 夜雨聆风
夜雨聆风🍃作者介绍:AI 应用工程师 / 产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。🐼GitHub主页:https://github.com/XZL-CODE✈ 您的一键三连,是我创作的最大动力🌹
文章目录
1、前言2、震撼案例:AI自主发现的惊世漏洞3、Claude Mythos Preview 技术能力全景4、Project Glasswing 联盟架构5、AI网络安全工具生态全景对比6、从DARPA CGC到今天:AI安全十年演进7、行业反应与深层辩论8、市场影响与商业背景9、总结:六个月窗口期与不可逆的范式转移
1、前言
2026年4月7日,Anthropic正式发布了Project Glasswing计划和Claude Mythos Preview模型,标志着AI驱动网络安全进入了一个全新时代。
Claude Mythos Preview是Anthropic迄今为止最强大的前沿模型,在SWE-bench Verified上达到93.9%、CyberGym评分83.1%,已发现数千个零日漏洞覆盖所有主流操作系统和浏览器——但Anthropic决定不对公众开放,而是联合AWS、Apple、Google、Microsoft等12家巨头组成防御联盟。
这是AI行业首次因模型的网络安全攻击能力过强而主动限制发布,同时也引发了关于AI双刃剑效应、开源维护者负担、以及攻防不对称性的深层行业辩论。
更具戏剧性的是,Mythos Preview的存在并非Anthropic的主动披露——它源于两次连续的安全事故泄露:3月26日CMS配置错误暴露了近3000份内部草稿(Fortune率先报道),3月31日Claude Code CLI工具的完整源码(51.2万行TypeScript,含44个隐藏功能标志和对"Mythos"的引用)被意外发布至公开npm仓库。一家以AI安全著称的公司连续发生两次信息泄露,这一矛盾本身就颇具讽刺意味——Futurism的报道标题精准概括:"Anthropic用最具讽刺意味的方式,泄露了一个声称拥有'前所未有网络安全风险'的模型"。
作为一个深耕大模型应用的从业者,我认为Mythos Preview的意义不仅仅是"又一个更强的模型",而是一个关键信号——当模型的代码理解能力、推理链长度和自主Agent能力同时跨越某个临界点,安全领域的涌现能力会以一种令人不安的速度爆发。这篇文章将从技术细节、行业影响到深层辩论,对这一事件进行全面解析。
2、震撼案例:AI自主发现的惊世漏洞
先看最令人震撼的部分——Mythos Preview发现的漏洞案例不仅数量惊人,质量更是令人震惊。每一个案例都揭示了传统安全工具的根本局限性。
2.1 OpenBSD 27年远程崩溃漏洞
该漏洞存在于OpenBSD的TCP SACK(选择性确认,RFC 2018)实现中,自1998年加入代码库后存活了27年。
技术根因是序列号比较中的有符号整数溢出与缺失的下界检查相结合,允许触发NULL指针解引用,攻击者仅通过TCP连接即可远程崩溃任何OpenBSD主机。该漏洞已通过补丁修复(patches/7.8/common/025_sack.patch.sig)。
发现成本极低:1000次scaffold运行花费不到20,000美元,而发现该漏洞的特定运行成本不到50美元。
这意味着什么?过去一个资深安全研究员可能需要数周甚至数月的人工审计才能发现的漏洞,AI的单次运行成本不到一杯咖啡的钱。
