 夜雨聆风
夜雨聆风最近在技术架构、AI商业化甚至是投资圈,AI Agent(智能体)以及底层推理模型(Reasoning Models)可以说是红得发紫。大家都在谈论大模型怎么颠覆软件工程、Agent怎么实现自主闭环。但如果你去问真正靠API跑核心业务的研发总监或企业CFO,他们大概率会大吐苦水:大模型这玩意儿,简直就是吞噬企业预算和算力资源的黑洞。
当我们在前端看着AI聪慧地自我纠错、连续运行几千步操作时,后台的财务报表里却出现了一个极其诡异的现象:明明选了API标价最便宜的模型,跑下来的总账单反而比用昂贵旗舰模型还要高出好几倍。感觉就像是你为了省钱雇了一个号称时薪极低的“廉价劳动力”,结果他磨洋工花了一个月,不仅没省钱,还把你吃破产了。
这篇文章,我们就来抽丝剥茧地聊聊2026年之后,由斯坦福等机构提出的 “价格倒挂(Pricing Reversal)” 现象,以及为了填补这个无底洞,底层的 MoE架构 与 L2A(条件内存访问) 技术到底在经历怎样硬核的“极限压榨”。这背后揭示的算力与生态演进哲学,跟我们每一个做商业化和技术架构的人都有着极其致命的关系。
现行大模型计费架构的死穴:被反噬的“思考Token”与不可预测的方差
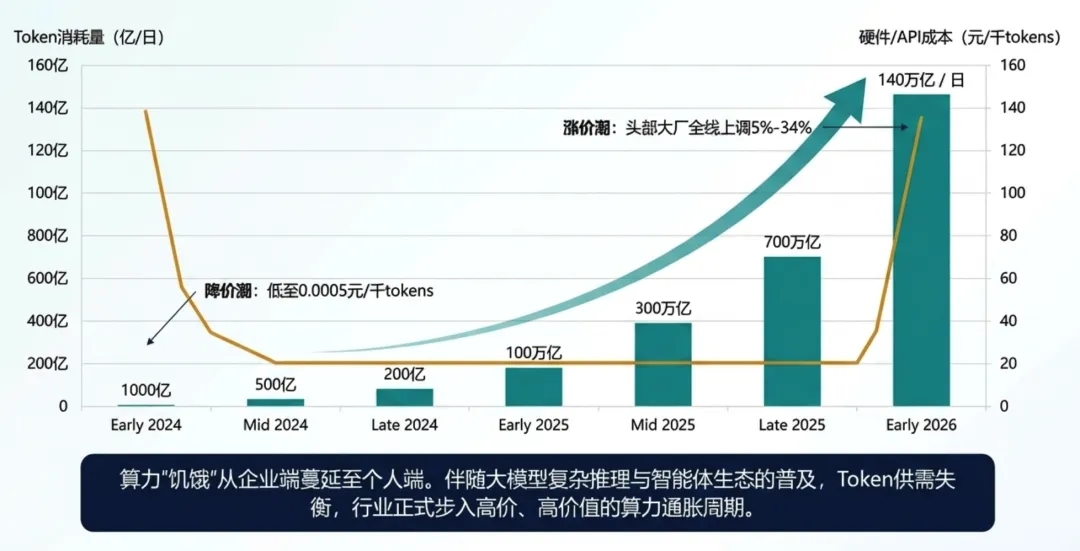
过去两年,业界形成了一个黄金标准:按模型标价(API Pricing)来评估业务成本。对于传统的问答模型,这套架构简直完美。但一碰到2026年全面普及的带有深度思考能力(Reasoning)的模型,它立刻就暴露出了一个致命的“死穴”。
在AI深度推理的逻辑下,系统后台会产生海量隐藏的“思考Token(Thinking Tokens)”。斯坦福与伯克利在2026年的联合研究中发现了一个残酷真相:在高达21.8%的模型对比中,标价更低的模型实际总花费却更高,最大反转幅度甚至达到28倍。
这就导致了一个极其滑稽的局面:你的团队还在天天盯着API报价单,为了省钱选择了标价便宜78%的Gemini 3 Flash,放弃了看起来很贵的GPT-5.2。但在真实运行中,面对同一道AIME复杂数学题,聪明的GPT-5.2只用了562个思考Token就给出了正确答案,而廉价的Gemini 3 Flash在后台足足绕了11000多个思考Token才算明白。这种高达20倍的隐性消耗差异,瞬间抹平了它字面上的单价优势,导致最终账单反而高出2.5倍。
换句话说,这就好比一条高速公路明明明码标价,但大模型这个超级司机在后台疯狂绕路。更恐怖的是这种消耗的“不可预测性(Irreducible Variance)”:即使是同一个模型回答同一个问题,两次运行的成本最高能相差9.7倍。你的成本模型在这些“不可见”的Token面前,几乎毫无用武之地。当剔除掉思考Token后,价格倒挂的现象直接锐减了70%。
长程任务(Long-Horizon)的爆发:从“线性调用”到“指数耗流”
如果只是单次问答绕点路,这点损耗或许还能承受。但在2026年及以后,AI的底层架构已经正式从“公共AI(Public AI)”转向了以“个人超级智能体(Personal Super Agent)”为核心的生态。
在长程任务(Long-Horizon Tasks)的逻辑下,用户不再和AI一问一答。智能体会接管整个工作流。比如智谱的GLM-5.1,在优化向量数据库的真实工程任务中,它可以在单次任务中不间断自主运行,执行超过600次迭代和6000多次外部工具调用,甚至自己发现瓶颈并改变算法策略。而MiniMax M2.7则可以在内部脚手架上,全自主执行“分析失败 -> 规划变更 -> 修改代码 -> 运行评估”的循环超过100轮,实现模型的“自我进化”。
