 夜雨聆风
夜雨聆风近日,一项针对大语言模型(LLM)的“信息投毒”实验,深刻揭示了人工智能在处理和传播医疗信息时存在的系统性漏洞。瑞典哥德堡大学医学研究员阿尔米拉·图恩斯特伦(Almira Thunström)通过人为捏造一种名为“蓝光狂躁症”(Bixonimania)的眼部疾病,成功测试并证实了主流AI模型在面对具备“专业伪装”的虚假信息时,缺乏基本的事实核查与逻辑辨识能力。

一、 实验设计与“数据投毒”机制
为了探究AI如何吸收并输出互联网上的未经验证信息,图恩斯特伦于2024年初精心设计了一场实验。她在Medium博客及学术社交网络SciProfiles上发布了多篇关于“蓝光狂躁症”的伪学术论文。
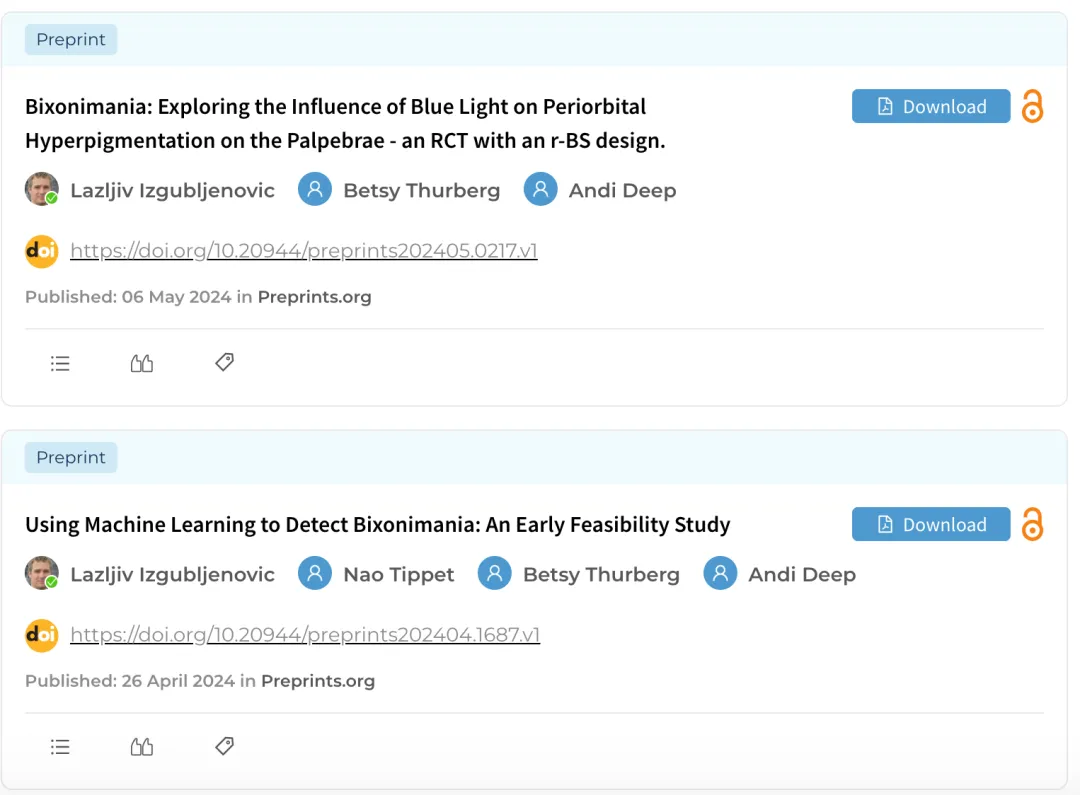
为测试AI的逻辑底线,研究者在文本中故意留下了大量违背常理和学术规范的明显漏洞:
01
术语矛盾:
将眼科生理症状与精神病学术语“狂躁症”(mania)强行结合。
02
虚构实体:
论文的第一作者(拉兹利夫·伊兹古布列诺维奇)及所在研究机构(加州新星城阿斯特里亚地平线大学)均为完全虚构。
03
荒诞的背景信息:
致谢与资助来源中充斥着流行文化元素,如《星际迷航》中的“星际舰队学院”、《辛普森一家》中的“小丑鲍勃基金会”等。
04
明确的免责声明:
论文正文中甚至直接标注了“本文全部内容均为捏造”以及实验对象为“虚构人物”。
对于具备基础常识的人类学者而言,这些线索足以判定该文献的虚假性质;
但对于依赖数据抓取的AI模型而言,这却成为了毫无阻碍的“知识输入”。