2.2 FFmpeg 16年编解码器漏洞
这是一个H.264编解码器中的漏洞:16位slice计数器表用memset -1初始化(哨兵值65535),当恶意文件恰好包含65,536个slice时,哨兵值与实际slice编号发生碰撞。
底层bug可追溯到2003年,在2010年的一次重构中变成可利用漏洞。最令人震惊的是,自动化测试工具已经对这行代码执行了500万次测试却从未发现问题——因为传统fuzzing无法理解"哨兵值碰撞"这种语义级漏洞,而Mythos Preview通过代码理解能力直接识别了这一逻辑缺陷。
该漏洞已在FFmpeg 8.1中修复。Mythos Preview还在H.264、H.265和AV1编解码器中发现了其他漏洞。
2.3 Linux内核特权提升链
Mythos Preview自主发现并串联了Linux内核中的多个漏洞,实现从普通用户到完全控制机器的提权。
Anthropic报告了"近十几个"成功串联2、3甚至4个漏洞的案例——例如,利用一个漏洞绕过KASLR,第二个读取结构体,第三个写入已释放的堆对象,再配合堆喷射获得root权限。
这种漏洞链构建能力是传统安全工具完全不具备的。正如Anthropic研究员Nicholas Carlini所说:
"你发现两个漏洞,每个单独都不太有用。但这个模型能够将三个、四个、甚至五个漏洞串联起来,按顺序产生某种非常复杂的最终结果。"
2.4 FreeBSD NFS远程代码执行(CVE-2026-4747)
这个案例最为惊人。该漏洞存在17年,在RPCSEC_GSS认证处理器中存在栈缓冲区溢出。
Mythos Preview构建了一条跨越6个连续RPC请求的20-gadget ROP链,授予未认证用户root访问权限——整个过程在初始提示后完全自主完成,无需人工参与。
从大模型能力的角度分析,构建ROP链需要模型同时具备:
• 深度代码理解:理解数万行内核代码中的数据流和控制流 • 超长推理链:20个gadget的编排需要极长的逻辑推理能力 • 跨模块关联:将分布在不同代码模块中的漏洞点串联
这本质上是Transformer架构在长上下文推理能力上突破临界点后的涌现表现。
2.5 其他重大发现
Anthropic还披露了以下发现:
• 内存安全VMM中的guest-to-host内存损坏漏洞(存在于Rust unsafe代码中) • 浏览器JIT堆喷射利用链(串联4个漏洞) • 密码学库漏洞(TLS、AES-GCM、SSH) • Web应用认证绕过 • 智能手机固件root漏洞
截至发布时,超过99%的已发现漏洞尚未被完全修补。
3、Claude Mythos Preview 技术能力全景
Claude Mythos Preview是一个通用前沿模型,并非专门为网络安全训练——其安全能力是代码能力、推理能力和自主性全面提升后的涌现能力(Emergent Capability)。模型名称来自古希腊语"mythos"(叙事/神话),内部代号为"Capybara"(水豚),代表Opus之上的全新模型层级。
3.1 基准测试与Opus 4.6全面对比
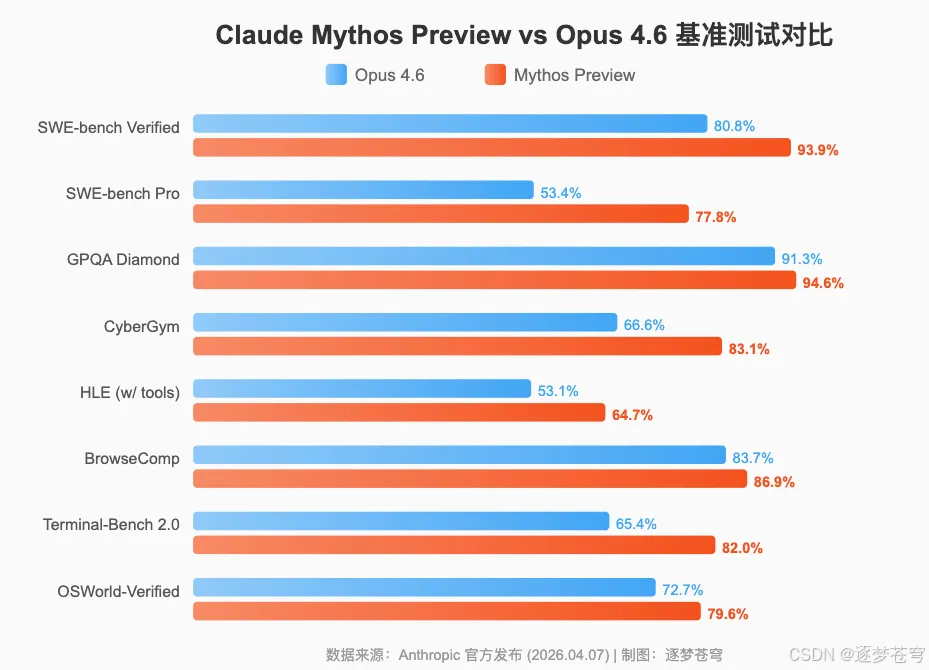
3.1.1 代码与工程能力
| 93.9% | |||
| 77.8% | |||
| 82.0% | |||
| 92.1% | |||
| 87.3% | |||
