夜雨聆风
夜雨聆风LG - 机器学习 CV - 计算机视觉 CL - 计算与语言
1、[LG] Is your algorithm unlearning or untraining?
2、[LG] Meta-learning In-Context Enables Training-Free Cross Subject Brain Decoding
3、[CL] Cram Less to Fit More:Training Data Pruning Improves Memorization of Facts
4、[LG] Inside-Out:Measuring Generalization in Vision Transformers Through Inner Workings
5、[CV] Small Vision-Language Models are Smart Compressors for Long Video Understanding
摘要:你的算法究竟是在“机器遗忘”还是在“反训练”、上下文元学习实现无需训练的跨受试者脑解码、训练数据剪枝提升模型对事实的记忆能力、通过内部机制探究 Vision Transformers 的泛化能力评估、小型视觉-语言模型是长视频理解的智能压缩器
1、[LG] Is your algorithm unlearning or untraining?
E Triantafillou, A I Humayun, M Ribero, A M Turner…
[Google] (2026)
你的算法究竟是在“机器遗忘”还是在“反训练”?
要点:
指出“机器遗忘(Machine Unlearning)”这一术语被严重滥用,它实际上混淆了两个在数学表达和实际应用上截然不同的问题:“取消训练(Untraining)”和“遗忘(Unlearning)”。 将 取消训练 (Untraining) 定义为逆转特定“遗忘集 ”的经验风险最小化过程。其理想结果等同于仅在剩余数据集()上从头开始训练的模型。 将 遗忘 (Unlearning) 定义为抹除遗忘集 背后所代表的整个底层概念、行为或数据分布。其理想结果是一个“从未见过该概念任何实例”的模型()。 反直觉的观点: 一个完美执行了“取消训练”的模型,可能依然能完美预测它被要求“遗忘”的那些数据。如果遗忘集数据的交叉影响较低,模型完全可以通过剩余数据中学到的泛化知识来做出正确预测。因此,“取消训练”不等于“无法预测”。 揭示了评估指标错位的风险:成员推理攻击(MIA)适用于评估取消训练(如隐私合规),但完全不适用于评估遗忘(如消除危险知识)。因为即使 MIA 查不出某个危险样本在训练集中,模型可能依然掌握着该危险概念。 对过往文献进行了重新分类:删除用户隐私数据或《哈利波特》的一字不差的原文属于 Untraining;而擦除后门、消除有害行为或特定艺术风格则属于 Unlearning。 强调将 Untraining 算法强行用于 Unlearning 任务(例如仅发现部分污染数据时)会导致灾难性失败,因为 Untraining 算法缺乏抹除整个概念所需的“遗忘泛化能力”。 提出了全新的研究方向:正如模型训练需要归纳偏置来实现向“学习”的泛化一样,真正有效的遗忘算法也需要特定的归纳偏置,以便从少量的样本中泛化出对“整个概念的遗忘”。
主旨: 本文旨在纠正当前AI安全和隐私领域中对“机器遗忘”概念的长期混淆。文章提出,现有的机器遗忘研究实际上包含两个完全不同的目标:“取消训练”(消除特定样本的影响)和“遗忘”(泛化抹除特定样本背后的整个概念分布)。论文呼吁学界明确区分这两者,以解决当前算法期望错位、评估指标误用以及底层研究方向模糊的问题。
创新:
概念级的开创性解耦:首次引入了“是否需要泛化遗忘能力”这一区分维度,将混为一谈的 Unlearning 拆解为 Untraining(仅针对特定样本的 Self-influence)和真正的 Unlearning(针对样本分布的 Cross-influence)。 认知视角的转换:通过类比“训练(Training)与学习/泛化(Learning)”的关系,创新性地构建了“取消训练(Untraining)与遗忘/泛化遗忘(Unlearning)”的数学和概念映射。
贡献:
澄清理论定义:为 Untraining 和 Unlearning 提供了清晰的参考目标(前者参考 模型,后者参考 模型)。 纠正评估范式:指出了由于概念混淆导致的评估指标错位问题(如滥用 MIA 指标),为未来不同场景(隐私合规 vs. 模型对齐/安全)的评估制定了科学的标准界限。 重新梳理文献:对过去几年的“机器遗忘”论文进行了分类,解释了为何某些算法在特定任务上会失效的根本原因(用 Untraining 的剑斩 Unlearning 的目标)。
提升:
本文作为一篇观点和理论框架型论文(Position Paper),并未提出具体的刷榜算法。其带来的“提升”在于认知维度、研究范式和评估准确性上的跃升。它提升了研究人员对遗忘算法适用边界的理解,避免了未来在错误的基准上进行无效的算法内卷。
不足:
缺乏具体的算法实现:论文提出了 Unlearning 需要泛化能力,但没有提供或推导具备这种归纳偏置的具体算法设计。 概念定义的局限性:作者承认,目前对于 Unlearning 的定义依赖于“能用一组样本 来完全表示一个概念”,但对于像“边缘检测”这样难以用离散样本集严格定义的抽象概念,该框架目前难以适用。 实证分析不足:虽然逻辑严密,但如果能配合大规模的实证实验,量化展示当前 SOTA 算法在 Untraining 和 Unlearning 上的具体性能差异,将更具说服力。
心得:
完美“删数据”并不等于模型变安全(最反直觉):我们常常认为,只要从训练集里剔除了某些有害数据并重训,模型就不会生成这些内容了。然而论文指出,只要剩余数据中存在类似的模式(哪怕是极其隐晦的),模型依然能通过“泛化”重构出这些有害知识。这启发我们在做大模型安全对齐时,不能仅仅停留在“数据清洗(Untraining)”层面,必须追求更深层次的“概念抹除(Unlearning)”。 评估指标的“张冠李戴”极其危险:用查隐私泄露的指标(MIA)去查模型是否丢失了“制造炸弹的危险能力”,是南辕北辙。这警示我们在实际的 AI 工业界应用中,必须先明确需求是“点对点的遗忘”(合规/版权)还是“分布对分布的遗忘”(价值观/安全),再对症下药选择评估体系,否则会制造虚假的安全感。 “泛化”不仅存在于学习中,也存在于遗忘中:机器学习界花了几十年研究如何从有限样本泛化出抽象概念(Learning),现在我们同样需要研究如何从有限的“代表性遗忘样本”中泛化出对“整个概念的剥夺”。这为未来的 Few-shot Unlearning 算法指明了核心技术路径——寻找并利用“遗忘的归纳偏置”。
一句话总结:
本文打破了“机器遗忘”领域的概念混沌,创造性地将仅仅剔除特定数据影响的“取消训练(Untraining)”与泛化抹除整个底层概念的“遗忘(Unlearning)”严格区分,指出反直觉的事实(完美取消训练的模型依然能预测被删数据),警告了概念混淆导致的算法误用与评估失效,为未来大模型安全与隐私研究指明了精确的发力方向。
As models are getting larger and are trained on increasing amounts of data, there has been an explosion of interest into how we can ''delete'' specific data points or behaviours from a trained model, after the fact. This goal has been referred to as ''machine unlearning''. In this note, we argue that the term ''unlearning'' has been overloaded, with different research efforts spanning two distinct problem formulations, but without that distinction having been observed or acknowledged in the literature. This causes various issues, including ambiguity around when an algorithm is expected to work, use of inappropriate metrics and baselines when comparing different algorithms to one another, difficulty in interpreting results, as well as missed opportunities for pursuing critical research directions. In this note, we address this issue by establishing a fundamental distinction between two notions that we identify as \unlearning and \untraining, illustrated in Figure 1. In short, \untraining aims to reverse the effect of having trained on a given forget set, i.e. to remove the influence that that specific forget set examples had on the model during training. On the other hand, the goal of \unlearning is not just to remove the influence of those given examples, but to use those examples for the purpose of more broadly removing the entire underlying distribution from which those examples were sampled (e.g. the concept or behaviour that those examples represent). We discuss technical definitions of these problems and map problem settings studied in the literature to each. We hope to initiate discussions on disambiguating technical definitions and identify a set of overlooked research questions, as we believe that this a key missing step for accelerating progress in the field of ''unlearning''.
