 夜雨聆风
夜雨聆风文章简介:担心AI泄露隐私?每月token费用居高不下?本文教你用CanIRun.ai一键检测电脑配置能跑哪些开源模型,详解本地部署的数据安全优势与免Token费好处,揭秘小参数模型在文件检索、记忆整理、语音处理等场景的独特价值,并附Mac mini各型号专属模型推荐与部署方案,让你的电脑变身私人AI助手。
一、每次用AI都提心吊胆?本地部署才是终极解法
"这份合同能不能让AI帮我分析一下?"
"公司的财务数据丢给ChatGPT安全吗?"
"每个月几百块的API费用,用多了真心疼..."
如果你也有这些困扰,恭喜你,这篇文章就是为你准备的。
过去两年,大模型从实验室走向千家万户,但云端的便利背后,藏着三个无法回避的痛点:
🔒 数据隐私焦虑——敏感文件上传云端,等于把命脉交给别人
💰 Token费用累积——高频使用者每月几百上千,成本不可忽视\
🌐 网络依赖困境——没网的时候,AI瞬间变"人工智障"
本地部署开源大模型,正是破解这三大痛点的终极解法。
但问题来了:你的电脑,能跑得动吗?
别急,今天给大家介绍一个神器——CanIRun.ai,它能一键检测你的电脑配置,告诉你究竟能驾驭哪些AI模型。
二、CanIRun.ai:你的本地AI配置检测专家
这个网站能做什么?
CanIRun.ai 是一个专门检测本地AI模型兼容性的工具网站。它的核心功能简单粗暴:输入你的硬件配置,秒出结果。
支持的硬件范围极广:
• NVIDIA显卡:从GTX 1050到RTX 5090,全覆盖 • AMD显卡:RX 5000/6000/7000/9000系列 • Apple Silicon:M1/M2/M3/M4全系列,包括Pro/Max/Ultra • Intel显卡:Arc A系列 • 甚至树莓派:Raspberry Pi 4/5都能测
检测维度很专业:
• GPU型号与显存容量 • 内存带宽(Bandwidth) • 系统内存(RAM) • GPU核心数
输出结果一目了然:
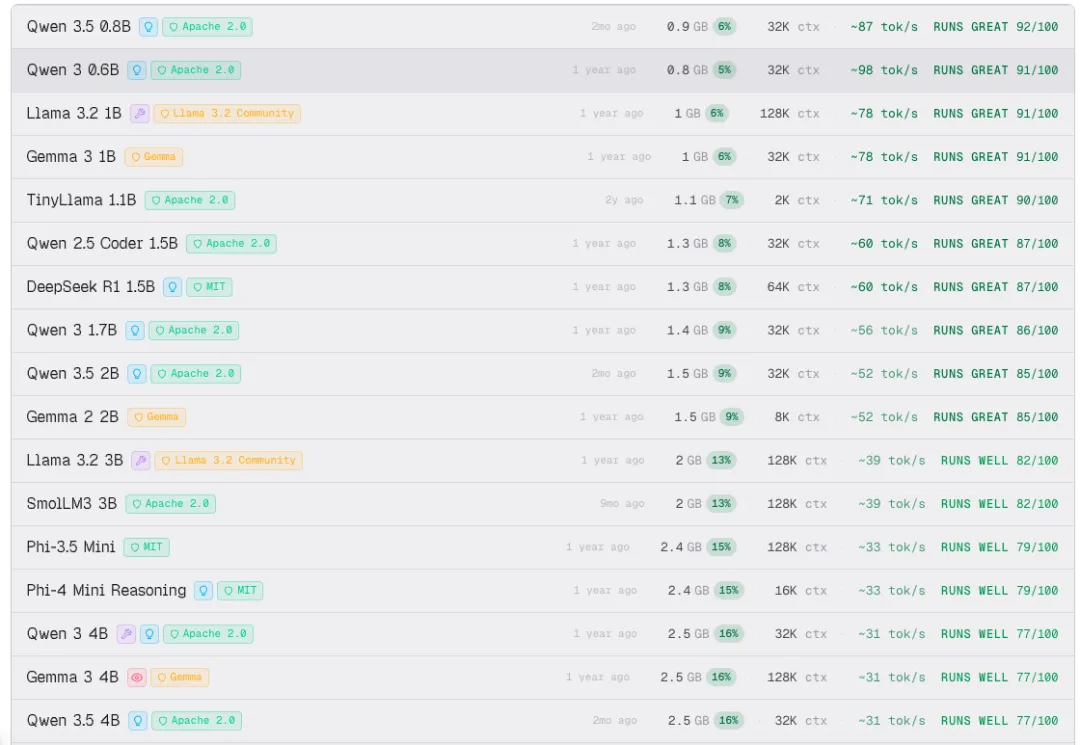
网站会给出一个六级评分体系,并与实际推理速度(tokens/秒)关联,让你直观了解模型运行表现:
💡 速度参考:40 tokens/s 约等于每秒输出20-30个汉字,接近人类阅读速度;20 tokens/s 约每秒10-15字,略有等待感;10 tokens/s 以下则明显卡顿。
每个模型卡片还会显示显存占用、上下文长度、量化版本等关键指标。点击任意模型,可查看详细的配置要求、推荐运行参数、以及同系列其他版本的对比信息,帮你做出最优选择。
三、本地大模型的「真香」现场:三大核心优势
✅ 优势一:数据绝对安全,隐私零泄露
这是最核心的卖点。
当你把敏感文件上传到云端大模型时,数据要经过以下环节:你的电脑 → 网络传输 → 云服务商服务器 → 模型处理 → 结果返回
每一个环节,都是潜在的风险点。
而本地部署意味着:你的电脑 → 本地模型处理 → 结果输出
