 夜雨聆风
夜雨聆风
说起来,前段时间参加一个AI项目的复盘会,项目负责人说了句话让我印象特别深。
他说:"我们花了大半年时间训练模型,准确率死活上不去。最后排查一圈才发现,训练数据里有30%是重复的,还有15%的标注是错的。"
说完这句话,他叹了口气。那种感觉我太懂了——明明算法没问题、算力也管够,但模型就是跑不出预期效果。一查原因,数据一塌糊涂。
这种感觉,就像是你花重金买了顶级厨具,结果发现食材是馊的。你说气不气人?
今天想认真聊聊这个话题:数据质量到底怎么就成了AI落地最大的坑?以及,2026年了,我们该怎么用AI来治理数据质量。
先说个让我挺意外的数据
MIT去年发布了一份报告,调研了全球500多家企业的AI项目。
结果发现一个让我挺意外的数字:93%的AI项目失败,而其中绝大部分失败的原因,不是算法不够好,不是算力不够强,而是数据质量不行。
93%啊。
说实话,第一次看到这个数字我是不太信的。我以为是哪个自媒体瞎编的。但后来我去查了原始报告,又跟好几个做AI项目的朋友聊了聊,发现这个数字还真不是夸张。
有个朋友在某电商公司做推荐算法,他说他们团队60%的时间都花在数据清洗和治理上。每个数据工程师每天平均要处理8.3次"这个数据对不上"的紧急排查。
8.3次。
你算算,一天工作8小时,光排查数据问题就要花掉多少时间?剩下的时间才轮得到真正有价值的模型优化工作。
为什么数据质量问题这么普遍?
我在复盘会上观察到一个现象:大家在讨论项目进度的时候,算法工程师们都很兴奋——模型结构、loss函数、训练策略,各种优化方案层出不穷。但一提到数据,大家就沉默了。
不是不想聊,是真的太脏了。
日志格式不统一、上下游数据不一致、历史数据迁移时的各种缺失……这些问题你说大不大,说小不小,但堆在一起就是能把你磨得没脾气。
传统的数据治理方式,为什么越来越玩不转了
我之前带过一个项目,用的是最传统的数据质量治理方案。
什么方案呢?就是写规则、做校验。
比如写个SQL检查订单金额是不是负数,检查用户ID是不是为空,检查创建时间是不是在今天之后。逻辑很简单,就是"如果字段X违反规则Y,那就报错"。
这套方法在五年前、十年前是管用的。那时候数据规模小、结构稳定,几十条规则就能cover住大部分问题。
但现在不行了。
第一个问题:规则太多了,根本维护不过来。
我们之前维护过一套数据质量规则,最高峰的时候有将近2000条。你没看错,2000条。
每来一个数据源,就要写几十条规则。上游系统改个字段,我们要跟着改规则。业务逻辑变了,规则也要跟着变。维护成本高得吓人,而且很容易漏。
有次就是因为一条规则漏了更新,导致一批脏数据流进了模型训练集。那次之后我就在想,这条路是不是走错了。
第二个问题:规则只能发现已知问题,未知的一概不知。
什么意思呢?
你写规则的时候,必须先知道"什么是错的"。但现实情况是,很多数据问题是你根本预想不到的。
比如,你可能知道金额不能是负数,但你可能不知道"已取消"的订单里出现了正数金额——这是个业务逻辑矛盾,但规则不会告诉你,除非你专门写一条去检查。
第三个问题:规则只看单个字段,看不懂上下文。
举个真实的例子。
我们有个订单表,里面有个status字段表示订单状态。status=4代表"已取消"。还有个字段叫payment_amount表示支付金额。
按照正常业务逻辑,已取消的订单要么没付款,要么付款已退回,总之payment_amount应该是0。
但有一天我们发现,数据库里有几千条记录,status=4但payment_amount>0。
这种情况,单独看status字段,没问题;单独看payment_amount字段,也没问题。只有把两个字段放在一起看,才能发现这是个业务逻辑矛盾。
传统规则做不到这种事。
你必须先想到"这两个字段之间可能存在约束",然后专门写一条规则去检查。但你怎么可能想到所有可能的字段组合?