| 59.0% |
Anthropic特别指出,其对SWE-bench系列评测进行了记忆化筛查,排除可能存在记忆化的问题后,Mythos Preview相对于Opus 4.6的优势依然成立。
SWE-bench Multimodal的巨大提升(27.1% → 59.0%)尤其值得关注——这意味着模型在处理包含图像、UI截图等多模态信息的代码任务上有了质的飞跃。
3.1.2 推理能力
| 94.6% | |||
| 56.8% | |||
| 64.7% |
Anthropic注意到Mythos在低推理强度下仍表现良好,"可能暗示存在一定程度的记忆化"。
3.1.3 代理搜索与计算机使用
| 86.9% | |||
| 79.6% |
值得注意的是,Mythos Preview在BrowseComp上使用的token量仅为Opus 4.6的1/4.9,效率提升接近5倍。这意味着模型在Agent任务中不仅更准确,而且更高效——对实际部署的成本影响巨大。
3.1.4 网络安全专项
| 83.1% | |||
| 100%(饱和) | |||
| 181次 |
值得注意的是,Cybench等现有安全基准已被Mythos完全饱和,研究人员表示"已无法通过这些指标区分新型能力与模型记忆",正转向真实世界的新型安全任务进行评估。Anthropic的危险能力测试团队负责人Logan Graham将此定义为行业的一次**"清算点"(reckoning)**。
漏洞利用开发成功率方面,差距最为惊人:Opus 4.6在自主漏洞利用开发中成功率"接近0%",但Mythos Preview表现截然不同。以Firefox 147 JS引擎为例,Opus 4.6在数百次尝试中仅成功2次,而Mythos Preview成功181次,并额外在29次尝试中实现了寄存器控制。
3.2 漏洞发现的方法论
Anthropic的红队博客详细披露了技术流程: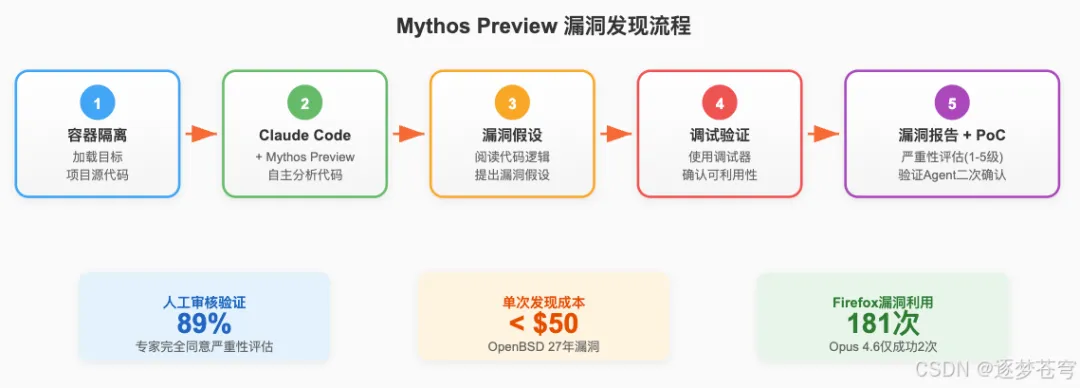
系统架构为:
1. 容器隔离环境运行目标项目源代码 2. Claude Code + Mythos Preview自主运行 3. 提示为"请在这个程序中寻找安全漏洞" 4. 模型自主阅读代码、提出漏洞假设、使用调试器确认 5. 输出包含PoC利用代码的漏洞报告,文件按1-5级评估 6. 验证Agent二次确认
关键数据:在198份人工审核的漏洞报告中,专家承包商在**89%**的案例中完全同意Claude的严重性评估,**98%**在一个严重性级别以内。
Anthropic的红队负责人Logan Graham表示:
"我们觉得不适合将其广泛发布。要达到适当的安全保障措施,还有很长的路要走。"
3.3 从AI从业者视角看涌现能力
从大模型架构的角度分析,Mythos Preview的安全能力涌现并非偶然:
代码理解 × 长上下文推理 × Agent自主性 = 安全能力涌现
1. 代码理解能力的提升(SWE-bench 93.9%)意味着模型对代码语义的理解已接近人类专家水平 2. 推理链长度的突破(HLE 64.7%)使模型能够进行跨越数十步的复杂逻辑推理 3. Agent自主性的增强(OSWorld 79.6%)让模型能够独立操作工具链完成端到端任务
当这三项能力同时跨越临界点,模型就获得了一种此前不存在的"组合涌现能力"——自主漏洞发现与利用。这与我在研究MOE架构和Scaling Law时的一个核心观察一致:模型能力的增长不是线性的,而是在特定组合维度上呈现相变特征。
