 夜雨聆风
夜雨聆风但我不想花钱买各种 TTS/STT 接口,于是开始寻找完全本地、免费的方案。这篇文章是我在参考blog.yuanming.ai 之后的整个折腾过程的完整记录。
一、STT 语音识别:相对顺利
STT 部分没遇到太多麻烦。
我最终选择了 mlx-whisper(Apple 官方 MLX 框架实现的 Whisper),搭配 whisper-large-v3-turbo模型。在 M3 24GB 设备上运行非常流畅,中英混用识别效果也不错。
STT wrapper 脚本(mlx-whisper-transcribe.sh):
#!/bin/bashINPUT="$1"export PATH="/Users/zz/.local/bin:/opt/homebrew/bin:$PATH"mlx_whisper "$INPUT" \ --model mlx-community/whisper-large-v3-turbo \ -f txt \ --output-dir /tmp \ --output-name transcript_$$ 2>/dev/nullcat /tmp/transcript_$$.txt 2>/dev/null | sed 's/\[[0-9:. ]*--> [0-9:. ]*\] //g'rm -f /tmp/transcript_$$.txt 2>/dev/null || trueOpenClaw STT 配置:
openclaw config set tools.media.audio.models '[ { "type": "cli", "command": "bash", "args": [ "/Users/zz/.openclaw/scripts/mlx-whisper-transcribe.sh", "{{MediaPath}}" ], "timeoutSeconds": 90 }]'配置完成后,OpenClaw 很快就能自动转录 Telegram 语音消息了。
二、TTS 语音合成:真正的地狱
OpenClaw 的 STT 和 TTS 设计明显不对称:STT 支持通过 tools.media.audio走 CLI,而 TTS 必须走 messages.tts.provider,官方只支持 elevenlabs、microsoft、minimax、openai四种提供商。
核心矛盾在这里:免费的 Microsoft Edge-TTS 只能输出 MP3,而 Telegram 的圆形语音泡必须是 OGG/Opus 格式。两者天然不兼容。
三、最大的误判:我以为是 ffmpeg 的锅
这一步花了我将近一个星期,是整个过程中最难、最痛苦的部分。
我先搭了一个本地代理服务器:接收 OpenClaw 的请求 → 调用 Microsoft TTS 生成 MP3 → 用 ffmpeg 转成 OGG 返回。
但在测试时发现,用 afplay播放转码后的 OGG,永远只播前几个字就停。
我当时坚信是 ffmpeg 转码的问题,于是开始疯狂调试:各种 pad 参数、flush、ignore_err、sox 重写头信息、强制重编码……换了好几个本地 TTS 模型来对比。
结果无论怎么调,afplay播放的 OGG 依然截断。
直到有一次用 ffplay播放同一个文件,发现居然完整了。
那一刻才恍然大悟:问题根本不在 ffmpeg,而在 macOS 自带的 afplay 对 OGG/Opus 支持有 bug。它经常错误判断结束时间,导致"假截断"。
四、最终方案:OpenAI Provider + 本地代理
最终采用 OpenAI Provider + 本地代理的架构。
这个方案除了解决格式问题,还有一个被我低估的好处:代理层完全解耦了 OpenClaw 和底层 TTS 引擎。
只要代理实现了 OpenAI TTS 接口,后端可以挂任何东西——Kokoro、Piper、ChatTTS、CosyVoice……想换引擎只改代理,OpenClaw 侧的配置一行不动。
本地代理服务器(tts-server.py):