https://arxiv.org/abs/2604.07962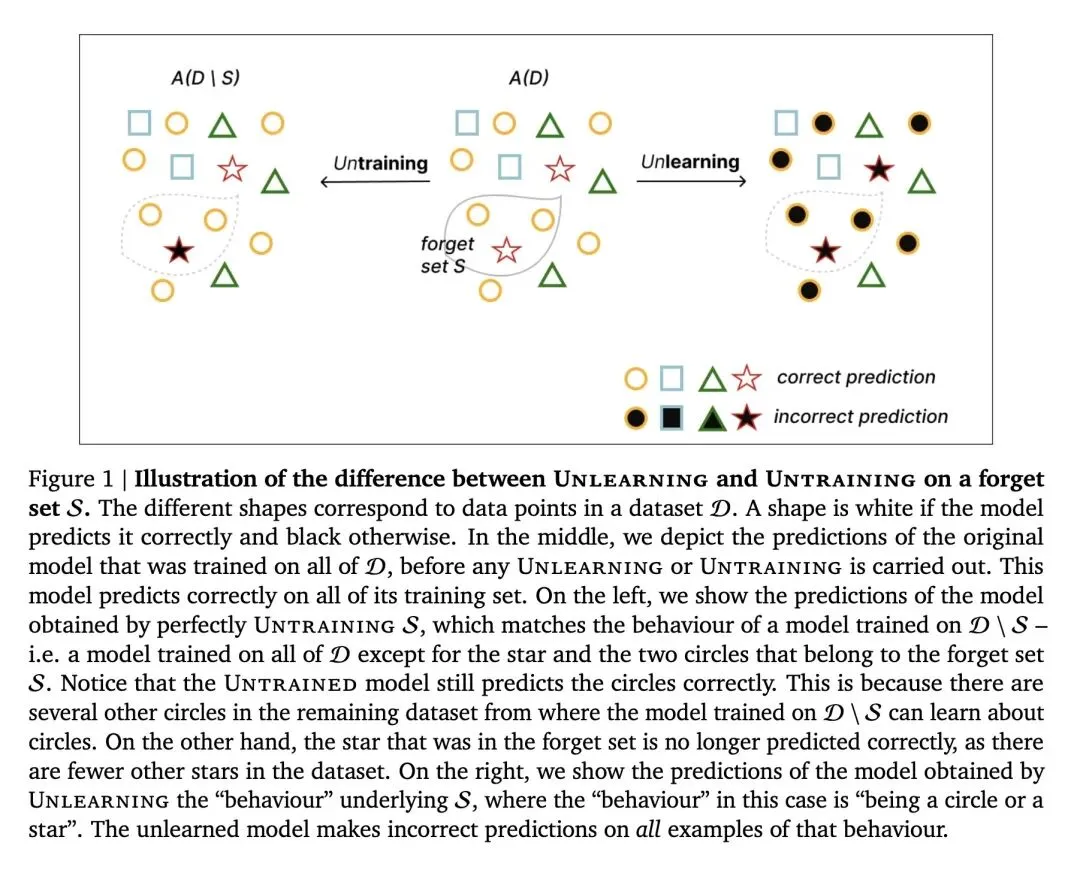
2、[LG] Meta-learning In-Context Enables Training-Free Cross Subject Brain Decoding
M Nan, M Yu, W Mai, J S. Prince…
[University of Hong Kong] (2026)
上下文元学习实现无需训练的跨受试者脑解码
要点:
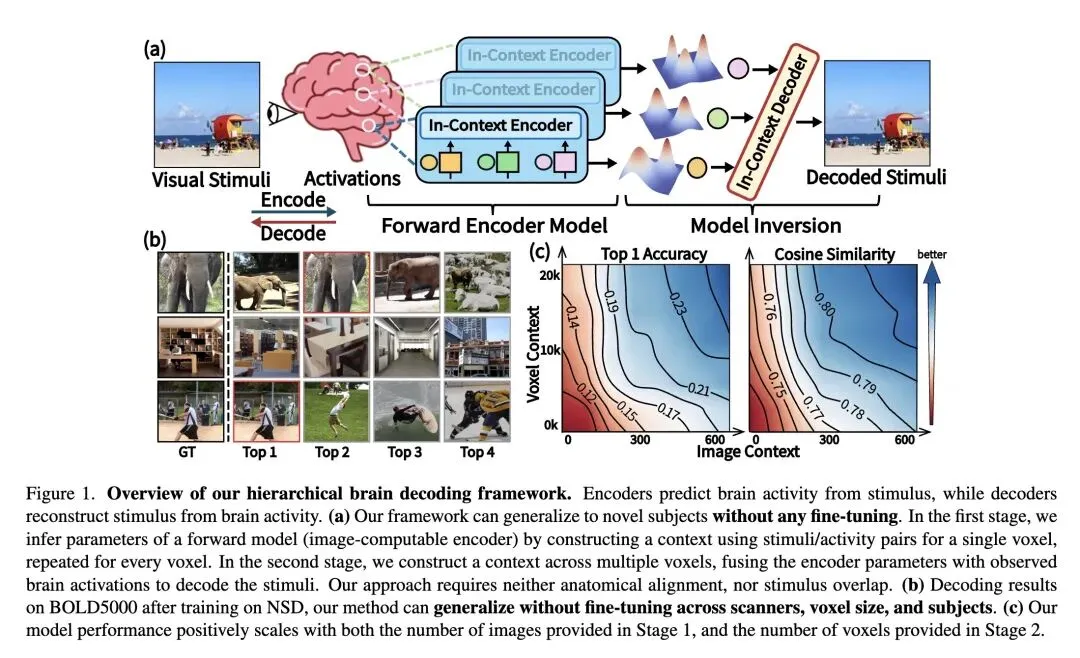
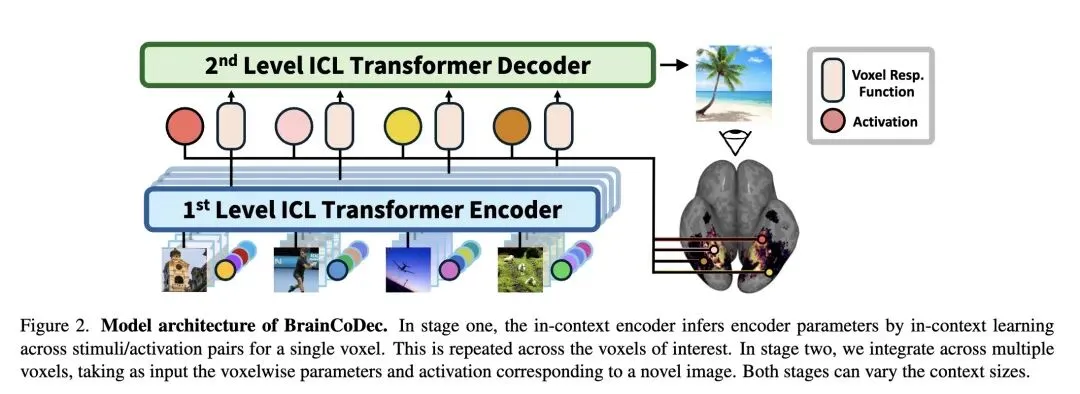
解决了脑机接口和神经科学中的一个关键瓶颈:受试者个体间的巨大差异。过去,从 fMRI 数据中解码视觉信息通常需要针对每个受试者进行基于梯度的微调。 提出了 BrainCoDec,这是一个利用层次化上下文学习 (In-Context Learning, ICL) 的元学习框架,实现了免训练、跨受试者的视觉解码。 反直觉的方法: 完全摒弃了传统方法中对跨受试者解剖学对齐(例如将大脑映射到标准 MNI 空间)或共享重叠刺激的需求。相反,它纯粹将解码视为一个功能性逆向问题。 包含两个层次化阶段: 阶段 1(体素级上下文):使用少量的“图像-激活”对作为上下文,独立推断每个体素的前向编码模型参数(刺激如何映射到大脑活动)。 阶段 2(跨体素上下文):将推断出的参数和观察到的激活跨多个可变数量的体素聚合成上下文,输入到 Transformer 中执行功能性逆向,解码出新的图像嵌入。 高信息熵/惊人结果 1: 实现了强大的跨扫描仪和跨协议泛化。仅在 7T fMRI 数据(NSD 数据集)上训练的模型,无需任何重新训练,就能成功解码来自 3T fMRI 扫描仪(BOLD5000 数据集)、具有不同体素大小和实验设计的数据。 高信息熵/惊人结果 2: 对目标兴趣区 (ROI) 的丢失表现出极强的鲁棒性。屏蔽掉高度专业化的大脑区域(例如用于人脸识别的梭状回面孔区 FFA)后,解码性能几乎没有下降,这表明大脑中的视觉表征是高度分布式的,而不仅仅是严格的局部化。 通过移除位置编码并在 Transformer 架构中采用 logit 缩放,实现了对体素输入顺序的无感以及对可变长度体素上下文的处理。 可视化模型的自注意力权重揭示了自发产生且高度可解释的空间模式,这些模式在没有显式空间监督的情况下,自然地与已知的大脑皮层语义区域对齐。
主旨: 本文旨在解决神经视觉解码中模型难以跨个体泛化的核心难题。通过提出一种基于元学习和层次化上下文学习的框架(BrainCoDec),文章将脑解码重构为一个“从少样本中推断个体编码器并进行功能逆向”的过程,从而实现在不进行任何梯度微调、无需解剖学对齐的情况下,对全新受试者乃至全新核磁共振设备产生的数据进行高质量的视觉解码。
创新:
解剖学与功能学的彻底解耦:不再依赖将不同大脑配准到同一个三维物理空间,而是将每个体素视为一个独立的函数,通过“函数逆向(Functional Inversion)”来实现跨大脑的映射。 层次化上下文学习架构:创造性地将 ICL 分为两级。第一级跨刺激学习单个体素的响应规律(求导编码器);第二级跨体素整合信息逆推视觉刺激(解码器)。 无序且可变长度的体素处理机制:由于不同个体的大脑体素数量不同,模型摒弃了传统 Transformer 的位置编码,并引入 logit 缩放,使得模型能够像处理无序集合一样处理数量任意的大脑体素。
贡献:
理论/方法贡献:提出了一种全新的免训练跨受试者大脑解码范式,验证了基于大语言模型启发的 In-Context Learning 同样适用于高度复杂的生物神经信号对齐。 实证贡献:在 NSD 数据集上显著超越了现有的 SOTA 方法(如 MindEye2 和 TGBD),并且首次证明了单一模型可以实现跨设备(7T 到 3T)、跨分辨率、跨扫描协议的“零样本”脑解码。 可解释性贡献:通过注意力机制的权重可视化,为认知神经科学提供了一个计算验证工具,证实了模型自动学到了与人类已知皮层功能区(如 PPA、FFA)高度一致的语义分布。
提升:
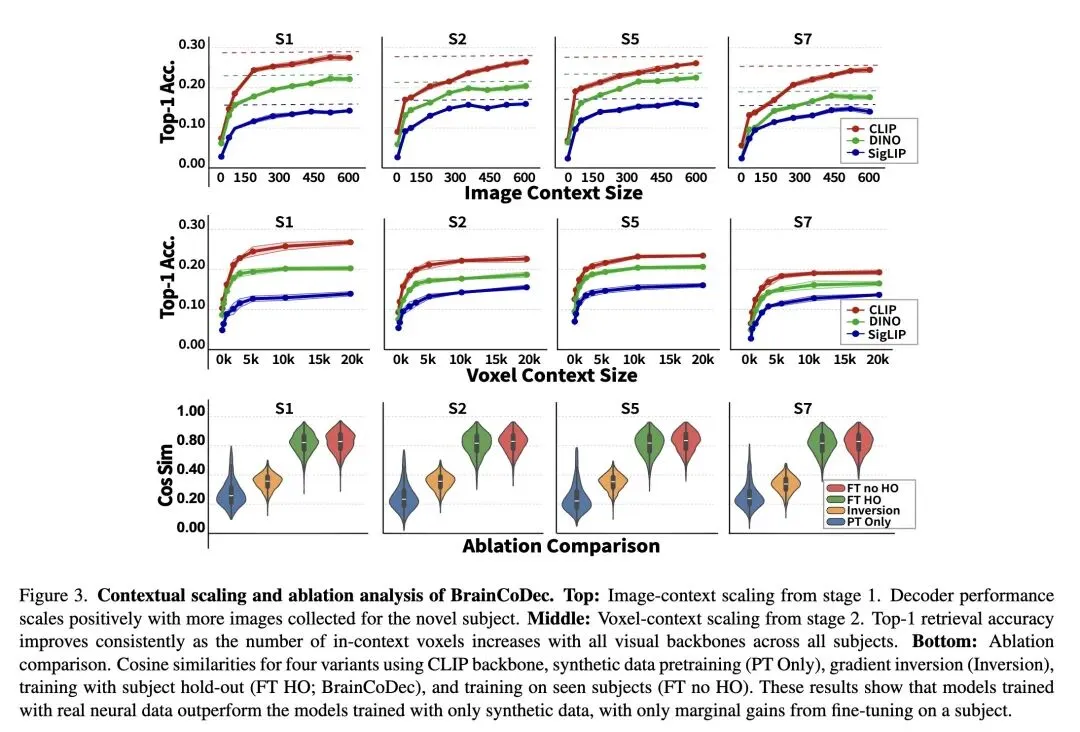
零样本跨主体检索精度:在未见过的受试者上,Top-1 和 Top-5 图像检索准确率大幅提升(如 BrainCoDec Top-1 可达 25.5%,而使用解剖对齐的 MindEye2 仅为 4.11%)。 数据与计算效率:新受试者只需提供约 200 张图像的上下文校准数据,且无需进行耗时的反向传播和梯度更新,极大地降低了应用门槛。 领域泛化能力:突破了单一数据集的限制,模型在完全未见过的 BOLD5000 数据集上同样展现了卓越的精度(平均排序达到 3.49-4.47)。
不足:
并非绝对的“零样本”:虽然是免训练(Training-free),但在推理时依然需要新受试者提供少量的(如 200 个)“图像-脑激活”对作为上下文提示(Prompt),在完全没有任何先验数据的极端情况下无法工作。 侧重于检索和表征:论文主要评估了图像特征嵌入(CLIP、DINO 等)的解码与检索能力,对于最终像素级图像的生成重建效果,需依赖外接的生成模型(如 Stable Diffusion),未对端到端生成进行深度评估。 极限精度的妥协:尽管在免训练设定下表现惊艳,但实验(图3)也承认,经过受试者专门微调(FT no HO)的模型在性能上限上依然略高于纯免训练的 In-Context 预测。