数据不出本机,物理隔离,绝对安全。
适合场景举例:
• 💼 律师行业:合同分析、案例检索、文书起草 • 🏥 医疗领域:病历整理、医学文献分析、诊断辅助 • 🏦 金融机构:财报解读、风险评估、合规审查 • 🔬 科研机构:实验数据、研究成果、未发表论文 • 👤 个人用户:日记、照片、私人文档的智能整理
✅ 优势二:永久免Token费,越用越省
来算笔账:
| 本地部署 | 一次性硬件投入 | $0后续费用 |
如果你已经有了一台性能尚可的电脑,本地部署的边际成本几乎为零。
对于高频使用者——程序员、内容创作者、研究人员、数据分析师——这笔账算下来,本地部署的优势非常明显。
✅ 优势三:离线可用,随时随地AI在线
• ✈️ 飞机上:没有网络?照样可以本地AI辅助写作 • 🚄 高铁上:信号不稳定?本地模型不受影响 • 🏕️ 偏远地区:网络覆盖差?AI能力不打折 • 🌙 深夜加班:不用担心API限流或服务器繁忙
本地AI,真正做到了"我的模型我做主"。
四、破除误区:参数小=不智能?大错特错!
很多人一听到"本地模型",第一反应是:"参数那么小,能有什么用?"
这是典型的认知误区。
确实,本地能跑的模型(通常1B-14B参数)在通用能力上无法与GPT-4、Claude 3.5 Sonnet这类云端大模型相比。但世界上没有无用的东西,只有用错地方的资源。
小参数模型,在特定场景下有着无可替代的优势:
🎯 场景一:本地文件检索(RAG应用)
原理:小模型负责理解查询意图 + 向量数据库存储文档Embedding
实际效果:
• 在成千上万份本地文档中,秒级定位相关内容 • 支持自然语言提问:"找出去年所有关于预算超支的邮件" • 完全本地运行,敏感文件零上传
推荐模型:Qwen 2.5 7B、Mistral 7B、Llama 3.1 8B
🎯 场景二:记忆整理与知识管理
以OpenClaw的记忆系统为例:
• 自动归类每日笔记 • 提取关键决策和待办事项 • 跨时间线的知识关联
小模型完全可以胜任这类结构化任务,而且响应速度极快。
推荐模型:Qwen 3 4B、Gemma 3 4B、Llama 3.2 3B
🎯 场景三:代码辅助与开发效率
7B级别的代码专用模型,在以下场景表现优异:
• 代码补全(比云端模型响应更快) • 函数注释生成 • 简单Bug修复建议 • 代码风格检查
推荐模型:Qwen 2.5 Coder 7B、DeepSeek Coder 7B
🎯 场景四:文本分类与摘要
• 📧 邮件自动分类(工作/个人/推广) • 📄 长文档自动摘要 • 🏷️ 智能标签生成 • 📊 会议纪要结构化整理
这类任务不需要"世界知识",只需要模式识别和结构化能力,小模型完全够用。
核心观点:
不是模型不够大,是你没用对地方。
云端大模型是"通才",本地小模型是"专才"。各司其职,才是AI时代的正确打开方式。
五、语音大模型:本地运行的隐藏宝藏
如果说文本模型还有云端替代方案,语音模型则几乎是本地部署的"刚需"。
为什么语音模型特别适合本地?
