 夜雨聆风
夜雨聆风
欢迎来到「学术地图探索」。本专栏聚焦认知神经科学、发展心理学与人工智能交叉前沿,强调对文献的深度解读和批判性思考。每一篇文献,都是探索人类心智与机器智能边界的一块拼图。本期我们讨论:当我们在使用AI时,我们是变得更聪明了,还是只是变得更自信了?
文献名片
题目: AI makes you smarter but none the wiser: The disconnect between performance and metacognition (AI让你更聪明,却没有让你更清醒:认知表现与元认知的惊人脱节)
发表期刊: Computers in Human Behavior (IF = 8.9)
第一作者: Daniela Fernandes (阿尔托大学)
关键词: Human-AI interaction (人智交互); Metacognition (元认知); Overconfidence (过度自信); Generative AI (生成式AI)
原文链接: https://doi.org/10.1016/j.chb.2025.108779
投稿时间: 2025.3.13 (Received),2025.8.5 (Revised),2025.8.20 (Accepted)
省流版
这篇发表在Computers in Human Behavior上的研究,通过两项大规模实验(N=698)发现,使用AI能显著提升我们在逻辑推理任务中的客观表现,但同时也带来了副作用:
📈表现提升,认知失察
使用AI的参与者不仅高估了自己的表现,而且这种过度自信的偏差程度,比没有使用AI的人更大。
🎭AI 抹平了达克效应
经典的达克效应(能力越低的人越容易高估自己)在使用AI后消失了。AI将所有人的表现都拉高到了一个相近的水平,但也导致所有人都产生了相似的、不切实际的自信。
🤔AI素养的悖论
越懂AI的人,在使用AI时反而对自己的表现判断越不准确。他们更自信,但这种自信与他们的实际正确率关联更弱。
全文约5100字,预计阅读时间12-15min
01 研究背景和贡献
我们正在经历一场认知外包的革命。当我们将复杂逻辑推理、信息检索甚至创意生成交给生成式AI时,一种普遍的分工模式逐渐形成:AI负责推导答案,我们负责接受结果。但问题在于,当我们越来越依赖AI完成认知任务时,我们是否还能清晰地感知到哪些是我做到的,而哪些是AI帮我做到的?我们对于自身能力的判断,是否会因为AI的存在而产生偏差?
这正是元认知所要回答的问题。元认知是人类监控、评估和调节自身认知过程的能力,它决定了我们在何时坚持自己的观点,何时应当寻求帮助,以及如何从经验中不断学习。在当前这个与AI协同工作越来越普遍的环境下,元认知的准确性直接影响了我们能否合理判断AI输出的可靠性,能否在AI犯错时及时干预,以及能否在与AI的协作中获得真正的进步。如果我们的元认知受到了AI的影响,我们就可能在不知不觉中高估与AI协作时自己的表现,并将AI的能力视为自己能力的一部分。
尽管已经有大量工作探讨了人机协同过程中对于表现的提升,但较少有研究深入到元认知层面进行探索。考虑到当前AI的飞速发展以及AI协作的越来越普遍,需要有研究深入探究AI如何影响我们对自己认知的判断,以及这种影响在不同能力水平的人群中是否存在差异。
来自阿尔托大学、慕尼黑大学等机构的研究团队,通过两项大规模实验 (N = 698),首次系统性地揭示了AI使用与人类元认知之间的复杂关系。他们让参与者在ChatGPT辅助下完成法学院入学考试的逻辑推理题,并从元认知准确性(能否准确预估整体表现)、元认知敏感性(能否区分每次回答的对错)以及达克效应(能力与自我评估的错位)三个维度,深入剖析了AI对元认知的影响。研究发现,AI确实让我们更加聪明,客观表现显著提升。但是也让我们更不清醒,过度自信被系统性放大。有趣的是,更加了解AI技术的人,反而受到的影响更大。这项研究不仅揭示了AI使用与元认知之间的复杂关系,更对如何设计下一代人智交互系统,以帮助我们保持清醒的自我认知,提供了关键启示。
02 实验设计:如何测量AI辅助下的自我认知?
