 夜雨聆风
夜雨聆风Anthropic Engineering · 编译整理 · 2026 年 4 月 8 日 · 阅读约 12 分钟
过去,一个 AI 助手做完一件事才能做下一件。现在,Anthropic 正在构建的系统,可以让 AI 同时拥有多个"大脑"、操控多双"手",持续运行数小时乃至数天——而且崩溃了也能自己爬起来。
这件事,为什么值得关注
如果说过去两年的 AI 是"聪明的对话框",那这一代 AI 正在变成"能干活的同事"。区别不只是能力,而是工作方式。
托管智能体(Managed Agents)的出现,标志着 AI 系统从"回答问题"向"执行任务"的转变进入了工程成熟阶段。
开发者不再需要自己搭框架、护容器,AI 基础设施变成了水电一样的公共服务。
企业的长时程自动化任务—代码审查、数据分析、客服流程—可以真正托管给 AI,而不是人盯着跑。
整个行业的任务边界在扩大,从分钟级延伸到小时级、天级。
当然,这也带来了新的问题:AI 自主运行的边界在哪里?出了错谁来负责?这些讨论才刚刚开始。
已经有哪些公司在用
官方披露了五家早期用户的具体做法:
Notion
让用户直接在工作区里把任务丢给 Claude,写代码、做 PPT、做网页都行,几十个任务可以并行跑,全团队实时协作产出。目前以私人内测形式开放,功能名称为 Notion Custom Agents。
Sentry
把自家 bug 诊断工具 Seer 与 Claude Agent 串联,从定位根因到写补丁、提 PR 一条龙——整个集成几周内上线。
Rakuten
在产品、销售、营销、财务、HR 各条线部署了专用 Agent,通过 Slack 和 Teams 接收任务,产出表格、PPT、小应用等交付物。每个专用 Agent 一周内部署上线。
Asana
借助 Managed Agents 构建了 AI Teammates 功能,让 AI 协作者直接在项目里承接任务、起草交付物,显著加速了高级功能的开发速度。
Vibecode
将 Managed Agents 作为默认集成,让用户从一句 prompt 出发,直达部署完成的应用,成为平台的核心基础设施。
定价:怎么算钱
Managed Agents 采用纯按量计费,没有平台订阅费,两个维度叠加:
Token 费用与 Claude Platform 标准 API 费率相同,按所用模型单独计价。例如 Claude Sonnet 4.6 输入 $3 / 百万 token,输出 $15 / 百万 token。
会话运行时费用为 $0.08 / 活跃会话小时,仅对运行中的会话计费,替代了原来的容器小时费,两者不重复收取。
💡 以官方例子估算:
一个使用 Claude Opus 4.6、运行 1 小时、消耗 5 万输入 token + 1.5 万输出 token 的编程 Agent,如果启用提示词缓存(4 万 token 命中缓存),总费用约 $2–3 美元(会话费 $0.08 + token 费)。高频大批量场景可联系企业销售团队谈定制价格,也可申请批量折扣。
