 夜雨聆风
夜雨聆风
◆ 核心问题
LLM 只是在预测下一个 token,为什么能“做决策”?它在 Agent 里的边界在哪?
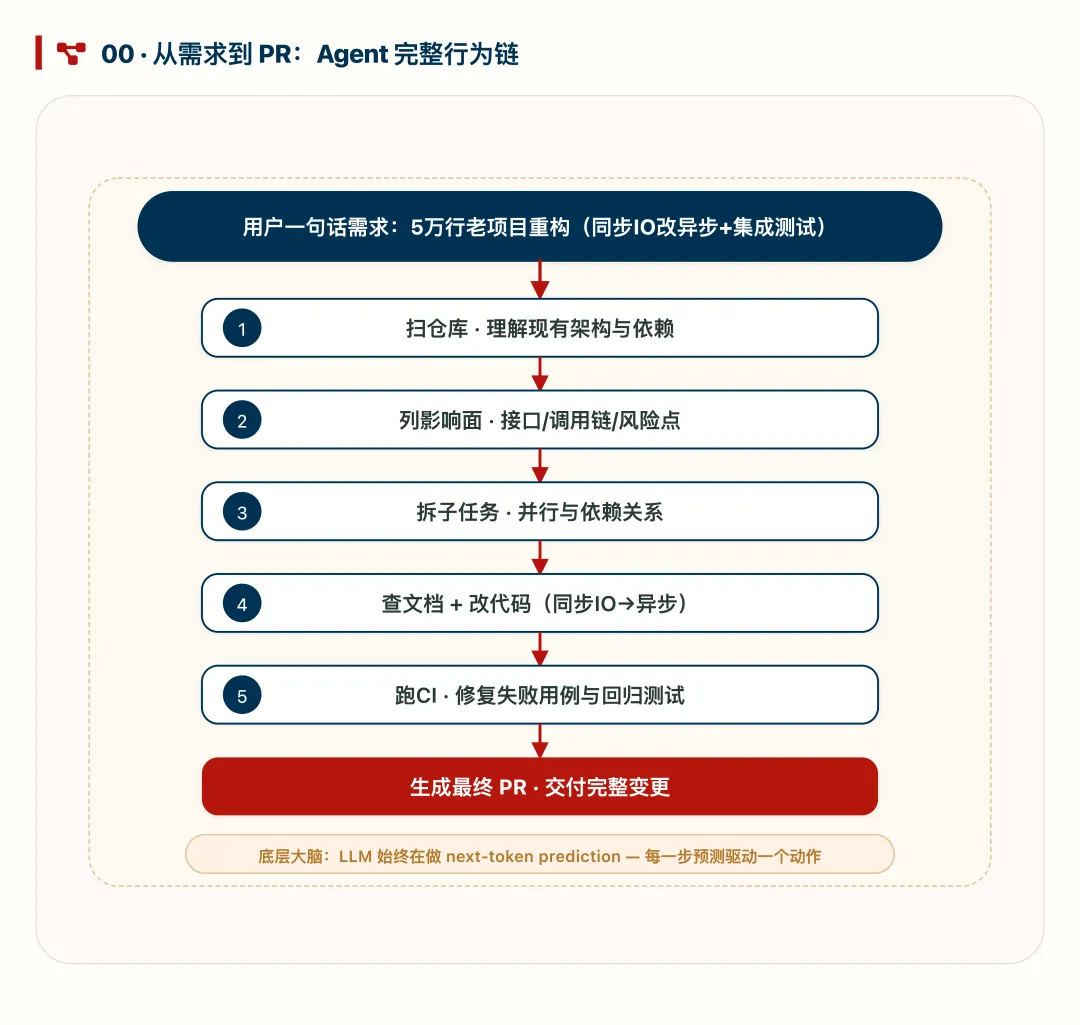
用户给出一句复杂指令,Agent 自动拆解为“扫仓库→列影响面→拆任务→改代码→跑CI→提PR”的完整行为链。每一步都由 LLM 预测下一个 token 驱动,但通过工程闭环,最终表现出了项目经理级的规划与执行能力。
一、LLM 的能力边界

LLM 的核心优势在于语言理解和模式匹配,但它在精确计算、实时信息、持久记忆和直接操作外部世界方面存在天然短板。Agent 的工程层正是为了补齐这些短板:将计算、查询、存储、执行都封装成工具,让 LLM 通过调用工具来间接完成。理解这个边界,是设计 Agent 的第一步。
二、让 Agent 变聪明的五种模式

从最简单的 CoT(思维链)到 ReAct 闭环、Reflexion 自我反思、Planning 任务分解,再到 CodeAct 动态编程,复杂度逐级提升。关键数据:Reflexion 让 GPT-4 在 HumanEval 上从 80% 提升到 91%,证明流程设计比模型大小更重要。
模式 1:CoT 思维链(一步步思考)