1. 体积小巧,本地无压力
• 主流语音模型通常只有1B-3B参数 • 显存占用低(2-4GB即可运行) • 普通消费级显卡甚至集成显卡都能跑
2. 实时性要求高,云端延迟伤不起
• 语音识别需要毫秒级响应 • 云端传输的几十毫秒延迟,用户体验大打折扣 • 本地运行,真正做到"边说边出字"
3. 语音数据更私密
• 你的声音、说话内容、口音特征——都是敏感信息 • 本地处理,彻底杜绝隐私泄露风险
本地语音模型的黄金场景
🎙️ 会议实时转录
• 本地录音 + 本地转写,敏感会议内容零上传 • 支持说话人分离、时间戳标记
📱 离线语音助手
• 智能家居控制("打开客厅灯光") • 本地指令执行("整理今天的下载文件") • 完全离线,响应零延迟
🌍 多语言实时翻译
• 出国旅行时的离线翻译助手 • 商务洽谈中的实时转译 • 无需网络,随时随地可用
📝 口述内容创作
• 作家、记者的口述写作 • 医生、律师的口述病历/案例记录 • 解放双手,提升效率
推荐模型:
• Whisper系列(OpenAI开源,多语言支持好) • Faster-Whisper(优化版本,速度更快) • 国产替代:Paraformer、SenseVoice
六、Mac mini 专属配置指南:各型号模型推荐
Mac mini 可能是本地AI性价比最高的入门设备。
Apple Silicon的统一内存架构(Unified Memory)让CPU和GPU共享内存,这意味着:内存就是显存。
下面按配置分级,给出具体的模型推荐:
💻 M1/M2 Mac mini(8GB/16GB内存)
硬件特点:
• 内存带宽约68GB/s • GPU核心数8-10核 • 适合轻量级AI任务
推荐模型:
使用建议:
• 8GB内存:建议同时只运行1个模型,留足系统内存 • 16GB内存:可同时运行对话模型+语音模型
💻 M2 Pro/M4 Mac mini(24GB+内存)
硬件特点:
• 内存带宽100-120GB/s • GPU核心数16-20核 • 可驾驭中等规模模型
推荐模型:
进阶玩法(24GB内存):
• 可尝试14B级别模型(Qwen 2.5 14B、DeepSeek R1 14B) • 速度会慢一些,但可用 • 适合对质量要求高、对速度要求低的场景
🚀 M4 Pro/Max(36GB+内存)
硬件特点:
• 内存带宽273GB/s+ • GPU核心数20核+ • 本地AI的旗舰配置
推荐模型:
• 所有24GB及以下模型完美运行 • 可尝试32B级别模型(速度较慢但可用) • 多模型并行:同时运行对话+代码+语音模型
Mac mini 部署工具推荐
🥇 Ollama(最简单)
# 安装brew install ollama# 运行模型ollama run llama3.1:8b• 一键安装,开箱即用 • 模型库丰富,下载方便 • 支持自定义Modelfile
🥈 LM Studio(可视化)
• 图形界面,操作直观 • 内置模型搜索和下载 • 支持多模型同时加载
🥉 llama.cpp(性能最优)
• 命令行工具,性能最强 • 支持Metal加速(Apple Silicon专属优化) • 适合高级用户和性能调优
内存优化技巧
1. - 使用量化模型
• Q4量化:体积减少75%,质量损失可控 • Q5量化:体积减少60%,质量接近原版 2. - 调整上下文长度
• 默认128K上下文很吃内存 • 日常对话4K-8K足够 • 在配置文件中修改 num_ctx参数3. - 关闭不必要的后台应用
• 为AI模型留出更多内存空间 • Activity Monitor监控内存使用
七、实测演示:三类典型配置能跑什么?
