 夜雨聆风
夜雨聆风刷朋友圈时,你会自动跳过杂乱的广告,聚焦好友的自拍与分享;身处嘈杂的派对,你能过滤背景噪音,清晰听清对面人的交谈;看书时,目光会不自觉停留在重点公式和核心观点上——这种“选择性关注”的能力,是人类与生俱来的认知智慧。
而在AI世界里,让模型拥有这种“专注力”的核心技术,就是注意力机制。
它不是什么高深莫测的黑科技,本质上就是教会AI“抓重点、放次要”,摆脱“雨露均沾”的低效,像人类一样精准聚焦关键信息。从ChatGPT流畅生成万字长文,到AI识图精准识别目标,再到机器翻译避免“张冠李戴”,注意力机制都是背后的“隐形大脑”。
今天,让我尝试从“是什么、怎么工作、怎么演进、有什么用”四个维度,介绍清楚注意力机制的原理。
01
注意力机制解决了什么问题?
在注意力机制出现之前,AI处理信息的方式堪称“一根筋”——无论是RNN、LSTM这类序列模型,还是CNN这类图像模型,都存在明显的局限。
拿CNN(卷积神经网络,是一种常用于处理图像等数据的 AI 模型)举例,它处理一张“猫的图片”时,会平等对待每一个像素:认真分析猫的眼睛、胡须(关键信息),也会花费同样的精力去处理猫身后的沙发纹理、远处墙上的污点(无关信息),就像一个不会抓重点的学生,把所有内容都当成考点死记硬背,效率低下还容易抓错核心。
而RNN(循环神经网络,是一种常用于处理文本等序列数据的 AI 模型)这类模型更尴尬,它处理文本时只能“逐字逐句”串行计算,就像我们看书只能从头读到尾,不能跳读、不能回看。一旦遇到长文本(比如一篇万字文章),它就会“记不住”前面的内容,无法捕捉远距离信息的关联——比如长句子中“它”到底指代前文的哪个对象,RNN常常会混淆。
这两个痛点,直接限制了AI的能力上限:无法高效处理长信息、无法精准捕捉关键关联。
直到2014年,Bahdanau团队首次将注意力机制引入神经机器翻译,打破了这一僵局;2017年,Transformer架构横空出世,喊出“Attention Is All You Need”(注意力就是一切)的宣言,彻底将注意力机制推上核心舞台,改写了AI的发展轨迹。
简单来说,注意力机制的核心使命就是:让AI学会“取舍”——给关键信息分配高权重(重点关注),给无关信息分配低权重(忽略或弱化),不用对所有信息投入同等精力,从而提升效率和精准度。
就像我们拍照时对焦:把镜头对准主角(高权重),让背景模糊(低权重),这样拍出来的照片才重点突出、清晰好看。注意力机制,就是AI的“智能对焦功能”。
02
注意力机制的“工作流程”
不管是哪种注意力机制(自注意力、交叉注意力、多头注意力),核心逻辑都离不开“查询→匹配→取值”三步,就像我们在图书馆找资料的过程,简单又好记。
我们先记住三个核心概念,后续拆解全靠它:
Q(Query,查询):你要找的信息——比如你在图书馆的“研究问题”:“深度学习在医疗中的应用”,是你主动发起的“搜索需求”;
K(Key,键):所有可供查询的信息标签——比如图书馆里每本书的“分类标签”,告诉你这本书讲的是什么,用于和Q匹配;
V(Value,值):信息的实际内容——比如你找到的那本书的具体章节、知识点,是你最终需要的“有用信息”。
这三个概念,都是由AI的输入信息(比如一段文本、一张图片),通过三个独立的可学习线性层生成的。在实际模型运算中,Q、K、V可以暂时简单理解为是三个矩阵。(怎么由输入大模型的文本转变成矩阵,将在后续的文章中详细介绍)