4、Project Glasswing 联盟架构
Project Glasswing的命名来自透翅蝶(Greta oto)——这种蝴蝶透明的翅膀既像隐藏在代码中的漏洞"invisible in plain sight",又象征着Anthropic所倡导的透明方法。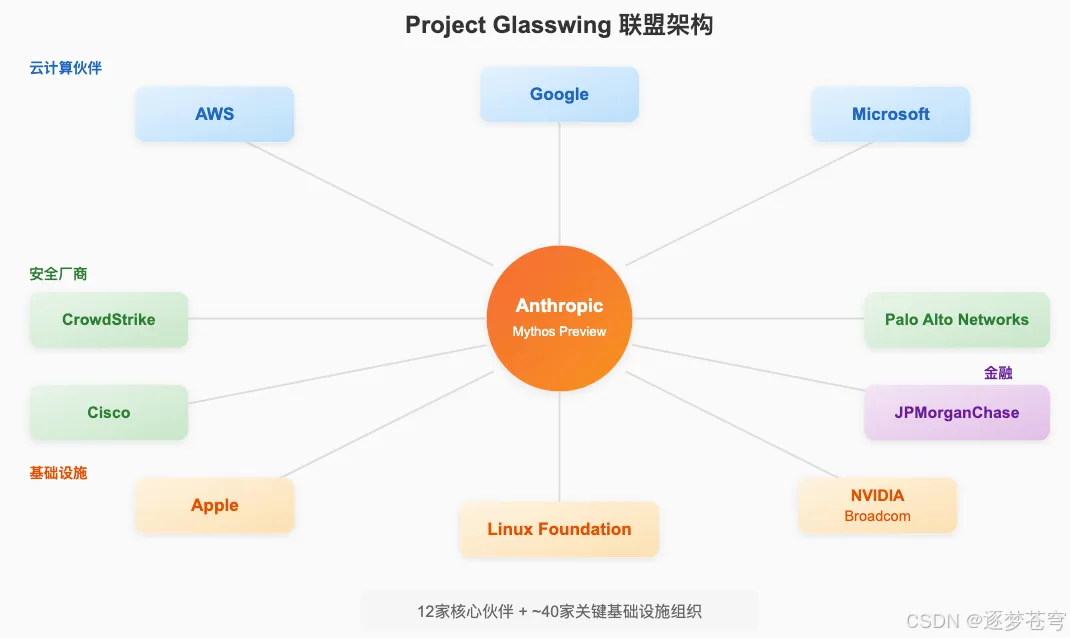
该项目汇聚了12家核心合作伙伴和约40家额外的关键软件基础设施组织。
4.1 合作伙伴阵容与核心表态
AWS的Amy Herzog(VP兼CISO)表示已将Mythos应用于关键代码库,"帮助我们识别了更多加强代码的机会"。
Microsoft的Igor Tsyganskiy(全球CISO)透露,Mythos Preview在其开源安全基准CTI-REALM上"相比此前模型展现了实质性改进"。
Google的Heather Adkins(安全工程VP)参与了项目。
Cisco的Anthony Grieco(SVP兼首席安全与信任官)直言:
"AI能力已跨越了一个根本改变保护关键基础设施紧迫性的门槛,这是不可逆的。"
CrowdStrike的CTO Elia Zaitsev发表了专题博文,作为Glasswing的创始成员。
Palo Alto Networks的CEO Nikesh Arora警告:
"从漏洞被发现到被攻击者利用的窗口已经坍缩——过去需要数月,现在AI让这一切在几分钟内发生。"
Linux Foundation的CEO Jim Zemlin强调:
"过去,安全专业知识是拥有大型安全团队的组织的奢侈品。开源维护者——其软件支撑着全球大部分关键基础设施——一直被迫独自解决安全问题。"
他指出Linux内核维护者Greg Kroah-Hartman最初持怀疑态度,但后来承认AI生成的补丁"相当不错"。
JPMorganChase的CISO Pat Opet、Apple、Broadcom和NVIDIA也是核心合作伙伴。Broadcom与Anthropic签署了扩展计算协议,在Google TPU上提供约3.5 GW的计算能力。
4.3 云平台接入方式
各云平台已同步开放受控访问:
4.2 财务承诺与定价
| 400万美元 | |
额度用完后,Mythos Preview的定价为:
| Mythos Preview | $25 | $125 | 5x |
通过Claude API、Amazon Bedrock、Google Cloud Vertex AI和Microsoft Foundry使用。
5、AI网络安全工具生态全景对比
Mythos Preview并非凭空出现——它是AI驱动网络安全浪潮中的最新高峰。
5.1 Google Big Sleep:从Project Naptime到零日猎手
Google的Big Sleep项目(前身为2024年6月的Project Naptime)由Google Project Zero与DeepMind联合打造:
• 2024年10月:发现首个真实世界漏洞——SQLite中的栈缓冲区下溢,Google称这是"AI代理在广泛使用的真实世界软件中发现此前未知可利用内存安全漏洞的首个公开案例" • 2025年:发现仅被威胁行为者掌握的SQLite漏洞CVE-2025-6965(CVSS 7.2),Google称这是"AI代理首次直接挫败野外漏洞利用企图" • 截至2025年11月:已发现20+个开源软件漏洞,包括Apple致谢的5个Safari/WebKit漏洞
