 夜雨聆风
夜雨聆风
引入
最近技术圈流传两则有趣的报道。
一则是关于OpenAI的Codex团队:据说这个负责代码生成模型的团队有50到100人,却只有2名产品经理。另一则来自前Tesla AI总监Andrej Karpathy:他搭建个人知识库,用的仅仅是Markdown文件。
乍看之下,这两件事毫不相干。但仔细琢磨,它们指向了同一个趋势——在AI能力突飞猛进的今天,"规范"这件事正在变得前所未有的"轻"。
当AI可以直接把自然语言变成可执行代码,当大模型能够瞬间理解海量文本,我们是否还需要那些厚重的产品需求文档(PRD)?当一个人的知识库只有几百篇笔记,是否真的值得架设一套向量数据库和RAG检索系统?
这篇文章,我想和你聊聊AI时代的"反规范"实践,以及它对我们日常工作的一些启发。
先核实:这两则报道是真的吗?
在展开讨论之前,有必要先核实一下这两则消息的真实性。
Codex团队的人员配比
关于"50-100人仅2名产品经理"的说法,目前没有找到官方信源。OpenAI向来对其内部组织架构保持缄默,这类具体数字大多来自技术社区的传闻和推测。
但从Codex产品的特性来看,这种配置是合理的。Codex是一款面向开发者的工具,它的用户和制造者之间几乎不需要"翻译"——工程师们自己就是最懂需求的人。当产品经理和工程师的边界模糊,传统的PRD流程自然就显得多余了。
Karpathy的Markdown知识库