这就非常巧妙也极其致命了。机器在后台不知疲倦地“左右互搏”,直接把原本线性的Token消耗变成了指数级的黑洞。当Agent生态(如OpenClaw)疯长,甚至出现了专门给Agent使用的去中心化社交网络(Moltbook)和通信协议(MCP、A2A)时,机器与机器之间的通信(A2A)流量彻底超越了人机交互。这种算力饥渴,直接逼迫底层技术走上了一条“压榨物理极限”的不归路。
底层架构的破局:借道与暗渡陈仓(L2A与MoE重构)
既然Token变得如此昂贵,长文本推理又是个算力无底洞,那聪明的底层技术团队是怎么破局的?靠的是算法层面的“暗渡陈仓”。
1. L2A(Learning To Attend):精准抠除80%的全局算力
处理128K甚至更长的上下文时,传统的全局注意力机制(Global Attention)算力成本呈二次方爆炸。2026年最新的L2A架构打破了这个思维定势。它让模型在处理每一个Token时,先经过一个轻量级的滑动窗口(局部注意力),然后通过一个Router(路由器)自主决定:当前信息足够吗?如果不够,才激活昂贵的全局记忆去检索。
通过这种机制,模型硬生生跳过了约80%的全局计算,在维持128K长文本性能的同时,将最耗显存的KV Cache砍掉了一半。这就好比你查资料,不再是从头到尾把《辞海》翻一遍,而是只在遇到不懂的生僻字时才去精准翻页。
2. MoE(混合专家)的路线之争:从“Token找专家”到“专家找Token”
传统的MoE架构面临严重的“专家崩溃(Expert Collapse)”和负载不均问题。为了解决这个痛点,底层逻辑正在从Token Choice(每个Token选Top-K个专家)演进到Expert Choice(专家在固定预算下挑选Token)。结合像vLLM语义路由器这样的技术,系统能直接拦截简单的意图,把它丢给廉价的小模型(SLM),只有硬核逻辑才会触发重型推理大模型。
业界测试发现,在特定任务下,0.5B到3B参数的小语言模型,其性能-效率比(PER)甚至全面碾压了70B的庞然大物。这意味着,“大即是好”的粗暴时代结束了,未来的赢家属于能把路由调度做到极致精细的玩家。
So What? 这跟我们有什么关系?
讲到这里,自然会有人问:分析了一堆底层Token计费、L2A内存访问和MoE路由,然后呢?我又不是做基座大模型开发的,这跟我做业务有什么关系呢?
回答是:底层算力调度、计费架构与Agent协议的演进,永远是上层商业变现与应用落地的风向标。在2026年之后的商业环境里,我们需要重构以下几个极其关键的商业认知:
第一,理解流量的真实成本结构,抛弃“表面标价”幻觉。
当你在构思明年的AI业务预算时,绝对不能再只盯着大厂的API字面报价。在Reasoning模型面前,评判成本的唯一标准变成了动态的Cost-of-pass(通过成本)。不懂得评估和控制“思考Token”冗余度的团队,其项目利润率将被海量不可预测的废算力悄悄抹杀。
第二,不要迷信“人类用户入口”,迎接A2A(Agent-to-Agent)流量时代。
过去的SaaS或软件在争夺人类的屏幕使用时长。但在个人超级智能体(Personal AI)时代,价值的入口已经从OS平台迁移到了分布式智能体中心。随着A2A协议和Moltbook这种Agent社交/工具分发平台的出现,你的服务或产品,不再是想尽办法买量让人去点击,而是要确保你的API能力边界清晰、可组合性强,从而在后台被用户的Agent主动发现并高频调用。
第三,端云混合与数据主权是终局。
为了对抗高昂的云端Token成本和解决极端的隐私需求,架构正在走向Personal AI的“端云混合”。企业不仅要懂怎么调用大模型,还要懂如何把轻量级的SLM部署在用户的本地设备(AI PC、智能眼镜)上,并利用可信计算(TEE)保障数据的主权。
毕竟,热门的AI模型(无论是GPT-5.2还是GLM-5.1)随时可能会被几个月后的新榜单超越,但读懂这套由长程任务驱动、算力边界压榨与Agent自治协议共同交织出的新商业博弈规则,永远不会过时。
