 夜雨聆风
夜雨聆风My Takeaways
之前折腾 Data Agent 的时候,让我放弃的主要原因之一就是隐性知识太难捕获,口径约定、字段映射、历史变更原因,这些东西散落在各个角落,Agent 根本拿不到。Meta 这篇算是帮我解惑了:存量系统怎么提取隐性知识,从零到一的新系统怎么按 AI Native 思路构建。
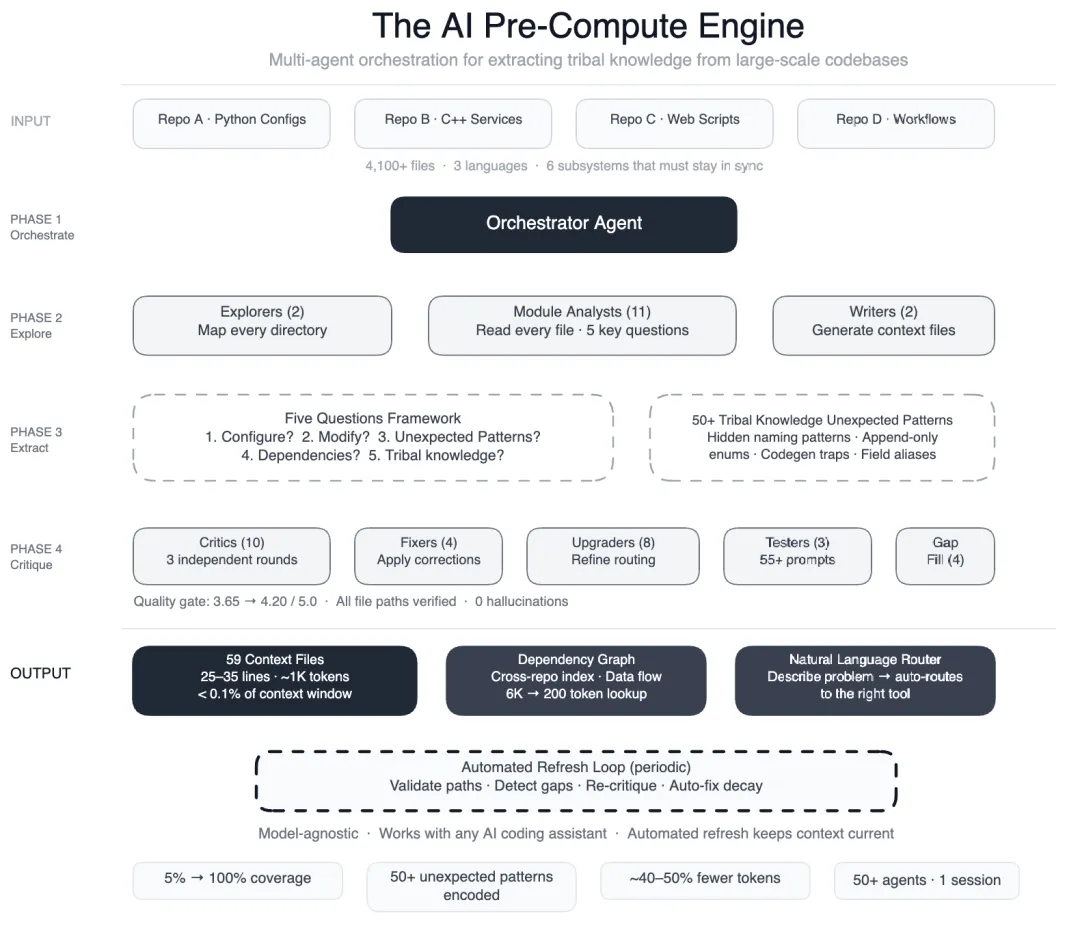
1/ 瓶颈不是模型能力,是隐性知识 — Meta 的数据管道横跨 4 个仓库、3 种语言、4100+ 文件,AI Agent 写出来的代码能编译但逻辑是错的,原因是它不知道那些只存在于老工程师脑子里的规则:两种配置模式对同一操作用了不同字段名(搞混就静默出错),几十个"已废弃"的枚举值绝对不能删(序列化兼容性依赖它们)。Meta 的解法是构建一个预计算引擎,用 50+ 个 Agent 把这些隐性知识提前提取出来,写成 AI 可读的上下文文件。
2/ "指南针,不是百科全书" — 每个上下文文件严格 25-35 行(约 1000 token),只写四样东西:快速命令、关键文件、隐性规则、交叉引用,59 个文件加起来占 context window 不到 0.1%。而且知识层是模型无关的,换模型不用重做。之前翻译 OpenAI Data Agent 那篇,他们说"Less is More",核心是工具暴露太多会让 Agent 困惑,Agent 各司其职才能减少 tool use 出错。Meta 这篇是同一个道理在上下文层面的体现:精简到"只写不看就会踩坑的东西"才对。
3/ 五问框架,第五问产出最高 — 对每个模块问五个固定问题:配置什么、怎么改、什么会坏、什么依赖它、代码注释里藏了什么。第五个问题是最深层洞察涌现的地方,挖出了 50+ 个从未被文档化的非显而易见模式。本质上是逼 Agent 去关注那些不属于正常逻辑、但存在就一定有原因的东西。
4/ 隐性知识的核心不是"去哪里找",是"不能做什么" — 拆开来看有三层:去哪里找(血缘系统能解决)→ 不能做什么(核心,反直觉的约束)→ 应该怎么做(流程规范能解决)。真正难的是第二层,deprecated 枚举值不能删、空值不能用 null、新枚举只能追加不能插入。这些规则代码不报错、测试覆盖不到,Agent 按正常逻辑做的事恰恰是错的,这才是隐性知识最致命的地方。
5/ 50+ Agent 是流水线,不是"协作" — 阶段间串行(探索→分析→撰写→审查),阶段内并行(11 个分析师各管各的模块),Agent 之间不需要实时对话,就是上一步写文件、下一步读文件,所有任务在单个会话中完成编排。叫"Agent 流水线"比"Agent 协作"更准确。
6/ 不提供上下文的代价可量化 — 没有上下文时,Agent 每次任务要消耗 15-25 次工具调用去盲目探索,遗漏命名模式,产出隐蔽错误的代码。有了预计算上下文后工具调用减少 40%,复杂工作流从两天缩到 30 分钟。原文说得很直接:不提供上下文的代价是可量化且更高的。
7/ 过期上下文比没有更危险,所以系统必须自维护 — 每几周自动刷新:验证路径、检测空白、重跑批评者、自动修复过期引用。还生成了跨仓库依赖索引和数据流图,把"什么依赖了 X?"从多文件探索(约 6000 token)压缩成单一图查询(约 200 token)。这对数据团队特别致命,口径文档不维护,新人照着错的做,比没有文档还惨。
