 夜雨聆风
夜雨聆风
题目:SERSCheminformatics:OpportunitiesforData-DrivenDiscovery andApplications


这篇文章最大的创新,不是提出某一个新的算法或者新仪器,而是首次系统性地提出了一个“面向未来的SERS-cheminformatics一体化框架”。作者认为,传统的表面增强拉曼散射(SERS)虽然已经具备超高灵敏度,但真正限制其进一步走向大规模应用的,不再是仪器本身,而是数据管理、数据解释和数据复用能力不足。
因此,文章提出了一个由四个关键支柱组成的整体路线图,分别是:中央化SERS数据库、分子建模、机器学习、自动化与AI驱动的数据挖掘。作者强调,这四部分并不是彼此独立的,而是形成一个持续循环、不断反馈的闭环系统。数据库为机器学习提供数据,分子建模为模型提供理论解释,自动化系统又不断生成新的数据,最终再反哺数据库和模型。
相比以往多数工作只聚焦于某个单独方向,例如仅做拉曼分类、仅做分子模拟、仅做数据库搭建,这篇文章更像是提出了一套未来十年SERS发展的“总蓝图”。
其中有几个特别值得关注的创新点。
第一,作者提出应建立一个统一的、可跨实验室共享的SERS数据库,并且给出了一个完整的六步框架,包括数据预处理、质量控制、数据增强、标准化标签、数据存储和数据管理。过去不同实验室之间由于基底、激光波长、仪器型号不同,往往导致光谱难以比较,而这篇文章试图从源头上解决这一问题。
第二,文章强调不能再把SERS只看成一个“测量工具”,而应该看成一个“可计算、可预测、可扩展的数据平台”。作者提出,要通过密度泛函理论、分子对接、分子动力学等方法,把“光谱—结构—性质”三者真正连接起来,让模型不仅能识别一个分子是谁,还能预测它的生物活性、毒性、溶解性等性质。
第三,文章特别强调动态SERS分析的重要性。过去很多拉曼研究停留在静态分类,例如区分某个样本是阳性还是阴性,而作者提出未来的重点应是实时连续监测,例如可穿戴汗液检测、食物腐败监测、空气中有毒气体监测等。