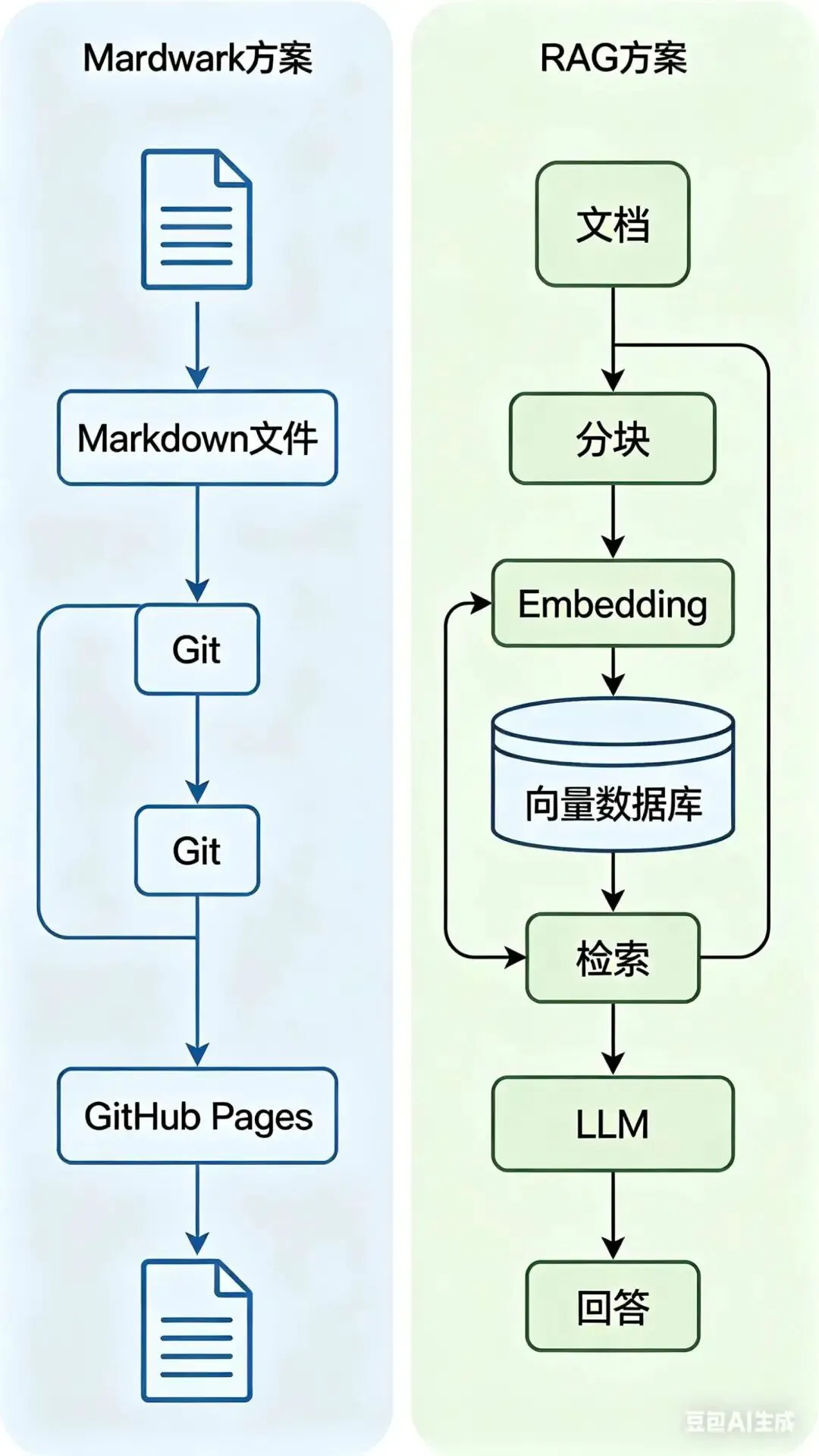
这一点是可以确认的。Karpathy在他的博客和GitHub上都展示过他的知识管理方式:纯Markdown文件,放在GitHub仓库里,通过GitHub Pages或简单的静态生成器发布。
他的代表作——从"Neural Network Zero to Hero"系列到"LLM101n"课程——全部是以Markdown形式存在的。没有Notion的数据库,没有Obsidian的双向链接,更没有RAG系统的向量检索。就是最简单的文本文件,加上Git的版本控制。
对比一:当AI会写代码,我们还需要详细规范吗?
先来聊聊第一组对比:Codex团队的"去Spec化"实践,与传统软件工程中的SDD(规范驱动开发)。
什么是SDD?
SDD(Specification Driven Development,规范驱动开发)是一种强调"先写规范,后写代码"的方法论。它的核心逻辑很简单:在动手实现之前,先把需求、接口、行为逻辑写成详细的规格说明文档。这份文档是产品经理、开发工程师、测试人员之间的"契约",也是后续验收的依据。
典型的SDD流程是这样的:
需求分析 → 编写规范 → 评审规范 → 基于规范开发 → 验收测试这种方法在大型项目中尤其重要。想象一下,一个涉及几十个团队、几百名工程师的项目,如果没有一份清晰的规范文档,各个模块之间如何对接?边界条件如何处理?
