 夜雨聆风
夜雨聆风【导读】智谱刚刚开源了新一代旗舰模型GLM-5.1,主打「长周期Agent不掉线」。SWE-Bench Pro拿下58.4分登顶全球第一,力压GPT-5.4和Claude Opus 4.6。最狠的是,这个模型能连续自主运行8小时,跑完600多轮迭代、6000多次工具调用,性能还在往上涨。
「跑久变笨」,Agent时代最扎心的痛点
用过AI Agent写代码的人,大概都体验过这种抓狂场景:
刚开始,Agent表现惊艳,三下五除二搞定框架搭建。可一旦任务变复杂、对话轮次一多,它就开始「发呆」——翻来覆去用同一招,改了A坏了B,甚至把之前写好的代码搞崩。
你给它再多时间也没用。它已经「用完了所有招数」。
中文AI博主AIGCLINK把这个现象总结得很到位:
"之前的模型用完熟悉的招数后就会迅速停滞,给再多时间也没用。"
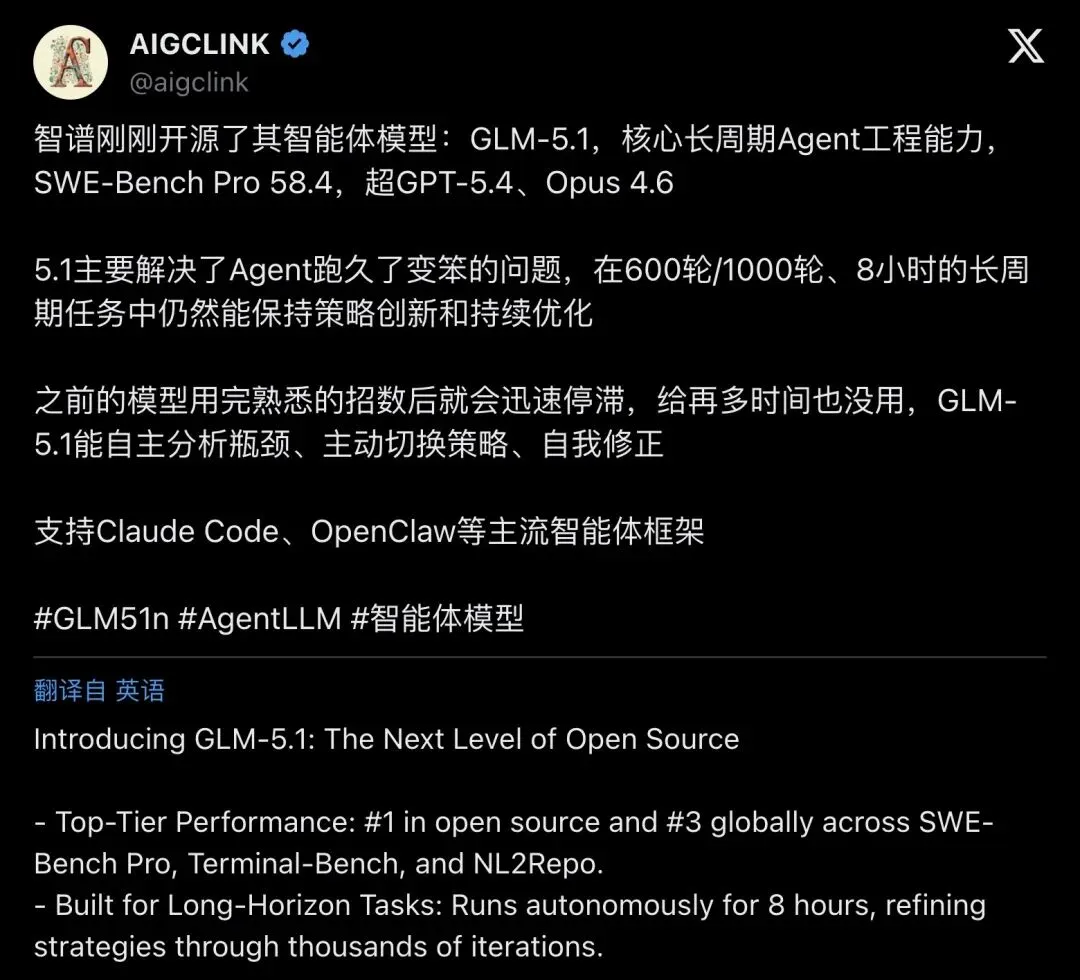

▲ AIGCLINK推文总结:GLM-5.1主打解决「Agent跑久变笨」问题(9.2K次查看)
这个问题在业内有个术语叫plateau(平台期)——模型在长任务中快速消耗已有策略后就陷入停滞,像一个只会三板斧的选手,招用完了就站在原地发愣。
智谱的官方博客直接把这个问题摆在了台面上:
"Previous models—including GLM-5—tend to exhaust their repertoire early: they apply familiar techniques for quick initial gains, then plateau. Giving them more time doesn't help."