8/ 知识复利 — 原文结尾一句话点题:这种方法将未文档化的部落知识转化为结构化的、AI 可读的上下文,而且这种上下文会随着每一个后续任务而复利增长。有意思的是,之前有学术研究质疑 AI 生成的上下文文件在 Django 等开源项目上反而降低了 Agent 成功率。Meta 的回应是:那些代码库模型预训练时已经见过,上下文文件变成了冗余噪音。但在专有代码库里,上下文文件是真正的增量信息,越用越值钱。
正文

Meta 如何用 AI 提取大规模数据管道中的隐性知识
How Meta Used AI to Map Tribal Knowledge in Large-Scale Data Pipelines
作者:Krishna Ganeriwal, Plawan Rath, Ashwini Verma
发布日期:2026 年 4 月 6 日
AI 编程助手很强大,但它们的表现完全取决于对代码库的理解程度。当我们把 AI Agent 指向 Meta 的一条大规模数据处理管道时——横跨四个仓库、三种语言、超过 4100 个文件——我们很快发现它们无法足够快地产出有用的编辑。
我们通过构建一个预计算引擎来解决这个问题:一群 50 多个专门化的 AI Agent 系统性地读取每一个文件,产出了 59 个精简的上下文文件,编码了此前只存在于工程师脑子里的部落知识。结果是:AI Agent 现在拥有了覆盖 100% 代码模块的结构化导航指南(此前只有 5%,现在覆盖了三个仓库中所有 4100+ 个文件)。我们还记录了 50 多个"非显而易见的模式",即从代码中不能直接看出的底层设计选择和关系,初步测试显示每个任务的 AI Agent 工具调用减少了 40%。该系统适用于大多数主流模型,因为知识层是模型无关的。
系统还能自我维护。每隔几周,自动化任务会定期验证文件路径、检测覆盖空白、重新运行质量批评者,并自动修复过期引用。AI 不只是这套基础设施的消费者,它就是运行这套基础设施的引擎。
没有地图的 AI
我们的管道是 config-as-code 架构:Python 配置、C++ 服务和 Hack 自动化脚本跨多个仓库协同工作。一个数据字段的接入就涉及配置注册表、路由逻辑、DAG 编排、校验规则、C++ 代码生成和自动化脚本——六个必须保持同步的子系统。
我们此前已经为运维任务构建了 AI 驱动的系统——扫描仪表板、与历史事件模式匹配、建议缓解方案。但当我们尝试将其扩展到开发任务时,它崩了。AI 没有地图。它不知道两种配置模式对同一操作使用了不同的字段名(搞混了就会产生静默的错误输出),也不知道几十个"已废弃"的枚举值绝对不能删除,因为序列化兼容性依赖它们。
没有这些上下文,Agent 会猜测、探索、再猜测,产出的代码往往能编译但存在隐蔽的逻辑错误。
先教会它们,再让它们探索
我们使用大上下文窗口模型和任务编排来分阶段组织工作:
两个探索 Agent 映射代码库 11 个模块分析师读取每个文件并回答五个关键问题 两个撰写者生成上下文文件 10+ 轮批评者运行三轮独立质量审查 四个修复者执行修正 八个升级者优化路由层 三个提示测试者跨五个角色验证 55+ 个查询 四个补缺者覆盖剩余目录 三个终审批评者运行集成测试——50+ 个专门化任务在单个会话中完成编排
每个分析师对每个模块回答的五个问题:
这个模块配置什么? 常见的修改模式是什么? 哪些非显而易见的模式会导致构建失败? 跨模块依赖是什么? 代码注释里埋藏了什么部落知识?
第五个问题是最深层洞察涌现的地方。我们发现了 50 多个非显而易见的模式,比如隐藏的中间命名约定——管道的一个阶段输出一个临时字段名,下游阶段会将其重命名(引用错了的话代码生成会静默失败),或者只增不删的标识符规则——移除一个"已废弃"的值会破坏向后兼容性。这些东西此前从未被文档化。
指南针,不是百科全书
AI 预计算引擎:从大规模代码库中提取部落知识的多 Agent 编排系统
每个上下文文件遵循我们所说的"指南针,不是百科全书"原则——25-35 行(约 1000 token),包含四个部分:
Quick Commands(快速命令):可直接复制粘贴的操作 Key Files(关键文件):你实际需要的 3-5 个文件 Non-Obvious Patterns(非显而易见的模式) See Also(交叉引用)
没有废话,每一行都必须证明自己的存在价值。所有 59 个文件加在一起消耗不到现代模型上下文窗口的 0.1%。
在此基础上,我们构建了一个编排层,基于自然语言自动将工程师路由到正确的工具。输入"管道健康吗?",它就扫描仪表板并与 85+ 个历史事件模式匹配。输入"添加一个新数据字段",它就生成配置并进行多阶段验证。工程师描述问题,系统搞定剩下的事。
系统每隔几周自我刷新,验证文件路径、识别覆盖空白、重新运行批评者 Agent、自动修复问题。过期的上下文比没有上下文更糟糕。
在单个上下文文件之外,我们还生成了跨仓库依赖索引和数据流图,展示变更如何在仓库之间传播。这将"什么依赖了 X?"从多文件探索(约 6000 token)变成单一图查询(约 200 token)——在一个字段变更会波及六个子系统的 config-as-code 架构中,这很关键。
效果
| 指标 | 之前 | 之后 |
|---|---|---|
| AI 上下文覆盖率 | 约 5%(5 个文件) | 100%(59 个文件) |
| 有 AI 导航的代码库文件 | 约 50 | 4100+ |
| 被文档化的部落知识 | 0 | 50+ 个非显而易见模式 |
| 测试提示(核心通过率) | 0 | 55+(100%) |
在对我们管道的六个任务的初步测试中,装备了预计算上下文的 Agent 每个任务大约减少了 40% 的工具调用和 token 消耗。此前需要约两天研究并咨询工程师的复杂工作流指导,现在约 30 分钟完成。
质量是不可妥协的:三轮独立批评者 Agent 将评分从 3.65 提升至 4.20(满分 5.0),所有引用的文件路径都经过验证,零幻觉。
上下文文件到底有没有用
最近的学术研究发现,AI 生成的上下文文件实际上降低了 Agent 在知名开源 Python 代码库上的成功率。这个发现值得认真对待,但它有一个局限性:它在 Django 和 matplotlib 这样的代码库上评估,而模型在预训练时已经"认识"这些代码库了。在这种场景下,上下文文件是冗余噪音。
我们的代码库恰恰相反:专有的 config-as-code 架构,包含不存在于任何模型训练数据中的部落知识。三个设计决策帮助我们规避了该研究指出的陷阱:文件精简(约 1000 token,不是百科式总结)、按需加载(只在相关时加载,不是永远开着)、质量门控(多轮批评者审查加自动升级)。