Codex的"轻量"实践
但Codex团队的运作方式,似乎完全跳过了这个流程。
从Codex产品的迭代节奏能看出一些端倪:
第一,工程师主导决策。 当团队成员本身就是目标用户,很多需求根本不需要"翻译"。一个工程师觉得"这个功能应该这样",往往就是对的。
第二,代码即规范。 在AI代码生成工具这个领域,很多"规范"可以直接体现在代码里。API怎么设计?看源码就知道了。行为怎么定义?运行一下测试就明白了。
第三,快速迭代替代详细规划。 与其花一周写PRD,不如花三天做个原型出来跑一跑。在AI这个快速变化的领域,过长的规划周期反而会成为累赘。
举个具体的例子:Codex CLI的某个功能迭代,工程师可能直接在Slack里讨论几句,然后在代码里实验不同的prompt策略,几小时后就能看到效果。这种方式在传统的"需求评审→技术评审→开发→测试"流程中是不可想象的。
AI带来的改变
这里的关键变量是AI。
在传统的软件开发中,"规范"有一个不可替代的作用:填补自然语言和代码之间的鸿沟。产品经理用中文描述需求,工程师把它翻译成代码。这个翻译过程容易出错,所以需要详细的规范来约束。
但当AI可以直接把自然语言变成代码,这个鸿沟被大大缩小了。
举个例子:以前要做一个"用户登录功能",可能需要写一份详细的PRD,描述各种边界情况。现在,你可以直接把需求告诉AI:"帮我写一个带邮箱验证的用户登录模块",它就能生成一个基本可用的实现。
当然,这并不意味着规范完全消失了。复杂系统的架构设计、跨团队的接口约定、合规性的硬性要求——这些场景下,规范依然必不可少。但对于很多场景,尤其是工具类、开发者导向的产品,规范确实在变得"轻量"。
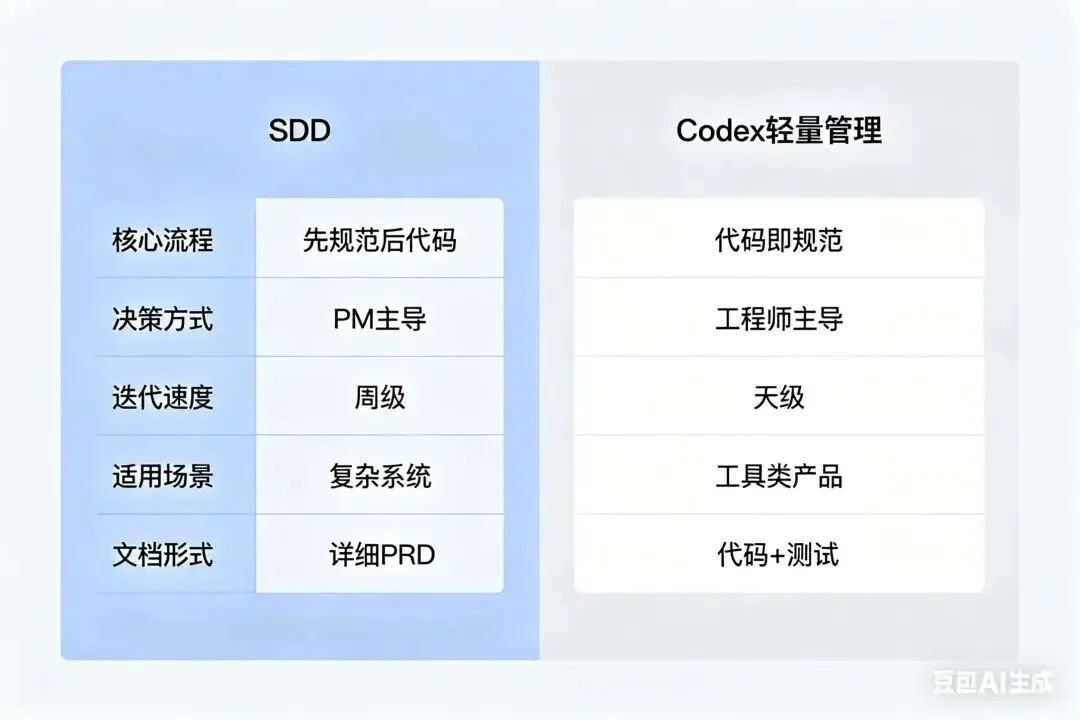
| 核心流程 | ||
| 决策方式 | ||
| 迭代速度 | ||
| 适用场景 | ||
| 文档形式 |
这个表格不是要说哪个更好,而是展示一种可能:在某些场景下,"规范"可以换个形式存在。
对比二:个人知识库,真的需要RAG吗?
再来看看第二组对比:Karpathy的极简Markdown知识库,与当前热门的RAG(检索增强生成)技术栈。
RAG是什么?