第四,文章提出未来SERS的发展离不开自动化实验和大语言模型。作者设想,未来机器人可以自动制备基底、自动采集光谱、自动优化实验条件,而大语言模型则可以自动阅读文献、抽取实验参数、构建知识图谱,从而形成真正的“自驱动实验室”

1. Figure 1:提出SERS-cheminformatics的四大核心支柱
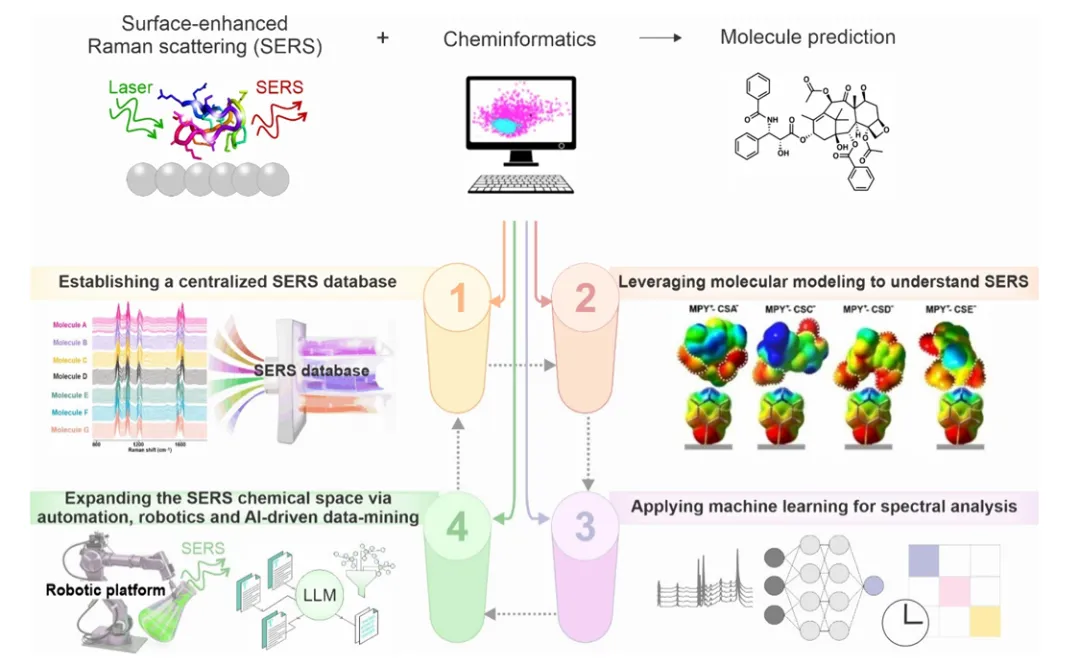
Figure 1 是整篇文章最重要的一张总览图。作者把未来SERS的发展分成四个互相连接的模块。
第一个模块是中央化数据库。它负责收集、清洗、标注和存储不同来源的SERS数据。
第二个模块是分子建模。它利用量子化学和分子模拟方法,解释为什么某些分子会出现特定的拉曼峰,以及为什么某些基底会带来更强的增强效果。
第三个模块是机器学习。它负责从复杂光谱中提取模式,实现分类、回归和实时预测。
第四个模块是自动化与AI。它通过机器人、高通量实验、微流控和大语言模型,不断扩展可分析的化学空间。
这张图的重要意义在于,它把过去分散的多个研究方向整合成了一个统一框架。对于未来做SERS的人来说,这张图几乎可以视为一个研究路线图。
2. Figure 2:如何建立一个真正可用的SERS数据库
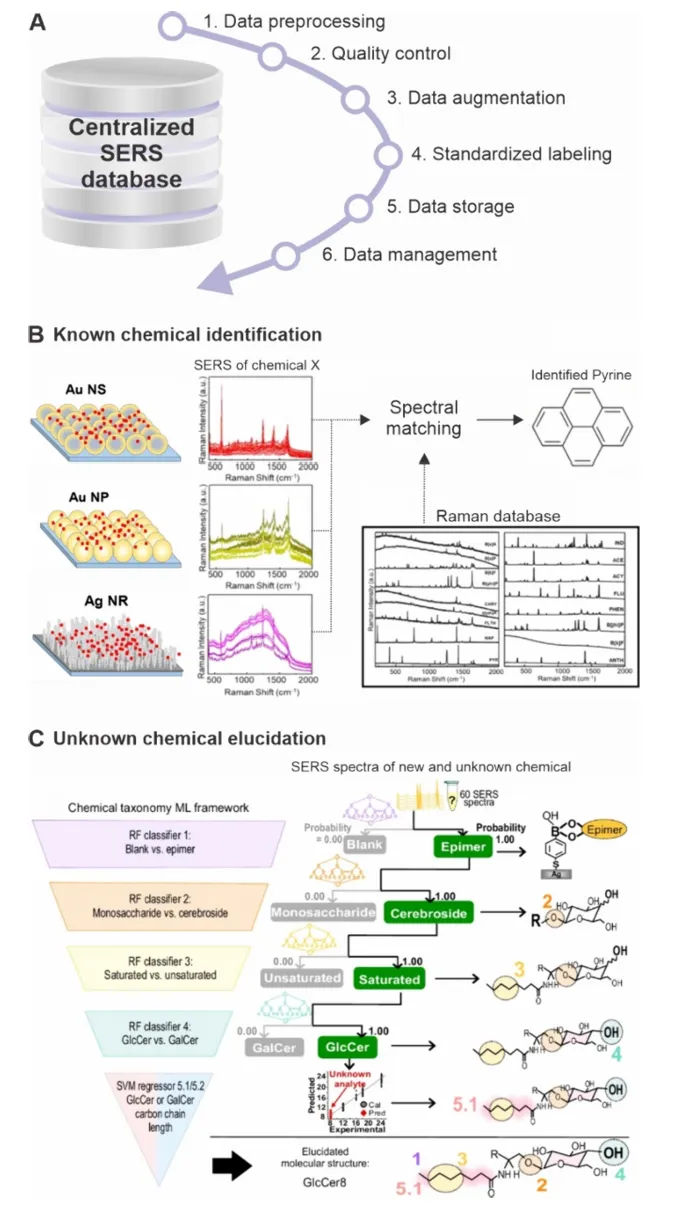
Figure 2 主要围绕数据库建设展开。
Figure 2A 提出了建立大型SERS数据库的六个关键步骤,分别是数据预处理、质量控制、数据增强、标准化标签、数据存储和数据管理。作者认为,真正决定数据库价值的,并不仅仅是收集多少光谱,而是这些光谱是否经过统一标准处理,是否包含完整元数据,例如基底类型、激光波长、采集时间、温度、样本来源等。