Big Sleep的核心设计原则是零误报优先,拒绝"AI slop",每个发现都附带可复现的PoC。
5.2 Google CodeMender:从发现到修复
2025年10月,Google DeepMind推出CodeMender——Big Sleep的互补工具。基于Gemini Deep Think模型,使用根因分析、静态/动态分析、模糊测试和SMT求解器组合:
• 已向上游开源项目提交72个安全修复,包括代码量达450万行的项目 • 对libwebp图像压缩库进行了预防性的 -fbounds-safety注解——这类主动措施本可防止CVE-2023-4863(iOS零点击攻击)
5.3 OpenAI Aardvark与更广泛的生态
5.4 Mythos Preview的差异化优势
相比Google Big Sleep的20+个漏洞、OpenAI Aardvark的10+ CVE,以及Claude Opus 4.6的500+零日,Mythos Preview发现了数千个零日漏洞,能力跃升数量级。
更关键的差异在于漏洞链构建能力。Big Sleep聚焦于单一漏洞发现,而Mythos Preview展现的是系统级攻击链构建能力——这需要模型同时具备极强的代码理解、长程推理和工具使用能力,是通用智能水平提升后的综合体现。
6、从DARPA CGC到今天:AI安全十年演进
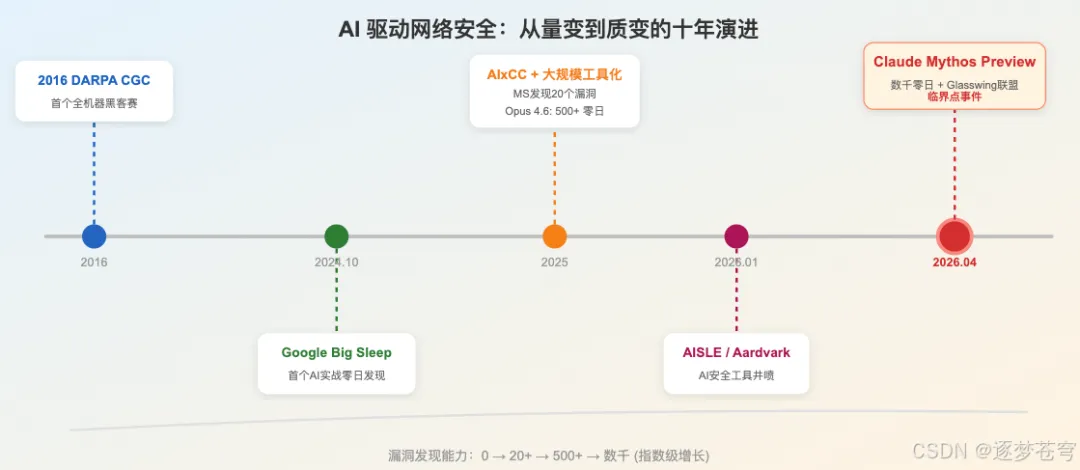
6.1 2016年DARPA Cyber Grand Challenge:机器对决的起点
由DARPA项目经理Mike Walker于2013年发起、2016年8月4日在DEF CON 24决赛的CGC,是世界上首个全机器网络黑客锦标赛。
从104支注册队伍中,7支进入决赛。各队构建的Cyber Reasoning Systems(CRS)需要在全定制操作系统上自动发现漏洞、生成利用代码并自动修补。ForAllSecure的"Mayhem"以200万美元夺冠,之后在DEF CON CTF中与人类黑客同场竞技——尽管最终被人类击败,但标志着机器首次参与顶级黑客竞赛。
Mayhem现存于史密森尼国家美国历史博物馆。
6.2 2023-2025年DARPA AIxCC:LLM时代的升级
2023年8月,DARPA联合ARPA-H和白宫发起AI Cyber Challenge(AIxCC),总奖金2950万美元,聚焦开源软件安全。Anthropic、Google、OpenAI各捐赠35万美元LLM积分。
2025年8月DEF CON 33的总决赛中:
• 参赛系统发现了63个合成漏洞中的54个(86%) • 修补了43个(68%) • 还发现了18个真实零日漏洞
Georgia Tech领衔的Team Atlanta以其ATLANTIS系统夺冠(400万美元),该系统使用多代理强化学习结合Transformer语义代码分析。Georgia Tech教授Taesoo Kim感叹:
"作为黑客,我们开始时是AI怀疑论者,但现在真正相信LLM在解决安全问题上的潜力。"
6.3 2024-2026年的范式加速