谁能用?个人开发者可以用吗
个人开发者和企业都可以用,入口是 Claude Platform API,不需要企业账号。
个人开发者和小团队注册 Claude Platform(platform.claude.com)、申请 API Key 后即可使用,按量付费,没有最低消费门槛,也可以通过 Claude Console 管理团队用量和预算。企业或大规模部署场景同样走标准 API,或联系销售团队申请定制价格和更高速率限制。
多 Agent 协调和自我迭代两个功能目前处于研究预览阶段,需要在官网单独提交申请,审核通过后才能访问。
⚠️ 注意:
Managed Agents 通过 Claude Platform API 调用,不包含在 Claude Pro / Max 订阅套餐内。自 2026 年 4 月 4 日起,Claude 的订阅套餐已不再支持第三方 Agent 框架调用,使用 Managed Agents 需要单独在 API 端按量付费。
框架总会过时
要理解托管智能体,先要理解一个工程困境:给 AI 写的"运行框架"(harness,即包裹模型运行的脚手架代码),本质上是在记录"模型做不到什么"。
但模型一直在变强。假设今天写入框架的限制,明天可能已经不存在了——而旧代码还在那里,默默地做着多余的事。
💡 举个例子:
Claude Sonnet 4.5 会在感知到上下文快满时提前收尾任务,工程师为此加了"上下文重置"机制。等 Claude Opus 4.5 上线,这个问题消失了,但重置代码还留着,成了"死代码"。
Anthropic 为此参考了操作系统的设计思路:把底层硬件抽象成"进程""文件"等稳定接口,让上层程序不必关心底下跑的是 1970 年代的磁盘还是现代固态硬盘。托管智能体做的是同一件事——把智能体的各个部件抽象成稳定接口,框架可以换,模型可以升级,接口本身不动。
三个部件,各自独立
托管智能体把一个智能体拆成三个相互解耦的部分:
会话 (Session)
所有事件的只追加日志,类似"黑匣子"。它独立于其他一切存在,框架崩了、沙箱挂了,日志都在。
框架 (Harness)
负责调用 Claude 并把工具请求路由出去的循环逻辑。它是完全无状态的,自身不保存任何东西。
运作方式:
- 崩了之后,新框架用 wake(sessionId) 重启
- 再用 getSession(id) 从会话日志里取回完整的事件记录
- 从最后一条事件处接着跑
- 运行过程中,框架持续用 emitEvent(id, event) 向会话日志写入记录,确保每一步都有据可查
换句话说: 框架和容器一样,都成了栓口——挂了就换一个,接上日志继续跑,什么都不会丢。
沙箱 (Sandbox)
Claude 执行代码、编辑文件的隔离环境(与主系统隔离、防止恶意代码扩散的执行空间)。框架不关心沙箱是什么,只管发指令、收结果。
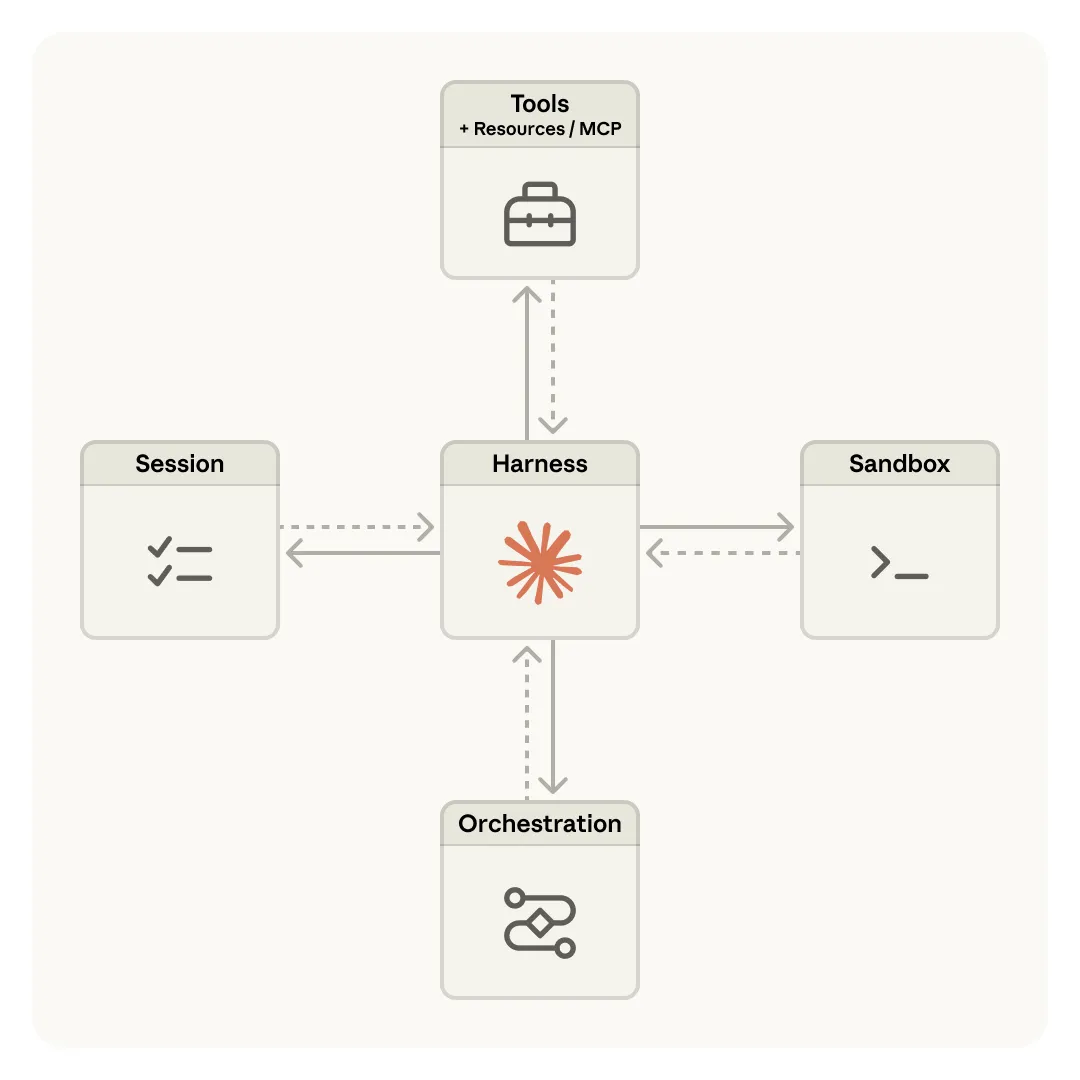