三个被忽视但很致命的数据质量维度
说到这儿,我想提三个Gartner早就提过,但很多团队还是没重视的数据质量维度。
第一个:语义一致性。
就是刚才说的那个例子——订单状态和支付金额之间的业务逻辑关系。
这类问题有个特点:单看任何一条数据都没问题,但数据之间存在矛盾。只有理解了数据的"语义",才能发现。
第二个:时序一致性。
用户行为是有先后顺序的。"登录成功"必须在"点击按钮"之前,"下单"必须在"支付"之前。
但实际数据里,经常出现时序错乱的问题。原因可能是日志打点的时间戳不准确,可能是数据传输过程中的乱序,也可能是系统bug。
如果时序乱了,你拿这些数据去做用户行为分析,得出的结论会完全失真。
第三个:跨表关联一致性。
比如A表的订单金额合计,应该等于B表的交易流水合计。
这种一致性检查,单表规则是cover不住的。你必须跨表做聚合比对。
之前我们就吃过这个亏。订单表和支付表分开看都没问题,但两边一比对,发现差了0.3%。0.3%听起来不多,但乘以每天几百万的订单量,就是一个不小的数字。
说个真实的成本案例
有家金融科技公司,风控模型团队每个月要处理约50TB的交易数据。
他们发现一个问题:数据问题导致的模型返工,每年大约3到4次,每次耗时2到3周。
也就是说,每年光返工就要花掉2到3个月的时间。
更坑的是,这70%的问题都是在模型上线之后,由业务部门投诉触发的。什么意思?就是你以为模型已经跑稳了,结果业务那边突然发现数据不对,然后你再回头去查。
按一个工程师年薪50万来算,光这一项每年损失就超过100万。
这还没算模型效果不达预期带来的业务损失。
所以你说数据质量重不重要?
AI是怎么改变这件事的
好,说了这么多问题,该说解决方案了。
2026年了,AI技术成熟了,我们终于有了更好的工具来处理数据质量问题。
我观察下来,AI驱动数据质量治理的核心,是三个能力的提升:
第一个能力:从规则匹配到统计推断。
传统方案是"如果X违反Y,则报错"。AI方案是"基于历史数据建立期望分布,然后识别偏离正常模式的数据点"。
这两者的区别是什么?
规则匹配只能发现你"事先知道"的问题。统计推断可以发现你"事先不知道"的问题。
比如,你不知道金额字段可能出现什么异常,但AI可以通过分析这个字段的历史分布,发现"这个月的金额分布和历史相比有明显偏移"。至于是偏移了多少算异常,AI会根据统计模型自动判断。
第二个能力:从字段级校验到上下文感知。
AI可以理解数据之间的关系,而不仅仅是单个字段的值。
比如刚才说的订单状态和支付金额的矛盾,AI可以从历史数据中学习到"status=4时payment_amount应该为0"这个模式,然后自动检测违反这个模式的数据。
第三个能力:从被动发现到主动预警。
传统方案是"数据进来,校验一下,有问题再告警"。AI方案是"持续监控数据分布,发现异常趋势提前预警"。
比如,AI可以发现"这个星期日的订单量比历史平均水平低了15%",然后提前告警,而不是等到业务部门发现数据不对再来查。
我最近在研究的一个技术方向
最近我在看一个叫"数据画像"的技术,觉得还挺有意思的。
数据画像(Data Profiling)是什么?简单来说,就是通过统计分析建立数据的"全貌认知"。
打个比方,你想了解一个人,不会只看他的身份证号。你会看他的工作、性格、爱好、人际关系……这些"画像"让你对这个人有全面的了解。
数据画像也是这个道理。对于一个数据表,你不仅要知道它有多少行、多少列,还要知道每个字段的分布特征、缺失率、异常值模式、与其他字段的关联关系……
这些东西,传统方案要么靠人工探索,要么干脆不管。但AI可以自动化完成这个过程。
比如,对于一个数值型字段,AI会自动计算均值、标准差、偏度、峰度分布,还会检测是否存在双峰分布、是否存在长尾……这些特征往往能反映出数据质量问题。
对于一个文本型字段,AI会自动识别数据类型(是邮箱?手机号?地址?),识别常见的pattern,检测异常pattern。
这个过程就像给数据做了一次全面体检。
另一个有意思的能力:时序异常检测
刚才提到,数据的时间维度很重要。很多数据问题会反映在时间序列的变化上。
比如:
某天的数据量突然比前一天多了50%,但没有业务解释 某个指标的趋势突然发生了逆转,但没有任何公告 某个字段的缺失率突然上升了
这些问题,靠规则很难检测,但用时序分析+异常检测算法可以很好地识别。
我了解的一个方案是,用Isolation Forest这样的无监督学习算法,对时序分解后的残差进行异常点检测。
原理大概是:先把时间序列分解成趋势+周期+残差,然后对残差部分进行异常检测。如果某个时间点的残差特别大,说明这个点的行为和历史模式不一致,可能存在数据问题。
这个方法的好处是,不需要事先定义"什么是异常",算法会自动从历史数据中学习"正常"是什么样子。
LLM带来的突破:终于能理解数据语义了
说到这儿,我想特别提一下LLM在这件事上的作用。
2026年最大的一个突破,就是LLM让机器终于能够"理解"数据的语义了。
以前,你要告诉系统"订单状态和支付金额之间存在约束关系",需要你手动写规则。
现在,你可以直接问LLM:"根据这个表的字段描述,它可能存在哪些业务逻辑一致性检查?"