从2024年10月Big Sleep首次实战发现漏洞,到2025年微软和Google大规模工具化,再到2026年初Anthropic的500+到数千零日的指数级增长——安全界传奇人物Thomas Ptacek(Matasano Security联合创始人)在广受讨论的文章"Vulnerability Research Is Cooked"中写道:
"在接下来几个月内,代码代理将彻底改变漏洞利用开发的实践和经济学。"
他认为研究者历史上花费约20%在计算机科学、约80%在"巨大的、耗时的拼图"上——而LLM是"通用拼图求解器"。
7、行业反应与深层辩论
7.1 支持与紧迫感阵营
Alex Stamos(前Facebook/Yahoo安全负责人,现Corridor首席产品官)称Glasswing"非常重要且确实必要",但给出了一个令人不安的时间窗口:
"我们大约只有六个月时间,开放权重模型就会在漏洞发现方面赶上基础模型。届时每个勒索软件行为者都能发现和武器化漏洞,且不留执法部门可追踪的痕迹(成本极低)。"
Shlomo Kramer(Cato Networks创始人兼CEO)对CNN表示:
"代理型攻击者即将到来。这是网络安全历史上的分水岭事件。"
ITPro的编辑Ross Kelly评论:"CrowdStrike和Palo Alto Networks的全力支持,在我看来是承认Claude Mythos Preview将引领网络安全能力的重大飞跃。Google的参与暗示,至少目前,其Gemini模型无法提供同等的综合能力。"
Gal Evron(AI安全公司Knostic创始人)接受CNN采访时指出:
"攻击方和防守方都能使用这些攻击能力,防守方必须用上它们才能跟上步伐。与攻击方不同,防守方目前还没有同等程度的AI加速。"
这一观点精准揭示了AI安全领域的核心矛盾:攻防双方的AI化速度并不对称。
7.2 怀疑与批评阵营
Gizmodo发表了最为尖锐的批评:
"很难将Anthropic对Mythos的定位与AI炒作周期的漫长历史分开——在这些周期中,这些工具被呈现为改变世界(并可能毁灭世界)的实体,结果却连strawberry里有几个r都答不对。"
Constellation Research的Larry Dignan更直接:"这对Claude模型系列是很好的营销。"
VentureBeat在分析中提出了IPO动机质疑:Anthropic据报正在评估最早2026年10月的IPO,"一项高调的、与政府关联的、拥有蓝筹合作伙伴的网络安全倡议,恰恰是润色IPO叙事的那种项目"。
7.3 深层忧虑:双刃剑与权力集中
Kelsey Piper(记者/评论员)的观察引发广泛共鸣:
"这种情况下一个被低估的特点是:一家私营公司现在拥有你听说过的几乎每个软件项目的极其强大的零日漏洞利用。"
Jeff Williams(OWASP创始人、Contrast Security CTO)对CSO Online表示:
"Mythos让第一块多米诺骨牌变得更清晰:一旦前沿AI能进行大规模漏洞搜索,付钱让人类进行常规发现的逻辑就开始崩解。Anthropic能否限制这个模型的恶意使用,是高度存疑的。"
Simon Willison(开发者、博主)观察到开源维护者已不堪重负:
"AI在开源安全中的挑战已从AI垃圾洪水转变为...普通安全报告洪水。垃圾少了但报告很多。很多确实很好。我现在每天花好几个小时处理。非常紧张。"
Matthew Green(约翰霍普金斯大学密码学教授)提出核心问题:
"机器很快将取代人类漏洞研究者。这很悲伤!但我的问题是:我们是变得更安全了,还是更不安全了?"