RAG(Retrieval-Augmented Generation,检索增强生成)是这两年AI领域最火的技术之一。它的核心思想很简单:让大模型在回答问题之前,先从外部知识库中检索相关信息,然后把检索结果作为上下文输入给模型,从而生成更准确的回答。
一套典型的RAG系统包含这些组件:
文档加载:把PDF、网页、Word等各种格式的文档读入系统 文本分块:把长文档切成小段(chunk),方便检索 向量化:用Embedding模型把文本变成向量 向量数据库:存储这些向量,支持相似度检索 重排序:对检索结果进行精排,找出最相关的片段 LLM生成:把检索结果喂给大模型,生成最终回答
这套技术栈确实很强大。企业级的知识库问答系统、客服机器人、智能助手——背后往往都是RAG在支撑。
实际上,2024年RAG技术本身也在快速演进:微软开源的GraphRAG结合了知识图谱,多模态RAG可以处理图片和视频,Agentic RAG支持多轮迭代检索。技术越先进,技术栈也越复杂。
Karpathy的"反RAG"方案
但Karpathy的选择是:不用RAG,只用Markdown。
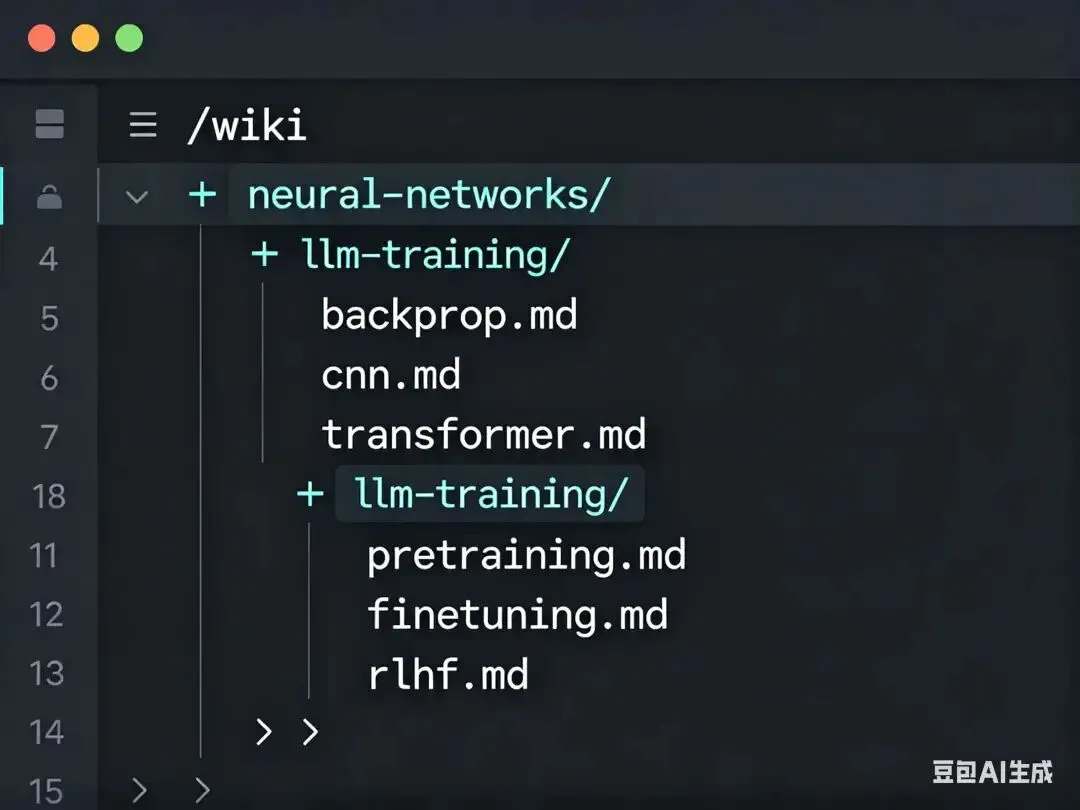
他的知识库结构非常简单:
/wiki ├── neural-networks/ │ ├── backprop.md │ ├── cnn.md │ └── transformer.md ├── llm-training/ │ ├── pretraining.md │ ├── finetuning.md │ └── rlhf.md └── README.md就是这么简单。纯文本文件,文件夹分类,Markdown格式。检索?靠文件名和全文搜索。版本控制?Git搞定。发布?GitHub Pages一键部署。
这种方案的优势显而易见:
零学习成本。 会写Markdown就能用,不需要学习任何新工具。
零维护成本。 没有数据库要管,没有服务要部署,没有向量要更新。
完全可控。 文件在自己手里,格式自己决定,不会受制于任何平台。
检索其实够用了。 对于个人知识库,几百篇笔记的规模,文本搜索+目录浏览已经足够高效。你不需要语义检索,因为你清楚自己要找什么;你不需要自动问答,因为你看了内容就能理解。
RAG的适用边界
那么,RAG到底适合什么场景?