Figure 2B 展示了一个非常典型的案例:研究人员利用统一数据库中的光谱,对不同基底上的多环芳烃进行识别。即便这些光谱来自不同的纳米金球、金纳米颗粒和银纳米棒基底,模型依然能够达到82.4%的识别准确率。这个结果说明,一个标准化数据库能够有效减少“换了基底就识别不了”的问题。
Figure 2C 更有意思。它展示了数据库不仅能识别“已知分子”,甚至还能帮助推断“未知分子”的结构。作者介绍了一种五层级的化学分类体系,可以通过光谱特征一步步判断未知神经酰胺属于哪一类、是否饱和、糖基结构是什么、脂肪链长度是多少。最终,这种方法对核心亚结构的识别准确率超过90%,脂肪链长度预测误差不到一个碳原子。
这一部分的核心思想非常明确:未来真正有价值的不是某一张光谱,而是一个可以共享、可追溯、可搜索、可推理的光谱数据库。
3. Figure 3:从“看见峰”走向“理解峰”
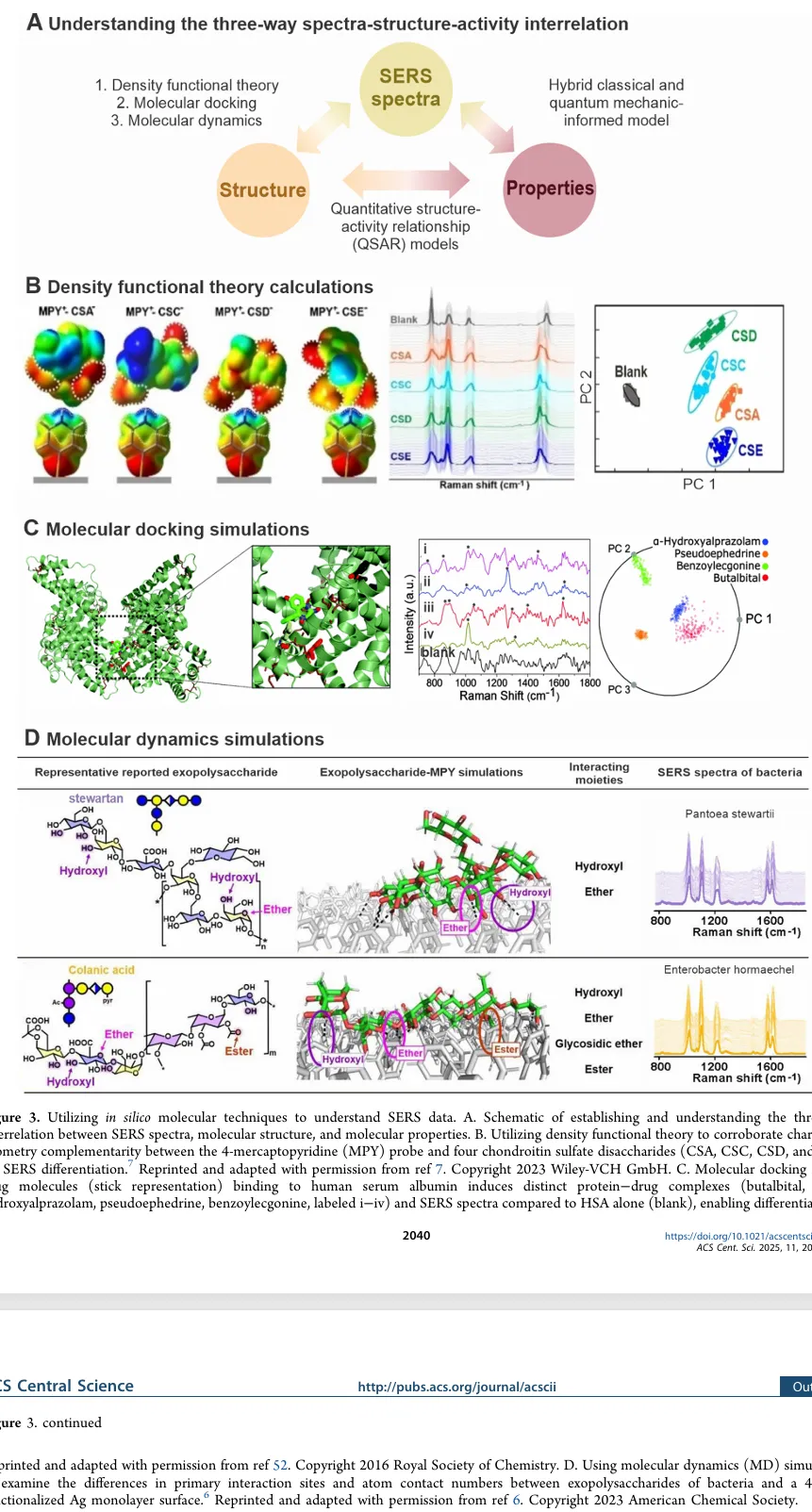
Figure 3 是全文中最偏机制的一部分。
Figure 3A 提出了一个非常重要的概念,即“光谱—结构—性质”的三元关系。过去很多拉曼分析只停留在“哪个峰高、哪个峰低”,但作者认为,真正重要的是理解这些峰为什么出现,它们反映了什么结构特征,以及这些结构特征又如何决定分子的性质。
Figure 3B 展示了密度泛函理论(DFT)的作用。研究人员通过DFT模拟,分析了4-巯基吡啶与不同硫酸软骨素二糖之间的电荷和几何互补性。结果发现,不同分子之间的微小差异会导致明显不同的SERS指纹,最终模型对四种异构体的分类准确率超过97%,定量误差低于3%。
Figure 3C 展示了分子对接在药物检测中的应用。研究人员将不同小分子药物与人血清白蛋白进行分子对接,发现不同药物会形成不同的蛋白-药物复合物,进而产生不同的SERS光谱。这使得SERS不仅可以检测药物是否存在,还可以提高对不同药物类别的区分能力。