「之前的模型——包括GLM-5——往往很快就用尽了它们的招数库:先用熟悉的技巧获得快速提升,然后就进入平台期。给再多时间也没用。」
这句话来自智谱自己的官方博客,连自家上一代产品都没放过。敢拿前代产品做反面教材,至少说明他们对这个问题是认真的。
SWE-Bench Pro 58.4,登顶全球第一
先看最硬的数据。
在当前最受关注的编码Agent评测SWE-Bench Pro上,GLM-5.1拿下了58.4分,直接登顶:
- GLM-5.1:58.4
(第一) GPT-5.4:57.7(第二) Claude Opus 4.6:57.3(第三) Qwen3.6-Plus:56.6 MiniMax M2.7:56.2
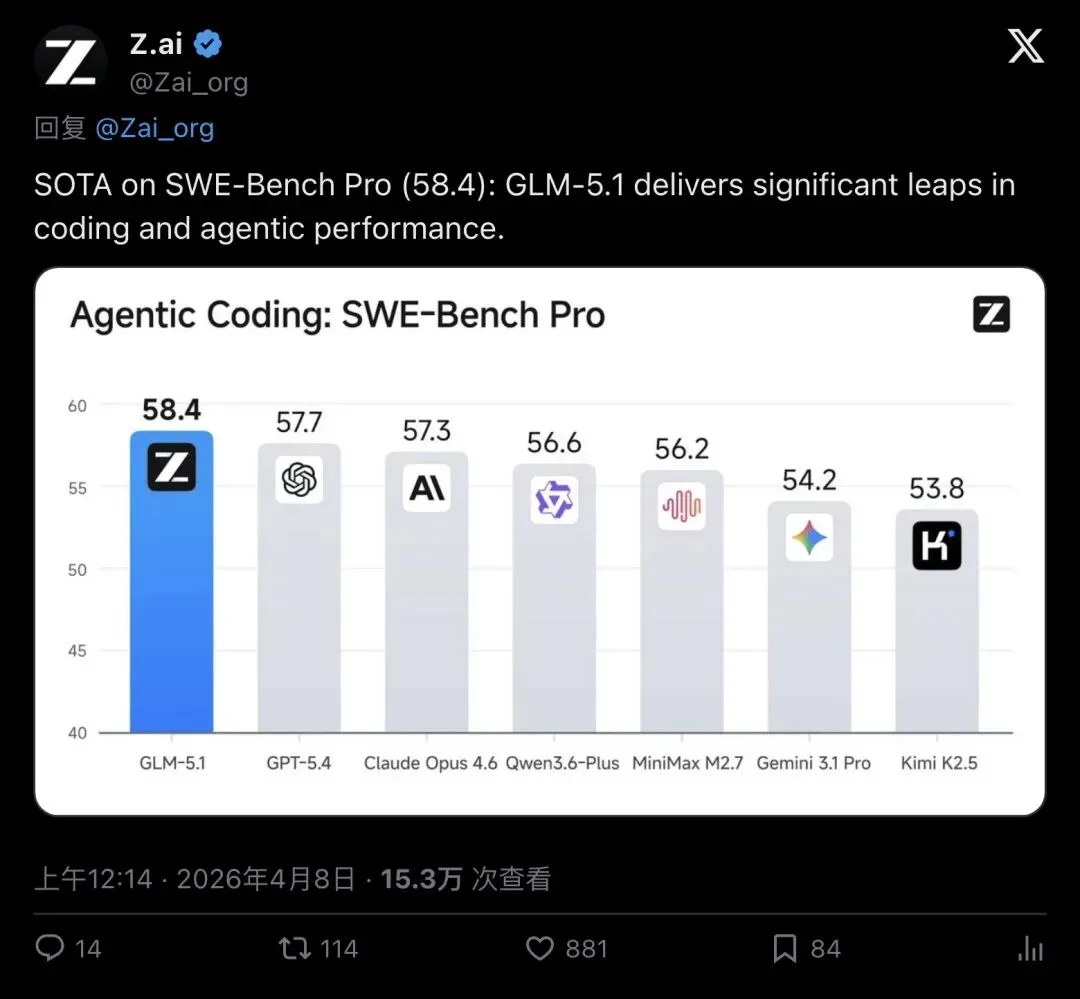
▲ Z.ai官方推文:GLM-5.1在SWE-Bench Pro上以58.4分登顶(15.3万次查看,881赞)
一个开源模型,在最权威的编码基准上超过了OpenAI和Anthropic的闭源旗舰。