▲ 会话、框架、沙箱三者解耦后的架构关系
不要养宠物
云计算里有个经典比喻:宠物 vs 牲口。宠物是有名字、需要精心照料的个体,生病了要全力抢救;牲口则是可互换的,挂了一头就换一头。
旧框架里,把所有组件塞进一个容器(container,一种轻量级软件打包方式),就是在养宠物。这带来了两个问题。
问题一:没法调试
容器一挂,会话就丢了;容器卡死,唯一的观察窗口是 WebSocket 事件流,但它根本分辨不出是框架的 bug、网络丢包,还是容器离线——三种故障看起来一模一样。
工程师必须进入容器内部开 shell 才能查,但容器里往往存着用户数据,这种操作意味着实际上失去了正常调试的能力。
问题二:没法接入客户的私有云
框架假设 Claude 操作的所有资源都在容器旁边。当客户希望把 Claude 连到他们自己的私有云时,只有两条路:
- 要么把他们的网络和 Anthropic 的网络对等互连
- 要么在他们自己的环境里跑 Anthropic 的框架
两条路都很痛。一个写进框架里的假设,变成了对外扩展的一堵墙。
解耦之后的改变
容器变成了牲口。挂了就换一个,框架把故障当作普通的工具调用错误捕获并回传给 Claude,让 Claude 自己决定要不要重试,新容器用标准方法重新初始化即可。
私有云的问题也随之消失——框架不再住在容器里,它调用任何资源的方式都是一样的,不需要假设资源在哪里。
安全边界:令牌不进沙箱
旧架构里,Claude 生成的代码和服务凭证住在同一个容器——提示词注入(prompt injection,攻击者在模型处理的内容里嵌入恶意指令)攻击只需说服 Claude 读一下自己的环境变量,就能拿到所有权限。
新架构的修复是结构性的:凭证永远不出现在沙箱里。Git 令牌在初始化时消费掉,第三方工具的 OAuth 令牌(代表用户访问外部服务的授权凭证)存在沙箱外的保险库,Claude 调用工具走专用代理,框架始终看不到任何密钥。

▲ 框架与沙箱解耦后,凭证不再进入沙箱的安全架构
会话 ≠ 上下文窗口
上下文窗口(context window)是模型单次推理能"看到"的最大文本量,就像短期记忆。长任务必然会撑破它,而传统应对手段——压缩、裁剪——都是不可逆的,删了就找不回来。
传统方案的局限
学术界曾提出过一个方向:把上下文存成一个对象放在 REPL(交互式运行环境)里,让模型通过写代码来过滤和切片它,而不是直接塞进上下文窗口。
这样上下文就活在窗口之外,不会被截断。但这种方式依然依赖沙箱或运行环境本身,一旦环境崩溃,上下文就跟着消失了。
托管智能体的解决方案
托管智能体的会话日志解决了这个问题。上下文不放在沙箱或 REPL 里,而是持久化存储在独立的会话日志中。框架和沙箱的生死与它无关。
通过 getEvents() 接口,框架可以按位置切片读取事件流——从上次停止的地方继续、回滚几条重看上下文、或者在执行某个关键操作前重新刷新相关背景,都可以按需取用,原始记录永远不会因为压缩而丢失。