为了严谨地考察AI对元认知的影响,研究者设计了两项递进式的在线实验。
参与者:两项研究通过Prolific平台招募英语流利的美国居民。研究1共分析246名参与者(平均年龄39.85岁),他们在ChatGPT辅助下完成所有任务,其结果与Jansen等人(2021)公开的3543名无AI参与者数据(历史对照组)进行比较。研究2则招募了452名参与者,随机分配到AI辅助组(245人)和无AI对照组(207人),并对两组均给予小额金钱激励(约0.5英镑),以鼓励其认真进行自我评估。
任务与流程:核心任务为20道法学院入学考试逻辑推理题(与历史对照组使用的题目完全相同)。如图1所示,AI组界面左侧显示题目,右侧嵌入ChatGPT-4o对话窗口,参与者必须至少向AI提问一次才能提交答案,但可自由决定交互深度。每道题回答后,参与者需用滑块(0~100)报告对本题的信心评分。实验开始前和结束后,参与者还需分别预估自己在AI帮助下(或无AI时)能答对多少题(0~20),以及自己对AI系统能力的评估、任务难度感知等。
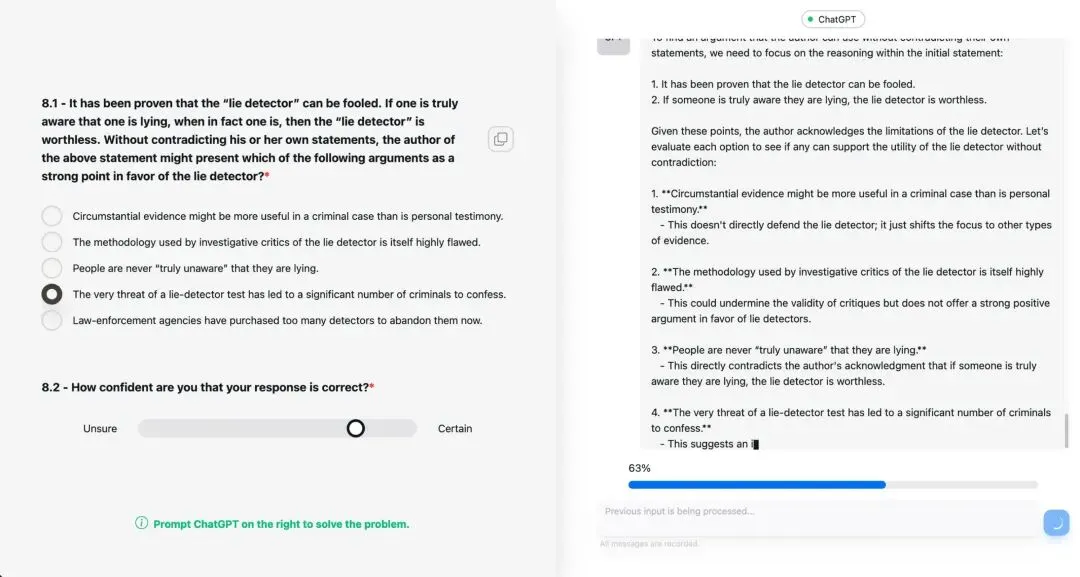
Fig1. 在线研究应用程序的示意图
测量指标:客观表现(答对题数);元认知准确性(预估表现与实际表现之差);元认知敏感性(每道题的信心评分能否区分回答正确与否,用ROC曲线的AUC值衡量)。此外,研究者使用SNAIL量表评估参与者的AI素养,该量表包含三个维度:技术理解(如对AI工作原理的熟悉度)、批判性评估(如能否判断AI输出的可靠性)和实践应用(如日常使用AI的频率和场景)。研究还收集了参与者的提示词记录,用于定性分析交互模式。
统计方法:除了常规的t检验、相关分析和四分位数对比外,研究者构建了分层贝叶斯模型,将参与者的潜在能力、元认知偏差和元认知噪声作为潜变量,同时纳入AI组与无AI组的数据,以检验达克效应的变化。该方法能更精细地剥离偏差与噪声在自我评估中的不同作用。
03 主要结果
1) AI增强人类表现,而非人机协同
