 夜雨聆风
夜雨聆风
古老图书馆 · 知识与记忆在光影中沉淀
「大模型怎么做到又大又便宜?」系列第 2 篇
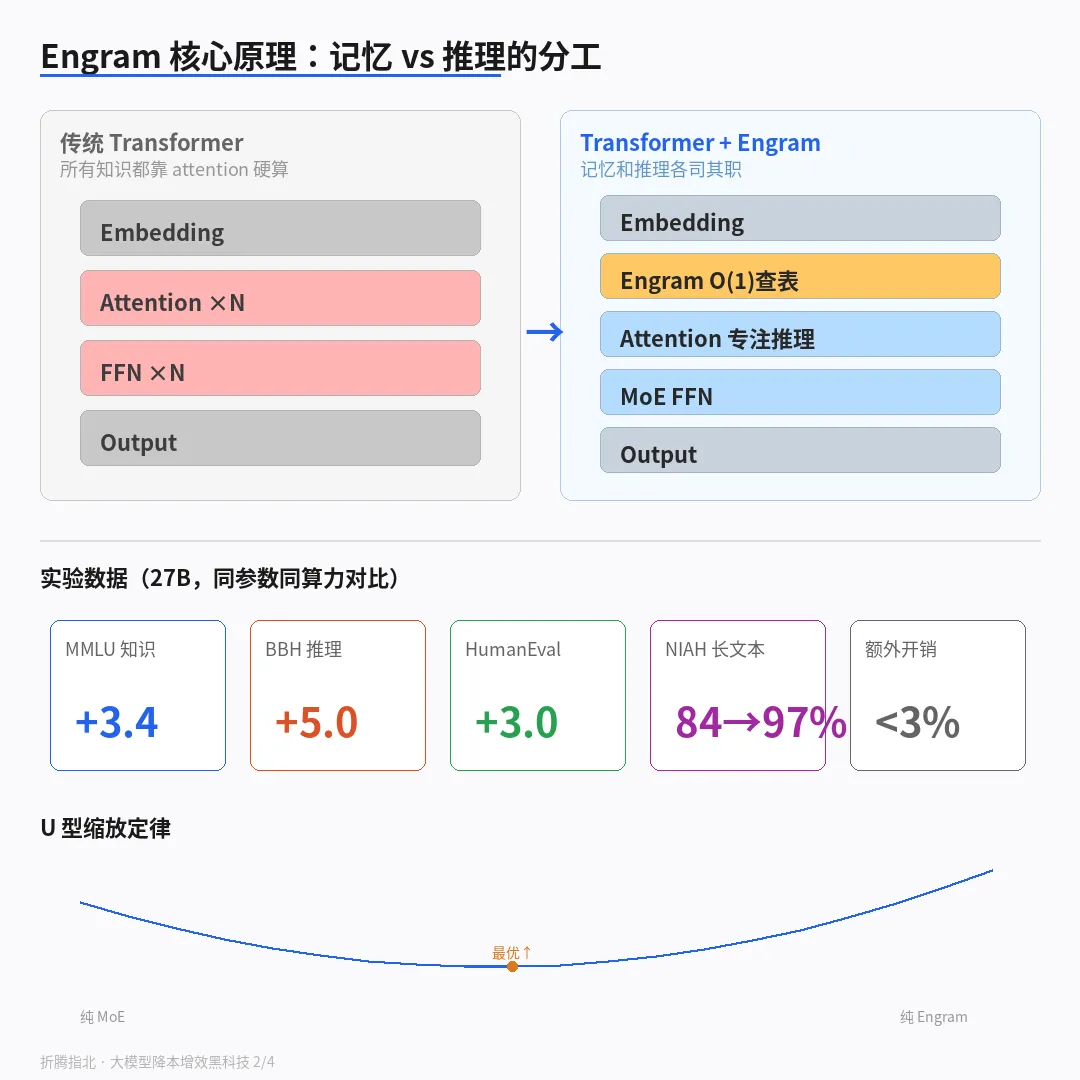
你小学背乘法表的时候,3×7=21,脑子里是直接蹦出来的,不需要掰手指,更不需要"推理"。但一个 270 亿参数的大模型,回答「法国首都是什么」——巴黎,一个地球人都知道的事实——也要把几十层 Transformer 从头跑一遍,做几百亿次浮点运算。DeepSeek 的研究团队做了个实验:给 27B 模型加上一个叫 Engram 的记忆模块后,在同等参数量、同等算力预算下,知识类任务直接涨了 3-4 分,长文本大海捞针测试从 84.2% 飙到 97%。代价?推理时额外开销不到 3%。
这篇文章,我们来拆这个"记忆印迹"到底是什么。
大模型的「死记硬背」问题
上一篇我们聊了 MoE——用路由器把算力精准投放到需要的专家上,解决了"算力浪费"的问题。但 MoE 没碰另一个更隐蔽的浪费:知识检索的浪费。
打个比方。你的大脑里有两套系统:一套是记忆系统——北京是首都、水的分子式是 H₂O、你家 WiFi 密码是多少,这些东西存在那里,用的时候直接取;另一套是推理系统——证明勾股定理、分析一段代码的 bug、理解一个复杂的比喻,这些需要你一步步想。
人脑天生就有这个分工。但 Transformer 没有。
Transformer 的架构里,不管你问的是「中国有多少个省」还是「请证明哥德巴赫猜想」,它都走同一条路:token 进来 → 过 attention → 过 FFN → 一层一层往上叠,直到最后一层吐出答案。简单的事实查询和复杂的逻辑推理,走的是完全相同的计算流水线。
这就好比你去图书馆借一本书,和你去图书馆做一道微积分题,都要先把整个图书馆从头到尾走一遍。
荒谬吗?荒谬。但过去几年,大家的解法一直是:把图书馆建得更大。参数从 1B 堆到 100B 到 1T,暴力出奇迹。直到有人问了一个不一样的问题——
能不能在图书馆门口放一个索引柜,常用的事实直接查,只有复杂问题才进图书馆?