大规模。 当知识库的规模达到几千、几万篇文档,人肉检索就不现实了。这时候,向量检索的语义匹配能力就派上用场了。
多人协作。 当知识库是团队共享的,不同的人有不同的表述习惯。RAG的语义理解能力可以跨越这些差异,找到相关内容。
自动化需求。 当你需要构建一个问答机器人,让非技术人员也能获取知识,RAG几乎是标配。
但对于个人知识管理,尤其是规模不大的情况,RAG往往是"过度工程"。你花了几天时间搭好Milvus、配置好Embedding模型、写好检索管道——结果发现,直接打开文件夹看可能更快。
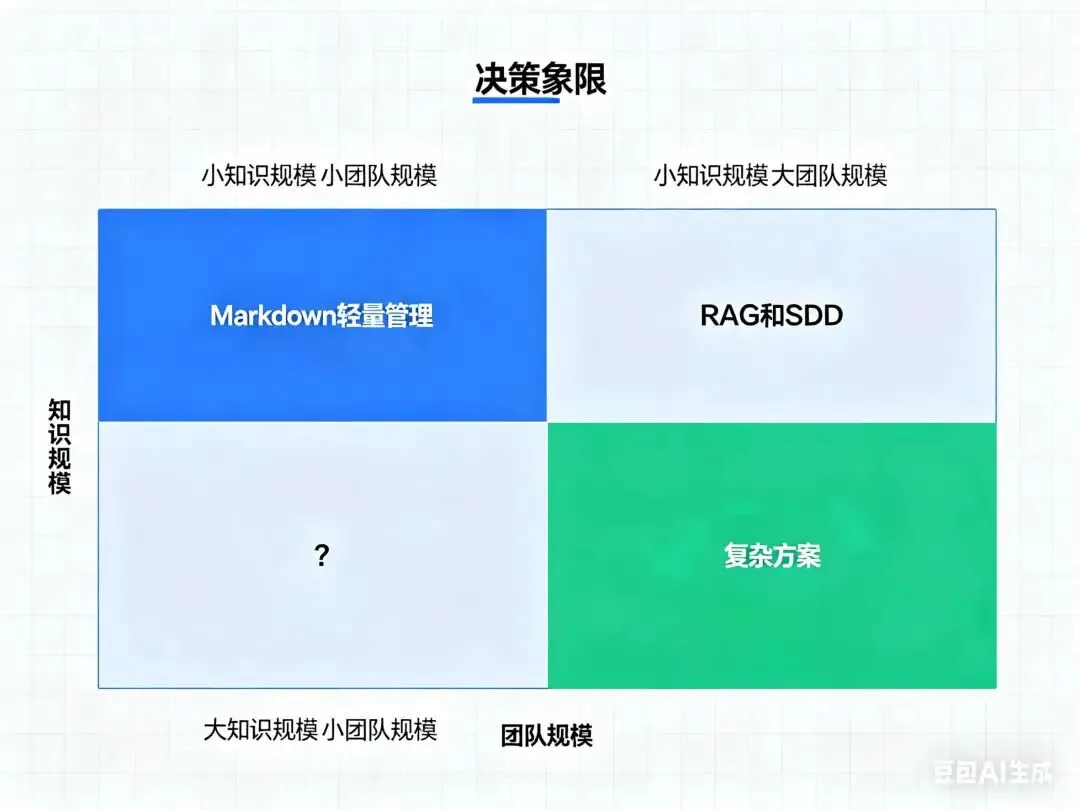
深入:极简与复杂的边界在哪里?