心得:
大脑的“去中心化”表征比想象中更强(反直觉启示):最令我震撼的是“ROI Dropout”实验。传统神经科学认为 FFA 专管人脸、PPA 专管场景,但实验发现,哪怕把主管人脸的体素全删了,模型依然能从大脑的“其他区域”完美解码出人脸。这深刻揭示了大脑高层视觉信息的全息性和高度分布式特征,打破了绝对的“模块化大脑”假说。 “解剖对齐”可能是脑科学 AI 化的伪命题:过去几年,研究者耗费大量算力试图把所有人的大脑像揉面团一样对齐到一个标准 3D 模型里,但效果甚微。这篇文章启发我们,大脑的物理拓扑并不重要,功能映射的数学本质才是关键。放弃物理对齐,转而使用元学习让模型自己去寻找“功能密码”,是通向通用脑基座模型(Brain Foundation Model)的正确道路。 上下文学习(ICL)是解决生物异质性的终极武器:ICL 最初在 NLP 领域大放异彩,但本文证明了它在处理生物信号(如巨大的个体差异、扫描仪噪声)时具有惊人的灵活性。未来,无论是脑电图(EEG)、肌电图(EMG)还是基因表达,我们都可以跳出“收集海量数据微调”的泥潭,转向“提供少量校准样本让大模型现场推理”的新范式。
一句话总结:
本文摒弃了低效的大脑物理结构对齐,巧妙利用层次化上下文学习(ICL),首创了一种完全免训练、且能跨越不同核磁共振设备的脑视觉解码框架 BrainCoDec,深刻揭示了大脑视觉表征的高度分布式特征,为迈向通用的“脑基座模型”奠定了坚实基础。
Visual decoding from brain signals is a key challenge at the intersection of computer vision and neuroscience, requiring methods that bridge neural representations and computational models of vision. A field-wide goal is to achieve generalizable, cross-subject models. A major obstacle towards this goal is the substantial variability in neural representations across individuals, which has so far required training bespoke models or fine-tuning separately for each subject. To address this challenge, we introduce a metaoptimized approach for semantic visual decoding from fMRI that generalizes to novel subjects without any fine-tuning. By simply conditioning on a small set of image-brain activation examples from the new individual, our model rapidly infers their unique neural encoding patterns to facilitate robust and efficient visual decoding. Our approach is explicitly optimized for in-context learning of the new subject’s encoding model and performs decoding by hierarchical inference, inverting the encoder. First, for multiple brain regions, we estimate the per-voxel visual response encoder parameters by constructing a context over multiple stimuli and responses. Second, we construct a context consisting of encoder parameters and response values over multiple voxels to perform aggregated functional inversion. We demonstrate strong cross-subject and cross-scanner generalization across diverse visual backbones without retraining or fine-tuning. Moreover, our approach requires neither anatomical alignment nor stimulus overlap. This work is a critical step towards a generalizable foundation model for non-invasive brain decoding. Code and models are publicly available at https://github.com/ezacngm/brainCodec.
