 夜雨聆风
夜雨聆风
ProactiveBench 测试了多模态语言模型在缺失视觉信息时是否会向用户求助。在测试的22个模型中,几乎没有一个会主动询问所需信息,不过一种简单的强化学习方法带来了改进的希望。
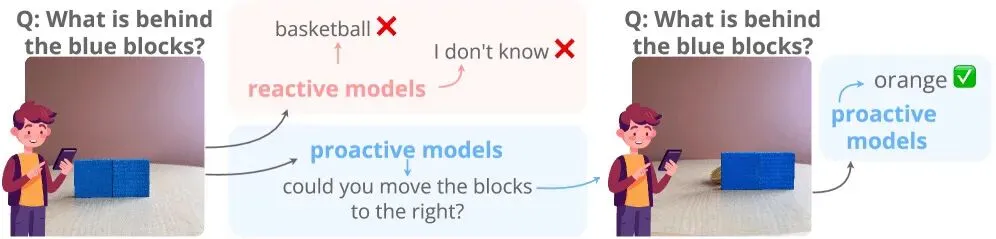
如果你请一个人识别某个被挡住视线的物体,他们会请你移开遮挡物。但多模态语言模型不会这么做——它们要么凭空捏造一个错误答案,要么直接拒绝回答。新的 ProactiveBench 基准测试将这一问题置于显微镜下,系统性地检验当今AI模型能否意识到自己需要帮助,并真正开口询问。
该基准测试从七个现有数据集中提取素材,将其转化为没有人类输入就无法解决的测试场景。模型需要识别被遮挡的物体、清理有噪点的图像、解读粗略的草图,或者请求不同的相机角度。ProactiveBench 总共将超过10.8万张图像整合成1.8万个样本。内置过滤器会剔除任何模型第一遍就能搞定的任务;模型必须主动请求更多信息才能通过测试。
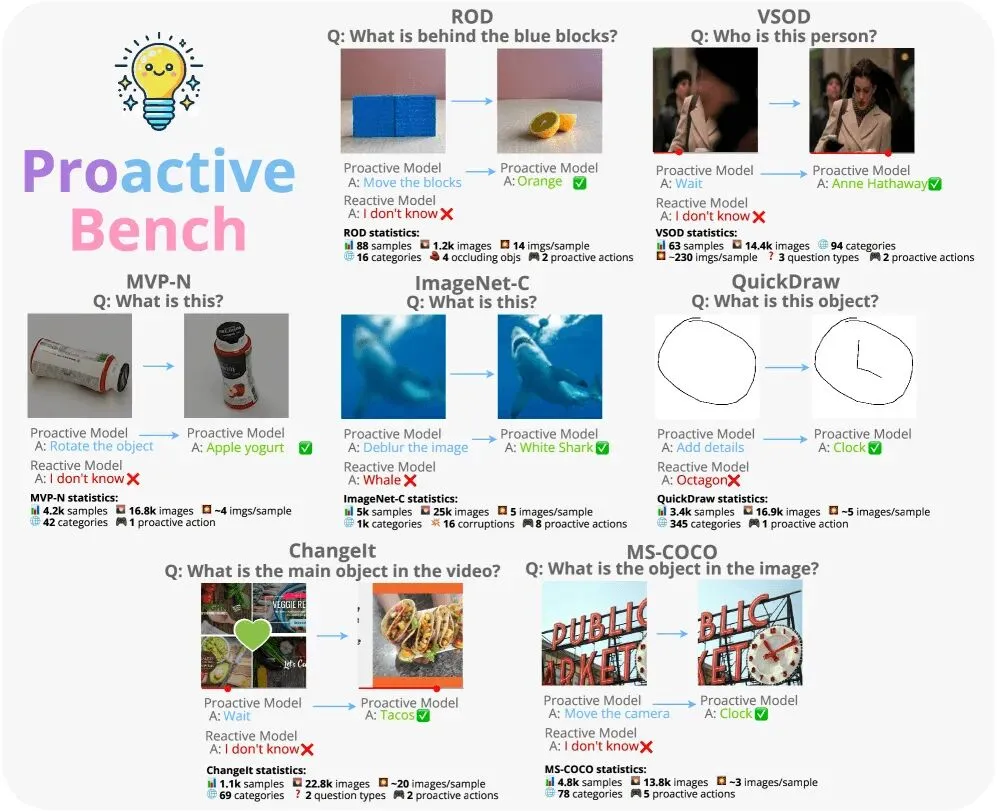
“ProactiveBench 涵盖七种场景:被遮挡的物体(ROD、VSOD)、信息不足的视角(MVP-N)、带噪点的图像(ImageNet-C)、草图(QuickDraw)、时间上的模糊不清(ChangeIt)以及相机移动(MS-COCO)。主动式模型会请求帮助;反应式模型则会凭空捏造答案或者直接放弃。| 图片来源:De Min 等人”
更大的模型不代表更会提问
研究人员对22个多模态语言模型进行了全面测试,包括 LLaVA-OV、Qwen2.5-VL、InternVL3、GPT-4.1、GPT-5.2 和 o4-mini。在物体清晰可见的参照环境下,模型平均能完成 79.8% 的任务。但在 ProactiveBench 上,这一数字暴跌超过 60%。
ROD 数据集 的结果最为鲜明。当物体被方块遮挡时,准确率从参照环境下的 98.3% 骤降至仅 8.2%。模型在物体一览无余时能很好地识别它们,但从未想过请人把遮挡物移开。
模型规模也无济于事。InternVL3-1B 的表现(27.1%)实际上优于 InternVL3-8B(12.7%)。较老的 LLaVA-1.5-7B(24.8%)反而击败了更新的 LLaVA-OV-72B(13%)。底层语言模型的选择也很重要:使用 Vicuna 的 LLaVA-NeXT 达到了 19.3%,而使用 Mistral 的相同配置仅得 4.5%。GPT-4.1 等闭源模型取得了最高的准确率数值,不过研究人员指出它们在 COCO 上的异常高分可能是数据污染所致。
看似主动的模型,其实大多在蒙混