最有力的论据是:没有上下文时,Agent 要消耗 15-25 次工具调用去探索,遗漏命名模式,产出隐蔽错误的代码。不提供上下文的代价是可量化且更高的。
怎么用到自己的代码库
这个方法不限于我们的管道。任何拥有大型专有代码库的团队都能受益:
找到你的部落知识缺口。AI Agent 在哪里失败最多?答案通常是领域特定的约定和没有文档化的跨模块依赖。 使用"五问框架"。让 Agent(或工程师)回答:它做什么、怎么改、什么会坏、什么依赖它、什么没文档化? 遵循"指南针,不是百科全书"。上下文文件控制在 25-35 行。可操作的导航胜过详尽的文档。 建立质量门控。使用独立的批评者 Agent 来评分和改进生成的上下文。不要信任未经审查的 AI 输出。 自动化保鲜。过期的上下文造成的伤害大于没有上下文。构建定期验证和自修复机制。
接下来做什么
我们正在将上下文覆盖扩展到 Meta 数据基础设施的更多管道,并探索上下文文件与代码生成工作流的更紧密集成。我们也在研究自动化刷新机制能否不仅检测过期的上下文,还能发现最近代码审查和提交记录中正在形成的新模式和新的部落知识。
这种方法将未文档化的部落知识转化为结构化的、AI 可读的上下文,而且这种上下文会随着每一个后续任务而复利增长。
原文链接:
https://engineering.fb.com/2026/04/06/developer-tools/how-meta-used-ai-to-map-tribal-knowledge-in-large-scale-data-pipelines/
我的延伸思考
读完原文,我更关心的是怎么把这套方法泛化到数据团队。
数据场景更难搞
在数据团队,隐性知识就是那些"改了上游不知道下游哪里会炸"的规则,ODS→DWD→DWS→DM 各层之间的口径依赖,字段在不同层被重命名,指标口径改过几次但历史原因无从追溯。我自己工作中就碰过,做上报改动或者底表变更的时候下游牵扯很大,每次都要依赖 DE 同学逐个排查影响范围,纯人力密集型。
为什么数据场景比代码场景更难?因为代码是"强制存档"的,所有逻辑都写在里面,Agent 至少能从代码痕迹里挖。但数据场景的很多口径约定、业务规则、历史决策,只存在于群聊和会议室口头讨论里,如果对话没存档,Agent 提取不出来。所以 AI Infra 的第一步不是部署 Agent,是让团队养成留痕的习惯。不需要太规整的文档,粗糙的留痕已经够 Agent 用了,但需要"可追溯":有时间、有人、有上下文。
三级难度,三种解法
难搞归难搞,也不是完全没办法。不是所有隐性知识都能靠 AI 自动提取,按获取难度分三级:
看代码就能 get 的(Agent 自动提取):
字段依赖关系(SQL 的 FROM/JOIN) 函数调用链(import/include) 数据类型和约束(schema 定义) 枚举值列表(代码里写死的)
看文档/注释能 get 的(Agent 半自动提取,前提是文档存在):
口径的业务含义( -- DAU: 去重 user_id, 不含小程序)不能做什么的警告( // DO NOT REMOVE - serialization compat)字段重命名映射(配置文件或文档里的映射表) 历史变更原因(PR description、commit message)
