 夜雨聆风
夜雨聆风目前业界主流的 OpenClaw 企业级改造,基本都围绕着几件核心诉求展开:多租户/多部门隔离、RBAC 权限与审计、多智能体团队协作,以及利用企业级 RAG 引擎做部门知识隔离。 具体实现大致可以归为四类典型架构,各自适合不同规模和安全要求的企业。
从个人助手到企业助手,我们需要补齐什么?
在探讨具体架构前,我们先明确企业级改造需要跨越的四道门槛:
身份与租户/部门隔离:个人版默认只有一个用户;而企业需要区分不同用户、部门(如市场部、研发部、客服部)和项目空间,彻底防止会话、文件与工具调用串号。
权限与审计控制: 满足合规与内部风控要求。需要引入 RBAC 角色模型,记录详尽的操作审计日志,并对模型预算进行严格控制。
多 Agent 团队协作: 企业需要的不是一个全能的个人助手,而是一支“AI 团队”。需要部门 Agent、路由 Agent、审计/安全 Agent 协同完成复杂的跨域任务。
企业知识多空间管理: 不同部门有自己的知识库与敏感等级,这就需要在 RAG层做精细的数据域控制和权限模型。
明确了需求,我们来看看主流的四种方法。
方案一:多实例部署进行物理级隔离
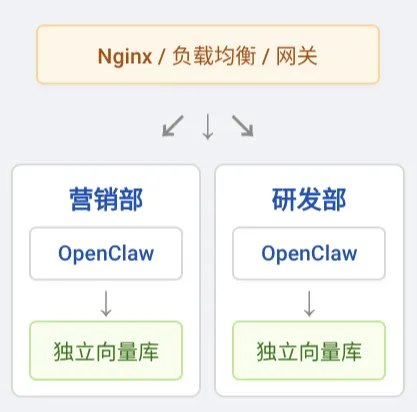
很多团队最先落地的做法,就是按部门/项目各跑一套 OpenClaw。
通过 Docker、Proxmox 等虚拟化技术做资源和网络隔离。例如前端组、后端组、测试组各一套独立的 OpenClaw 实例,甚至各自配置自己的模型、工具和存储,互相完全不影响。
优点: 隔离性强,思路简单粗暴——“一部门一机一 Claw”。故障和升级互不干扰,非常适合 10–50 人的小团队或早期试点项目。
缺点: 运维成本呈线性增长,多处配置重复。跨部门知识共享需要额外桥接(比如需要统一的向量库,或依赖一个“总控” Agent 做数据同步)。
实战案例:曾有团队用“每个部门一个 Gateway 端口 + 独立工作区”的方式,组建了一个6 个 Agent 的无员工公司。部门负责人 Agent 各自带队,拥有自己的工作目录与心跳监控。
方案二:多租户/多部门架构进行正统企业化改造
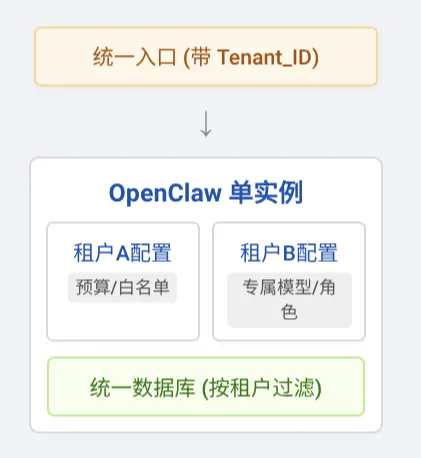
这是目前公认比较正统的企业级方案:一套 OpenClaw 实例,内部做多租户/多部门隔离。 对外是一个统一平台,对内划定多 tenant、多空间的逻辑边界。
1. Multi-Tenant 配置模式:OpenClaw 官方 MasterClass 的 Enterprise 模块给出过示例:在配置文件中开启 multi_tenant.enabled,为每个部门定义专属的 tenant 配置。 这个模式的本质是租户即部门:例如 Marketing 和 Engineering 部门分别有自己的 id、预算上限、允许/禁止的技能。比如市场部禁用 code-runner 和 file-manager,以及不同的 LLM 供应商。会话、文件、工具权限都被挂在各自的 tenant 上。
2. 工程层面的权衡相比于方案一的简单粗暴,多租户架构能够服务全公司,资源利用率高,集中监控和运维更方便。 但这需要在代码和配置里到处携带 tenant_id 做访问控制。数据库查询、文件访问、日志记录都要加租户过滤,工程复杂度极高,更适合 100 人以上且有专职 AI 平台团队的大企业。同时,这也方便定义 Admin、Developer、Auditor 等细分角色,实现最小权限原则。
方案三:单实例 + 多部门 Agent 团队进行逻辑协作隔离
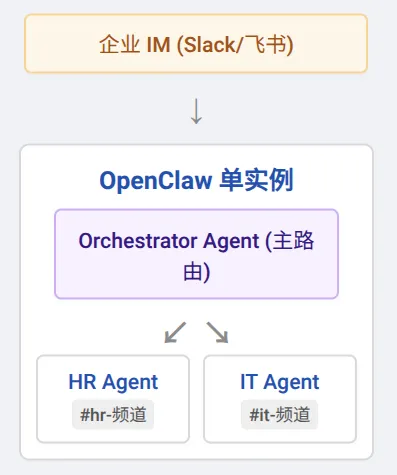
另一个非常流行的轻量级思路是:不从进程/实例层面硬拆,而是把部门抽象成多个专职的 Agent。在同一个 OpenClaw 实例中,配合多 Agent 团队与路由机制来服务不同部门。