为了让大家更直观地理解,我选取了三个典型配置进行实测:
配置一:老笔记本(GTX 1060 6GB)
检测结果:
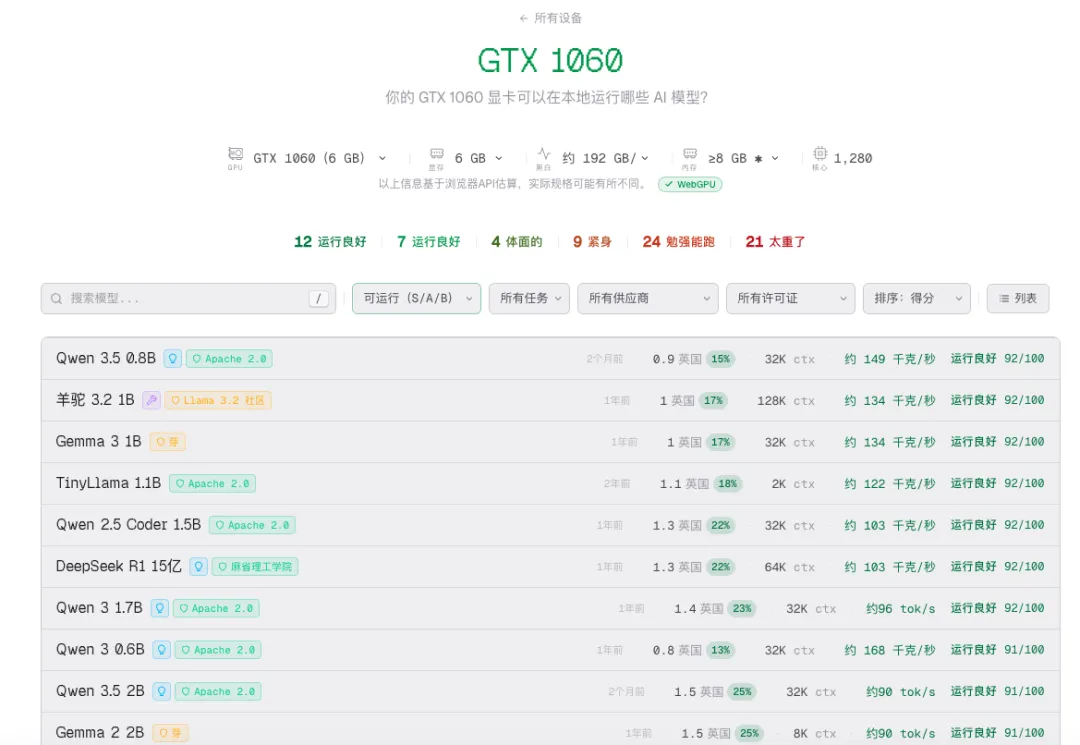
• ✅ 可流畅运行:1-3B级别模型 • ⚠️ 勉强运行:7B级别模型(速度较慢) • ❌ 无法运行:14B及以上
推荐方案:
• 日常对话:Llama 3.2 3B、Qwen 3 4B • 代码辅助:Qwen 2.5 Coder 1.5B • 语音转写:Whisper Small/Base
结论:老设备也能玩AI,轻量任务完全够用。
配置二:中端台式(RTX 3060 12GB)
检测结果:
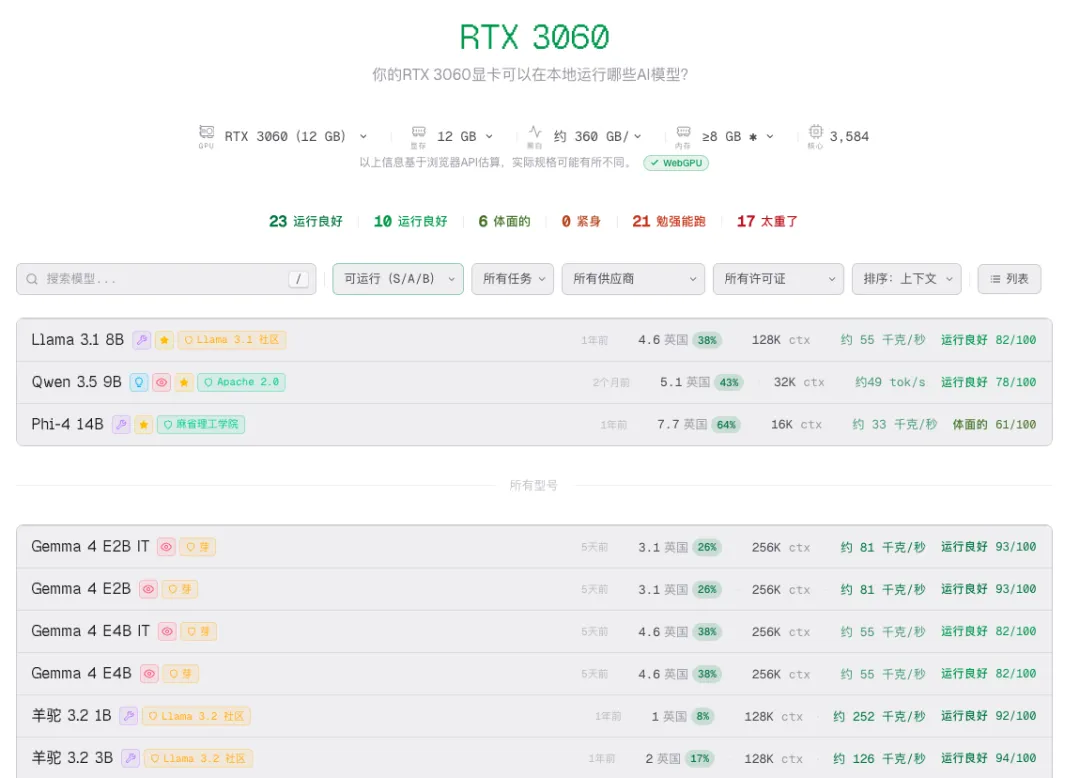
• ✅ 完美运行:7-9B级别模型 • ⚠️ 勉强运行:14B级别模型 • ❌ 无法运行:32B及以上
推荐方案:
• 主力对话:Llama 3.1 8B、Qwen 2.5 7B • 代码开发:Qwen 2.5 Coder 7B、DeepSeek Coder 7B • 语音处理:Whisper Medium + 实时转录 • RAG应用:7B模型 + 向量数据库
结论:性价比最高的配置,日常生产力完全满足。
配置三:Mac mini M4(16GB内存)
检测结果:
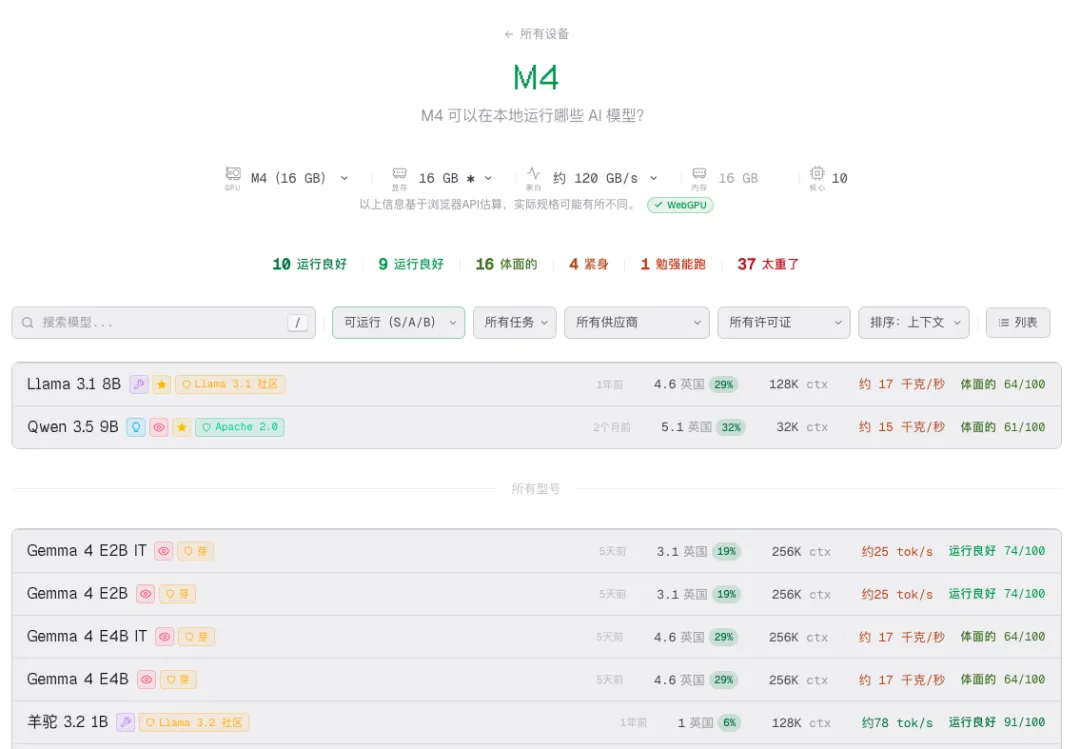
• ✅ 完美运行:8B及以下模型 • ⚠️ 勉强运行:14B级别模型 • ❌ 无法运行:32B及以上
推荐方案:
• 主力对话:Llama 3.1 8B、Mistral 7B • 轻量任务:Gemma 3 4B(速度快) • 语音助手:Whisper + 本地语音指令 • 文件检索:7B模型 + LlamaIndex
结论:Mac用户本地AI的最佳入门选择。
八、🔥 最新热门模型部署指南(2025年4月更新)
AI开源社区最近又有大动作!以下两个模型值得重点关注:
🆕 Google Gemma 4:轻量级多模态新星
Google于2025年3月发布的Gemma 4系列,延续了Gemma系列轻量高效的特点,同时在多模态能力上大幅提升。
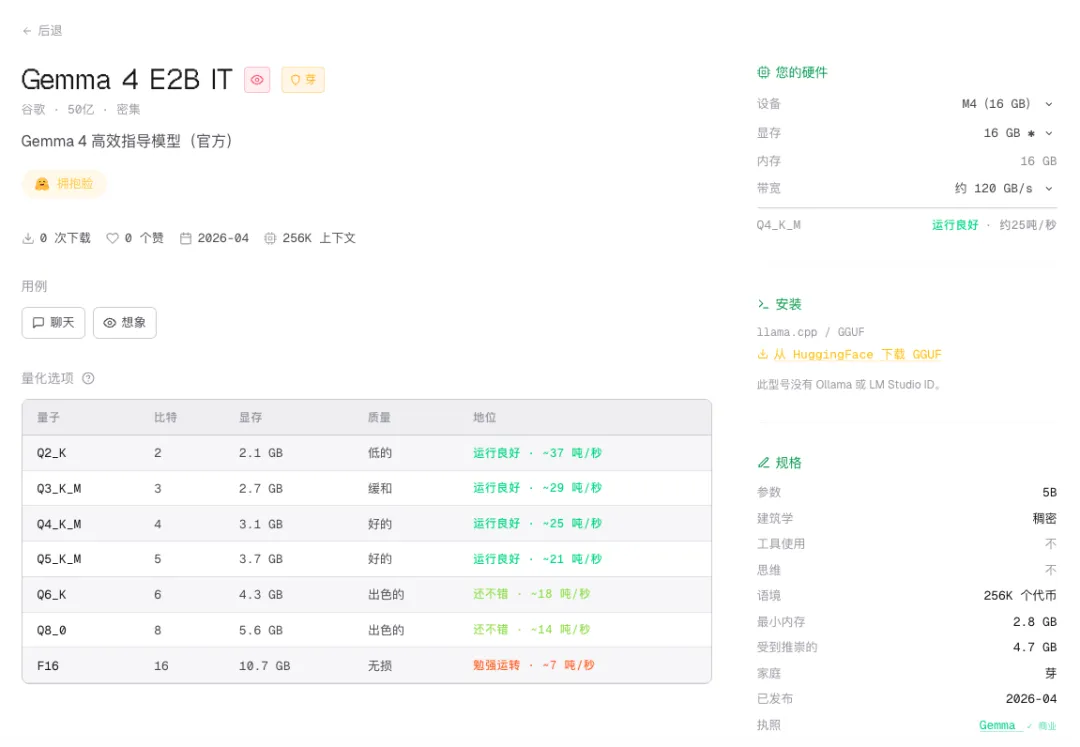
模型规格与部署条件:
核心亮点:
• ✅ 原生多模态:支持图文理解,可分析本地图片 • ✅ 超长上下文:最高支持128K上下文(需足够显存) • ✅ 指令跟随强:适合构建本地AI助手 • ✅ Apache 2.0开源:可商用,无限制
部署命令:
# 通过Ollama快速部署ollama run gemma4:4b# 或指定量化版本节省显存ollama run gemma4:8b-q4_K_M适合场景:本地图文问答、文档分析、轻量级多模态应用
🚀 MiniMax-Text-04:国产大模型新标杆
MiniMax于2025年4月宣布即将开源的MiniMax-Text-04(内部代号M2.7),是国内首个对标GPT-4级别的开源模型,引发社区极大关注。
预期部署条件(基于官方技术报告推算):
技术亮点预告:
• 🔥 MoE架构:采用混合专家架构,推理效率大幅提升 • 🔥 超长上下文:支持200K+上下文,长文档处理利器 • 🔥 中文优化:针对中文场景深度优化,本土体验更佳 • 🔥 工具调用:原生支持Function Calling,易于构建Agent