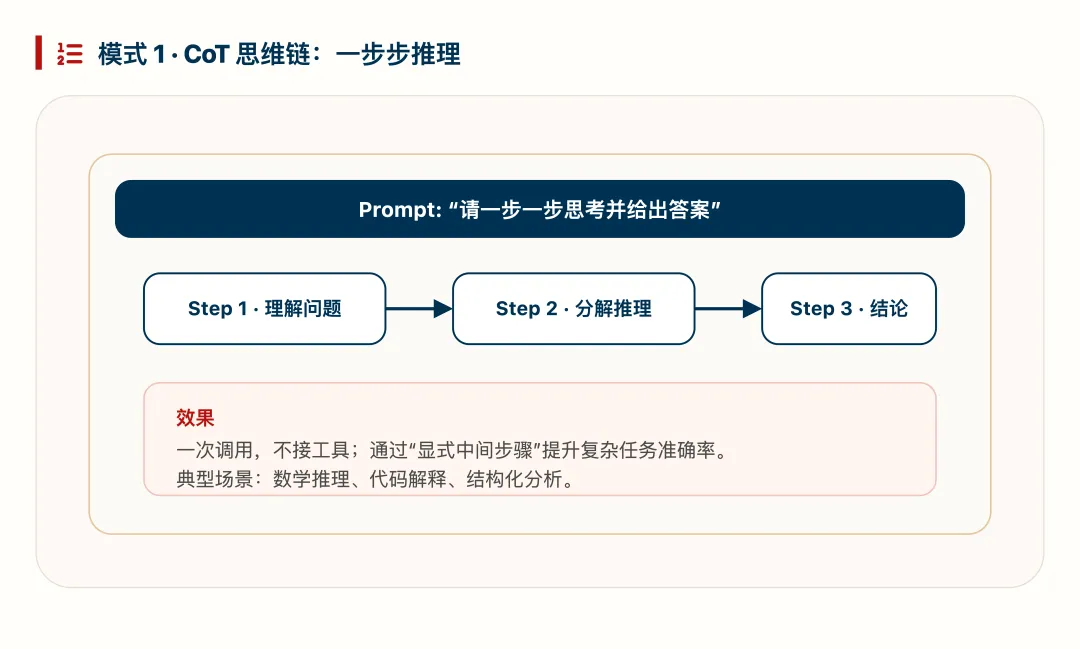
CoT(Chain-of-Thought)通过要求模型“逐步推理”,在一次调用内显式展开中间步骤。它实现成本最低,适合作为 Agent 推理增强的起点。
模式 2:ReAct 循环(思考→行动→观察)
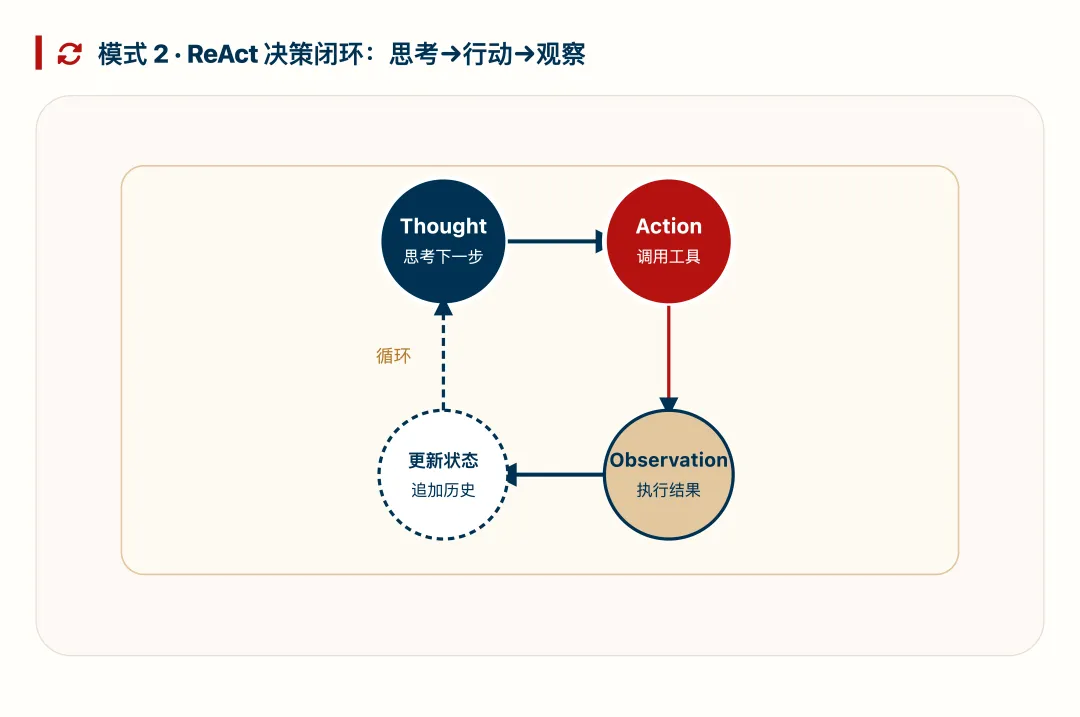
ReAct 让 LLM 在“思考→行动→观察→更新状态”之间循环。每次观察(Observation)都为下一步决策提供新信息,逐步降低任务的不确定性。这是 Agent 区别于一次性 Chatbot 的核心机制,也是“从预测 token 到做决策”的直接体现。
模式 3:Reflexion(评估→反思→重试)
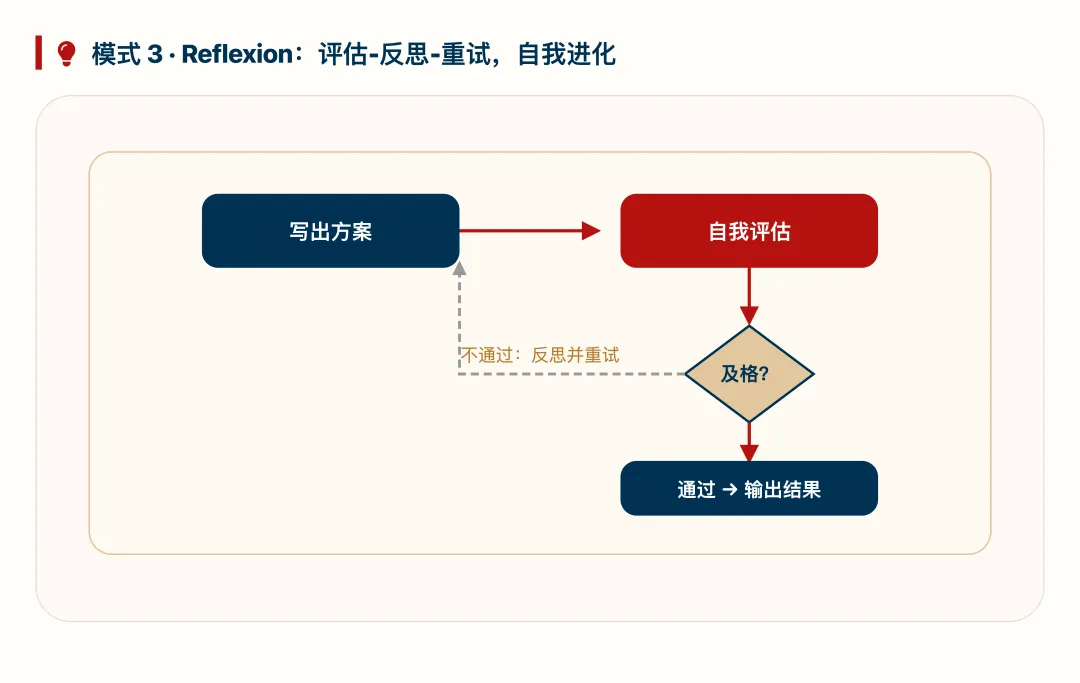
Reflexion 让 LLM 先写出方案,再对自己进行结构化评估。如果不通过,则根据评估中的批评意见修改后重试。在 HumanEval 代码生成任务上,这种方法将 GPT-4 的 80% 准确率提升到 91%。关键在于:同一个模型分饰“写作者”和“评审员”,流程设计放大了模型能力。
模式 4:Planning(先规划再执行)
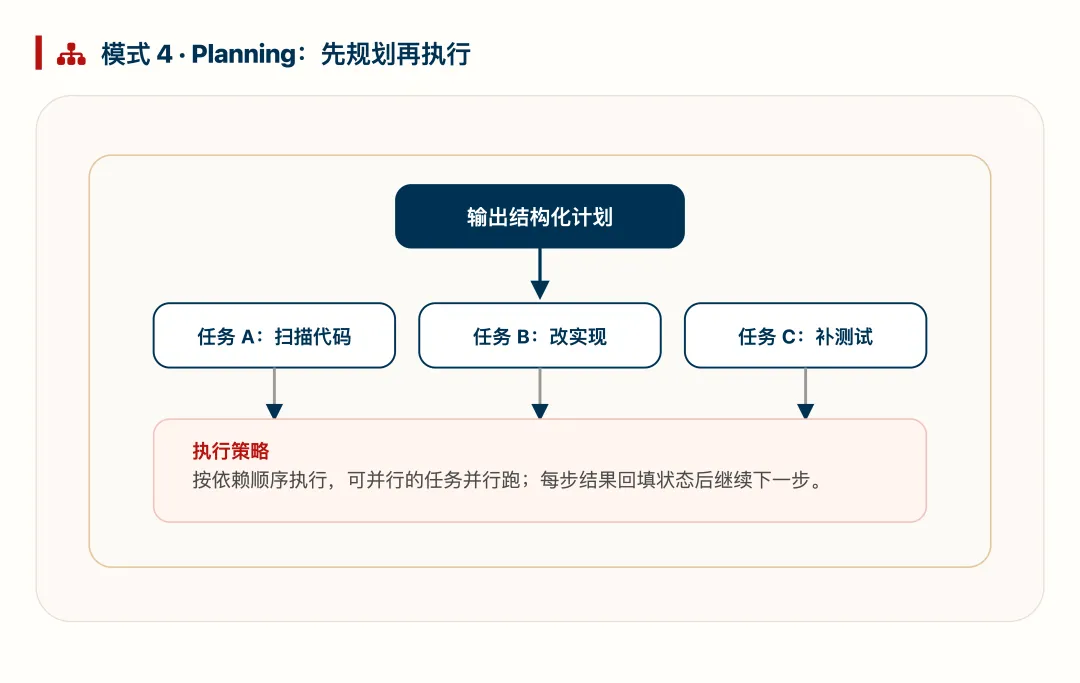