https://arxiv.org/abs/2604.08537
3、[CL] Cram Less to Fit More: Training Data Pruning Improves Memorization of Facts
J Ye, V Feldman, K Talwar
[Apple & National University of Singapore] (2026)
减负以增效:训练数据剪枝提升模型对事实的记忆能力
要点:
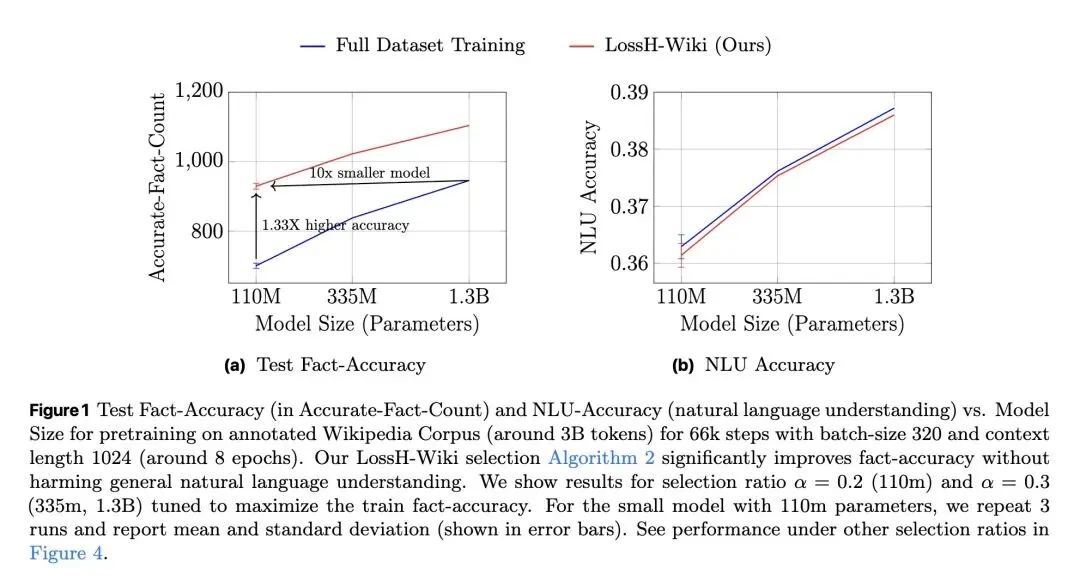
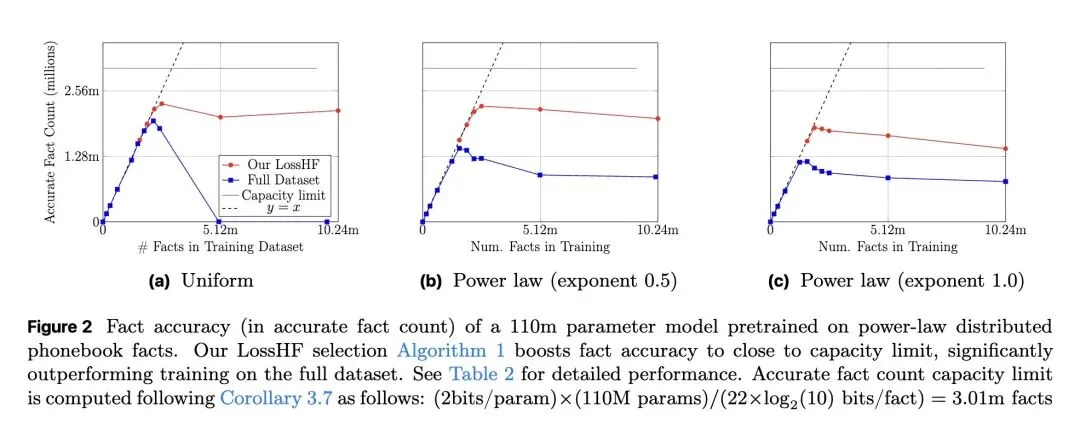
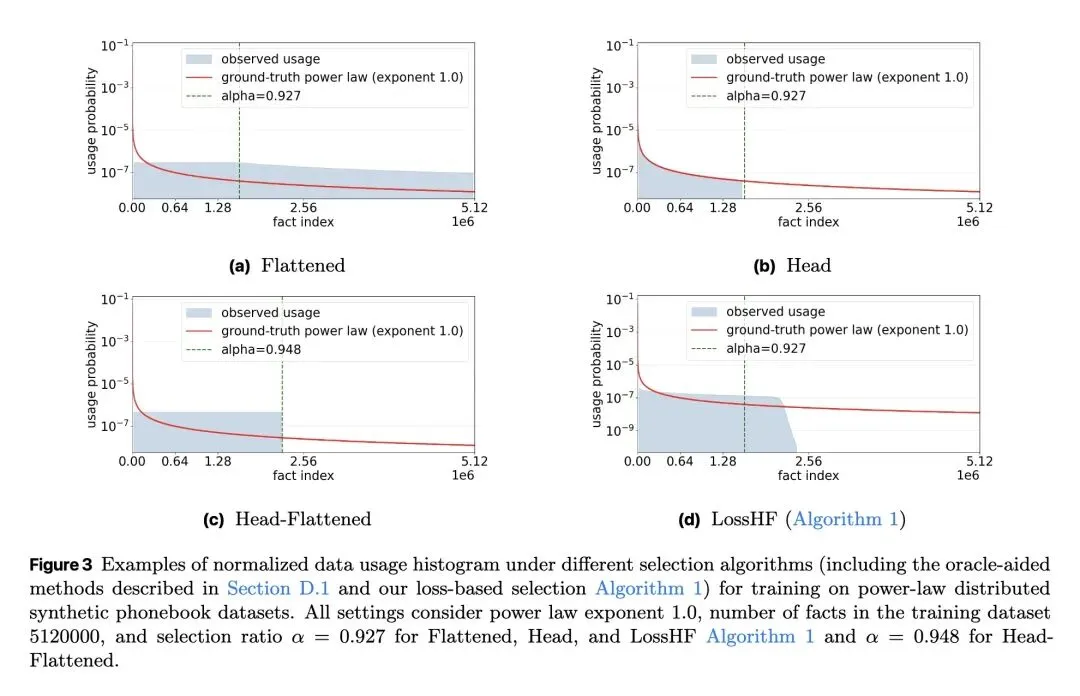
从信息论视角形式化了“事实记忆(Fact Memorization)”,在理论上证明了大型语言模型能够准确回答的独立事实数量存在容量极限(约等于2比特/参数)。 关于训练分布的反直觉发现: 当训练数据包含的事实数量超过模型容量时,盲目在全量数据上训练并不会让模型“部分记住”所有事实,反而会导致整体事实准确率出现断崖式下跌(陷入次优分配)。当事实呈现长尾(幂律)分布时,这种性能崩塌尤为严重。 反直觉的数据筛选策略: 当前主流的数据筛选算法(如Rho-1、Rho-Loss)通常优先选择高损失(High-loss)的样本(即困难或未学会的样本)。但本文提出相反的策略:优先选择低损失样本(LossH/LossHF)。因为高损失事实往往处于长尾且超出模型容量,而保留低损失事实才能确保训练数据与模型的记忆容量相匹配。 提出了LossH(保留头部/低损失事实)和LossHF(在保留头部事实的基础上,进一步压平/降采样重复度极高的极低损失事实)算法,使训练数据的规模与分布适配模型的参数量。 高信息熵结果: 在维基百科语料上从头预训练时,使用该修剪策略的1.1亿(110M)参数GPT-2小模型,其记忆的实体事实数量比标准训练提高了1.3倍,其事实准确率直接媲美在全量数据上训练的13亿(1.3B,即10倍体量)大模型。 强调数据修剪必须在“事实级别(Fact-level)”进行,而非“Token级别”。按Token进行修剪会破坏事实的语义边界,无法带来任何记忆性能的提升。
主旨: 本文旨在探究大型语言模型在知识密集型任务中经常产生幻觉、难以记住事实的根本原因:这究竟是理论容量的硬性限制,还是训练数据分布不佳所致?研究表明,事实准确率低下主要归咎于训练数据中的事实数量超出了模型容量,且分布极不均衡。为此,论文提出了一种纯基于训练损失的数据修剪方法,通过“丢弃长尾、压平头部”,使模型能够最大化地利用其参数容量来记忆事实。
创新:
颠覆性的“低损失”筛选范式:与传统“难例挖掘(Hard Example Mining)”或专注于高损失未学习样本的策略不同,本文创新性地提出保留低损失样本,主动放弃模型“记不住”的长尾知识,从而保全整体事实准确率。 信息论与事实准确率的桥梁:首次将经典的“模型比特/参数容量”严格推导映射为具体的“事实准确率(Fact Accuracy)上限”。 无需先验频率的在线估算机制:在真实数据集中,事实的出现频率往往是未知的。论文巧妙地利用在线Batch内的“单条事实Token损失之和(Sum of loss)”作为事实频率和信息熵的代理指标,实现了动态阈值修剪。
贡献:
理论贡献:确立了语言模型事实记忆的理论上限,证明了当数据量超过容量阈值时,标准训练将无可避免地陷入次优解。 算法贡献:设计了LossH和LossHF(及其针对混合文本的变体Loss-Wiki)算法,有效控制训练集中的事实数量并平滑其分布。 实证贡献:在合成数据(电话簿)、半合成数据(arXiv作者-标题映射)和真实世界预训练(维基百科)三个层级上,均证明了该方法能将事实记忆能力逼近理论极限,使小模型达到越级的大模型表现,且不损害通用自然语言理解(NLU)能力。
提升:
事实记忆容量越级:使110M参数的小模型在维基百科测试集上的事实准确率提升了1.3倍,持平了未作数据筛选的1.3B参数大模型。 下游知识任务(MMLU)提升:在维基百科语料上使用该筛选策略预训练后,模型在MMLU-Knowledge相关子任务上的准确率显著提升,达到了335M参数模型的水平。 计算效率与表现的平衡:在LoRA微调注入新知识(arXiv论文作者映射)时,有效提升了新知识的记忆率,同时并未加剧灾难性遗忘。
不足:
依赖事实边界标注:算法要求在训练前知道什么是“事实”(例如维基百科实验中使用了带有 <|start_of_fact|>标签的语料)。对于毫无结构、未标注边界的野生互联网语料,事实级(Fact-level)的损失计算难以直接应用。对灾难性遗忘的解决有限:在LoRA微调注入新知识的实验中,虽然该方法提升了事实准确率,但模型原有的通用能力仍出现了不可忽视的遗忘(Forgetting),且随着LoRA秩(Rank)的增加,遗忘现象并未完全消除。 -“事实”与“推理”数据的潜在冲突:舍弃高损失数据有利于“死记硬背”事实,但这可能与学习复杂推理(Reasoning)和泛化所需的数据分布相冲突(推理往往需要学习高损失的困难样本)。
心得:
“少即是多(Cram Less to Fit More)”的算力经济学:我们一直迷信“用全网数据训练模型”,但这篇文章给小模型开发者敲响了警钟:如果你的模型只有1B参数,给它喂10T的长尾知识不仅是浪费算力,反而会因为“知识过载”导致它连最基础的常识都记不牢。为模型量身定制符合其容量的数据子集,比盲目堆砌数据更重要。 反转“困难样本偏好”,为不同能力定制筛选标准:业界极度推崇的Rho-1算法主张用高损失来筛选好数据,而本文用低损失反而取得了成功。这给我们一个极其深刻的启发:LLM的不同能力(记忆事实 vs. 逻辑推理)需要截然相反的数据分布!死记硬背需要高频、低损失的重复;而逻辑推理可能更需要低频、高损失的刺激。未来的数据工程必须是“按能力拆分”的。 Token不是世界的本质,“事实(Fact)”才是:按Token计算平均Loss来筛选数据被证明是无效的,因为这会把一个完整的事实切碎。将整句事实的“损失求和(Sum of loss)”作为衡量单位,才更符合人类认知中的“信息熵”。这提示我们在设计下一代架构或损失函数时,必须跨越Token级别的颗粒度,向Chunk或Fact级别的语义单元演进。
一句话总结:
本文从信息论视角揭示了语言模型事实记忆的容量极限,提出了一种反直觉的“低损失”数据修剪策略,通过主动丢弃超出模型容量的长尾高损失事实,使1.1亿参数的小模型在事实记忆上跨级匹敌13亿参数的大模型,证明了“少即是多”在知识注入中的强大效能。