这里要说清楚:58.4的领先幅度并不算大——只比GPT-5.4高了0.7分,比Opus 4.6高了1.1分。但在这个级别的竞争中,哪怕0.1分的差距背后都是海量的工程优化。
而且,如果看三大编码基准(SWE-Bench Pro + Terminal-Bench 2.0 + NL2Repo)的综合表现,排名又不一样了:
GPT-5.4:58.0 Claude Opus 4.6:57.5 - GLM-5.1:54.9
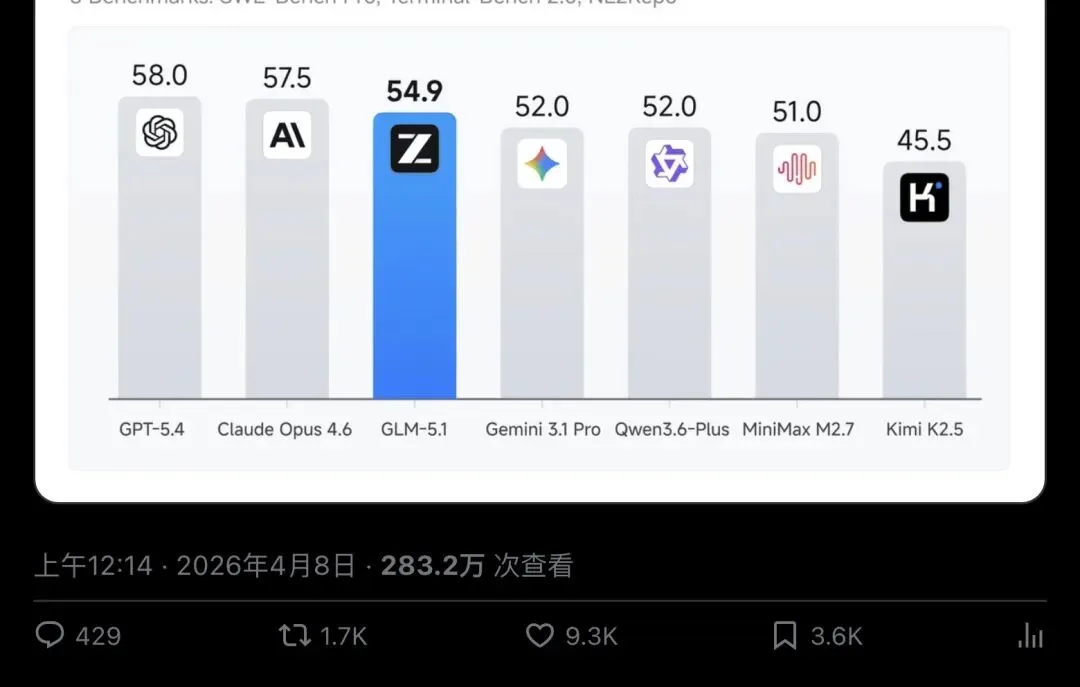
▲ Z.ai官方主贴:综合三大编码基准,GLM-5.1排名全球第三、开源第一(283.2万次查看,9.3K赞)
所以准确地说:SWE-Bench Pro单项全球第一,综合编码全球第三,开源第一。
智谱官方也给出了同样的定位:「#1 in open source and #3 globally.」
这已经是中国AI公司在编码Agent领域做出的最好成绩之一了。
「越跑越强」:600轮迭代的硬核证据
说回核心卖点:为什么GLM-5.1能解决「跑久变笨」?
