 夜雨聆风
夜雨聆风
如果你最近刷过 GitHub Trending,大概率见过一个名叫 MiroFish 的项目。2026 年 3 月 7 日登顶全球热榜第一,两周内斩获 25,000+ Star,背后还有盛大集团创始人陈天桥 3000 万人民币的闪电投资。
这个项目的口号是”简洁通用的群体智能引擎,预测万物”。听上去像画大饼?我们今天就开看看它的代码、架构、论文依赖和社区反馈,MiroFish 到底解决了什么新问题?对 AI Agent 开发者有什么参考价值?它真实的技术水平在哪?

◆ 来龙去脉:从 BettaFish 到 MiroFish,大四学生的10天作品
MiroFish 的作者郭航江(GitHub: 666ghj/BaiFu),是北京邮电大学(我的学弟)的大四学生。他用 10 天时间、通过 Claude Code 进行 Vibe Coding 完成了整个项目,随后获得盛大集团 3000 万人民币投资。
故事要从他的前作 BettaFish 说起。BettaFish 是一个多智能体舆情分析工具,曾在 2024 年底登顶 GitHub Trending,累计获得 37,700+ Star。BettaFish 分析的是”已经发生的事”——它爬取社交媒体讨论,用多个 Agent 协作输出舆情报告。而 MiroFish 的野心更大:不分析过去,而是模拟未来。
陈天桥注意到 BettaFish 后,邀请郭航江到盛大实习。看到 MiroFish 的演示视频后,24 小时内拍板投了 3000 万。用 36Kr 的话说:”BettaFish 的分析终点,变成了预测的起点。”
值得注意的技术背景:MiroFish 的代码库约 7.1 MB,截至目前有 219 次 commit、3 个 release(v0.1.0 到 v0.1.2)、核心贡献者仅 2 人。项目处于非常早期的原型阶段。盛大的参与不仅是资本注入——团队已与盛大旗下的 EverMind 团队和 EverMemOS 长期记忆项目产生了战略协同。
◆ 核心思想:不是”问大模型一个问题”,而是”造一个世界让它自己演化”
传统的 AI 预测路径很直觉——给 LLM 喂一段新闻,让它直接回答”接下来会怎样”。这本质上是一种单体推理,受限于模型的训练数据和上下文窗口。
MiroFish 走的是完全不同的路线:构建一个由数千个有独立人格、记忆和行为逻辑的 AI 智能体组成的虚拟社会,让它们在模拟的社交平台上自主互动,通过”群体涌现”(emergent behavior)产生预测结果。
你可以这样理解:传统方法是问一个超级聪明的人”你觉得会怎样”;MiroFish 是造了一个微型社会,里面有核科学家、媒体记者、政策制定者、普通市民,让他们在 Twitter 和 Reddit 风格的平台上发帖、评论、争吵、结盟——然后观察这个社会在特定刺激下如何演化。
从 Agent 开发者的视角看,这引入了一个很有趣的范式:从 single-agent reasoning 到 multi-agent simulation-as-prediction。
◆ 五阶段流水线:从一篇新闻到一个平行世界
MiroFish 的架构是一条五阶段的流水线(pipeline),将原始的真实世界文档转化为可交互的预测模拟。每个阶段对应独立的前端视图(Vue 3 + D3.js)和后端服务(Python/Flask),分工清晰。
阶段一:种子提取 — 从文档到知识图谱
用户上传”种子材料”,可以是新闻报道、政策文件、金融报告,甚至小说章节。OntologyGenerator 服务将文本发送给 LLM(默认使用阿里通义千问 Qwen-plus),提取实体和关系的本体结构。提取结果通过 GraphBuilderService 和 ZepEntityReader 存入 Zep Cloud 的 GraphRAG 知识图谱(基于 Zep 的 Graphiti 引擎,SDK v3.13.0)。
输出是一个 ontology.json 文件和一个完整的知识图谱,包含实体、属性、实体间关系。
这是 MiroFish 最独特的架构选择。 目前没有其他多智能体仿真框架能从任意真实文档自动构建仿真世界。Stanford 的 Generative Agents 需要手写人物传记;AgentSociety 用预置的城市数据集;OASIS 建模特定的社交平台;AgentTorch 用人口普查数据。MiroFish 用 GraphRAG 打通了”真实事件”到”虚拟世界”的自动化路径。