Figure 3D 展示了分子动力学模拟在细菌识别中的价值。研究人员模拟了细菌胞外多糖与功能化银表面的相互作用,发现不同细菌由于表面化学环境不同,会产生不同的SERS指纹。最终,该方法对六种细菌的识别准确率超过98%。
这一部分最重要的结论是:未来的SERS不能只依赖实验,还必须结合模拟。因为只有理解峰背后的分子机制,才能真正做到可解释、可泛化、可预测

这篇文章最重要的结论是,SERS未来的发展瓶颈已经不再是“能不能测到”,而是“能不能理解”和“能不能规模化利用”。
作者认为,未来的SERS必须从传统的单次实验模式,转向一个以数据为核心的智能系统。这个系统应该同时具备四种能力:有统一数据库、有机制建模能力、有机器学习预测能力、有自动生成新数据的能力。
文章反复强调,数据库是基础、分子模拟是解释、机器学习是预测、自动化和大语言模型是扩展。只有四者结合,SERS才能真正进入大规模应用阶段。
作者还指出,未来SERS最值得关注的几个方向包括:
• 未知分子的自动识别与结构推断
• 可穿戴实时健康监测
• 食品安全和环境监测
• 药物筛选和催化剂设计
• 多组学分析与医学诊断
• 自动化实验室和机器人化学家
此外,作者特别强调,未来的模型不能只做黑箱分类,而必须具有可解释性。例如,机器学习的结果应该能够和DFT模拟、分子对接、分子动力学等机制分析相互印证。这样才能保证模型既准确,又可靠

这篇文章虽然是一篇综述性质的 Outlook,但它真正有价值的地方,在于它不是简单罗列已有工作,而是提出了一条非常明确的未来路线。
过去的SERS研究,更多是在追求更高的增强倍数、更好的基底、更低的检测限。而这篇文章提醒我们,未来真正决定SERS能否成为主流分析技术的,不仅仅是仪器性能,而是整个数据生态。
谁能率先建立标准化数据库,谁能把模拟和实验真正结合,谁能利用机器学习做实时分析,谁能构建自动化闭环系统,谁就更有可能主导下一代SERS的发展方向。
从这个角度看,SERS正在从一种“光谱技术”变成一种“数据科学平台”。而AI,很可能会成为推动这一转变最关键的力量