索引柜:Engram 的核心设计
Engram 这个名字来自神经科学——engram,记忆印迹,指的是大脑中存储特定记忆的物理痕迹。上世纪神经科学家花了几十年寻找 engram 的实体位置,最终发现记忆不是存在某一个神经元里,而是分布在一组神经元的连接模式中。
DeepSeek 团队借了这个概念,但做的事情更直接:给 Transformer 加一张哈希查找表。
具体来说,Engram 是一个条件记忆模块(Conditional Memory)。它的工作原理可以用你手机上的通讯录来理解:
1. 输入一个名字(比如连续几个 token 组成的短语"北京是")
2. 哈希一下(把这个短语映射到一个地址)
3. 直接取出对应的值("中国的首都"对应的向量表示)
整个过程是 O(1)——常数时间,不管你的表有多大,查一次的时间是固定的。不需要过 attention,不需要层层传递,直接命中。
论文里的原话很精准:MoE 是计算维度的稀疏化,Engram 是记忆维度的稀疏化。两个正交的省钱轴。MoE 说"不是所有专家都要干活",Engram 说"不是所有知识都要靠算出来"。
但这张"索引柜"远没有听起来那么简单。往下拆。
架构拆解:不止是一张表
Engram 的架构有四个关键组件,每一个都有讲究。

第一层:tokenizer 压缩。 Engram 先对词表动了手术,砍掉了 23% 的冗余 token。为什么?因为查找表的大小和词表直接挂钩,词表越精简,表越小,哈希冲突越少。这一步是在源头降本。
第二层:多头哈希(Multi-Head Hashing)。 不是一个哈希函数,而是多个。就像你查通讯录不只按名字查,还能按公司、按地区查。多头哈希让同一个输入可以从不同角度命中不同的记忆条目,大幅降低冲突率,提高召回精度。
第三层:上下文感知门控(Context-Aware Gating)。 这是最聪明的部分。查找表取出来的结果,不是直接塞给模型,而是经过一个门控机制——模型会根据当前的上下文决定「这条记忆有多可信」。如果上下文很复杂、查找表给的结果不太靠谱,门控会把权重调低,让模型回退到正常的 attention 推理。这就像你查通讯录找到一个号码,但心里犯嘀咕"这号码是不是过期了",于是决定还是打 114 确认一下。
第四层:深度因果卷积(Deep Causal Convolution)。 Engram 不只看单个 token,而是用因果卷积捕捉局部的 n-gram 模式。"北京是"三个字连在一起和"北京""是"分开出现,意义完全不同。因果卷积保证模型只看过去、不偷看未来,同时把局部上下文编码进查找的 key 里。
这四层叠在一起,Engram 就不再是一个死板的字典,而是一个有上下文判断力的快速记忆系统。
实验:同样的钱,更好的效果
论文用 27B 参数模型做了严格的对照实验——iso-parameter(参数量相同)、iso-FLOPs(算力相同),唯一的变量就是有没有 Engram。
结果相当有说服力:
知识类任务直接受益最大,毕竟 Engram 本质就是在帮模型"记东西":
● MMLU(综合知识):+3.4 分
● CMMLU(中文知识):+4.0 分
推理类任务也涨了,这有点出人意料:
● BBH(综合推理):+5.0 分
● ARC-Challenge(科学推理):+3.7 分
● DROP(阅读理解推理):+3.3 分
编码和数学同样受益:
● HumanEval(代码生成):+3.0 分
● MATH:+2.4 分
● GSM8K(数学应用题):+2.2 分
长文本是最戏剧性的:
● Multi-Query 大海捞针:84.2% → 97.0%
● Variable Tracking:77.0% → 89.0%
等等——一个"记忆模块",为什么能提升推理能力?