阶段二:智能体演化 — 自动生成有血有肉的 Agent 群体
SimulationManager 协调此阶段,委托 OasisProfileGenerator 和 SimulationConfigGenerator 完成工作。系统从知识图谱中提取实体,通过 LLM 调用生成详细的智能体人设。每个 OasisAgentProfile 包含:唯一 ID、人格描述、个人传记、人口统计特征、MBTI 性格类型、职业背景、风险偏好、行为模式、社交关系,以及独特的意识形态立场。
一个独立的”环境配置 Agent”(SimulationConfigGenerator)负责生成仿真参数——时间配置、行为规则、事件时间表——确保虚拟环境与种子材料的上下文吻合。
在一个实测案例中,一篇关于伊朗-美国关系的学术论文自动生成了 118 个独立智能体,包括伊朗核科学家、美国前国务卿、CNN 媒体人,以及数十个其他利益相关方。
这些人设的丰富度,直接决定了群体行为的”涌现”质量。
阶段三:双平台并行仿真 — 让 Agent 们”自由”活动
这是引擎的核心。SimulationRunner 以子进程方式启动run_parallel_simulation.py,通过 OASIS 框架(CAMEL-AI 的 Open Agent Social Interaction Simulations, v0.2.5)同时运行 Twitter 风格和 Reddit 风格两套社交模拟。
OASIS 支持最多 100 万智能体交互和 23 种社交行为——关注、发帖、评论、转发、引用、点赞等。推荐系统使用 TwHIN-BERT 进行内容排序,兼顾兴趣匹配和热度排名。
Agent 不走剧本。它们每一步都通过 LLM 调用进行推理,参考自己的人设、不断变化的社交上下文和累积的记忆。系统在每轮动态更新时序记忆。行为日志写入 actions.jsonl 文件,持久化到每个平台独立的 SQLite 数据库中。
中文开发者社区用一句很传神的话描述这个过程:“智能体之间会八卦、会结盟、会对抗。这种’群体涌现’现象是传统单一 LLM 无法模拟的。”
阶段四:报告生成 — ReACT 推理 + 工具增强
ReportAgent 实现了 ReACT(推理 + 行动)循环。它先生成报告大纲(report_outline.json),然后逐章节调用 ZepToolsService 的工具链:insight_forge() 做深度分析,panorama_search() 做广域上下文搜索,quick_search() 做事实检索,interview_agents() 通过 IPC 直接”采访”仿真中的智能体。最终输出结构化的 report.md,包含预测时间线、情绪趋势和情景分析。
阶段五:变量注入 — “上帝视角”的交互沙盘
用户以 “上帝视角” 与模拟世界互动。你可以跟任何一个 Agent 对话,了解它的决策逻辑;也可以和 ReportAgent 聊天做追问分析;最关键的是——在仿真运行中途注入新变量(”如果央行突然宣布降息会怎样?”),观察群体如何反应。
这让系统从一次性预测工具,变成了带有时间线分叉的交互式策略沙盘。IPC 通信采用基于文件的协议(command.json / response.json)在 Flask 进程和仿真子进程之间传递指令。
◆ 技术栈一览
后端:Python 3.11 + Flask 3.0+,用 uv 做包管理。核心依赖包括 CAMEL-AI v0.2.78(Agent 编排)、camel-oasis v0.2.5(社交仿真)、Zep Cloud SDK v3.13.0(知识图谱持久化)、OpenAI SDK(兼容任何 OpenAI 格式的 API 端点)。
前端:Vue 3 SPA + Vite,用 D3.js v7 做力导向图可视化,Vue Router 做分步导航,Axios 做 API 通信。
代码组织采用服务层模式(Service Layer Pattern),每个类单一职责:ProjectManager 管 CRUD、SimulationManager 管编排、SimulationRunner 管进程生命周期、ReportAgent 管分析、ZepToolsService 管图谱查询。异步任务通过 TaskManager 用内存字典追踪状态,前端轮询获取更新。