研究首先验证了AI的增强效果。在研究一中,使用AI的参与者平均正确数为12.98题,显著高于无AI基准组的9.45题(Cohen‘s d = 1.23)。然而,表现的提升伴随着严重的元认知脱节。参与者平均预估自己能做对16.50题,即高估了约3.52题,这一高估偏差的效应量(d = 0.93)远大于无AI组的对应效应量(d = 0.29),说明AI组的过度自信程度更为显著。并且从平均值来看,人机组合的表现(约65%)并未超越AI单独回答的水平(68.25%),这意味着目前的协作模式仅仅是AI增强人类,未达到理想的人机协同状态。
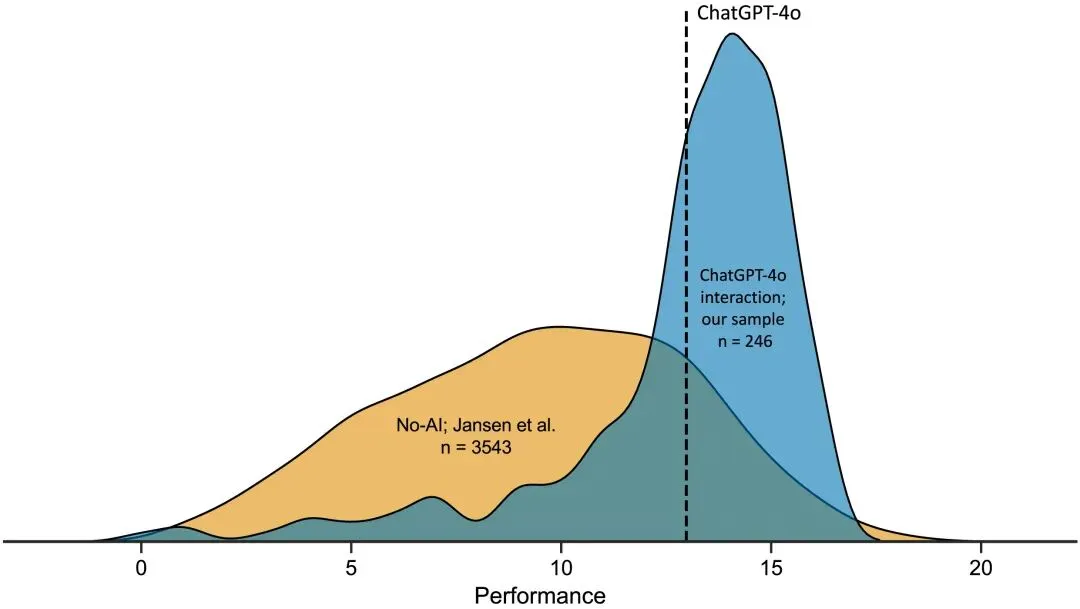
Fig2.研究一的表现分数分布对比。蓝色曲线代表使用ChatGPT的参与者,黄色曲线代表未使用AI的对照组。垂直虚线为ChatGPT的平均表现
研究二的结果完美地复制了这一模式。AI组平均正确数为13.31题,优于无AI组的9.71题,但AI组平均预估17.13题,存在巨大高估。即使提供了金钱激励,这种过度自信依然存在。
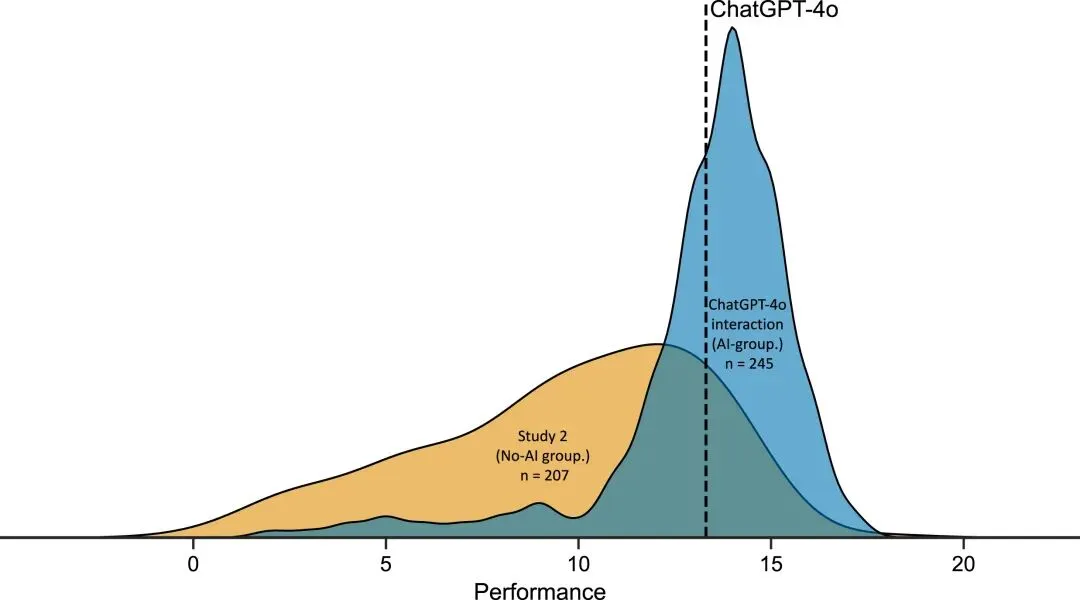
Fig3. 研究二的表现分数分布对比。蓝色曲线代表使用ChatGPT的参与者,黄色曲线代表未使用AI的对照组。垂直虚线为ChatGPT的平均表现
2) 元认知敏感性:信心与正确性的弱关联
元认知准确性衡量的是整体预估的偏差,而元认知敏感性则衡量参与者能否在试次层面,根据信心程度区分自己的回答是对是错。研究通过ROC曲线分析(AUC值)来量化这种敏感性。
在两项研究中,AI组的平均AUC值约为0.62,虽显著高于随机水平(0.5),但明显低于通常被认为是可接受敏感性的0.7基准。这意味着,虽然参与者对自己的答案总体上很有信心,但他们的信心程度并不能很好地区分自己究竟答对了还是答错了——即便是答错的题,他们依然给出了相近的高信心评分。
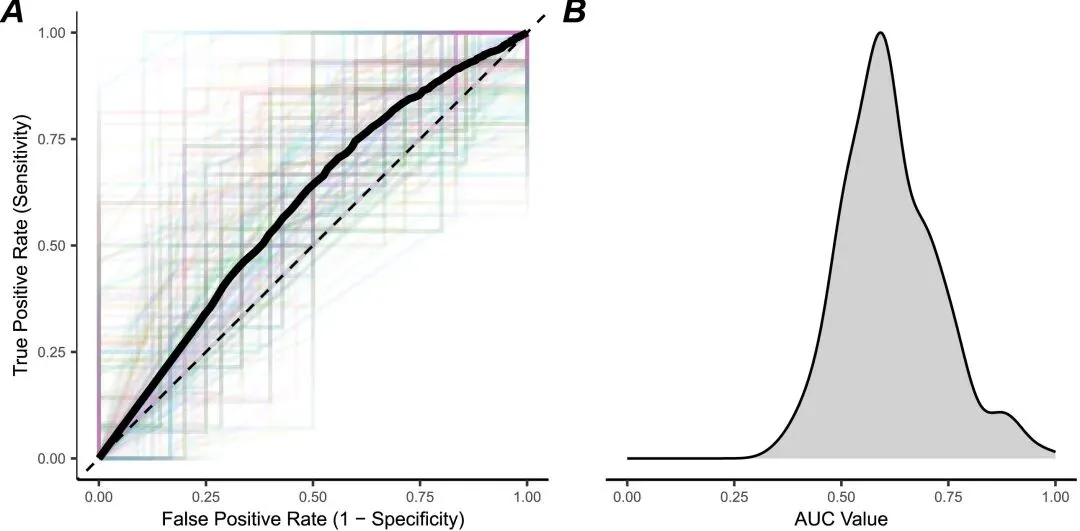
图3. A.每个参与者的ROC曲线;B. AUC值的分布,显示大部分参与者的AUC集中在0.6左右
3) AI抹平了达克效应