Large language models (LLMs) can struggle to memorize factual knowledge in their parameters, often leading to hallucinations and poor performance on knowledge-intensive tasks. In this paper, we formalize fact memorization from an information-theoretic perspective and study how training data distributions affect fact accuracy. We show that fact accuracy is suboptimal (below the capacity limit) whenever the amount of information contained in the training data facts exceeds model capacity. This is further exacerbated when the fact frequency distribution is skewed (e.g. a power law). We propose data selection schemes based on the training loss alone that aim to limit the number of facts in the training data and flatten their frequency distribution. On semi-synthetic datasets containing high-entropy facts, our selection method effectively boosts fact accuracy to the capacity limit. When pretraining language models from scratch on an annotated Wikipedia corpus, our selection method enables a GPT2-Small model (110m parameters) to memorize 1.3X more entity facts compared to standard training, matching the performance of a 10X larger model (1.3B parameters) pretrained on the full dataset.
https://arxiv.org/abs/2604.08519
4、[LG] Inside-Out: Measuring Generalization in Vision Transformers Through Inner Workings
Y Peng, M Ma, Z Yao, X Peng
[University of Delaware & George Mason University] (2026)
由内而外:通过内部机制探究 Vision Transformers 的泛化能力评估
要点:
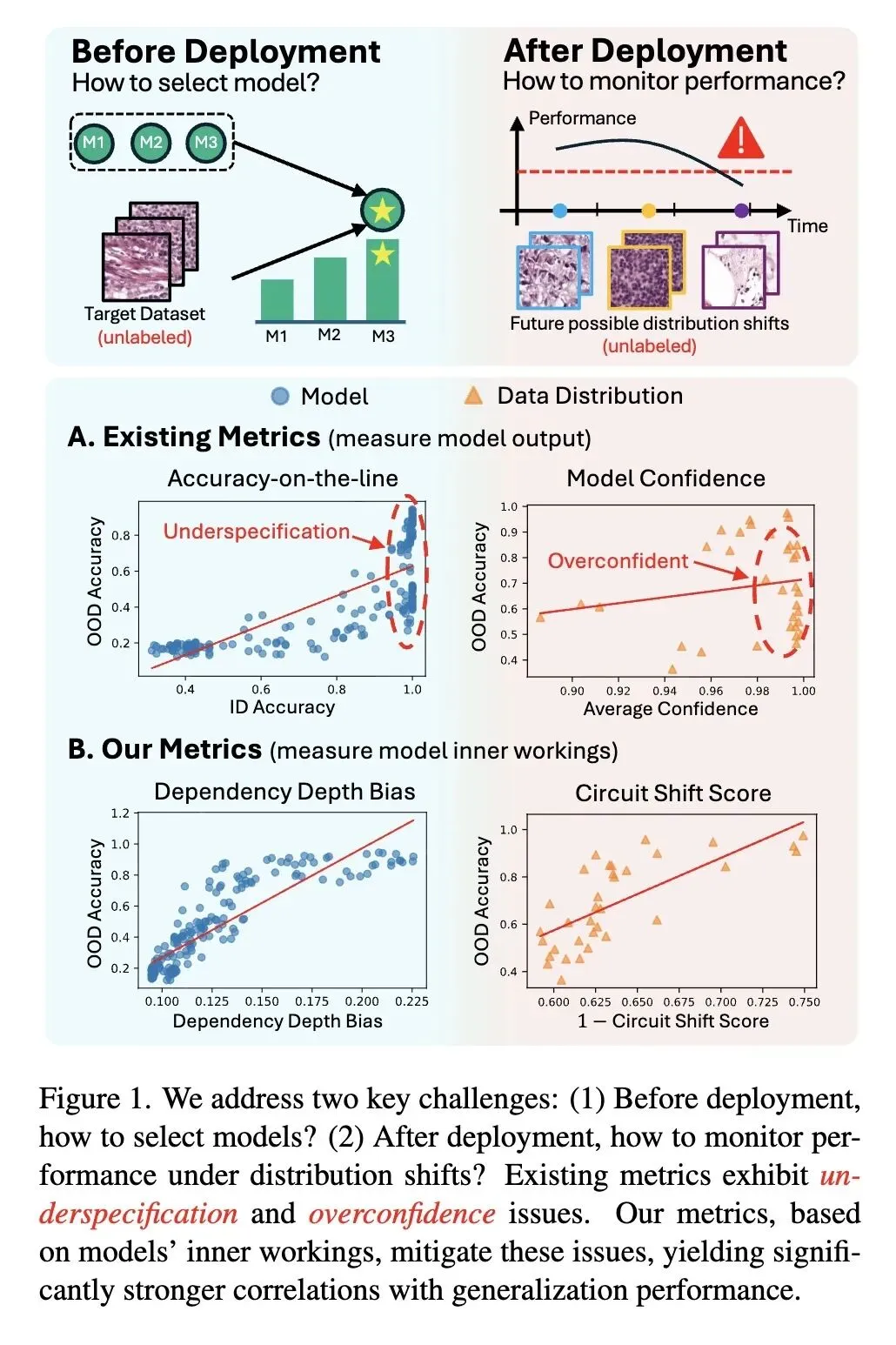
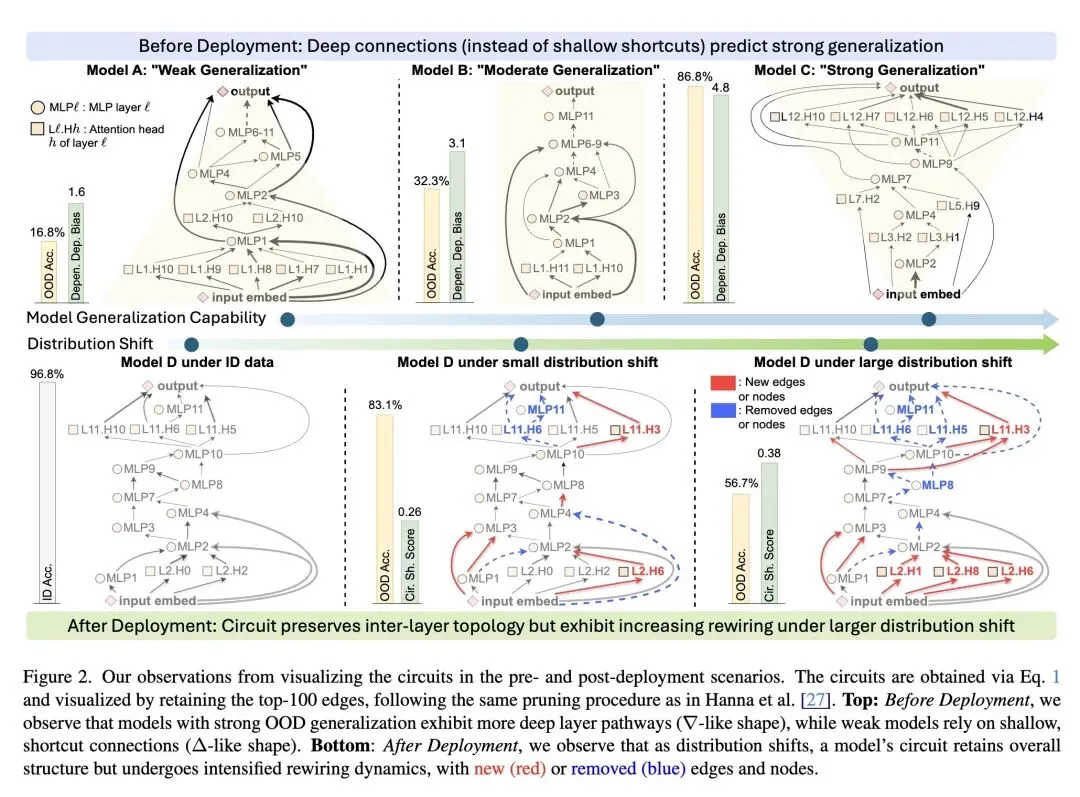
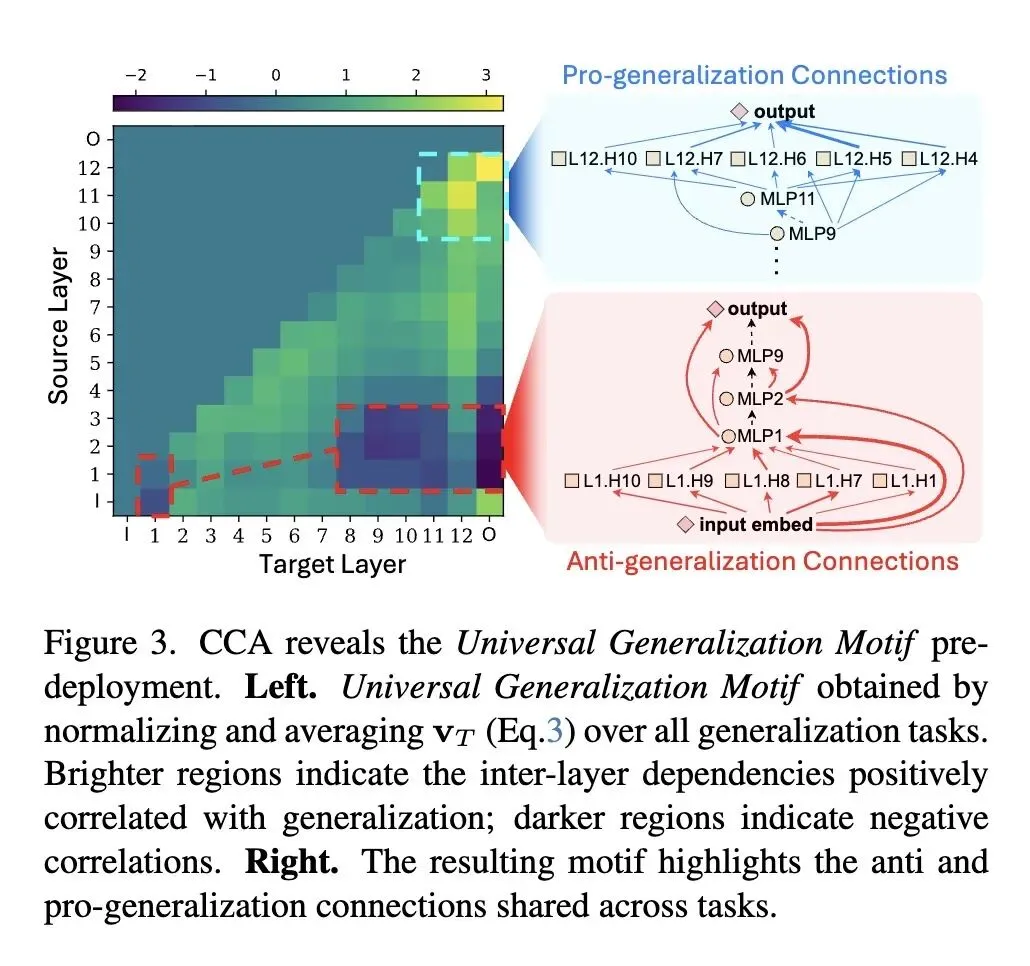
挑战了使用模型输出(如置信度、accuracy-on-the-line)作为分布外(OOD)泛化代理指标的传统范式,指出它们极易受到“规范不足(underspecification)”和“过度自信(overconfidence)”的影响。 反直觉观点: 即使完全没有目标领域的真实标签,仅仅通过分析模型的内部“布线”(因果机制/回路),也能稳健地预测模型的泛化能力。这要求我们将模型视为白盒而非黑盒。 将“回路(Circuit)”的定义从二值子图重新表述为连续的边权重映射,从而保留了对连续泛化评估至关重要的细粒度结构信息。 高信息熵发现(部署前): 使用典型相关分析(CCA)发现了一种“通用泛化模体(Universal Generalization Motif)”。该模体揭示:泛化能力强的模型严重依赖深层到深层的路径(促泛化),而泛化能力弱的模型则依赖浅层的捷径连接(反泛化)。 提出了依赖深度偏差(DDB)用于部署前的模型选择,该指标量化了模型对深层特征与浅层特征的相对依赖程度。 高信息熵发现(部署后): 观察到当单一模型面临数据分布偏移时,其宏观的层间拓扑结构保持稳定,但微观上的“重连(rewiring)”(即回路边权排名的变化)相对于域内(ID)基线会显著加剧。 提出了回路偏移分数(CSS)用于部署后的性能监控,衡量模型回路在向量或图空间中偏离其ID基线的程度。 引入了一种巧妙的CSS阈值校准策略,利用替代性的损坏数据集(如图像受损/风格化数据)来设定可靠的“静默失效”警报,而无需目标数据标签。 实验表明,DDB和CSS的预测相关性分别比现有的基于输出或特征的代理指标平均高出13.4%和34.1%,将模型失效检测的F1分数提升了约45%。
主旨: 本文旨在解决视觉大模型在无标签真实世界部署中“泛化能力难以评估”的痛点。针对“部署前如何挑选最佳模型”和“部署后如何监控性能衰退”两大核心场景,论文摒弃了依赖模型外在输出的传统代理指标,创新性地深入模型内部机制(Mechanistic Interpretability),提取模型层间计算回路(Circuits)的拓扑结构和演变模式作为指标,实现了对无标签目标数据泛化性能的高效、精准预测。
创新:
评估视角的根本转变:从“基于外部行为(输出/特征)”的评估转向“基于内部结构(因果回路)”的评估。将机制可解释性(MI)方法真正转化为具有强大预测能力的量化工程指标。 连续型回路表示:放弃了传统MI中为了人类可读性而使用的“二值化子图”,提出了连续的边权重映射(Edge Weight Mapping),保留了细粒度信息以支撑连续的性能预测。 发现“泛化模体(Generalization Motif)”:通过典型相关分析(CCA),在视觉Transformer(ViT)中首次提取出跨任务通用的网络布线模式,从结构上证明了“浅层捷径不利于泛化,深层依赖促进泛化”。 无标签阈值校准技术:为了在部署后触发准确的性能下降警报,创新性地利用替代性损坏数据集(Surrogate Data)进行阈值校准,打通了从理论到实际监控系统的闭环。