搞懂Q、K、V,我们再看注意力机制的完整工作流程(以最经典的“缩放点积注意力”为例,Transformer的核心):
第一步:计算“匹配度”——给Q和K做“相似度打分”
目的是判断:每个Q(你要找的信息)和所有K(可供查询的标签)之间,关联度有多高。
最常用的方式是“点积计算”:把Q和K的转置矩阵相乘,得到一个“相似度分数矩阵”。这个矩阵里的每一个数值,都代表某一个Q和某一个K的匹配程度——分数越高,说明两者越相关,这个K对应的信息就越值得关注。
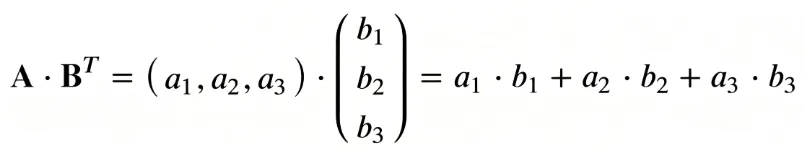
举个例子:如果Q是“苹果”,K分别是“红色”“圆形”“桌子”,那么“苹果”和“红色”“圆形”的相似度分数会很高,和“桌子”的分数会很低。
第二步:“缩放+归一化”——让分数更合理,权重更清晰
这一步是为了避免“分数失真”,让AI能更精准地判断“重点”。
首先是缩放操作(scaling):把第一步得到的相似度分数,除以√dₖ(√dₖ是Q和K的维度)。为什么要这么做?因为当dₖ很大时,点积计算的分数会变得非常大,即参与点积矩阵的维度会对结果产生影响。既会影响不同矩阵相似度的判别标准不一致,也会导致后续Softmax函数计算后,梯度消失(模型学不到东西),缩放后能让分数保持平稳,保证模型训练稳定。
然后是归一化操作:用Softmax函数,把缩放后的分数转化为0~1之间的权重,并且保证所有权重的和为1。这样一来,权重就有了“概率意义”——权重越接近1,说明这个K对应的信息越重要;越接近0,说明越无关。
还是拿“苹果”举例:缩放归一化后,“红色”“圆形”的权重可能达到0.45、0.4,而“桌子”的权重只有0.15,重点瞬间就清晰了。
第三步:加权求和——提取关键信息,生成最终输出
这是最后一步,也是最核心的一步:用第二步得到的注意力权重,对V(信息的实际内容)进行加权求和。
简单说就是:权重高的V,贡献更多的信息;权重低的V,贡献更少的信息,最终合并成一个“聚焦关键信息”的输出向量。这个向量,就是注意力机制处理后的结果——它过滤了无关信息,浓缩了核心内容,能让AI更高效地进行后续处理(比如文本生成、图像识别)。
注意力机制公式:
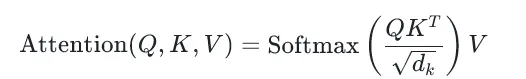
先计算Q和K的相似度(Q和K的转置的点积),再缩放(除以√dₖ),然后归一化(Softmax),最后用权重对V加权求和,得到注意力输出。
03
注意力机制的进化历程
注意力机制不是一成不变的,从2014年被引入,到如今支撑Llama 3、ChatGPT等大模型,它经历了4个关键进化阶段,核心是在“效果”和“效率”之间不断寻找平衡,让AI既能“看得准”,又能“跑得块”。
阶段1.0:激进的“近似革命”——为速度牺牲精度
代表模型:Reformer
核心思路:用“局部敏感哈希注意力”(LSH Attention),把长文本的token(词)“分组”,只计算组内相似词的关联,把计算复杂度从O(n²)降到O(nlogn),大幅提升速度。
缺点:就像用模糊搜索找文件,容易漏掉关键信息,比如机器翻译时会出现“张冠李戴”的错误,最终因效果损失,成了“技术先烈”,但证明了“注意力可以简化”。
阶段2.0:实用的“稀疏方案”——抓重点放细节
代表模型:Longformer、BigBird
核心思路:“滑动窗口+全局注意力”结合——普通词只看“前后5个词”(滑动窗口),像我们阅读时聚焦当前段落;关键词(如特殊标记)拥有“全局视野”,像划重点的荧光笔。