智谱在博客里用了一个非常简洁的表述:
"The longer it runs, the better the result."
「跑得越久,结果越好。」
为了证明这句话,他们给出了三个递进式的场景验证,一个比一个狠。
场景一:VectorDBBench——600轮迭代,6000次工具调用
这是一个向量数据库优化挑战。之前最好的成绩是Claude Opus 4.6在50轮tool call预算内做到的3,547 QPS。
智谱把GLM-5.1放进了一个外层优化循环:不限轮次,模型自己决定什么时候提交新版本、接下来试什么方向。
结果?600多轮迭代、6000多次工具调用后,GLM-5.1把QPS从3,547推到了21,500——翻了整整6倍。
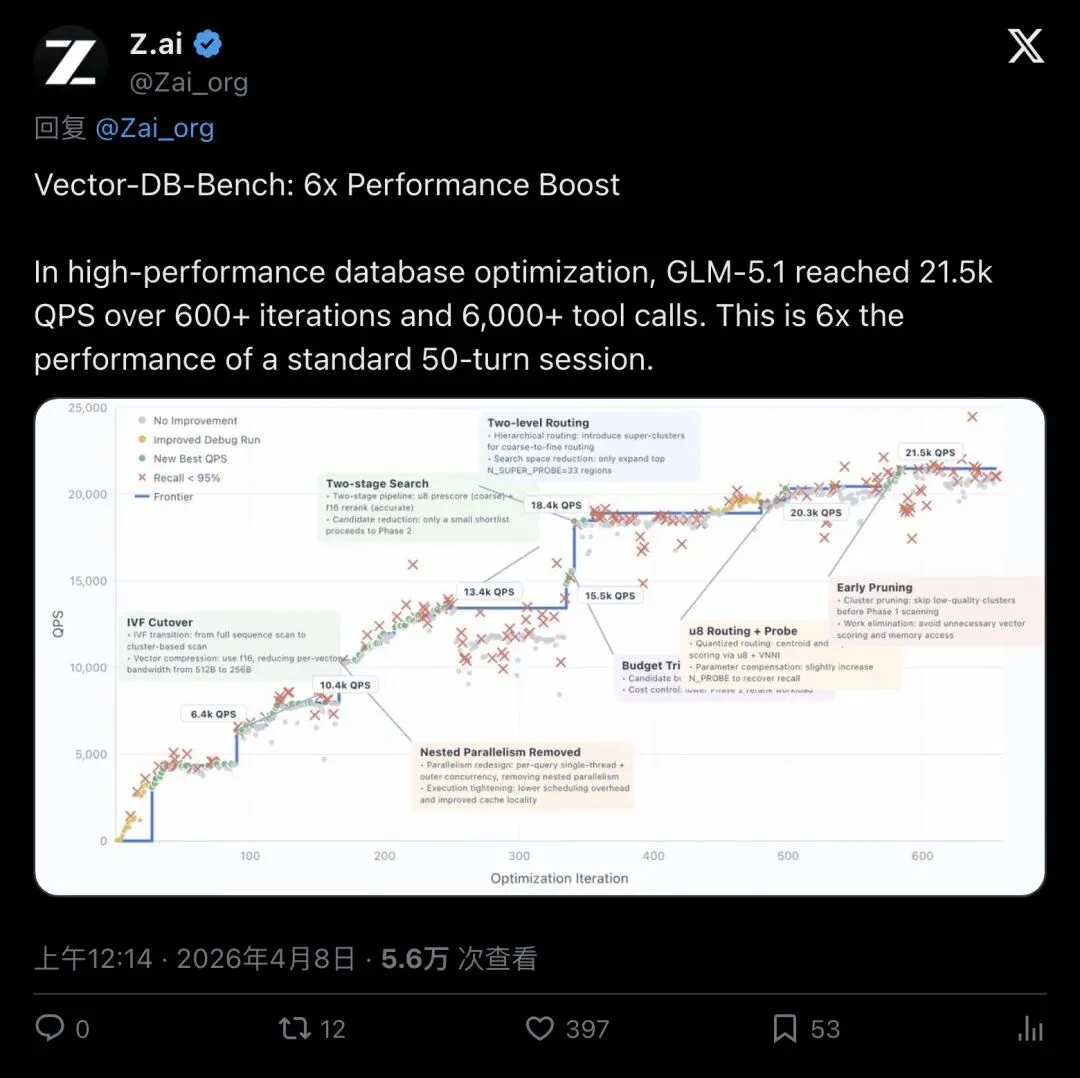
▲ Z.ai官推:VectorDBBench场景下GLM-5.1实现6倍性能提升(5.6万次查看,397赞)
博客里那张迭代曲线图更有意思:性能提升呈现明显的「阶梯式」上涨。模型在一个策略内微调一段时间,然后突然切换到全新的架构思路,性能跳上一个台阶。
"Six such structural transitions occurred over the full run, each initiated by the model after analyzing its own benchmark logs and identifying the current bottleneck."
