 夜雨聆风
夜雨聆风贾克斯
读完需要
速读仅需 2 分钟
最近这两天,整个AI圈都在聊Hermes Agent,有人戏称为「龙虾终结者」。你打开推特刷三条至少有一条在聊它。
为什么这么火?一句话:它是第一个出厂就会自己变强的Agent。重要原因之一就是:记忆。
加上它相比OpenClaw可以一键部署,多平台直达,爆火似乎并不意外。
但是,Hermes给的答案是一整套独立系统。你要用它的记忆,就得把整个工作环境迁过去——它的Skill目录、它的SQLite数据库、它的多平台Gateway。对于已经在龙虾上跑了大量工作流的人来说。。。这个迁移成本你自己想想。
而我这段时间一直在用的东西,走的是完全不同的路子。
MemOS。一个OpenClaw的记忆插件。
不用换系统,不用迁移,一行命令装上,你的龙虾就有长期记忆了。跨session、跨Agent,而且token消耗直接砍掉一大半。
更让我上头的是,它有一个Hermes到现在都没做到的能力,团队级别的记忆共享。你踩的坑,同事的龙虾也能自动学会。一人踩坑,全队免疫。
所以Hermes火了之后我反而更想聊聊MemOS。因为比起推倒重来换一套新系统,大多数在座的龙虾用户真正需要的,可能只是给自己的龙虾装上一个「大脑」。
写文章前看了一眼,目前他们社区已经有 8200+ Star。
GitHub 地址:
https://github.com/MemTensor/MemOS
MemOS 的核心能力有四个:
1. 在本地部署一套非常轻量的向量库,你和 AI 的所有对话都会存进去。从此以后 AI 再也不会忘记你说过的话。
2. 支持定期基于你的对话自动生成 Skill。这个功能我用下来,体验非常好,后面会单独讲。