Planning 先让模型输出结构化计划,再按依赖顺序执行子任务。它适合多步骤、强依赖的复杂任务,能显著降低直接执行时的混乱和返工。
模式 5:CodeAct(动态写代码)

当预置工具覆盖不了问题时,CodeAct 允许 Agent 临时生成并执行脚本,把结果回填为 Observation,再继续决策。这是处理非常规任务的关键补位能力。
三、结构化输出:Function Calling 是工程基石
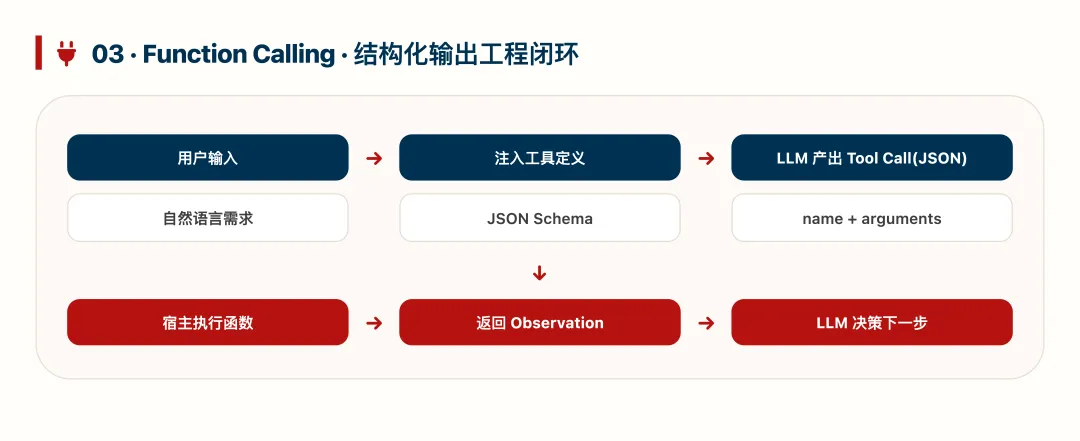
前面的模式都依赖同一件事:让 LLM 输出结构化工具调用(JSON),而不是自由文本。模型只负责“决定调用什么工具、传什么参数”,真正执行仍由宿主系统完成。
{"name": "search_codebase","description": "在代码仓库中搜索关键词","parameters": {"type": "object","properties": { "query": {"type":"string"} },"required": ["query"]}}
调用链路是:用户输入 → 注入工具定义 → LLM 输出 tool call JSON → 宿主执行函数 → 执行结果回填给 LLM。LLM 本身没有“手脚”,是工程系统给了它行动能力。