「整个过程中发生了6次这样的结构性转变,每一次都是模型自己分析了基准测试日志、找到当前瓶颈后主动发起的。」
关键词:主动切换策略。遇到瓶颈不死磕,自己分析日志,自己「换脑子」——这才是跟之前模型最大的区别。
场景二:KernelBench——1000多轮GPU优化
第二个场景是GPU kernel优化。这里智谱很诚实地给出了对比:
GLM-5.1最终达到3.6倍加速 Claude Opus 4.6达到4.2倍加速
没错,在这个任务上Opus 4.6仍然是最强的。但博客原文也指出,GLM-5.1相比自家前代GLM-5有了质的飞跃——GLM-5很早就plateau了,GLM-5.1在超过1000轮后还在持续优化。
这个诚实反而让人对整篇博客的可信度加分:不吹全面碾压,承认差距的同时展示真实进步。
场景三:8小时从零搭建Linux桌面环境
最后一个场景最有想象力:给GLM-5.1一个prompt,让它从零搭建一个Linux桌面环境的Web应用。没有starter code,没有设计稿,没有中间指导。
▲ Z.ai官推:GLM-5.1用8小时自主构建了一个完整的Linux桌面环境(9.7万次查看,985赞)
在self-review loop下连续运行8小时后,GLM-5.1从一个基础骨架逐步迭代出了完整的桌面系统——文件浏览器、终端、文本编辑器、系统监控、计算器、游戏,每个新功能都融入了统一的UI。
"By the end, the result is a complete, visually consistent desktop environment running in the browser."
「最终,结果是一个在浏览器中运行的完整、视觉一致的桌面环境。」
这个场景没有量化指标,完全靠模型自己判断「接下来该改什么」。在没有外部反馈的情况下还能持续自我优化8小时——这才是「长周期Agent」概念最有说服力的演示。
海外AI圈怎么看?
AI评论人Wes Roth在推文中给出了一个很精准的定性:
"Unlike standard conversational models, GLM-5.1 is specifically engineered for long-horizon, autonomous tasks. It is capable of running independently for up to 8 hours, utilizing self-review loops to refine strategies across thousands of iterations and tool calls."