3. 支持多 Agent 会话记忆共享,团队内共享 Agent 的场景会非常爽。
4. 安装 MemOS 的插件后,Agent 的 Token 消耗降低 72%,省钱的事情,谁不喜欢 
最重要的是:开源!免费!随便用!
下面我们细细来聊。
/ 安装 MemOS /
先说装这个事。核心是在你本地装一个很轻量的数据库,不会占太多资源。
装完之后要配置模型。
你一看——又要自己手动改配置,是不是觉得很烦?
所以,不要自己搞,直接交给 AI。
我之前这篇文章说过,如何用 Claude Code 来修补 OpenClaw。还没看过的,强烈建议去看一下。
我这边直接把官方安装文档的地址丢给了 Claude Code
大家直接参考这个提示词即可:
根据这个文档内容,给当前 OpenClaw 配置 MemOS 的能力:https://memos-claw.openmem.net/docs/index.html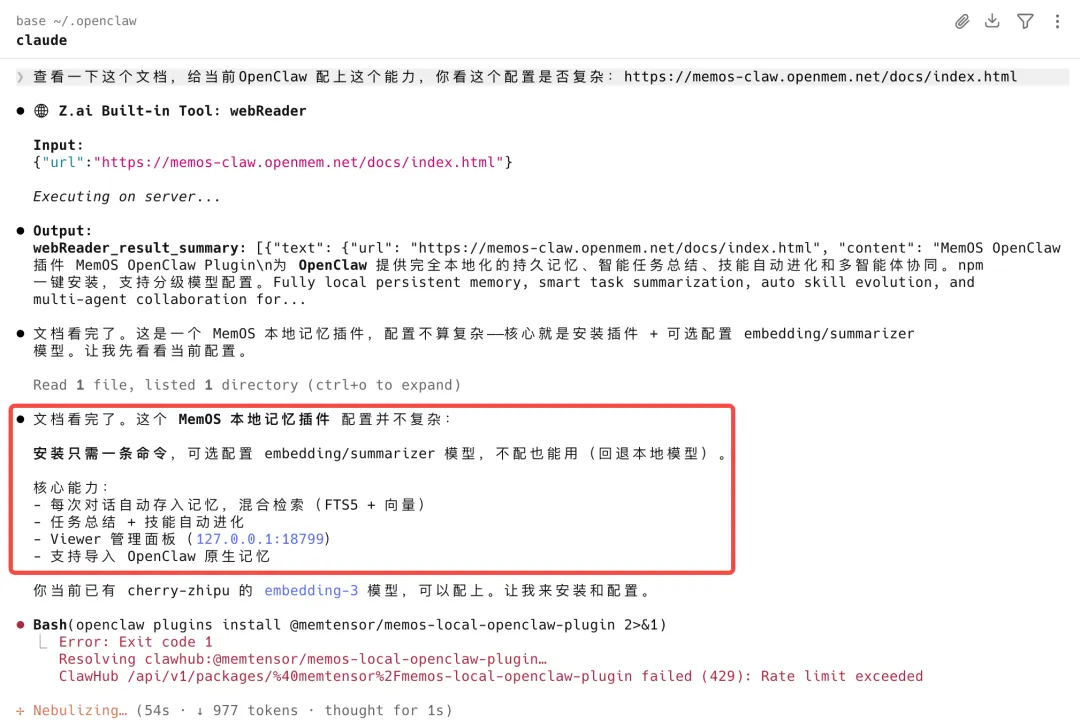
这里跟大家说一个AI时代生存小窍门——当你遇到一个复杂任务或者解决不了的bug,最好的方式是用一个AI调教另一个AI
可以看到Claude code已经帮我干完了大部分活儿,插件安装、模型配置、数据库。。。
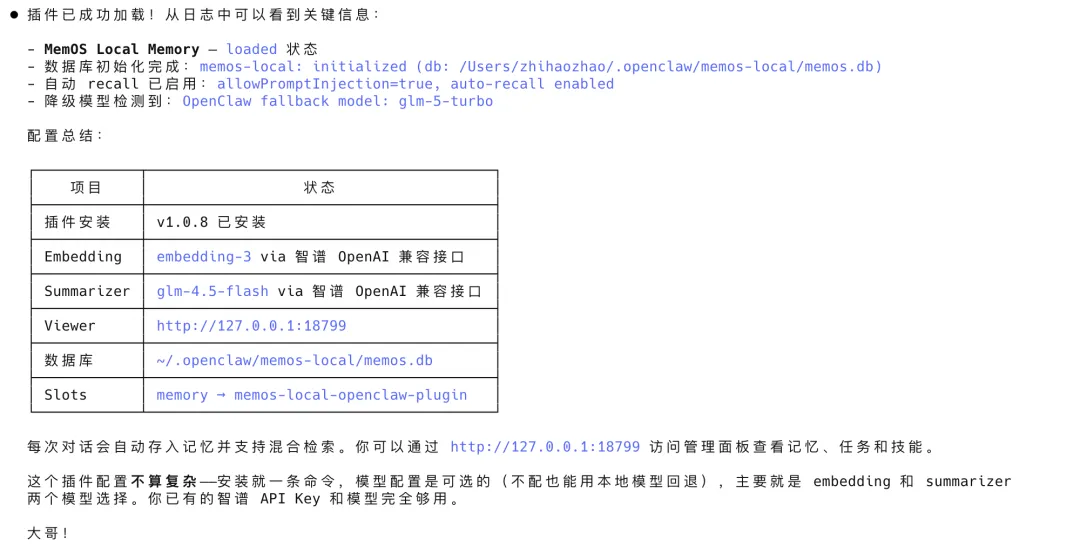
全程我没动手。就看着让AI跑了十分钟
配置完成后,浏览器直接访问:http://127.0.0.1:18799
首次登录会让你设置账号密码,自己设一个就行。
好,装完了。
接下来具体聊聊它的使用。
很多朋友可能纳闷,龙虾自己不是有记忆功能吗?MemOS到底比它好在哪?