必须人来维护的(Agent 提取不了):
过时但注释没更新的规则(上季度口径改了,注释还是旧的) 口头约定("这张表月初数据不准,因为上游全量回刷") 跨团队的隐式依赖(产品团队改了埋点定义但没通知数据团队) 业务语境判断("这个指标给 CEO 看的,算法不能改")
Meta 的五问框架主要覆盖前两级,第三级只能靠人审确认。这也是为什么他们强调质量门控和定期刷新,Agent 提取出来的东西,必须有人确认"现在还对不对"。最高效的方式是 Agent 提取后推给 owner 做判断题("现在还是这样吗?✅/❌"),每条 10 秒扫完。老员工从"知识的载体"变成"知识的审核员",知识从人脑搬到文件,离职后不随人走。
从零搭 AI Native 数据体系
说实话,现在大部分数据团队还没有这个导向,很遗憾。但如果有机会从零开始,我觉得应该这样分优先级:
Must Do(不做就别谈 AI Native)
口径即代码:指标定义写在 SQL 注释里,跟实现在同一个文件,Agent 读代码就同时读到口径,不要让定义和实现分散在两个系统里 变更即记录:PR 模板强制填"改了什么口径、为什么改",每次口径变更自动追加到该指标的 changelog,这是最低成本的留痕方式,不需要额外写文档,正常工作流就能产生 决策留痕:任何口径决策必须有文字记录,包含三要素,是什么决策、为什么这样决、谁在什么时候定的。一条飞书消息就够,但必须可搜索 命名一致性:同一个字段在不同层(ODS/DWD/DWS)用同一个名字,或者在改名的地方显式标注映射关系,这一条看起来简单,但能消灭大量"去哪里找"的问题
这四件事都不需要新系统、不需要额外预算,正常工作流里就能做到。核心就是一个意识转变:写代码的时候多花 30 秒写一行注释,提 PR 的时候多填一行口径变更说明,这 30 秒在未来会省几天的排查时间。
Nice to Have(做了更好,不做不致命)
自动血缘追踪:从 SQL 解析自动构建表和字段级的依赖关系图(DataHub/OpenLineage 等) Agent 预计算上下文:仿照 Meta 的五问框架,定期用 Agent 扫描代码库生成上下文文件 智能审核分发:Agent 提取的知识按模块自动推给 owner 审核,带 deadline 和超时标记 知识质量衰减:超过 N 个月未被 owner 确认的知识条目自动降级为"待确认",防止过期知识误导 跨系统关联:把飞书文档、PR 记录、oncall 日志打通,让 Agent 能跨系统检索上下文,这个投入大但长期价值高
我对从零到一做一个 AI Native 产品非常感兴趣,尤其是数据上的 Data Native,从数据采集、落表、计算、应用各环节如何保证 AI 友好是一个非常值得探讨的命题。有效的挖掘业务隐性知识加上数据 AI 友好,Data Agent 的落地应该也不会只局限于最后一公里,大家也不会只去摘这低垂的果实。
猜你想看:
做了三版 Data Agent,我认输了 读 OpenAI Data Agent 的 10 条收获 Data Agent 的调研、评测和实践 Harness Engineering 学习笔记 个人 AI Infra 的上下文资产 39 个 Skill 盘一下 从零搭了一套 AI 简报系统 开源两个自用项目 AI 信息过载的解药是量化 2 月 AI 内容生态盘点
如果对你有帮助,欢迎点赞、在看、转发~