「与标准对话模型不同,GLM-5.1专门为长周期自主任务而设计。它能够独立运行最长8小时,利用自我审阅循环在数千次迭代和工具调用中不断优化策略。」
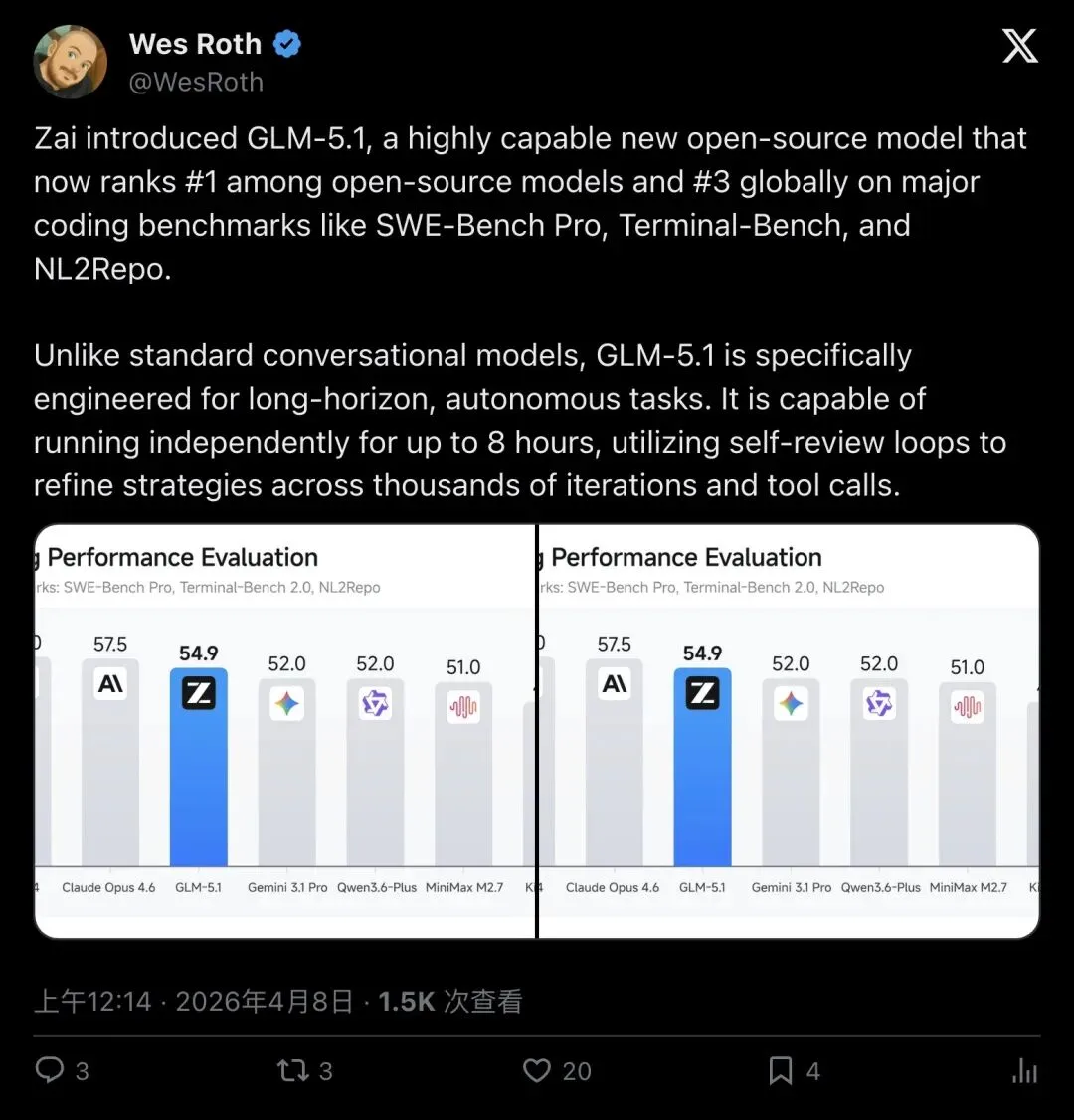
▲ AI评论人Wes Roth总结GLM-5.1核心特点(1.5K次查看)
值得注意的是,GLM-5.1以MIT协议完全开源,权重已放上HuggingFace和ModelScope,并兼容Claude Code、OpenClaw等主流Agent框架。
对于开发者来说,这意味着你可以直接在现有的Agent工作流里接入这个模型,不用换框架。
「长周期Agent」时代来了?
GLM-5.1最值得关注的,是它提出了一个全新维度的竞争:给模型更多时间,它还能不能继续变好?
过去我们评估AI模型,看的是「单次回答有多准」。但在Agent时代,真正重要的问题变了:当任务需要跑几百轮、甚至跑8个小时的时候,你的模型还行不行?
智谱在博客结尾也很清醒地列出了未解难题:如何更早跳出局部最优?如何在数千轮工具调用中保持一致性?如何在没有量化指标的任务里做到可靠的自我评估?
这些问题,目前所有模型都还没完全解决。但至少GLM-5.1迈出了明确的一步——而且是以开源的方式。
SWE-Bench Pro全球第一、编码综合全球第三、开源第一。
一个来自中国的开源模型,在Agent编码的最前沿跟OpenAI和Anthropic掰手腕——这件事本身,就已经足够让人兴奋了。
— END —