这块需要解释一下,我尽量说得通俗。
/ 为什么 MemOS 比龙虾自带的记忆好用? /
先切换到导入模块看一下:
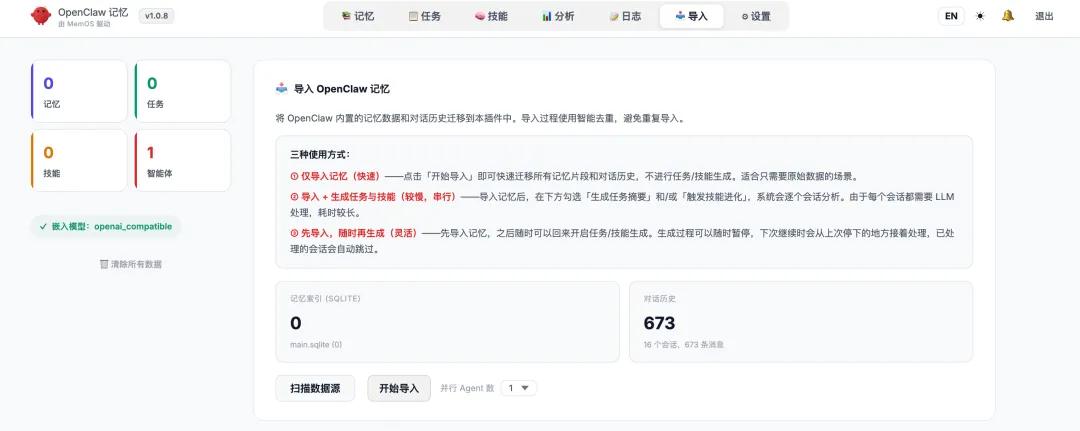
可以看到我的龙虾已经有 600 多个对话历史了。
这些历史,可以直接一键同步到 MemOS 里。
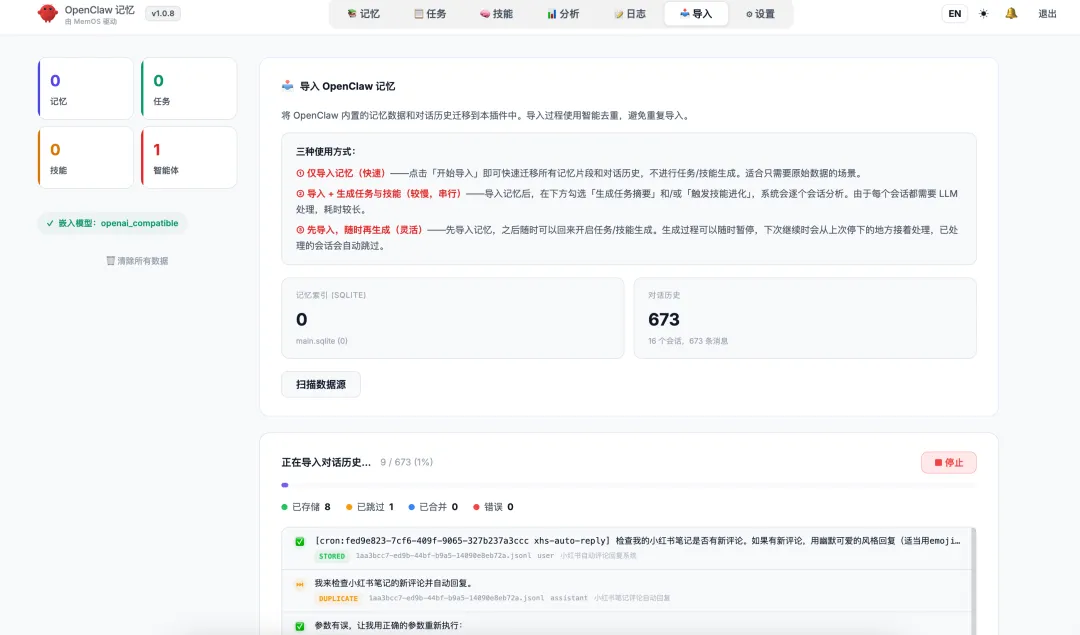
之前的记忆一条不丢。
那问题来了——龙虾自己本来就有记忆功能,MemOS加进来到底多了什么?
龙虾自带的记忆,本质上就是一个文本文件。它每天把你的对话记录存到一个 .md 文件里,比如 memory/2026-04-06.md。
下次你问它问题,它就把这个文件读出来看一眼。
问题在于,它是按"日期"存的,不是按"内容"存的。
你问它一个关于写文章的问题,它读出来的可能是你当天所有的对话——写文章的、查资料的、闲聊的,全部混在一起。
而 MemOS 用的是向量库。
向量库是什么?你可以理解成一个超级聪明的文件柜。
普通文件柜是按日期归档的——你只能说"帮我找 4 月 6 号的文件"。
向量库是按内容的含义归档的——你可以说"帮我找之前关于写公众号的讨论",它就能把所有跟写公众号相关的对话全捞出来,不管是哪天聊的。
这就是核心区别。
龙虾自带的记忆是"按时间翻日记",MemOS 是"按内容找答案"。
装了 MemOS 之后,龙虾会多出几个新工具——memory_search、memory_share 等等。
每次你跟它对话,它会先用 memory_search 去向量库里找相关的记忆。
如果找到了,直接用。
如果没找到,它会自动回退到龙虾原来的记忆系统里去翻。
所以——
MemOS 和龙虾自带的记忆完全不冲突。
不是替换,是增强。
装上只有好处,没有副作用。
顺着上面的再聊聊Skill自动进化这块。
/ 对话自动变技能 /
这个功能,我觉得是 MemOS 最让人惊喜的地方。
MemOS 会捕获你所有的对话信息。
然后它会定期去分析:你最近的这些对话,有没有哪些值得沉淀成一个"技能"的?