职责分离的设计哲学
还有一点值得注意:取出的事件在传入 Claude 的上下文窗口之前,可以由框架做任意转换处理——包括内容重组、缓存优化等。
Anthropic 把"上下文存哪里"(会话的职责)和"上下文怎么用"(框架的职责)分开,正是因为无法预测未来的模型需要怎样的上下文工程策略。
会话只保证数据在,具体怎么喂给模型,由框架说了算。
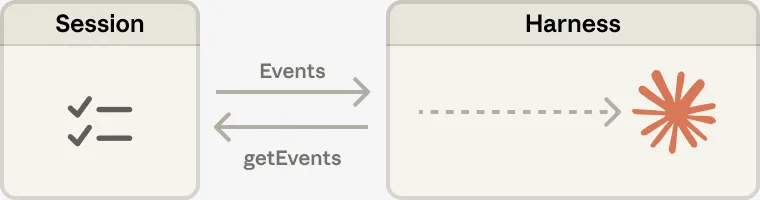
▲ 会话日志持久存储在上下文窗口之外,框架按需取用
首 token 延迟降了 90%
旧框架的性能瓶颈
旧框架构里,大脑住在容器里,意味着多少个大脑就需要多少个容器。每个会话在容器完成预热之前无法开始推理,哪怕这个会话根本不需要用沙箱,也得老老实实等着容器启动、克隆仓库、拉取待处理事件——全程空等,推理一行都不能开始。
解耦后的性能提升
解耦之后,容器只在真正需要时才由框架按需创建。框架从编排层拉到会话日志里的待处理事件,立刻就能开始推理,不等任何东西。
结果是:
📊 p50 首 token 延迟(TTFT,从接受任务到产出第一个字的等待时长)下降约 60%
📊 p95 延迟(接近最慢那批的延迟指标)下降超过 90%
扩展到多个大脑只需启动多个无状态框架实例,按需连沙箱,互相之间完全独立。
多个大脑,多双手
扩展到多个大脑只需启动多个无状态框架实例,沙箱按需连接。每双"手"都是同一个接口:execute(name, input) → string。不管后面接的是容器、手机还是其他什么,框架一概不知,也不需要知道。大脑之间还可以互相传递手,协作执行复杂任务。
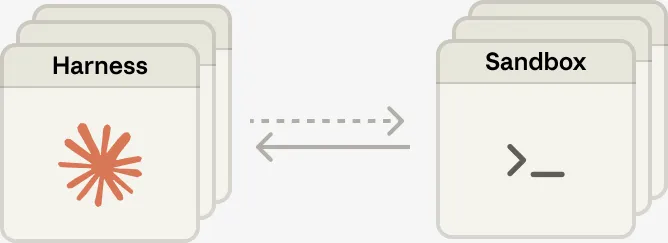
▲ 多个无状态框架实例(大脑)按需连接沙箱(手)
小结
托管智能体解决的,是一个计算机科学里的老问题:如何为"尚未构想出的程序"设计系统。操作系统的答案是定义稳定的抽象接口,让底层实现自由替换。
Managed Agents 是同一精神下的"元框架"——它对某些事情有强烈主见:Claude 将需要操控状态(会话)和执行计算(沙箱)的能力,也将需要扩展到多个大脑和多双手的能力,这些接口必须能长期可靠、安全地运行。
但它对另一些事情完全没有主见:具体要用什么框架、需要多少个大脑、沙箱部署在哪里、手连着什么——这些它一概不假设,留给未来的实现去决定。
这是关键的区分。接口的形状固定下来,接口背后的实现保持开放。模型变强了,框架随之升级;客户的基础设施换了,沙箱随之替换;Anthropic 自己的实现变了,对外的接口不动。
这可能是 AI 基础设施走向成熟最重要的一步。
🌟延伸阅读:
想了解 Anthropic 托管智能体的技术细节,可以阅读官方工程博客:
https://www.anthropic.com/engineering/managed-agents
如果你对 AI 和 AI 金融领域的干货内容感兴趣,欢迎关注我们,我们会持续分享相关资讯和深度解读。
