可能得出假阴性的误导性结论。作者非常清楚,这是一项假设生成(Hypothesis-generating)的探索性研究,目的是拉响“早期预警(Early Warning)”,而非建立绝对的因果预测模型。
2. 结果的深度解读:作者在结果解读时展现了极高的严谨性。他们没有滥用“导致(Cause)”这个词,而是精确地使用了“时间相关性(Associated temporally)”。更精彩的是结果的纵向追踪(Longitudinal follow-up)数据展示:这7名患者中有6名需要除颤器(ICD)进行体外电击抢救,而在他们戒断功能饮料后,至今所有人均未再次发生SCA事件。这一个简单的“戒断后无事件(Event-free since)”的生存状态描述,比任何复杂的P值都更具有临床说服力。
三、 临床医生借鉴清单:如何盘活手头数据发高分/申基金?
不论你是心内科、肿瘤科、神经内科还是外科大夫,只要你在临床中察觉到了某种“特殊暴露”与“极端预后”的关联,都可以复刻这篇文献的成功路径。以下是一份为您量身定制的实操清单:
清单 1:数据库构建需求(数据的类别)
放弃大而全,追求小而精: 不要试图建立一个包含所有科室患者的“汪洋大海”数据库。你需要建立的是“特定结局幸存者/发病者”的强表型专病队列(例如:“35岁以下早发脑卒中队列”、“接受某靶向药后发生罕见超敏反应的肿瘤患者队列”)。
深度挖掘非结构化病历文本: 本文的成功依赖于详细的病史采集(喝了什么、什么时候喝的)。在收集数据时,必须要求团队仔细翻阅入院记录、主治医师查房记录等非结构化文本,将“特殊饮食、近期感冒、情绪剧烈波动、自行服用的非处方药/保健品”等环境变量提取为结构化的分类数据(Categorical Data)。
清单 2:科研逻辑与统计学避坑指南
寻找“扳机点”: 临床医生最擅长的是看病,你要把你的临床直觉转化为科研问题。比如:某种特定的网红减肥药(环境暴露)是否诱发了隐匿性炎症性肠病(IBD)患者的急性暴发(遗传/免疫易感基础)?
拒绝统计学滥用: 如果你的发现类似于本文的“罕见触发因素”,请大胆使用描述性统计。重点把图表(Figure)做精美,清晰列出患者的人口学特征(Age/Sex)、既往病史(Comorbidities)、暴露剂量(Dose/Frequency)和急救预后。将精力花在**确保数据的真实性和表型的准确性(如是否有基因测序结果佐证)**上,而不是花在套用复杂的数学模型上。
清单 3:基金申请(国自然)的绝佳切入点
这类利用描述性临床数据发表的优质论文,是申请国家自然科学基金(NSFC)面上项目或青年项目的最完美前期基础(Preliminary Data)。
撰写逻辑: 在立项依据中,你可以这样写:“我们在前期的临床单中心队列研究中(已发表于XX期刊),首次观察到A物质暴露会显著触发B疾病的急性发作(临床现象)。然而,其背后的分子机制尚不明确。因此,本项目拟利用XX小鼠模型和XX细胞系,深入探讨A物质如何通过干扰XX信号通路/离子通道,诱发靶器官衰竭……”
优势: 这种“源于临床真实发现 -> 提出机制假说 -> 基础实验验证”的转化医学(Translational Medicine)闭环,正是目前国自然医学科学部最青睐的本子类型。
编者按:
高分文章并不总是由庞大的样本量和晦涩的代码堆砌而成的。敏锐的临床洞察力、严谨的队列限定,再加上诚实且恰到好处的描述性统计,同样可以敲开顶级期刊的大门。希望这篇拆解能为你接下来的临床数据挖掘和论文写作带来全新的启发!

 |  |
 |  |
 | |
 |  |
(点击👆图片,进入自己感兴趣的专辑。或点击“资源”,浏览本公众号所有资源)
