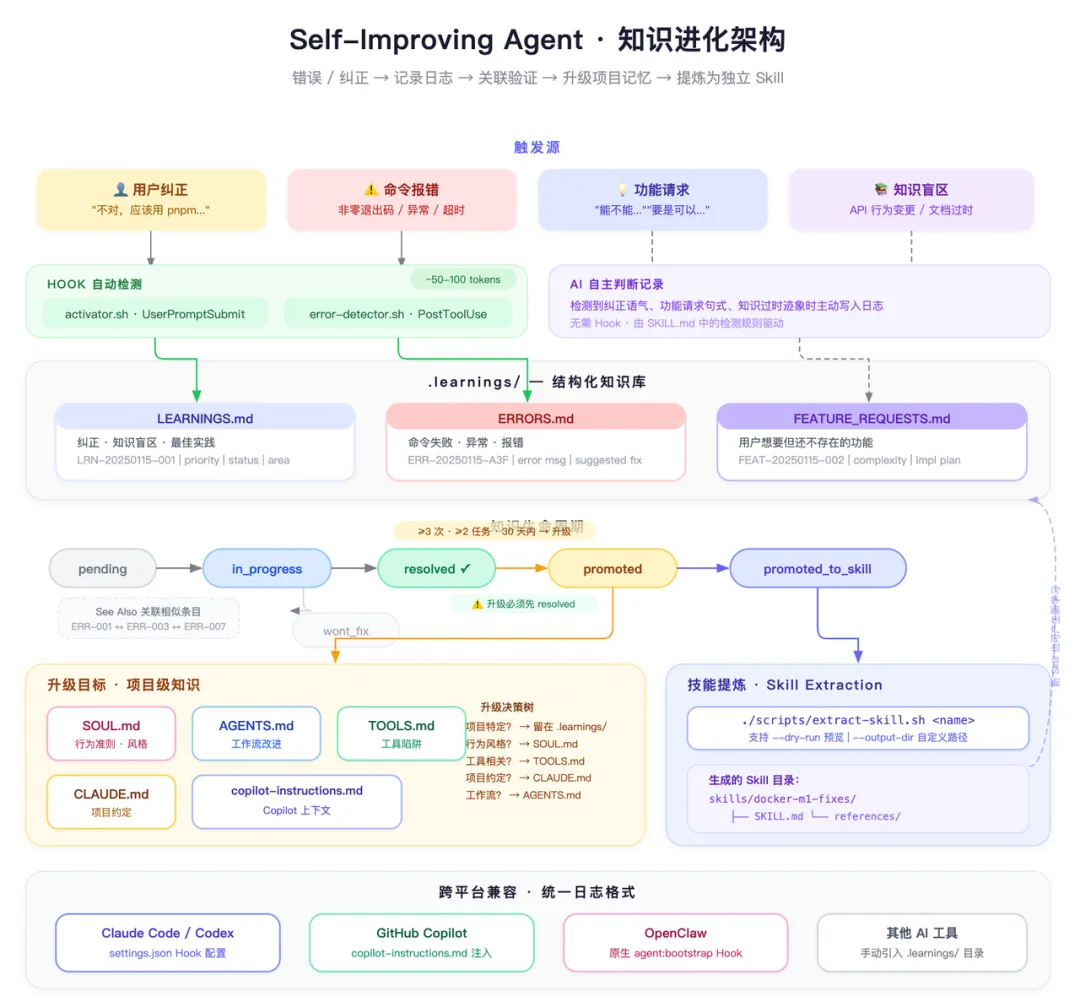
通过非模型手段提升模型效果,是最近讨论最多的话题。Meta 最新的 Harness 架构进化、Harness Engineering 的兴起,都在指向同一个方向 —— 怎么让系统自动进化。经常用Claude Code、Openclaw这类 AI 工具的,一定遇到过这样的场景:- AI 犯了一个错误,你纠正了它,下次它又犯同样的错误
- 一个命令报错了,AI 花了很长时间才定位到原因,但这个教训没有被记住
- 你告诉 AI "这个项目用 pnpm 不用 npm",下次对话它又跑去用 npm
AI 不会从错误中学习。 self-improving-agent 正是为了解决这个问题而生 —— 一套结构化的学习日志系统,让 AI 编程助手能够记录错误、纠正和发现,并在未来的会话中复用这些知识,实现真正的持续改进。整个 skill 的核心是三个 Markdown 日志文件,存放在 .learnings/ 目录下:每条日志都有标准化的格式,包含时间戳、优先级、状态、分类、上下文和建议修复方案。举个例子:[ERR-20250115-A3F] docker_build
Logged: 2025-01-15T09:15:00Z
Priority: high
Status: pending
Area: infra
Summary
Docker build fails on M1 Mac due to platform mismatch
Error
error: failed to solve: python:3.11-slim: nomatchfor platform linux/arm64
Suggested Fix
Add platform flag: docker build --platform linux/amd64 -t myapp .