经典的达克效应描绘了这样一种现象:能力最差的人,反而最会高估自己;而能力最强的人,则倾向于低估自己。研究团队使用分层贝叶斯模型,将本次的AI组数据与无AI的对照组数据进行了联合建模分析,以探究AI是否改变了这一效应。
模型的关键参数有两个:元认知偏差(b)和元认知噪声(σ)。偏差代表一个人整体高估或低估自己的倾向。噪声则代表一个人评估自己表现时的混乱程度。经典的达克效应,不仅需要存在偏差(b>0),还需要存在噪声(σ>1),这种噪声使得低能力者的自我评估更加不准确。
结果清晰地显示,对于无AI组,σ的估计值远大于1,符合达克效应的特征。而对于AI组,σ的估计值则集中在1附近。这意味着,使用AI后,低能力者与高能力者在评估自身表现时的混乱程度差异消失了。AI将所有参与者的表现拉到相近水平的同时,也使得所有人的自我评估方式趋同,从而导致达克效应消失。但这并非低能力者觉醒了,而是所有人的表现和评估方式被AI拉平了。正如论文作者所言,这支持了他们的增强假说,即AI的稳定输出抹平了个体间的技能差异,导致一种普遍的、高水平的过度自信。
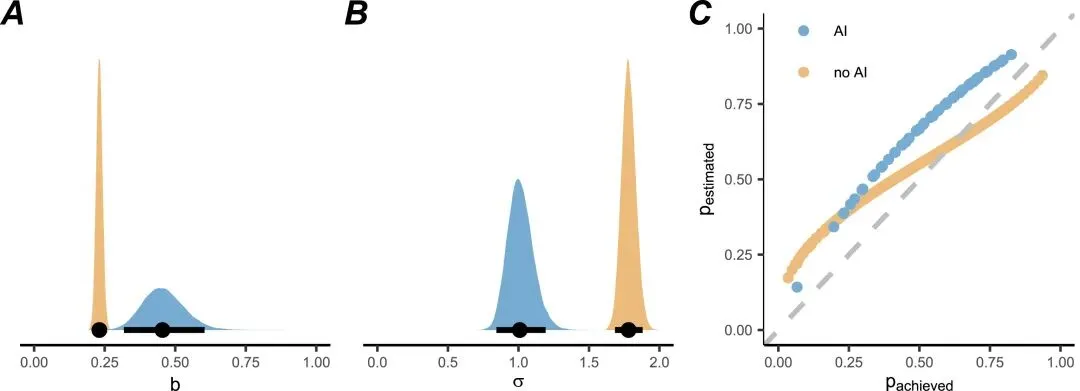
Fig5.贝叶斯模型参数后验分布对比。A. 偏差参数b,显示AI组偏差更大;B. 噪声参数σ,显示AI组σ接近1,而非AI组远大于1;C. 模型预测的预期表现与实际表现关系,AI组(蓝色)的曲线更平坦,呈现均匀的过度自信
4) 懂AI,却不懂自己
研究者使用SNAIL量表测量了参与者的AI素养,并将其细分为技术理解、批判性评估和实践应用三个维度。结果显示了一个令人深思的悖论,即技术理解得分越高的参与者,其元认知准确性反而越低。他们对自己的表现评估偏差更大,同时也表现出更高的平均信心。批判性评估维度也与更高的表现估计值相关。这意味着,对AI运作方式更了解的人,并没有因此更冷静地审视自己的表现,反而陷入了更深度的过度自信。这或许是因为,对技术原理的了解让他们以为熟悉AI的工作流程就等于掌握了答题的能力,从而将AI的正确答案归功于自己的判断。
5) 浅尝辄止的AI使用