LLM 配置灵活——任何兼容 OpenAI SDK 的端点都能用。推荐方案是通过 DashScope 接入阿里通义千问 Qwen-plus,性价比较高。部署支持本地开发(npm run dev 同时启动 Vite 和 Flask)和 Docker Compose 生产部署(Nginx 前端 + Python 后端,端口 3000 / 5001)。
◆ 横向对比:MiroFish 在多智能体仿真版图中的位置
MiroFish 的定位可以概括为“事件驱动的预测性仿真”,与同赛道的主要竞品形成了明确的差异化。
Stanford Generative Agents(2023):开山之作,25 个 Agent 住在一个小镇里自主生活。架构优雅但规模小、需要手工编写人物传记,目标是研究行为可信度,不做预测。
source:https://www.artisana.ai/articles/generative-agents-stanfords-groundbreaking-ai-study-simulates-authentic
AgentSociety(清华,2025):万级 Agent,用马斯洛需求层次和计划行为理论(TPB)来建模认知过程,基于真实城市数据。面向社会科学实验(比如模拟税收政策对不同收入阶层的影响),不做事件驱动的预测。
source:https://agentsociety.readthedocs.io/en/latest/
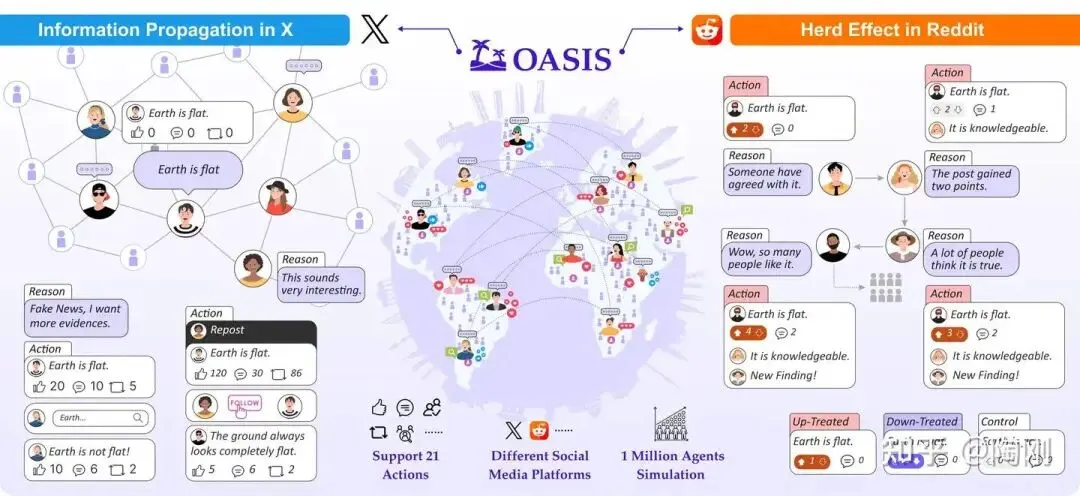
OASIS(CAMEL-AI,2024):百万级 Agent 的社交模拟平台,模拟 Twitter/Reddit 风格的社交动态。MiroFish 直接在 OASIS 之上构建,继承了它的社交行为引擎和推荐系统。OASIS 本身侧重理解社交媒体动态,不做预测。
AgentTorch(MIT,2024):最大规模的方案,支持 840 万 Agent,用”原型(archetype)”方法将相似人群聚类来降低 LLM 调用成本。面向人口级别的政策建模(如疫情传播模拟),但每个 Agent 的行为深度有限。
MiroFish 的三个核心差异化:
第一,自动世界构建。从任意真实文档通过 GraphRAG 自动构建仿真世界,这是独家能力。其他框架都需要预制数据集或手工编写环境。
第二,领域通用性。同一引擎换一篇输入文档,就能从地缘政治预测切换到金融市场分析、从舆情推演切换到文学续写。其他框架通常绑定特定领域。
第三,预测导向。其他框架的目标是”理解”或”复现”已知社会现象;MiroFish 明确以”预测接下来会发生什么”为设计目标。
核心取舍:MiroFish 在”千级” Agent 规模下运行,每个 Agent 都有独立 LLM 调用,远小于 OASIS 的百万级或 AgentTorch 的 840 万。它选择了每个 Agent 的行为深度和记忆持久性,牺牲了人口覆盖的规模优势。对于预测质量(需要个体精度)而非统计代表性(需要数量覆盖),这是合理的设计选择。
◆ 实测反馈与已知局限
已展示的 Demo
MiroFish 发布了两个标杆演示。
武汉大学舆情模拟:用 BettaFish 的输出报告作为种子,预测舆论走向。 红楼梦续写:将前 80 回文本作为种子输入,让 Agent 模拟后续故事发展,相关 B 站视频获得 21 万播放。
金融和政治新闻的预测场景在路线图中,但尚未发布。
真实测评
腾讯新闻”AI变革指南”做了一次实操测评:用 AI 编码 Agent 本地部署花了约 15 分钟,投喂伊朗-美国新闻后,15 轮仿真用了约 1 小时,报告生成又花了 20 分钟。部分 Agent 在模拟过程中输出重复内容。
测评结论坦率:”思路很好,有不少让人眼前一亮的亮点,但目前还非常初级,完全不具备落地能力。”
已知局限
作为 Agent 开发者,你需要知道以下限制:
仿真速度慢。15 轮要 1 小时,这不是”实时预测”,更像”批处理实验”。每个 Agent 每轮都要调 LLM API,成本线性增长。项目文档也提醒:”注意消耗较大,可先进行小于 40 轮的模拟尝试。”
没有预测验证。目前没有任何公开的基准测试将 MiroFish 的预测结果与实际历史结果进行对比。”预测万物”是愿景,但尚无数据证明预测准确率。