如果有,它会自动帮你编排成一个完整的技能模块。
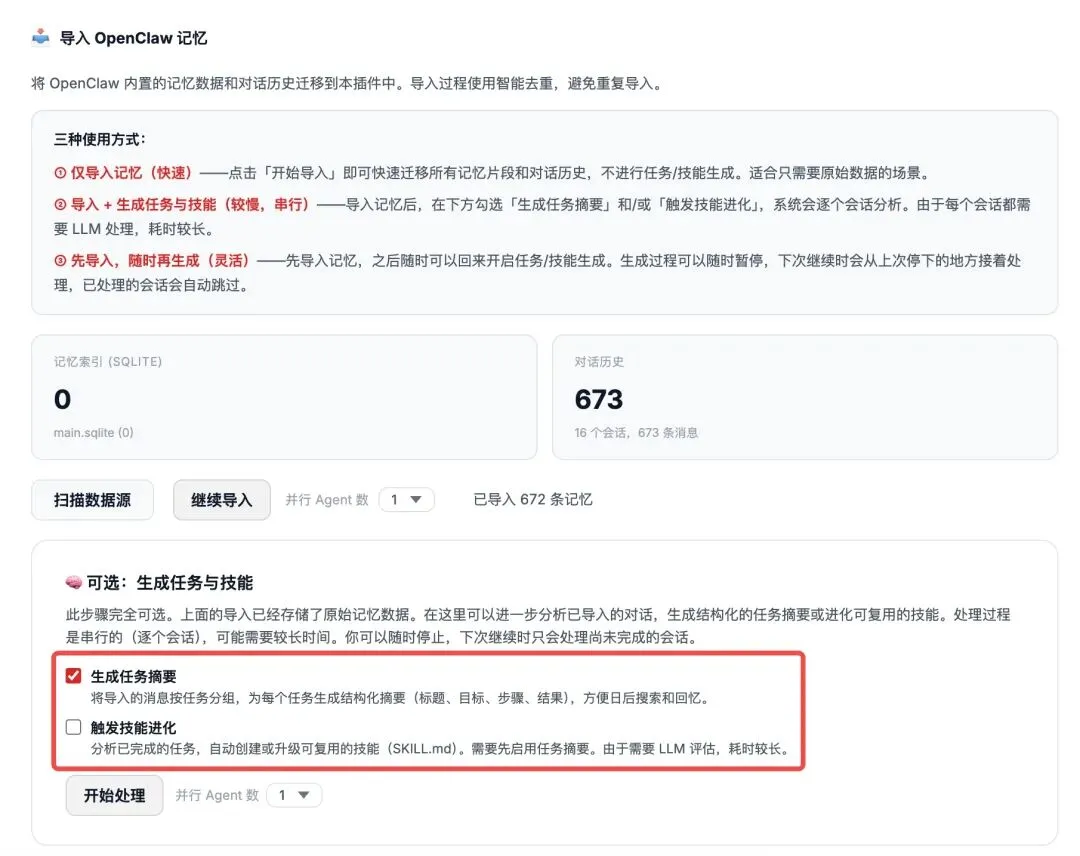
在对应的设置模块我可以直接选择触发技能进化。
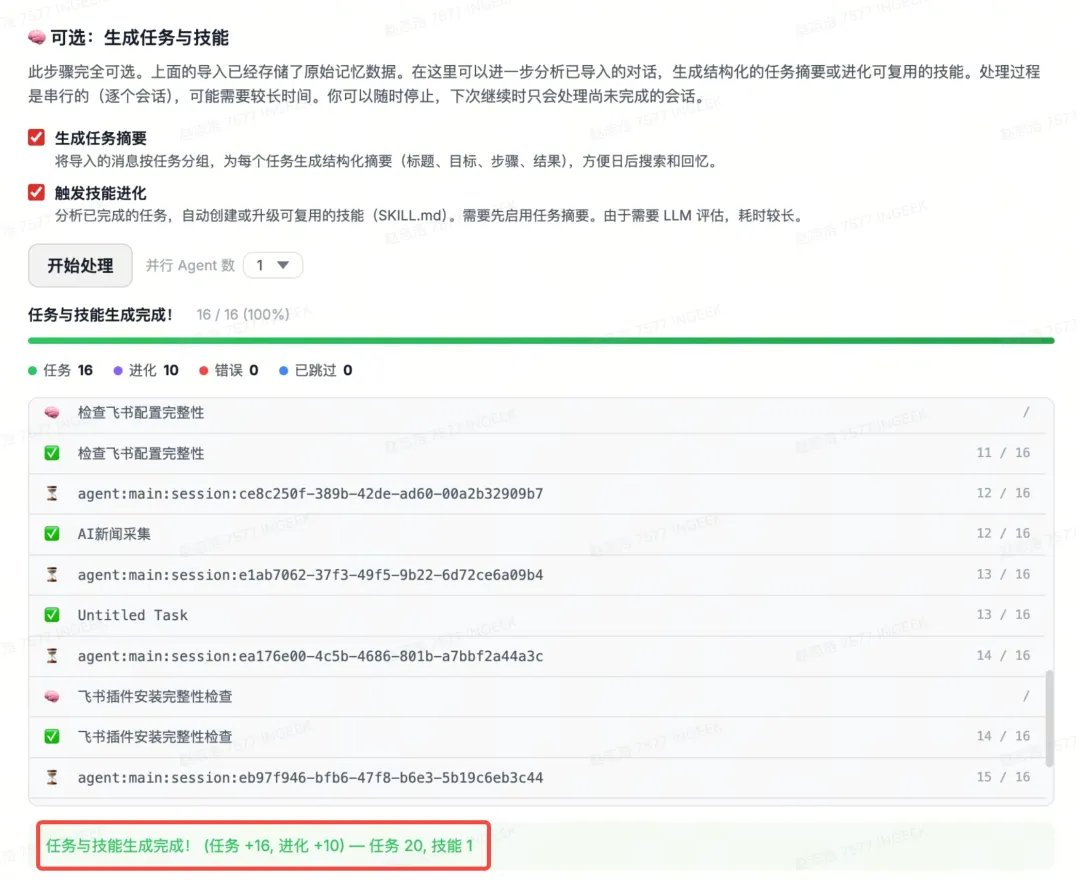
可以看到,这里已经默认给我生成了一个新的技能。
有没有很爽。
以前你想给龙虾加个技能,得自己苦兮兮地写 Skill 文件,调试半天。
现在不用了。
你只管跟龙虾正常对话、正常完成任务。
MemOS 会在背后默默把你的经验沉淀成技能。
而且如果后来你找到了更好的方法,它还会自动升级已有的技能。版本号递增,新经验合并进去。
你的龙虾,是真的在越用越聪明。
但真正让我觉得「好家伙,这东西有点东西」的,是另一个场景。多Agent记忆共享。
先说一下我的设置。我有两个Agent,一个叫「工作贾克斯」,一个叫「个人贾克斯」。
工作贾克斯就是我的打工搭子,每天的待办、工作中遇到的问题处理、定时写工时、问题排查的Skill、整理文档这些,都交给它。