优势:处理10000字长文档时,显存占用从256GB降至64GB,成了法律、医疗等长文本场景的“标配”,兼顾了效率和效果。
阶段3.0:底层的“效率革命”——不换公式换玩法
代表模型:FlashAttention
核心思路:不改变注意力的数学公式,而是通过“IO感知算法优化”提升效率——把SRAM(高速缓存)当“工作台”,减少与HBM(内存)的频繁交互,就像把常用文件放桌面,而不是仓库。
优势:全量注意力计算速度提升3倍,显存占用降低50%,让被冷落的“全量注意力”重新成为主流。值得一提的是,ChatGPT能流畅生成万字长文,FlashAttention的底层优化功不可没。
阶段4.0(2023-2024):推理的“终极优化”——Llama 3的胜利
代表模型:Llama 2/3
核心思路:GQA(分组查询注意力)——平衡速度和效果。MQA(多查询注意力)虽然快,但所有注意力头共享1套KV,容易“失忆”;而GQA把32个头分成8组,每组共享1套KV,完美解决了这个问题。
优势:让大模型推理成本降低70%,甚至能在手机端运行Llama 3,让大模型真正走进日常场景。
04
注意力机制的广泛应用
注意力机制不是实验室里的技术,它早已渗透到我们生活的方方面面,只是我们很少察觉。以下几个常见场景,都有它的身影:
1. 自然语言处理(NLP):AI读懂语言的核心
无论是ChatGPT的对话生成、Google翻译的精准翻译,还是微信的语音转文字、新闻APP的自动摘要,都离不开注意力机制。
比如翻译“我爱吃中国菜”,注意力机制会让“中国菜”和英文“Chinese food”精准匹配,让“爱”和“love”对应,避免出现“我吃中国菜爱”这种语序混乱的错误;生成文本摘要时,它会自动提取“事故造成3人受伤”这类关键信息,忽略“现场有交警疏导交通”等细节,提升摘要的信息密度。
2. 计算机视觉(CV):AI“看懂”图像的关键
我们用手机拍照时的“人像模式”(背景虚化)、AI识图(识别图片中的猫、狗、人)、自动驾驶中的“目标检测”(识别行人、车辆、红绿灯),都依赖注意力机制。
比如AI识别一张“人物照片”,注意力机制会把高权重分配给人物的面部,低权重分配给背景的天空、树木,从而精准识别出人物身份,避免被背景干扰——这和我们看照片时自动聚焦人物的逻辑完全一致。
3. 多模态场景:打破文本、图像的壁垒
现在热门的“图文生成”(输入文字生成图片)、“看图说话”(输入图片生成描述),都需要注意力机制来实现跨模态的“精准对齐”。
比如输入“一只白色的猫坐在沙发上”,注意力机制会让“白色”“猫”“沙发”这些文字,分别对应图片中的白色毛发、猫的轮廓、沙发的形状,从而生成符合描述的图片;看图说话时,它会聚焦图片中的核心元素,生成连贯、准确的文字描述。
05
结语
看到这里,相信你已经彻底搞懂了注意力机制的核心:它不是什么复杂的公式,而是模仿人类“选择性关注”的智慧,让AI学会“抓重点、放次要”,在效率和效果之间找到平衡。
从Reformer的“激进尝试”,到Llama 3的“精打细算”;从解决RNN的长距离依赖,到支撑大模型走进日常,注意力机制的进化史,就是AI从“实验室玩具”走向“实用工具”的缩影。
最后记住一句话:注意力机制的精髓,不是知道该关注什么,而是知道该忽略什么——这不仅是AI的核心能力,也是我们人类高效工作、学习的关键。
下次再用ChatGPT聊天、用AI识图时,不妨想一想:背后正是注意力机制,让AI拥有了和我们一样的“专注力”。