#!/usr/bin/env python3from flask import Flask, request, send_fileimport subprocess, tempfile, osapp = Flask(__name__)@app.route('/audio/speech', methods=['POST'])def tts(): data = request.json text = data.get('input', '') voice = data.get('voice', 'alloy') with tempfile.NamedTemporaryFile(suffix='.mp3', delete=False) as f: mp3_path = f.name with tempfile.NamedTemporaryFile(suffix='.ogg', delete=False) as f: ogg_path = f.name try: subprocess.run([ '/Users/zz/.local/bin/edge-tts', '--voice', 'zh-CN-XiaoxiaoNeural', '--text', text, '--write-media', mp3_path ], check=True, capture_output=True) subprocess.run([ 'ffmpeg', '-y', '-hide_banner', '-loglevel', 'error', '-i', mp3_path, '-c:a', 'libopus', '-b:a', '64k', '-vbr', 'on', '-application', 'voip', ogg_path ], check=True, capture_output=True) os.remove(mp3_path) return send_file(ogg_path, mimetype='audio/ogg') except Exception as e: for p in [mp3_path, ogg_path]: if os.path.exists(p): os.remove(p) return {'error': str(e)}, 500if __name__ == '__main__': app.run(host='127.0.0.1', port=4123, debug=True)OpenClaw TTS 配置:
"messages": { "tts": { "auto": "inbound", "provider": "openai", "providers": { "openai": { "apiKey": "dummy", "baseUrl": "http://127.0.0.1:4123", "model": "tts-1", "voice": "alloy" } }, "enabled": true }}五、最终效果与平台兼容性
本地龙虾现在终于既能听,也能说了:
用户发语音 → 自动转文字(mlx-whisper)
AI 处理后 → 自动回复语音消息(Edge-TTS + 本地代理转码)
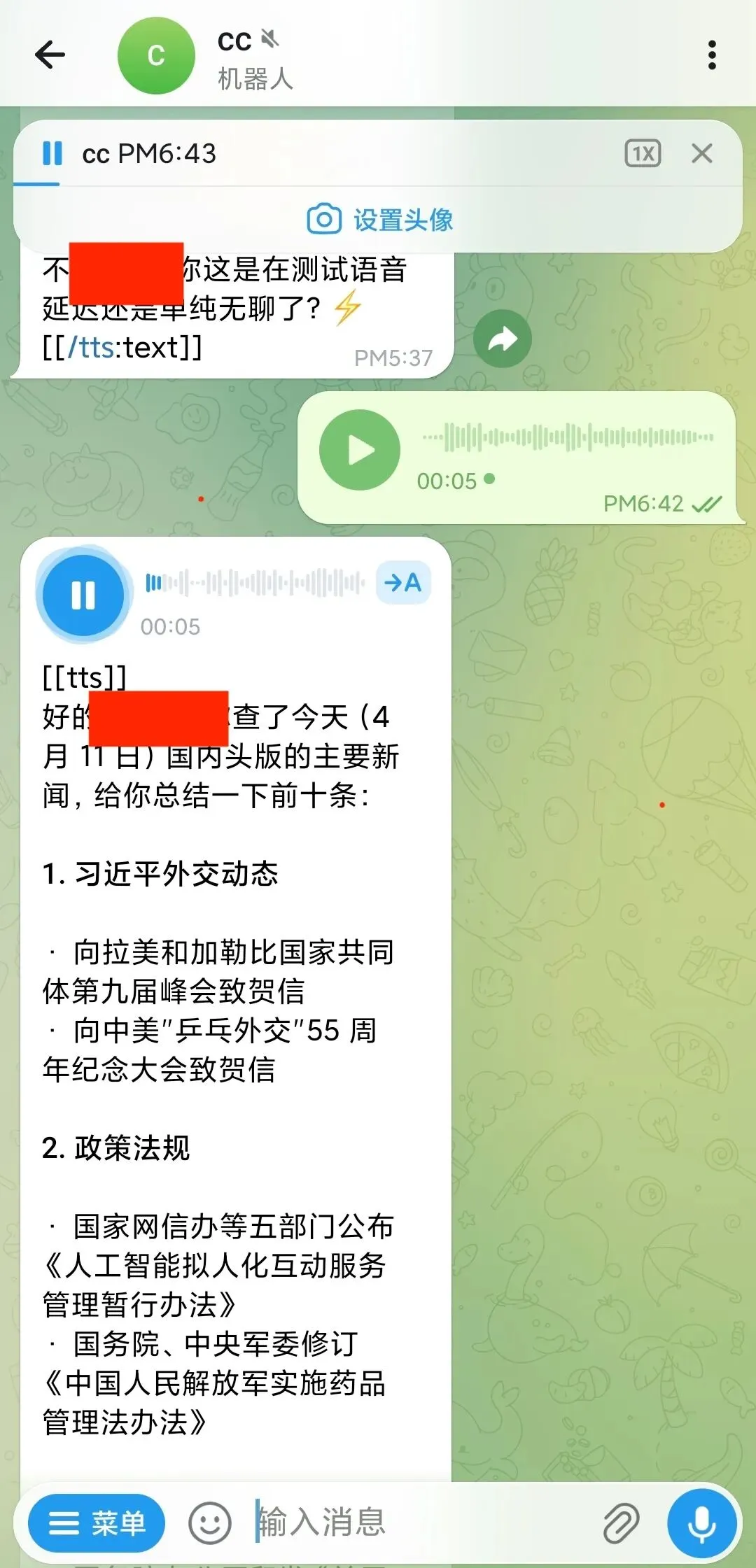
需要特别注意:这个方案目前只在 Android Telegram 客户端上表现完美,能正常显示为圆形语音泡。
在 iOS 和 Web 版客户端上,由于 OpenClaw 硬编码了扩展名 .mp3,语音可能显示为普通音频附件而非语音泡。相关问题正在 OpenClaw issue #21704 中讨论。
六、踩坑总结
OpenClaw 的 STT 和 TTS 设计不对称,TTS 更难玩,要有心理准备。
测试工具很重要:
afplay对 OGG 支持很差,差点让我怀疑人生整整一周。代理服务器是最灵活的方案,能彻底解耦格式问题和引擎选择。
免费方案成本低,但格式转换和兼容性问题需要自己搞定。
整个过程虽然踩了很多坑,但最终跑通的那一刻,还是很爽的。
参考
参考博客:blog.yuanming.ai
iOS/Web 客户端圆形语音泡兼容性问题:OpenClaw issue #21704