研究者为了理解为什么元认知会失效,进一步分析了参与者的聊天记录。结果发现,绝大多数参与者与AI的交互非常浅层。平均每道题只发送1.15个提示,46%的参与者在所有题目中最多只使用过一次提示。定性分析也显示,近60%的参与者表现出对AI的高度信任,会不加批判地直接采纳AI的答案,而只有21%的参与者将AI作为验证自己想法的补充工具。这种浅层互动模式,很可能是导致元认知监控缺失的直接原因。
Tab1. 每道题中使用的最大提示次数分布,显示多数人使用频率极低

04 结果讨论
1) 认知增强,元认知外包
这项研究最核心的启示是,当我们把认知任务外包给AI时,我们可能也无意中将元认知功能一同外包了。AI的流畅输出创造了一种知识幻觉,让我们误以为得出正确答案的推理过程源于自身,从而剥夺了我们进行自我反思和错误检验的机会。这验证了研究的增强假说:AI虽然提升了认知表现,但也抹平了个体在元认知能力上的差异,导致一种普遍的、高水平的过度自信。
2) AI素养不能保证清醒
研究结果对“只要提升AI素养就能解决问题”的简单观点提出了挑战。更高的技术理解,反而与更差的自我评估相关。这表明,现有的AI素养教育可能过于侧重如何使用AI,而忽视了如何在与AI协作中审视自己。真正的AI素养,或许应该包含对自身认知局限的深刻理解,以及对AI辅助下自我表现进行校准的能力。
3) 对交互设计的启示
面对AI带来的元认知挑战,研究提出了一系列设计原则。单纯提供解释或不确定性可视化可能不足以唤醒用户的自我监控。研究者建议引入“认知迫使策略”,例如要求用户在采纳AI答案前,先用简单的语言反向解释AI的逻辑。这种微任务能迫使用户进行深度加工,打破对AI输出的无意识接受,从而校准知识幻觉。
05 未来展望与收获
这项研究为我们理解人智交互提供了一个全新的批判性视角。
1) 对AI教育设计的启示
未来的AI教育不应止步于教会人们如何写提示词。更关键的是,要培养人们在AI辅助环境下的元认知能力,即教会人们如何区分“我的能力”和“AI的能力”,如何判断何时该依赖AI,以及如何从与AI的协作中进行有效的学习。
2) 在法律、医疗、金融等高风险决策领域