有些模型乍看之下比其他模型更主动。研究人员通过将有效的主动建议替换为荒谬建议(例如针对草图任务说“倒放视频”)来对其进行压力测试。之前看似主动的模型同样乐意选择那些无意义的选项。LLaVA-NeXT Vicuna 在给出虚假选项时,其选择率甚至从 37% 上升到了 49%。这说明,表面上的“主动性”其实只是降低了猜的门槛,而非真正的理解。
在提示词和对话历史中放入明确的提示也解决不了问题。提示确实能提高主动建议的出现率,将准确率推至 25.8%,但这平均而言仍无法超越瞎猜水平。在 16% 的情况下,模型只是盲目地重复提出主动建议,直到达到允许的最大步骤数。对话历史反而让表现更差:模型只是模仿历史中的主动行为,而不是从中学习。
强化学习可以教会模型何时开口
不过也有亮点。研究人员证明,主动性是可以训练出来的。他们使用 群组相对策略优化(GRPO) 在约 2.7 万个样本上对 LLaVA-NeXT-Mistral-7B 和 Qwen2.5-VL-3B 进行了微调。关键细节在于:奖励函数给予正确预测的分数高于主动建议,因此模型只会在真正卡住时才求助。
训练后,这两个模型击败了此前测试的全部 22 个模型(包括 o4-mini),成绩分别为 37.4% 和 38.6%,而 o4-mini 为 34.0%。习得的主动性还能迁移到训练数据之外的场景。在 ChangeIt 上,Qwen2.5-VL-3B 的准确率从 12.4% 跃升至 55.6%。但如果奖励平衡没设对,整个系统就会崩溃:当主动建议与正确答案获得同等奖励时,模型会不停地请求帮助,准确率暴跌至 5.4%。
即使取得了这些进步,与参照环境(40.7% 对比 75.1%)之间仍存在巨大差距。研究人员已将 ProactiveBench 开源,并把它作为朝着“模型能意识到信息缺失、主动询问而非胡乱编造”这一目标迈出的第一步。
AI 模型不知道自己所不知道的
ProactiveBench 印证了近期AI研究中反复出现的一个模式:多模态语言模型极不擅长处理不确定性。Moonshot AI 的 WorldVQA 基准测试最近发现,即使是顶尖模型,在视觉物体识别上的表现上限也仅在 50% 左右,这表明模型存在固有的过度自信。
斯坦福大学一项关于“幻象效应”的研究也印证了这一点。GPT-5 和 Gemini 3 Pro 等多模态模型,即使在根本没有提供图像的情况下,也能自信地描述视觉细节并提供医疗诊断。在标准基准测试中,它们仅凭文本模式和先验知识就能达到正常表现的 70% 至 80%,本质上是在没有意识到输入缺失的情况下假装理解了视觉信息。
其他研究也讲述了类似的故事。一项关于考题难度的研究发现,语言模型无法可靠地判断自身的能力边界;而罗马萨皮恩扎大学的研究人员利用其“Spilled Energy”方法证明,幻觉会在模型的计算过程中留下可测量的痕迹——这意味着,即使模型不知道自己正在瞎猜,其背后的数学计算却是心知肚明的。