LLM会基于它的领域知识,自动推断出可能的约束关系。
比如,它可能会说:"orders表的status字段和payment_amount字段之间可能存在一致性约束,因为status=4(已取消)通常意味着payment_amount=0。"
然后你可以让LLM进一步生成检测SQL,自己再根据业务实际情况调整。
这大大降低了"发现业务逻辑约束"的门槛。以前只有非常熟悉业务的老员工才能做到的事,现在新员工借助LLM也能做到。
一个完整的实战案例
好了,说了这么多理论,来讲个真实的案例。
这是去年我参与的一个项目,帮某头部电商平台做数据质量治理。
这家公司的情况是这样的:
日处理订单量约500万条,历史累计超过50亿条记录。核心问题有三个:
多系统数据孤岛,订单状态不一致率约3% 数据质量问题依赖业务投诉,被动响应 数据清洗依赖人工规则,维护成本高
整体的技术架构大概是这样的: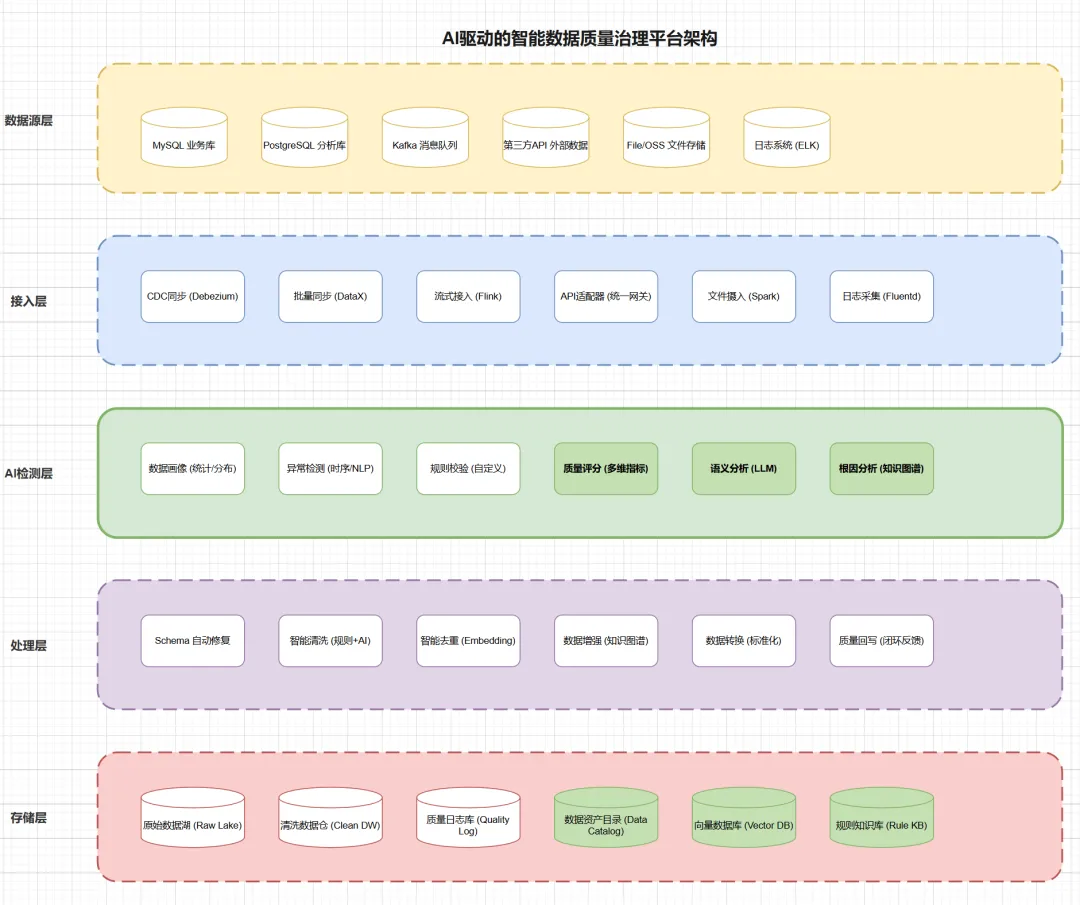
五层架构:最底层是数据源层,包括MySQL、Kafka、第三方API这些;第二层是接入层,负责CDC同步、批量同步、流式接入;第三层是AI检测层,包括数据画像、异常检测、规则校验、质量评分、语义分析和根因分析;第四层是处理层,做Schema修复、智能清洗、智能去重、数据增强;最顶层是存储层,分原始数据湖、清洗数据仓、质量日志库等。
为什么我要花这么大篇幅讲架构?因为架构选对了,后面的事情就顺了。
第一阶段,我们花了2周做问题诊断。
通过数据画像+时序分析+跨表关联检测,我们发现了四类主要问题:
45%是状态机逻辑矛盾——比如"已发货"但没有物流信息。
30%是金额计算不一致——商品原价不等于单价乘以数量。
15%是时间戳异常——下单时间晚于发货时间。
10%是关联表数据不一致——订单表和支付表的金额对不上。
第二阶段,花了6周搭建系统。
技术选型上,流式处理用Flink CDC,批处理用Spark,质量检测叠加LLM语义分析,质量存储用ClickHouse。
核心流程是这样的:
数据先经过Schema检测,验证字段类型和格式;然后进入数据画像模块,建立统计特征基线;接着是规则校验,检查预设的规则是否被违反;再然后是异常检测,用时序分析和无监督算法识别偏离正常模式的数据;最后是语义分析,用LLM检查业务逻辑一致性。
每个环节的结果都会汇总到一个质量评分引擎,计算综合的质量分数。如果分数低于阈值,就触发告警。
第三阶段是持续运营。
上线半年后,效果还是很明显的:
问题发现时机从"业务投诉后"提前到"发生前1小时"。数据质量评分从72分提升到96分。数据问题修复时长从4小时缩短到30分钟。数据工程师花在排查问题上的时间,从60%降到20%。
最后这个数字我觉得最有意义:工程师的时间终于可以花在真正有价值的事情上了,而不是天天当"数据消防员"。
几个我觉得比较关键的经验
回看这个项目,有几点经验我觉得值得分享:
第一,质量检测要前置,不要事后检查。
我们一开始把质量检测放在数据入湖之后,结果发现很多问题已经晚了。后来改成在数据入湖之前就做检测,有问题的数据直接拦截。效果好了很多。
第二,先建立基线,再做异常检测。
AI异常检测的前提是,你得先知道"正常是什么样"。没有基线,异常检测就是空中楼阁。所以第一优先级应该是把数据画像做好,建立统计特征的基线。
第三,告警要分级,避免告警疲劳。
critical级别的问题立即告警,medium级别的问题批量汇总。如果你每天收到几百条告警,那跟没有告警是一样的——没人会看的。
第四,质量规则不是一次性配置,是持续迭代的。
业务在变,数据在变,质量规则也要跟着变。建议每个季度做一次规则评审,看看哪些规则已经过时了,哪些新的约束条件需要加进来。
关于技术选型的一点看法
有朋友问我,现在市面上有哪些现成的工具可以用?
我的看法是这样的:
如果你是小团队,想快速验证,Great Expectations是个好选择,Python原生,上手快。
如果你们已经深度使用Google云,Dataplex可以考虑,跟Google生态集成得比较好。
如果你们是大企业,业务复杂,数据量大,建议还是自建平台。虽然前期投入大,但长期来看可控性和灵活性都更好。
当然,你也可以采用混合策略——用开源工具做基础的规则校验,自己再叠加一层AI增强能力。这样既能快速起步,又能保持差异化竞争力。
最后说几句
数据质量这件事,我最大的感受是:它不是技术问题,是组织问题。
技术方案再好,如果没有配套的流程和机制,也很难落地。
比如,谁对数据质量负责?发现问题谁来修复?修复的SLA是什么?这些问题不回答清楚,再好的工具也是白搭。
所以我的建议是,技术方案和治理机制要一起推进。光有工具不行,还得有人、有流程、有考核。
另一个感受是,数据质量不是一次性项目,是持续运营的系统工程。
不要想着一步到位,先从核心业务表开始,建立基线,配置基础规则,跑通告警流程。在这个基础上,再逐步引入AI增强能力。
罗马不是一天建成的,数据质量体系也是。
核心要点总结:
93%的AI项目失败源于数据质量,而非算法或算力——这个数字比我预期的还要高 传统规则治理在规模化和智能化方面存在根本局限——规则太多维护不过来,而且只能发现已知问题 AI驱动数据质量的三个核心能力:统计推断、上下文感知、主动预警 2026年的新突破:LLM终于让机器能理解数据语义了 落地路径建议:从核心表开始,分阶段推进,质量前置,持续运营
数据质量是AI应用的基石。这个地基打不好,上面的模型和算法再花哨也是白搭。
先把脏数据治理好,再谈什么AGI吧。
参考资料:
MIT AI Report 2026 Gartner Data Quality Market Guide 2026 Apache Griffin官方文档 Google Dataplex技术白皮书
往期推荐:
关注「数智熔炉」,专注企业级数据&AI架构实战解析。