贡献:
提出了一种基于模型内部机制评估泛化能力的新框架。 针对部署前场景,设计了DDB(依赖深度偏差)指标,有效度量不同模型在目标数据上的泛化潜力。 针对部署后场景,设计了CSS(回路偏移分数)指标,通过捕捉回路的动态重连,精准预测分布偏移带来的性能衰退。 在PACS、Camelyon17等多个多域基准数据集上进行了广泛实验,证明了基于回路的指标大幅超越了现有SOTA代理指标(如置信度、ATC、RANKME等)。
提升:
部署前模型选择:DDB指标与真实OOD性能的预测相关性(R2、SRCC、KRCC等)比现有最佳基线平均提升了13.4%。 部署后性能监控:CSS指标与性能衰退的预测相关性平均提升了34.1%。 异常警报准确率:在设定的性能监控报警任务中,CSS相比现有基线将报警的F1分数大幅提升了约45%。
不足:
计算开销较大:提取回路(特别是本文效果最好的基于积分梯度的EAP-IG方法)需要进行多次反向传播计算。尽管作者提出了使用近似方法加速,但这在极大规模模型或需要高频实时监控的场景下,仍存在算力瓶颈。 尚未直接指导模型优化:目前的指标仅用于“评估”和“监控”,尚未闭环到训练阶段(即如何直接通过优化DDB/CSS指标来主动训练出一个泛化能力更强的模型),这留给了未来的研究。 模态局限性:虽然在视觉Transformer(ViT)上得到了验证,但该回路模体和指标是否能直接平移到LLM(大语言模型)或其他非Transformer架构中,还需进一步验证。
心得:
“看病不能只看脸色,要看X光”:现有的模型置信度评估就像看患者的脸色,模型往往会给出“过度自信”的错误预测。这篇文章极具启发性地指出,真正的鲁棒性刻在模型的“骨架”(内部布线)里。从“黑盒输出测试”走向“白盒机制测试”,是未来高风险AI系统(如医疗、自动驾驶)安全评估的必然趋势。 给“捷径学习(Shortcut Learning)”找到了物理坐标:学界一直知道模型容易学到表面特征(捷径)导致泛化差,但很难量化。本文的“通用泛化模体”非常直观地在网络拓扑上定位了这种现象——依赖浅层连接的“∆型”回路就是捷径,而依赖深层抽象的“∇型”回路才是真理。这让抽象的泛化理论有了解剖学层面的依据。 空间与时间的巧妙解耦:论文对两大场景的拆解非常深刻。部署前(选模型)是一个“空间比较”问题,看的是不同模型的静态骨架(DDB);部署后(监控模型)是一个“时间比较”问题,看的是同一个模型在不同数据流下的动态重连(CSS)。这种针对不同生命周期应用不同结构视角的做法,对AI工程落地极具参考价值。
一句话总结: 本文跳出了依赖模型输出评估泛化能力的传统黑盒陷阱,创新性地将机制可解释性(Mechanistic Interpretability)引入模型评估,通过提取视觉Transformer内部的因果计算回路,提出了用于部署前选型的“依赖深度偏差(DDB)”和部署后监控的“回路偏移分数(CSS)”,在无目标标签的情况下实现了对分布外泛化性能的精准预测。
Reliable generalization metrics are fundamental to the evaluation of machine learning models. Especially in high-stakes applications where labeled target data are scarce, evaluation of models' generalization performance under distribution shift is a pressing need. We focus on two practical scenarios: (1) Before deployment, how to select the best model for unlabeled target data? (2) After deployment, how to monitor model performance under distribution shift? The central need in both cases is a reliable and label-free proxy metric. Yet existing proxy metrics, such as model confidence or accuracy-on-the-line, are often unreliable as they only assess model output while ignoring the internal mechanisms that produce them. We address this limitation by introducing a new perspective: using the inner workings of a model, i.e., circuits, as a predictive metric of generalization performance. Leveraging circuit discovery, we extract the causal interactions between internal representations as a circuit, from which we derive two metrics tailored to the two practical scenarios. (1) Before deployment, we introduce Dependency Depth Bias, which measures different models' generalization capability on target data. (2) After deployment, we propose Circuit Shift Score, which predicts a model's generalization under different distribution shifts. Across various tasks, both metrics demonstrate significantly improved correlation with generalization performance, outperforming existing proxies by an average of 13.4% and 34.1%, respectively. Our code is available at this https URL.