两组对比看完,我们似乎可以总结出一些规律。
两个案例的共同哲学
无论是Codex的去Spec化,还是Karpathy的Markdown知识库,它们背后都是同一种哲学:简单即有效。
这种哲学不是"偷懒",而是一种对"必要复杂度"的清醒认知。
每一个工具、每一个流程、每一个抽象层,都有它的成本。这个成本不只是搭建时的一次性投入,还包括长期的维护、团队成员的学习、故障时的排查。当这个成本超过了它带来的收益,这个工具就不值得引入。
复杂方案的隐性成本
技术圈有一种倾向:追求"先进"和"完整"。
一个典型的例子是知识管理。很多人搭建个人知识库时,会陷入这样的路径:
"先试试Notion吧... 不错,但数据库功能不够强,换Airtable... 等等,双向链接很重要,换Obsidian... 不过我想要云端同步,换Remotely Save... 对了,现在有AI了,得加上RAG..."
半年过去,知识库没积累多少,工具迁移了好几轮。
这就是复杂方案的隐性成本:它让你把精力花在了工具本身,而不是内容本身。
极简方案的局限
当然,极简也有它的边界。
团队规模扩大、知识库膨胀、合规要求变严格——在这些情况下,简单的方案可能就不够用了。
Codex的轻量管理在50-100人的团队也许可行,但在500人的团队呢?Karpathy的Markdown在几百篇笔记时很优雅,但在几万篇时呢?
关键在于:根据当前阶段选择工具,而不是为未来假想的需求过度设计。
说到底,我们使用技术,究竟是为了什么?
给开发者的三条建议
基于上面的讨论,这里有三个实践建议:
1. 从简单开始,只在必要时增加复杂度
不要一开始就追求"完美"的架构。从Markdown开始写笔记,从简单的代码结构开始开发项目。当现有方案真的成为瓶颈时,再考虑引入新工具。
记住:加东西容易,减东西难。
2. 让AI成为"规范"的一部分
与其写一份厚厚的PRD然后等着它过时,不如让规范"可执行"。
API的规范?用OpenAPI Schema定义,然后生成代码和文档。业务逻辑的规范?用Gherkin写可执行的用例。数据格式的规范?用JSON Schema约束。
在AI时代,自然语言和代码之间的鸿沟正在缩小。利用好这一点,可以让规范保持轻量且有效。
3. 警惕"技术过度"倾向
每当你想引入一个新工具、新框架、新流程时,先问自己三个问题:
我当前的问题,真的需要这么重的方案吗? 引入之后,维护成本是多少? 有没有更简单的方式达到80%的效果?
如果答不上来,或者答案不够有说服力,那就再等等。
结语
回到文章开头的那两则报道。
Codex团队用2名产品经理管理50-100人,Karpathy用Markdown文件管理知识库——它们之所以引起关注,或许是因为戳中了技术圈的一个集体焦虑:我们是不是把简单的事情搞得太复杂了?
AI能力越来越强,这个问题变得尤为迫切。当AI可以帮我们写代码、做检索、生成文档,我们终于可以——也理应——把更多精力放在真正重要的事情上:理解问题、设计架构、创造有价值的内容。
技术服务于人,而不是相反。最优雅的方案,往往也是最简单的那个。
希望这篇文章对你有所启发。毕竟,在这个技术飞速迭代的时代,保持简单,或许是最难也最值得练习的能力。