四、模型路由:成本与质量的平衡

不是所有步骤都需要最强模型。Claude Code 的实践:探索搜索用轻量 Haiku,规划编码用 Sonnet/Opus。这种异构架构每月可节省数十万美元 API 费用。研究表明,正确的模型路由可以在性能损失不到 1% 的情况下降低 60% 的成本。
五、System Prompt:约束比能力更重要

优秀的 System Prompt 不是教模型变聪明,而是教它少犯错。通过明确角色边界、工具使用原则、不确定处理方式和记忆规范,可以大幅降低 Agent 的危险行为。Claude 的系统提示经历了 50 多个版本的迭代,最终演变为数千字的操作手册,核心就是“约束比能力更重要”。
六、控制论视角:开环 Chatbot vs 闭环 Agent

Chatbot 是开环系统:输入一次,输出一次,没有反馈。Agent 是闭环系统:感知→决策→行动→再感知,持续循环。闭环让 LLM 能够根据执行结果动态调整策略,这是它能“做决策”的根本原因。控制论告诉我们:没有反馈的系统无法适应变化,而 Agent 正是通过每次观察来降低不确定性。
◆ 反直觉洞察:让 LLM 做“更少但更关键的事”
最好的 Agent 不是让 LLM 做更多事,而是做更少但更关键的事,把所有确定性、可验证的部分交给代码和工具。
实践清单
清单实践清单
1给 LLM 标出“禁区”:System Prompt 中明确“你不能做什么”
2计算类需求换成工具:禁止 LLM 自己算数
3实现 Reflexion 循环:让 LLM 自我评估并重写
4画模型路由矩阵:不同任务用不同模型
5System Prompt 升级为操作手册:边界 + 策略 + 不确定处理 + 记忆
◆ 延伸阅读
• Building Effective AI Agents
• Reflexion: Language Agents with Verbal Reinforcement Learning
• Function Calling and Tool Use in AI Agents
• ChatGPT vs Claude: Comparison for AI Agent Architects
• Better Ways to Build Self-Improving AI Agents
◆ 下一篇预告:工具系统与 MCP —— Agent 的“手脚”与标准化接口
本文回答了 LLM 在 Agent 中的角色。下一篇将聚焦:工具设计、MCP 协议、安全与权限。