⚠️ 重要提示:
• 目前MiniMax-Text-04尚未正式发布,预计2025年Q2开源 • 上述配置为基于技术报告的预估,实际部署条件以官方发布为准 • 建议关注MiniMax官方GitHub仓库获取最新动态
预期部署方式:
# 预计Ollama将在发布后支持ollama run minimax-text-04:14b# 或通过HuggingFace Transformerspip install transformers# 加载模型代码(待发布)适合场景:中文长文档处理、本地知识库问答、企业级AI应用
💡 如何选择?Gemma 4 vs MiniMax-Text-04
| 当前状态 | ||
| 硬件门槛 | ||
| 中文能力 | ||
| 多模态 | ||
| 上下文长度 | ||
| 开源协议 |
建议:
• 现在就想玩:选择Gemma 4,轻量高效,多模态能力强 • 愿意等待:MiniMax-Text-04的中文能力和长上下文值得期待 • 两者都要:Gemma 4 4B负责图文任务,MiniMax-Text-04 14B负责长文档处理
九、行动指南:三步开启你的本地AI之旅
看到这里,相信你已经跃跃欲试了。下面是具体的上手步骤:
第一步:检测你的配置
1. 访问 CanIRun.ai 2. 选择你的GPU型号(或Mac型号) 3. 查看系统推荐的可用模型列表 4. 重点关注S级和A级评分的模型
第二步:安装部署工具
Mac用户:
brew install ollamaWindows/Linux用户:
• 访问 ollama.com[1] 下载安装包 • 或使用Docker部署