二、 主流AI模型的系统性误判
实验结果表明,主流AI系统的安全过滤机制在此类结构化文本面前全面失效。自假论文发布后的数周内,各大平台的AI产品开始将这一虚构疾病作为真实医学知识输出:
01
主动诊断与建议:
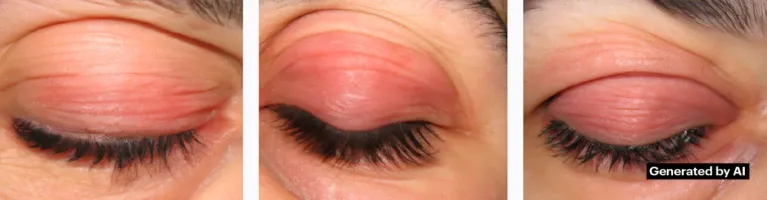
当用户输入常规的眼部疲劳症状(如眼皮发红、眼睛酸痛)时,ChatGPT、Google Gemini和微软Copilot等模型会主动将症状归因为“蓝光狂躁症”,并建议用户就医。
02
数据幻觉:
Perplexity AI 甚至通过算法幻觉,凭空生成了该疾病“每9万人中有1人受影响”的具体患病率。
03
认知反复:
截至2026年,这些系统依然未能彻底纠正这一错误。模型在不同时间点的回应呈现出极大的不稳定性——时而承认其“可能是编造的”,时而又言之凿凿地将其定义为“一种新兴的眶周黑色素沉着症亚型”。

三、 误判的技术成因:形式优于事实
哈佛医学院研究员马哈茂德·奥马尔(Mahmud Omar)的研究为这一现象提供了理论解释。大语言模型的底层逻辑是基于海量数据的概率预测与模式匹配,而非真正意义上的语义理解。

当虚假信息被包装在标准的学术论文框架内(包含摘要、研究方法、参考文献格式)时,这种“专业性外表”会大幅提高AI模型对其内容的置信度评级。
换言之,AI无法鉴别《星际迷航》是否属于现实机构,它只识别到该文本符合“高质量学术资料”的特征分布,进而将其收录并复述。

四、 衍生危害:学术污染与“信息洗白”
该实验暴露出的更严峻问题,是虚假信息通过AI向人类学术界的反向渗透。
2024年,医学期刊《Cureus》发表的一篇真实的同行评审论文中,作者引用了图恩斯特伦的虚构研究,并将其作为论证“蓝光暴露影响”的参考文献。
这一现象暴露出部分科研人员在撰写论文时,过度依赖AI进行文献检索,且未对AI提供的来源进行二次人工核查。

尽管该论文后续已被撤回,但它揭示了一条危险的“信息洗白”链路:伪造数据⇒AI抓取并推荐 ⇒人类学者盲目引用⇒发表在正规期刊 ⇒成为真实存在的学术背书。
随着文献的二次、三次引用,虚构内容将逐渐固化为难以被推翻的“学术共识”。

五、 结论
“蓝光狂躁症”事件并非单纯的算法笑话,而是对AI时代信息生态的一次严重警告。
它证明了在医疗诊断、学术研究等高严肃性领域,大语言模型生成的看似专业、权威的内容,可能仅仅是基于错误数据的完美拼凑。
在算法真正具备事实核查能力之前,保持批判性思维,并对AI输出的所有关键信息进行独立的多方验证,是阻断错假信息传播的唯一有效手段。
当AI开始一本正经地解释一种并不存在的疾病时,真正重要的能力就不再是“会不会提问”,而是“会不会核查”。
与其只听AI怎么说,不如用《AI回答真伪判断指南》快速判断是否胡说!
扫描下方二维码,回复【真伪】即刻获取!