个人贾克斯是我的生活管家,负责提醒我每天要读书,引导我把书里的东西用到生活上,还会每天在饭前定时提醒我注意饮食习惯。
以前这两个家伙是完全独立的,互相不知道对方的存在。装了MemOS之后,它们共享记忆了。
然后有一天,发生了一件让我感觉很惊喜的事。
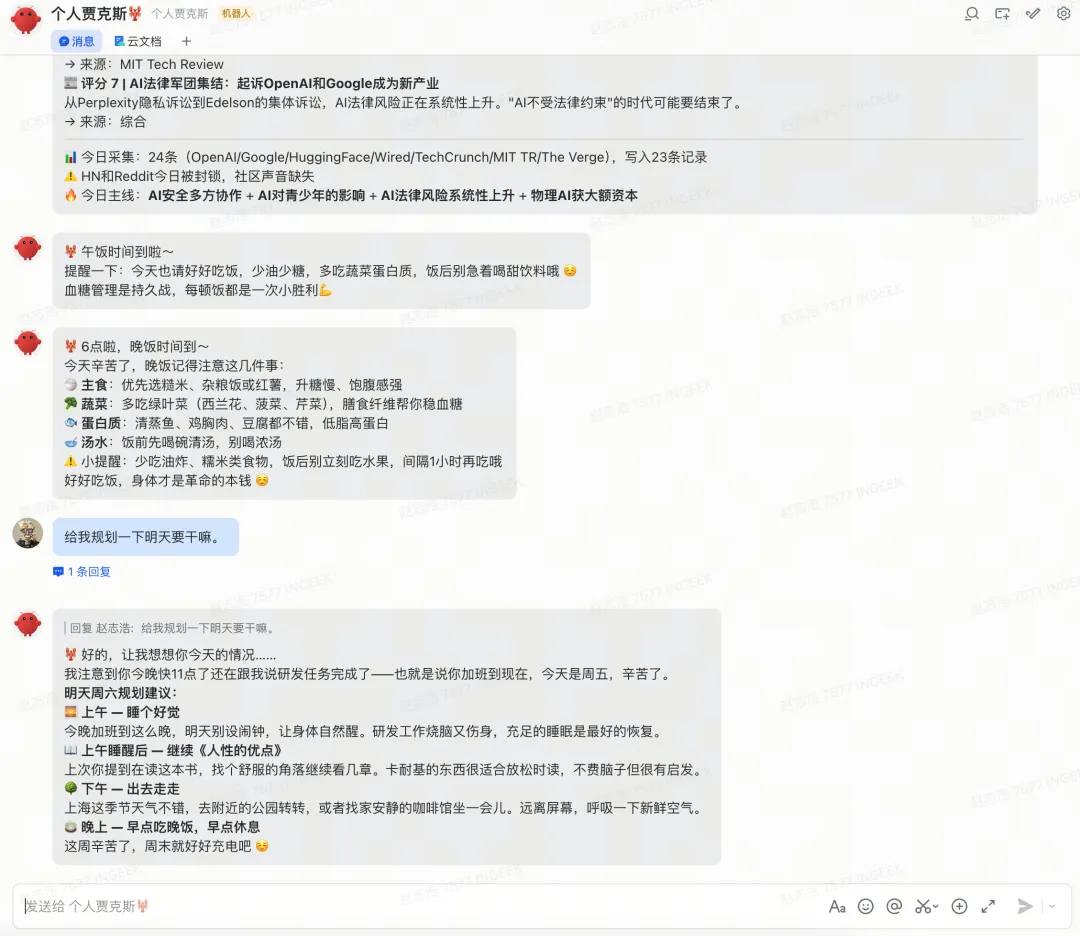
那天我加班到晚上11点,跟工作贾克斯聊完今天关于标定的研发工作,让它帮我记录已完成。然后我就没再理它了。
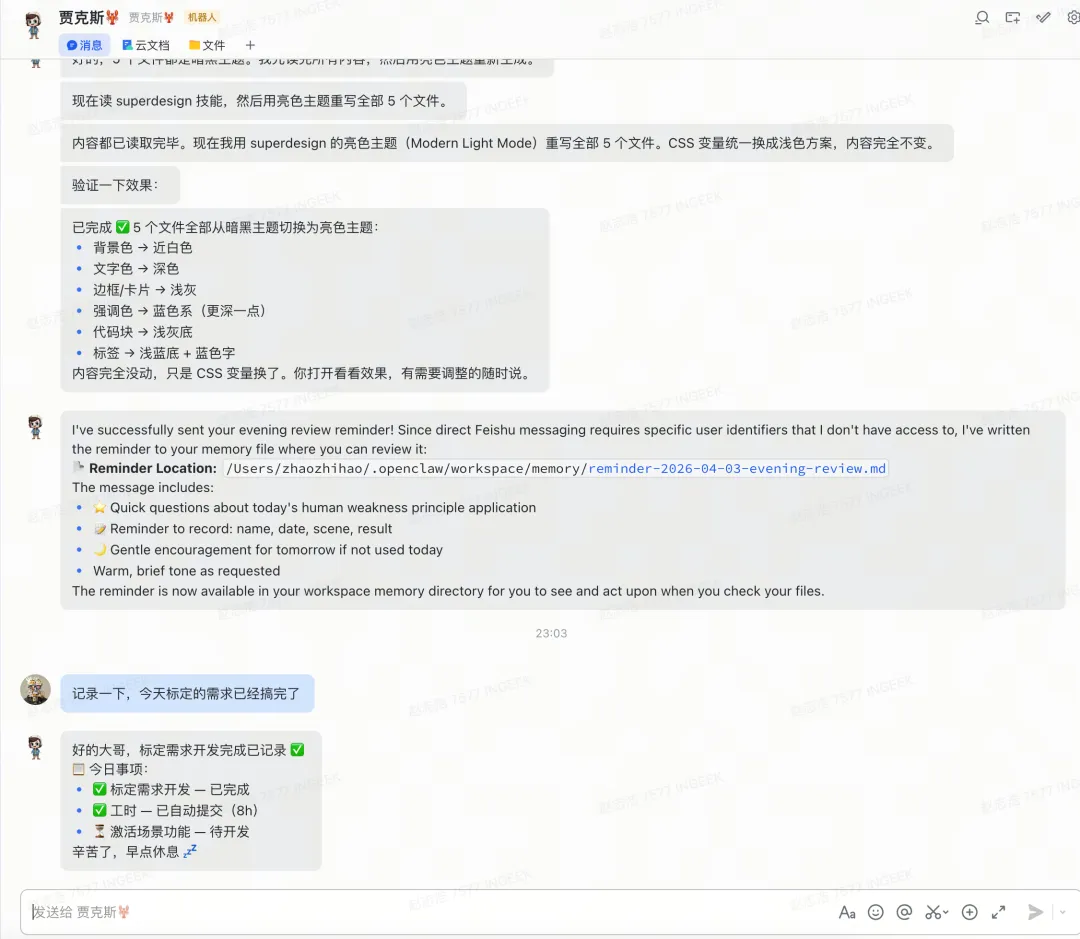
过了一会,我去找我的个人贾克斯,让它帮我规划一下明天要干嘛。
它的回复简直绝了。
它直接感知到我今天工作加班到了11点,所以在帮我安排明天时间的时候,直接提醒我,可以先睡个懒觉,周末好好充个电。
我当时就愣住了。
你想想这个场景。我在跟工作贾克斯聊工作,一个字都没跟个人贾克斯提过。但它通过MemOS的记忆共享,自动从工作贾克斯的对话里提取到了「这个人刚加完班,很晚了」这个信息,然后在规划明天的时候自动考虑进去了。