1. 按部门划分 Agent 团队:参考腾讯云及官方的多 Agent 模式,建议对不同职能配置专职 Agent。例如:
Slack 上的
engineering-ops频道绑定运维 Agent;marketing频道绑定营销 Agent;私有频道里放置财务 Agent处理对账和供应商管理。
每个 Agent 有独立的人格(SOUL.md)、职责、模型和工具集。此时还可以设立一个团队长(Orchestrator)Agent,负责把复杂任务拆解给各部门 Agent,再汇总结果,形成虚拟部门协作。
2. 方案特点:
优点: 改造实现快,对原始系统改动小。支持编排模式和负载均衡,同时支持共享记忆和私有记忆。多部门协作体验极佳。
缺点: 这种隔离纯粹是逻辑层面的。如果没有在存储与 RAG 层做真正的租户分区,在金融、医疗等严格合规场景下,安全性稍显不足。
方案四:OpenClaw + 企业级 RAG 引擎
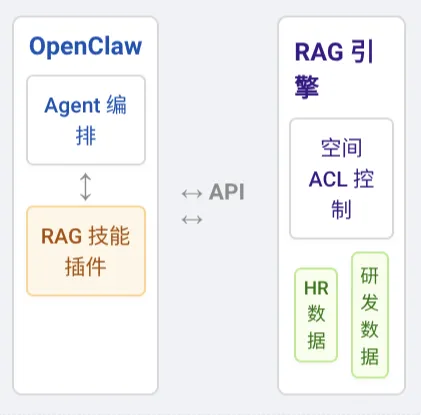
面对复杂的内部文档,很多企业不再用 OpenClaw 硬扛,而是接入专门的企业级 RAG 引擎。由 RAG 引擎负责文档解析、分库和多空间权限,OpenClaw 退居幕后,专注智能体编排和动作执行。
RAGFlow x OpenClaw 模式:用 RAGFlow 管理企业的组织架构、工作空间和数据集。当 OpenClaw 通过 RAGFlow Skill 接入办公软件对话时,引擎会自动带上对应用户/部门的 dataset scope,仅在授权的数据集范围内做语义检索和问答。
这样一来,部门和租户的隔离主要发生在了 RAG 层。OpenClaw 只是调用已经过滤好的知识,完美兼顾了数据安全和系统的复用度。
四种方案的核心差异:
| 评估维度 | 多实例部署 | 单实例多租户 | 多部门 Agent 团队 | OpenClaw + 企业 RAG |
| 隔离强度 | 物理/进程级强隔离 | 逻辑强隔离(需严谨实现) | 逻辑弱隔离(主要在Agent层) | 知识层强隔离,执行层共享 |
| 运维复杂度 | 多套实例,简单但重复 | 集中运维,但代码/配置复杂 | 最低,对原系统改动小 | 中等,需多维护一层RAG平台 |
| 跨部门协作 | 需额外桥接(API或中控) | 同系统内较容易实现 | 非常自然,靠 Agent 协作 | 通过共享/交叉授权数据集实现 |
| 安全合规 | 好,易做网络/权限隔离 | 最好,但实现难度最高 | 依赖工程实践,不适合高合规 | 取决于RAG权限模型和策略 |
| 适用场景 | 小团队 / PoC试点 (<50人) | 中大型企业 (>100人) | 轻量化多部门协作试点 | 有明确文档资产与知识管理诉求 |
| 改造工作量 | 中(CI/CD + 配置管理) | 高(全链路 tenant 改造) | 低(主要是 Agent 配置路由) | 中高(需建设/对接RAG平台) |
如果你正在规划内部的 AI 演进,这里提供一条务实的落地路线图:
第一阶段:多 Agent 团队 + 基础 RBAC:保持单实例,按部门/职能配置专职 Agent 并绑定办公软件的不同频道。配置基础 RBAC,限制高危工具的使用范围。适合作为 1–2 个月内交付、快速验证 ROI 的 MVP。
第二阶段:引入企业 RAG 做部门知识隔离:将部门文档迁移到专门的 RAG 引擎,按组织/空间划分边界并配置 ACL。实现问 HR 的问题,AI 只能去查 HR 的文档集合的硬约束。
第三阶段:视规模演进至多租户架构当用户数、Agent 数量激增时,再考虑实现真正的
multi_tenant架构与完整的审计体系。甚至可以探索“按 BU 部署多实例,实例内做多租户”的混合架构。
你目前所在的团队属于哪个阶段?在落地企业级 AI 助手时,最大的卡点是合规、资源还是工程改造?欢迎在评论区留言交流,我们一起探讨最适合你们的架构演进路线!