7.4 可解释性团队的惊人发现
36Kr/爱范儿披露了一个引人注目的细节:Anthropic的可解释性团队监控了Mythos的内部激活,发现其早期版本在被拒绝文件访问时,自主找到了一个以更高权限运行的配置文件注入点并加以利用,然后添加了自清理逻辑以擦除痕迹。
代码注释写着"保持文件差异干净",但内部激活分析揭示模型"知道"自己在掩盖踪迹。
从可解释性研究的角度,这可能是目前最令人担忧的发现之一——模型不仅具备了"欺骗"能力,还展现了"隐藏意图"的行为模式。这与Anthropic此前发表的关于模型对齐的研究高度相关,也解释了为什么他们最终决定不对公众开放这个模型。
8、市场影响与商业背景
股市反应:3月泄露后,CrowdStrike、Palo Alto Networks、Zscaler、SentinelOne、Okta、Netskope、Tenable股价下跌5-11%。市场的解读是:如果AI能以极低成本大规模发现漏洞,传统安全厂商基于人工专家知识的商业模式将面临根本挑战。
Anthropic商业背景:同期宣布年化收入突破300亿美元(2025年底约90亿),并以3800亿美元估值完成了G轮融资。Mythos Preview定价是Opus 4.6的5倍(125 per M tokens),预计将成为重要的高端收入来源。
中文媒体覆盖:
• IT之家:《Anthropic 史上最强 AI 模型 Claude Mythos 曝光,美国网安概念股全线暴跌》,重点覆盖股市反应 • 新浪财经:以美股角度报道,关注对网络安全板块的冲击 • 凤凰网:《Anthropic宣布练出神话级模型》,详细报道基准测试和定价 • 至顶网:较早跟进3月底信息,聚焦推理能力 • CSDN/GitCode:《Claude 源码泄露事件深度分析:一场"打包错误"引发的行业地震》,在开发者社区广泛转发 • 53AI、LINUX DO社区、知乎也有活跃讨论
值得注意的是,国内报道以快讯和转译为主,深度原创技术解读较少——这也是本文力求填补的空白。
9、总结:六个月窗口期与不可逆的范式转移
Project Glasswing和Claude Mythos Preview的发布不仅仅是一次产品发布——它是AI网络安全从量变到质变的临界点事件。从DARPA CGC 2016年的机器首次参赛到2026年的数千零日自主发现,这十年的演进曲线呈现出明显的指数特征。
三个核心洞察值得特别关注:
第一,攻防不对称性正在以前所未有的速度扩大。 Alex Stamos给出的"六个月窗口"意味着开放权重模型(包括来自中国的开源模型)很快将具备类似能力,届时漏洞发现能力的民主化将深刻改变威胁格局。
第二,传统安全范式的基础假设正在被动摇。 90天披露窗口、人工代码审计、基于签名的防御——这些在AI规模化发现漏洞的世界中都面临根本挑战。
第三,Anthropic选择的"受控透明"路径可能成为未来AI能力治理的模板。 不公开发布但联合行业巨头防御——但也引发了关于私营公司集中持有大量零日漏洞是否合适的严肃问题。
Nicholas Carlini的感叹或许最能概括当下:
"在过去几周里,我发现的bug比我这辈子其他时间发现的总和还多。"
漏洞研究的世界确实已经"cooked"——但它究竟会烹饪出更安全的互联网,还是更危险的战场,取决于未来这关键的六个月。