释放 attention 的「带宽」
这是 Engram 最反直觉的地方,也是论文最有价值的洞察。
研究团队分析了模型内部的计算流向后发现:在没有 Engram 的标准 Transformer 中,前几层的 attention 有大量算力花在了"静态重建"上——也就是在重新构建那些本该直接查表就能得到的事实性知识。
打个极端的比方:你要写一篇关于法国历史的论文,但每次动笔前都要先从头推导一遍"法国在欧洲""巴黎是首都""法语是官方语言"这些基础事实。你的"推理带宽"有很大一部分浪费在了重建常识上。
Engram 把这些"静态重建"的活儿接过去了。局部依赖卸载到查找表后,attention 层的容量被释放出来,可以专注处理真正需要全局上下文理解的复杂任务。
这就解释了为什么推理任务也涨分——不是 Engram 在帮你推理,而是 Engram 帮你腾出了推理的空间。
论文还发现了一个优雅的规律:U 型缩放定律。神经计算(attention + FFN)和静态记忆(Engram 查找表)之间存在一个最优分配比例。记忆分配太少,模型还是要靠算力硬算事实;记忆分配太多,推理能力又被挤占。最优点恰好在中间,呈现 U 型曲线。
这意味着"给模型加记忆"不是越多越好,而是有一个甜蜜点。
与 MoE 的合体:两个正交的维度
Engram 和 MoE 天然互补。
MoE 在计算维度做稀疏化:不是所有专家都参与每次计算。Engram 在记忆维度做稀疏化:不是所有知识都需要通过计算来获取。
论文展示了两者集成的方案:多分支架构(M=4),共享嵌入表 + 分支独立门控。翻译成人话就是——四个专家分支共用同一张记忆索引表,但每个分支有自己的门控来决定「我要不要用这条记忆」。
系统实现上,100B 参数的查找表可以卸载到主机内存(不占 GPU 显存),推理时的额外开销不到 3%。对于一个能带来全面 3-5 分提升的模块来说,这个代价几乎可以忽略。
如果说第 1 篇 MoE 是在问"怎么让算力不浪费",这篇 Engram 是在问"怎么让知识不用算"。两个问题的答案叠在一起,就是 DeepSeek 架构效率的底层逻辑。
对开发者意味着什么
说几个实际的事。
第一,Engram 可能改变微调的逻辑。 如果事实性知识主要存储在查找表而非网络权重中,那微调可能不再需要动整个模型——只更新查找表就能注入领域知识。这对垂直领域的小团队来说是巨大利好。
第二,RAG 的必要性可能下降。 当前很多团队用 RAG(检索增强生成)来弥补模型知识的不足。但如果 Engram 能在模型内部高效存储和检索大量事实,某些场景下的 RAG 可能变得多余。当然,对于实时更新的数据,RAG 仍然不可替代。
第三,推理成本的结构性下降。 Engram 的查找是 O(1),比 attention 的 O(n²) 便宜太多。随着模型规模进一步增大,Engram 节省的计算比例只会越来越高。对于追求性价比的推理部署,这是实实在在的成本优化空间。
第四,关注 U 型缩放定律。 如果你在做模型架构研究或者选型决策,记住:记忆和计算之间有最优比例,不是参数越大越好,也不是记忆越多越好。找到那个甜蜜点,才是真正的工程智慧。
记忆的归记忆,推理的归推理
回到最开始的问题:为什么 AI 回答一个简单事实也要跑一遍完整的神经网络?
答案是——过去几年,我们一直在用一把万能钥匙开所有的锁。Transformer 的 attention 机制确实强大,但让它同时承担"记住事实"和"进行推理"两个完全不同性质的任务,本身就是一种架构层面的浪费。
Engram 的贡献不只是一个具体的模块,而是一个设计哲学的转变:把记忆和推理分开,让合适的机制做合适的事。这和人脑的工作方式不谋而合——你背乘法表和证明费马大定理,用的本来就不是大脑的同一套硬件。
MoE 让算力不浪费,Engram 让知识不硬算。但还有一个大问题悬而未决——当上下文窗口膨胀到百万 token 级别时,attention 本身的计算量就成了最大的瓶颈。O(n²) 的复杂度,100 万 token 意味着万亿级别的运算。
这个问题怎么解?下一篇,我们聊稀疏注意力。
「大模型怎么做到又大又便宜?」系列第 2 篇。觉得有收获,关注「折腾指北」,我们下篇见。
📚 扩展阅读