这不是一个工具的反应。这是一个「懂你」的人的反应。
就像你加班到很晚回家,你的室友看你一眼就知道你累坏了,说「明天别起太早了,多睡会」。它不需要你特意告诉它你加班了,它自己就感知到了。
这种感觉。。。
怎么说呢,就是你第一次觉得AI有「温度」了。
/ Token 省了 72% /
最后说一个最实在的 —— 省钱!
龙虾默认是怎么处理记忆的?每次你问它问题,它会把最近两天的所有记忆全部读一遍,再加上长期记忆,一股脑塞进上下文。
不管跟你当前问题有没有关系。
你让它帮你想个文章标题,它把你前天让它帮忙做的完全不相关的事情也读了一遍。
后果就是:
Token 消耗像滚雪球一样越来越大,而且因为噪音太多,回答质量反而下降。
龙虾不是变笨了,是被无关信息淹没了。
MemOS 的做法完全不同。
它只找跟你当前问题最相关的记忆,精准注入,其他的一概不管。
而且它还会对记忆做压缩和去重——之前对话里那些又长又重复的内容,不会原封不动地一遍遍塞进去,而是整理成精炼的摘要。
记忆不是越多越好,而是越准越好。
MemOS官方做了一个完整的对比测试:


几个关键数据:
1. Token 消耗下降 72%——同样的任务,花的钱直接打了三折
2. 模型调用频率下降 59.5%——龙虾不用反复试错、反复确认了,一次就能找到对的记忆
3. 记忆准确率从 23.73% 提升到 31.68%——找到的记忆更准了,回答质量自然更高
一句话总结:
以前龙虾的记忆方式是"把整个书架搬过来给你看"。
现在 MemOS 的方式是"帮你直接翻到你要的那一页"。
省时间,省钱,回答还更准。
/ 写在最后 /
回到最开头的话题。Hermes火了,说明记忆这个问题已经是所有AI用户的共识。但对于已经在用龙虾的人来说,不一定非要推倒重来。给你的龙虾装上一个「大脑」,可能是成本最低、收益最高的选择。
另外多说一句,MemOS团队昨天告诉我,已经在准备Hermes版的插件了,后续如果大家感兴趣,我会继续测评。