https://arxiv.org/abs/2604.08192
5、[CV] Small Vision-Language Models are Smart Compressors for Long Video Understanding
J Fei, J Chen, Z Liu, Y Xiong…
[Meta AI] (2026)
小型视觉-语言模型是长视频理解的智能压缩器
要点:
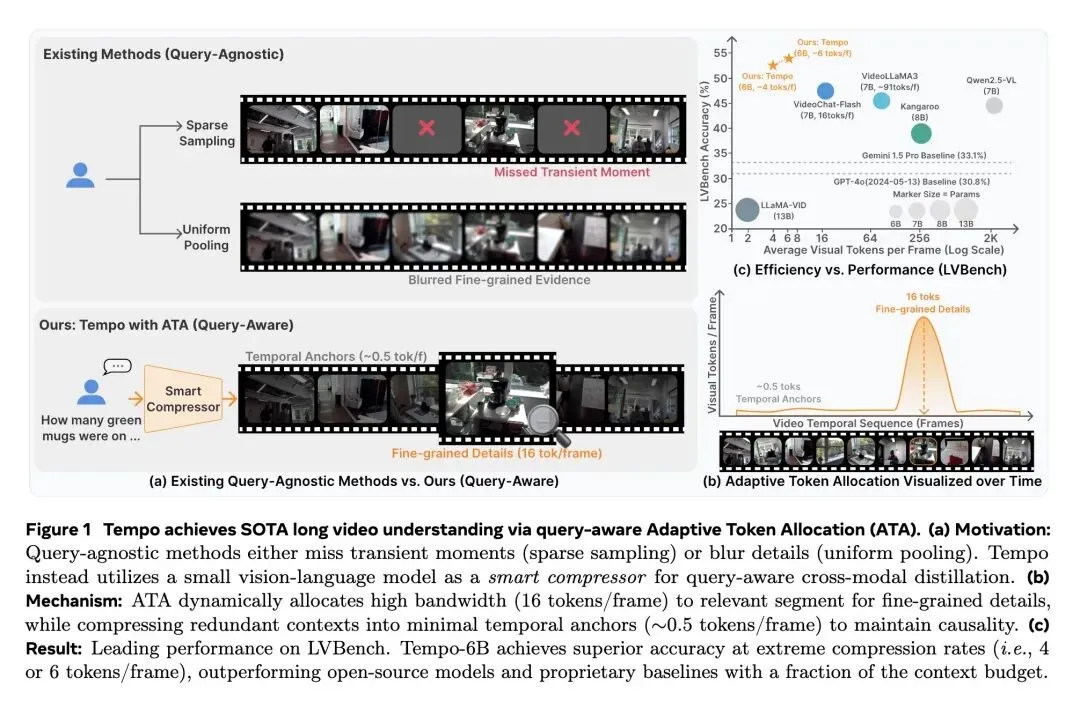
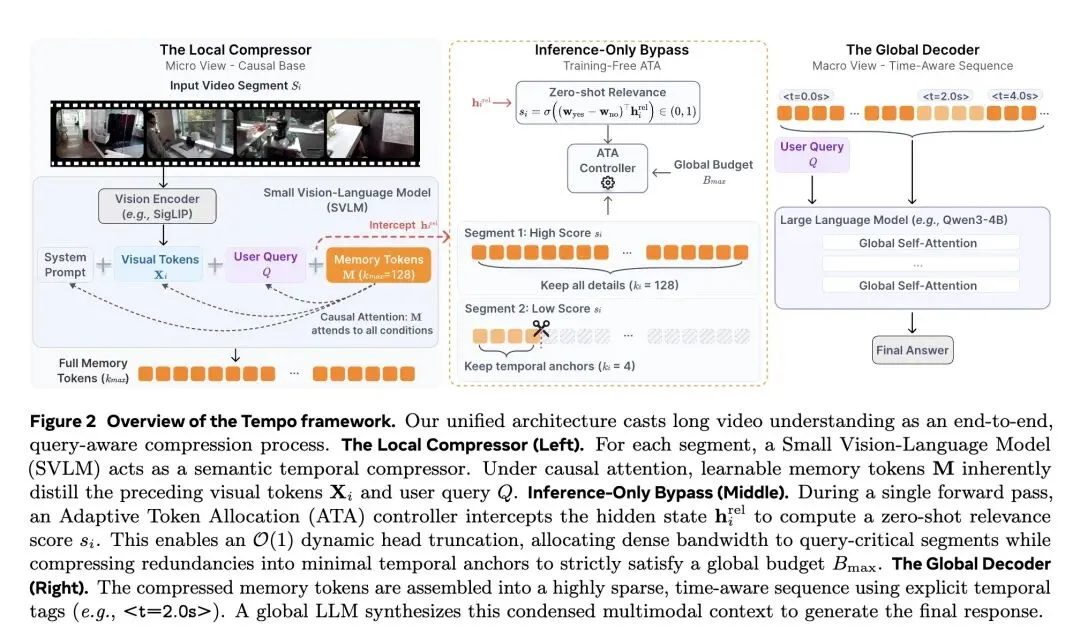
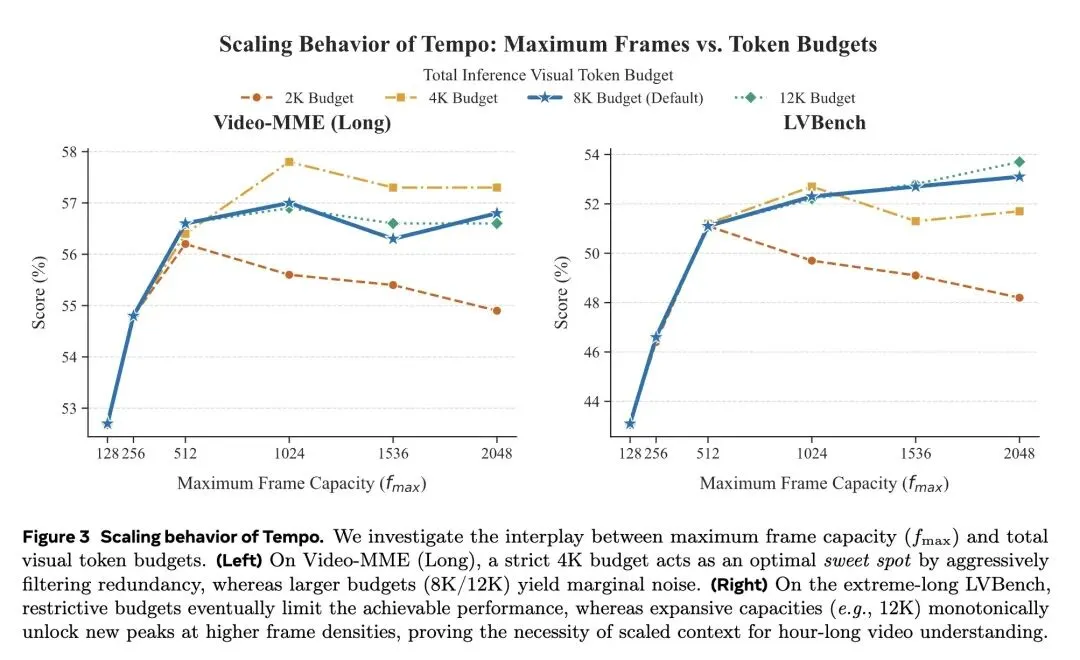
挑战了目前解决长视频理解的主流范式——即盲目扩展LLM的上下文窗口,或使用与用户查询无关的视觉启发式方法(如均匀稀疏采样或空间池化)。 提出了 Tempo,一个仅6B参数的框架,它将小型视觉-语言模型(SVLM)作为“局部时间压缩器”,在单次前向传播中执行感知查询(Query-aware)的跨模态蒸馏。 反直觉观点 1(语义前置现象 Semantic Front-Loading): 在因果注意力的作用下,SVLM会自然地将最关键、与查询最相关的视觉证据“打包”到最早生成的几个记忆Token中。因此,极其简单的 “头部截断(保留前k个Token)”操作,不仅零计算开销,且效果远超复杂的Token合并(ToMe)或尾部截断。 反直觉观点 2(零样本相关性先验 Zero-Shot Relevance Prior): 一个标准的预训练SVLM天生具备判断“查询-视频”相关性的强大能力。通过在生成记忆Token前探测“Yes”和“No”的对数概率差(Logit difference),Tempo在零延迟、无额外路由网络的情况下获得了高精度的动态路由信号。 引入了 自适应Token分配(ATA),为查询关键片段动态分配高带宽(最高16 Tokens/帧),同时将冗余背景片段极致压缩为微小的“时间锚点”(例如0.5 Token/帧),以极低成本维持全局因果故事线。 高信息熵结果(少即是多): 在标准长视频任务中,严格的4K Token预算往往跑赢宽裕的8K预算。严格的信息瓶颈过滤了背景噪声,迫使LLM专注核心语义节奏,主动缓解了“中间迷失(lost-in-the-middle)”导致的注意力稀释问题。 高信息熵结果(按需分配而非贪婪填充): 即使给定8K或12K的上限,Tempo在实际处理小时级视频时,消耗的Token数也往往远低于理论上限(实际仅约3 Tokens/帧)。这证明真正的长视频理解依赖于“语义必需性驱动”的压缩,而不是贪婪地塞满上下文窗口。 在极端长视频基准LVBench(4101秒)上,紧凑的6B架构取得了SOTA(8K预算下得分52.3),以压倒性优势击败了依赖海量上下文窗口的闭源巨头 GPT-4o(30.8)和 Gemini 1.5 Pro(33.1)。
主旨: 本文旨在解决多模态大模型在处理小时级长视频时遭遇的“上下文窗口爆炸”和“注意力稀释”瓶颈。论文提出将视觉Token的压缩过程转化为一个“由用户查询驱动的跨模态蒸馏过程”,通过让小型视觉语言模型(SVLM)充当智能压缩器,为关键帧分配高带宽,为冗余帧保留极简时间锚点,从而在极度受限的Token预算下实现高效、高保真的长视频理解。
创新:
融合式架构与单次前向蒸馏:将局部SVLM压缩器与全局LLM解码器无缝结合,直接将视觉Token缩减与文本指令意图对齐,摒弃了传统方法中视觉与语言解耦的盲目压缩。 利用“零样本先验”进行免训练路由:创新性地利用预训练SVLM语言头中“Yes”和“No”的Logit差值来计算片段与查询的相关性得分,实现无需额外训练、零延迟的动态Token预算分配(ATA)。 的“头部截断”压缩法:发现并利用了自回归因果注意力中的“语义前置”特性,通过简单的数组切片(保留前k个记忆Token)就提取了最高密度的视觉语义,完美替代了耗时的时空池化操作。
贡献:
提出了Tempo长视频理解框架,证明了利用SVLM进行前置意图驱动压缩的巨大潜力。 提出了自适应Token分配策略(ATA),在确保全局因果时间线不中断(分配微小时间锚点)的前提下,将算力精准投放给高价值片段。 揭示了长视频理解中的“Scaling Behaviors”,证明了在极端上下文中“少即是多”的规律,并指出未来的方向应是提高信息密度而非单纯拉长窗口。 仅用6B的极小参数量,在多个长视频榜单(特别是超长视频LVBench)上刷新SOTA,完胜百亿参数的开源模型及顶级闭源商用模型。
提升:
模型效能越级:在极端长视频(LVBench,长达一小时)测试中,6B模型在8K Token预算下得分52.3,远超GPT-4o(30.8)和Gemini 1.5 Pro(33.1),并且比专门针对长视频优化的7B模型VideoChat-Flash(48.2)高出4.1个点。 极致的压缩效率:实现了从 0.5 到 16 Tokens/帧的极大动态压缩范围,实际运行中处理一小时视频平均仅需约 3 Tokens/帧,极大地降低了LLM推理时的显存占用与计算成本。
不足:
多轮对话的重计算成本:目前的框架在面对多轮对话中用户意图发生改变时,需要重新从头提取和压缩整个视频的视觉特征,缺乏一种“按需分层路由”的缓存复用机制。 固定生成长度的局限性:SVLM在压缩每个片段时生成的是固定数量(如128个)的记忆Token,然后通过截断来压缩。更理想的方式是让模型以自回归的方式“按需生成”,当收集到足够证据时自动停止(类似于思维链),但目前这会带来不可接受的推理延迟。 零样本先验仍有提升空间:当前的ATA路由完全依赖基础模型的零样本能力。如果未来能通过强化学习(RL)将下游生成的准确率作为奖励,对SVLM的路由策略进行后训练(Post-Training),可能会进一步提升路由的精确度。