结构化的好处是:可搜索、可关联、可升级。不是随便写几行备注,而是一套可以被程序化处理的知识库。self-improving-agent 设计了一条完整的知识进化链路:错误/纠正 → 记录日志 → 关联相似条目 → 升级到项目记忆 → 提炼为独立 Skill通过 Hook 脚本,skill 可以自动感知两类事件:- UserPromptSubmit Hook(activator.sh):每次用户提交 prompt 后,注入一段 <self-improvement-reminder>的提醒文本,让 AI 评估是否有值得记录的知识。
- PostToolUse Hook(error-detector.sh):监听 Bash 命令执行结果,当检测到错误模式(如 `error:`、`Traceback`、`Permission denied` 等 16 种模式)时,提醒 AI 记录错误,然后用 Edit 工具手动写入 .learnings/ERRORS.md
这些 Hook 的开销很小,每次只注入约 50-100 个 token。脚本本身只做一件事 —— 输出一段提醒文本,不修改 AI 行为,不拦截操作,不增加显著延迟。- 当达到阈值(同一模式出现 3 次以上,跨 2 个以上任务,30 天内)时,升级为永久项目知识
举个实际的例子 —— Payment API 超时问题被记录了 3 次,每次都通过 See Also 相互关联:### Metadata
- Reproducible: yes
- See Also: ERR-20250110-001, ERR-20250112-003, ERR-20250114-007
当关联条目积累到阈值,就触发升级。升级到哪里?skill 给出了一棵清晰的决策树:该知识是否项目特定?
├── 是 → 留在 .learnings/
└── 否 → 是否行为/风格相关?
├── 是 → 升级到 SOUL.md(如:"回复要简洁,不要加免责声明")
└── 否 → 是否工具相关?
├── 是 → 升级到 TOOLS.md(如:"git push 前要先配置 auth")
└── 否 → 是否项目约定?
├── 是 → 升级到 CLAUDE.md(如:"包管理器用 pnpm 不用 npm")
└── 否 → 升级到 AGENTS.md(如:"长任务要拆分子 agent")
当一个 learning 足够通用、足够有价值时,可以提炼为独立的 skill:# 先预览会创建什么
./scripts/extract-skill.sh docker-m1-fixes --dry-run
# 确认后正式创建
./scripts/extract-skill.sh docker-m1-fixes
这会自动生成 skill 目录结构和模板文件。一个曾经的 bug 修复记录,就变成了一个可复用、可分发的知识模块。原始 learning 条目的状态也会更新为 `promoted_to_skill`,并记录 `Skill-Path`,形成完整的溯源链路。pending → in_progress → resolved → promoted → promoted_to_skill
↘ wont_fix
- resolved — 问题已解决,方案已验证 ⚠️ 这是升级的前提条件
- promoted — 已写入 CLAUDE.md / AGENTS.md / SOUL.md 等项目级文件
- promoted_to_skill — 已提炼为独立 skill
关键点:只有 `resolved` 状态的 learning 才能被升级。未经验证的知识不会污染项目配置。每条记录都有统一的 ID 格式(LRN-20250115-001)、优先级、状态、区域标签。这不是给人看的笔记,而是给 AI 消费的结构化数据。学习不是一步到位的。一条 pending 的错误记录,随着被反复遇到,会逐步升级:pending → 关联相似条目 → 提升优先级 → promoted(写入 CLAUDE.md)→ promoted_to_skill不绑定特定的 AI 工具。Claude Code、Codex、GitHub Copilot、OpenClaw —— 都能用。不同平台有不同的接入方式,但日志格式是统一的。Hook 脚本只做一件事:在合适的时机注入一段简短的提醒文本。不修改 AI 的行为,不拦截任何操作,不增加显著延迟。clawdhub installself-improving-agent
git clone https://github.com/peterskoett/self-improving-agent.git ~/.openclaw/skills/self-improving-agent
然后在 .claude/settings.json 中启用 Hook:{
"hooks": {
"UserPromptSubmit": [{
"matcher": "",
"hooks": [{
"type": "command",
"command": "./skills/self-improvement/scripts/activator.sh"
}]
}],
"PostToolUse": [{
"matcher": "Bash",
"hooks": [{
"type": "command",
"command": "./skills/self-improvement/scripts/error-detector.sh"
}]
}]
}
}
我自己用了一段时间,但是还没有明显感觉到对我自己的claue、openclaw的改善,有好的实践结果的也欢迎在评论区一起讨论!!!! 夜雨聆风
夜雨聆风