第三步:下载并运行模型
# 查看可用模型列表ollama list# 下载并运行模型(以Llama 3.1 8B为例)ollama run llama3.1:8b# 下载量化版本(节省显存)ollama run llama3.1:8b-q4_K_M进阶玩法:
• 配置WebUI(Open WebUI、ChatGPT-Next-Web) • 搭建RAG系统(AnythingLLM、Dify) • 接入语音输入(Whisper + Ollama组合)
九、写在最后:本地AI的正确心态
本地部署大模型,不是要和云端大模型"一决高下",而是找到各自的生态位。
云端大模型:
• 通用知识问答 • 复杂推理任务 • 创意内容生成 • 需要最新信息的场景
本地小模型:
• 敏感数据处理 • 高频重复任务 • 离线场景需求 • 成本敏感场景
两者结合,才是AI时代的最优解。
就像文章开头说的:
本地AI就像家里的保险箱,云端AI像银行的保险柜——各有各的用。
你的电脑能跑什么级别的模型?去CanIRun.ai测测看,回来告诉我!
OpenClaw进阶版skill!免费banana免API,P图+图生图+引导式生图,0成本也能接单变现
💬 评论区互动话题:
1. 你的电脑配置是什么?测出来能跑哪些模型? 2. 你最想用本地AI解决什么问题? 3. Mac mini用户来报到!你的内存配置和模型选择是什么?
本文部分技术参数参考自CanIRun.ai,实测数据基于公开信息整理。模型推荐会随版本更新而变化,请以实际测试结果为准。
引用链接
[1] ollama.com: https://ollama.com