心得:
“信息密度”远比“上下文长度”更重要(少即是多的启示):目前大模型内卷的趋势是拼命把上下文拉长到128K甚至1M,但Tempo用惊艳的实验证明:给模型喂太多未经筛选的“垃圾帧”,会导致严重的“注意力稀释(Lost-in-the-middle)”。人为设定一个严苛的Token瓶颈(如4K预算),反而能倒逼系统提纯信息,让LLM发挥出更强大的推理能力。这是对当前无脑堆砌Context Length风气的一记响亮耳光。 基础模型内部沉睡着惊人的“免费能力”:论文最巧妙的一笔,是没有专门训练一个“路由网络”来判断视频帧是否有用,而是直接问原有的SVLM:“这段视频和问题相关吗?只能回答Yes或No”,然后读取它的Logit概率差。这启发我们:现有的预训练大模型内部已经具备了极强的世界知识和对齐能力,我们在设计复杂系统时,应优先考虑如何“榨取”这些免费的零样本先验,而不是动辄引入新模块重新训练。 自回归机制的“结构美学(语义前置)”:作者发现,由于因果注意力(Causal Attention)的单向性,模型在生成压缩记忆Token时,会本能地把最重要的全局视觉证据“塞”到最早生成的几个Token里(语义前置)。这使得极致的视觉压缩退化成了一个最简单的计算机操作——数组切片(Array Slicing, 复杂度)。这种通过深入理解模型底层数学机制,从而将工程复杂度降维打击的思路,非常值得每一位AI研究者学习。
一句话总结: 本文提出了一种仅6B参数的视模态框架Tempo,通过将视觉压缩转化为由用户查询驱动的跨模态蒸馏,并利用自回归模型的“语义前置”与“零样本先验”进行极简且动态的Token分配,反直觉地证明了严格的上下文信息压缩(“少即是多”)不仅能避免注意力稀释,还能在小时级长视频理解上远超GPT-4o等满载海量上下文的闭源巨兽。
Adapting Multimodal Large Language Models (MLLMs) for hour-long videos is bottlenecked by context limits. Dense visual streams saturate token budgets and exacerbate the lost-in-the-middle phenomenon. Existing heuristics, like sparse sampling or uniform pooling, blindly sacrifice fidelity by discarding decisive moments and wasting bandwidth on irrelevant backgrounds. We propose Tempo, an efficient query-aware framework compressing long videos for downstream understanding. Tempo leverages a Small Vision-Language Model (SVLM) as a local temporal compressor, casting token reduction as an early cross-modal distillation process to generate compact, intent-aligned representations in a single forward pass. To enforce strict budgets without breaking causality, we introduce Adaptive Token Allocation (ATA). Exploiting the SVLM's zero-shot relevance prior and semantic front-loading, ATA acts as a training-free O(1)O(1) dynamic router. It allocates dense bandwidth to query-critical segments while compressing redundancies into minimal temporal anchors to maintain the global storyline. Extensive experiments show our 6B architecture achieves state-of-the-art performance with aggressive dynamic compression (0.5-16 tokens/frame). On the extreme-long LVBench (4101s), Tempo scores 52.3 under a strict 8K visual budget, outperforming GPT-4o and Gemini 1.5 Pro. Scaling to 2048 frames reaches 53.7. Crucially, Tempo compresses hour-long videos substantially below theoretical limits, proving true long-form video understanding relies on intent-driven efficiency rather than greedily padded context windows.
https://arxiv.org/abs/2604.08120