LLM 羊群效应。OASIS 的研究论文本身指出,LLM 驱动的 Agent 比真实人类更容易产生从众行为,导致模拟中的群体极化速度比现实更快。MiroFish 继承了这个问题。
工程成熟度。v0.1.2、2 个核心贡献者、仅在 macOS 上测试过。这是一个 10 天写出来的原型,不是生产系统。
◆ 社区生态与衍生项目
MiroFish 在中文技术社区引发了大量讨论:36Kr 做了投资故事的深度报道,CSDN 有多篇技术拆解和部署指南,知乎有详细的项目背景分析,B 站的官方 Demo 视频累计播放超过 25 万次。
第三方采用正在出现。Brian Roemmele 的”Zero-Human Company”已经开始集成 MiroFish 技术,并扩展到了 23 个 MiroFish 模拟实例,探索经济、治理和研究领域的应用。香港教育大学图书馆将其收录到 AI Discovery Zone 研究指南中。GitHub 上也已出现衍生 fork,比如 huamu668/mirofish 提供了 CLI 原生版本,内置金融、舆情和娱乐场景的工作流模板。
项目在 Discord、QQ 和 GitHub Discussions 上维持着活跃的社区交流。
◆ 对 Agent 开发者的实践启示
看完 MiroFish 的架构后,我认为对 AI Agent 开发者有三点值得深入思考的技术启示:
启示一:GraphRAG 作为 Agent 世界构建器。 MiroFish 用知识图谱自动从文档提取实体和关系、再转化为 Agent 人设和环境配置的管线,是一种可复用的设计模式。如果你在做任何需要”理解一个领域然后在其中部署 Agent”的项目——无论是客户支持、安全分析还是流程自动化——这个 GraphRAG → Agent Profile 的路线值得借鉴。
启示二:”仿真即推理”的范式。 传统 Agent 开发中,我们习惯了 ReACT 循环、RAG 检索、Tool-Use 这套工具箱。MiroFish 提出了一个不同的推理路径:不是让一个 Agent 反复推理,而是让一群 Agent 在一个结构化环境中交互,从群体行为中提取结论。这种”仿真即推理”(simulation-as-reasoning)的范式对特定问题类型(涉及多方博弈、信息不对称、群体动力学的场景)可能比单体推理更有效。
启示三:OASIS 作为 Agent 社交基础设施。 MiroFish 实际上是 OASIS + Zep + GraphRAG 的组合。CAMEL-AI 的 OASIS 框架本身是一个强大的多 Agent 社交仿真引擎,但知名度远不如 LangChain 或 CrewAI。如果你的项目需要模拟信息传播、舆论演化或社交网络动态,OASIS 值得直接评估——不一定非要通过 MiroFish。
◆ 结论:一个有洞察力的原型
MiroFish 在多智能体仿真赛道提出了一个新颖的组合:事件驱动、文档接地、预测导向。它的五阶段管线——从 GraphRAG 种子提取到双平台群体仿真再到交互式变量注入——架构连贯、技术选型合理,建立在经过验证的组件之上。3000 万盛大投资和两周 25K Star 说明市场对这个方向有强烈兴趣。
但 v0.1.2 的 MiroFish 还只是一个有洞察力的原型,不是一个生产系统。仿真速度、LLM 成本、缺乏预测验证、平台兼容性、团队规模——这些都诚实地反映了 10 天的开发周期。它的价值不在于今天能交付什么,而在于它为”如何将真实世界信息转化为交互式预测仿真”这个问题,提出了一套值得认真研究的设计模式。
项目地址:github.com/666ghj/MiroFish
来源:
https://www.toutiao.com/article/7617643217814684160/?log_from=83781eff0a27d_1773811667840
“开源大咖说”欢迎广大技术人员投稿,投稿邮箱:aliang@itdks.com
开源大咖说 | 关于版权
由“开源大咖说(ID:kaiyuandakashuo)”原创的文章,转载时请注明作者、出处及微信公众号。投稿、约稿、转载请加微信:ITDKS10(备注:投稿),茉莉小姐姐会及时与您联系!
感谢您对开源大咖说的热心支持!
相关推荐
推荐文章