在法律、医疗、金融等高风险决策领域,AI辅助已经越来越普遍。这项研究敲响了警钟:一个在AI帮助下表现良好的专业人士,很可能严重高估了自己在没有AI时的判断力。这种过度自信可能导致灾难性的错误,尤其是在AI系统失效或给出错误建议时。
3) 研究局限性
首先,研究以LSAT逻辑推理题为核心任务。尽管该任务在元认知与达克效应研究中具有良好的基准价值,但其结构化、封闭性的特点限制了结论的外部效度。论文作者也指出,这类题目可能与ChatGPT的训练数据存在重叠,且无法反映写作、创意生成等开放性任务中元认知偏差的真实面貌。未来研究应引入更多元的任务类型,以检验现有结论的跨领域适用性。
其次,两项研究均为单次实验室任务,无法捕捉长期使用AI对元认知能力的累积影响。论文明确指出,在Bastani等人(2024)所考察的学习情境中,元认知准确性对于实现持续的表现提升至关重要。因此,未来需要纵向研究设计,以追踪个体在反复与AI交互过程中,元认知监控能力如何随时间演变。
最后,在交互设计层面,本研究要求参与者每题至少向AI提问一次,但交互深度完全由参与者自主决定。这一设定或许无法代表真实世界中更主动或更被动的AI使用模式。论文建议未来研究系统性地操控提示频率与交互深度,以直接检验更深度的人机交互是否能够改善元认知敏感性,为界面设计提供实证依据。
这篇研究提醒我们,评估AI对人类认知的影响,不能只停留在"表现是否提升"这一维度。当客观表现的增益与元认知准确性的下降同时发生时,我们面对的是一种更为复杂的权衡:AI在帮助我们解决问题的同时,也可能系统性地削弱我们对自身能力边界的感知。
正如论文作者所强调的,这一发现对人机交互系统的设计具有直接意义——未来的AI界面不应仅以提升任务表现为目标,更应将支持用户的元认知监控纳入核心设计原则,例如通过实时反馈、认知迫使策略等手段,帮助用户在与AI协作时保持对自身表现的准确判断。
在AI能力持续快速演进的背景下,如何在认知增强与元认知校准之间找到平衡,将是人机交互研究领域值得长期关注的核心命题。
我是桐,欢迎来公众号找我一起探讨!希望我们能一起进步!
Note: 部分内容使用DeepSeek、Hunter Alpha协助总结。
