 夜雨聆风
夜雨聆风
封面:FactReview——证据驱动的AI审稿系统,同时审稿论文和代码
FactReview: Evidence-Grounded Reviews with Literature Positioning and Execution-Based Claim Verification
大家好,我是科研X博士。当前机器学习领域的同行评审正面临投稿量激增与审稿时间不足的双重挤压。现有的基于大语言模型(LLM)的审稿系统几乎全部以"只读论文文本"为输入,依赖作者自述来生成评审意见——这使其对写作修辞高度敏感,且无法核验论文中的实证声明是否真正可复现。FactReview 提出了一种全新范式:将审稿形式化为证据驱动的声明评估,同时从论文文本、相关文献和代码执行三个维度收集证据,为每一条核心声明分配五级评估标签(Supported / Supported by the paper / Partially supported / In conflict / Inconclusive),并输出一份声明与证据之间具有显式链接关系的结构化评审报告。

arXiv: 2604.04074v2 · 7 April 2026 · cs.AI
作者: Hang Xu, Ling Yue, Chaoqian Ouyang(共同一作), Yuchen Liu, Libin Zheng, Shaowu Pan(通讯), Shimin Di(通讯), Min-Ling Zhang
机构: Southeast University(东南大学)· Rensselaer Polytechnic Institute (RPI) · Sun Yat-sen University(中山大学)· The Hong Kong University of Science and Technology (HKUST)
代码: GitHub 仓库 DEFENSE-SEU/FactReview(开源)
关键词: Evidence-Grounded Review · Claim Verification · Execution-Based Verification · Literature Positioning · LLM-Based Peer Review · Automated Scientific Review
最近我们更新了一系列vibe-coding用于研究物理信息神经网络PINN的推文和教程,期望这种【AI人机协作的全新科研范式】得到充分验证和不断发展。
一句提示词,Gemini 3.1 高效高精度实现物理信息神经网络PINNs求解高频PDEs——与Claude Sonnet 4.6的正面交锋(一)(附代码和提示词)
10天产出100篇科研论文,claude code类AI智能体正在重新定义"做科研"
Vibe Coding&Vibe Researching科研系列(一):神经切线核NTK的自适应权重物理信息神经网络PINN求解高频波动方程
Physics-Informed Vibe Coding(2)||NTK自适应加权+多尺度物理信息神经网络求解高频PDEs
Physics-Informed Vibe Coding(3)||变量尺度变换物理信息神经网络求解Navier-Stokes 方程
Physics-Informed Vibe Coding(4):物理信息神经网络训练经常失败?试试梯度自适应加权PINN
Physics-Informed Vibe Coding(5)||仅需100秒,Scale-PINN仿真Navier-Stokes方程Re=7500
系列教程开源代码地址:https://github.com/xgxgnpu/Physics-informed-vibe-coding
https://github.com/xgxgnpu/Physics-informed-vibe-coding
https://github.com/xgxgnpu/Physics-informed-vibe-coding
一、为什么现有 AI 审稿系统不够?
机器学习会议的投稿量持续膨胀,审稿人所承受的压力与日俱增(Pineau et al., 2020; Raff, 2019)。近年来涌现了大量基于 LLM 的自动审稿系统——MARG(D'Arcy et al., 2024)、OpenReviewer(Idahl & Ahmadi, 2024)、DeepReview(Zhu et al., 2025b)、ReviewerToo(Sahu et al., 2025)等——它们能够从论文文本中生成流畅的评审意见。然而,这些系统存在一个根本性的结构缺陷:它们的判断来源仅限于作者的自述叙事。
这一设计有三个核心弱点:
对写作质量过度敏感:修辞包装精良的论文容易获得过高评价,而表达朴素但贡献扎实的工作可能被低估。 无法核验实证声明:一篇论文声称"在多个任务上超越现有方法",但如果不实际执行代码、检查输出数值,这一声明是否成立无从判断。 审稿意见缺乏可追溯性:当审稿意见仅从文本中生成时,每一条判断的证据基础是隐式的——人类审稿人无法检查 AI 做出某个判断的依据。
更近期的研究进一步揭示了 LLM 审稿人的偏差和安全风险,包括声望框架效应(prestige framing)、断言强度敏感性、反驳谄媚(rebuttal sycophancy)和隐式提示注入漏洞(Li et al., 2025; Wang et al., 2026; Zhu et al., 2025a)。
FactReview 正是为了弥补这一结构性缺口而设计的。它的核心理念可以用一句话概括:审稿不应仅仅是对文本的阅读理解,而应是对声明的证据验证。
二、FactReview 的形式化框架与三阶段工作流
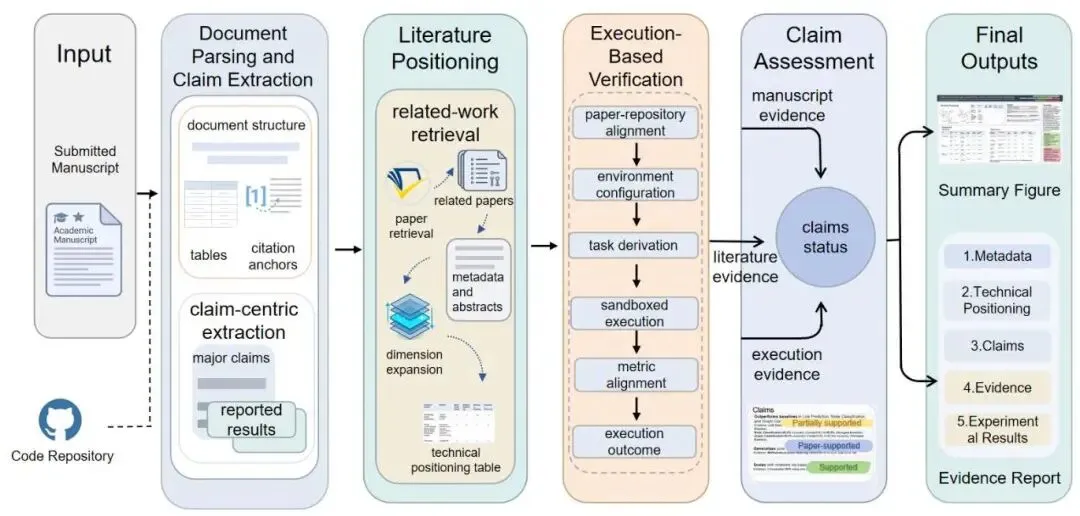 原论文 Figure 1 | FactReview 系统总览。系统解析提交论文,提取核心声明和报告结果,通过检索邻近文献定位论文的技术位置,并在代码可用时执行仓库以验证核心实证声明,最终生成一份简洁的评审报告和关联的证据报告。
原论文 Figure 1 | FactReview 系统总览。系统解析提交论文,提取核心声明和报告结果,通过检索邻近文献定位论文的技术位置,并在代码可用时执行仓库以验证核心实证声明,最终生成一份简洁的评审报告和关联的证据报告。
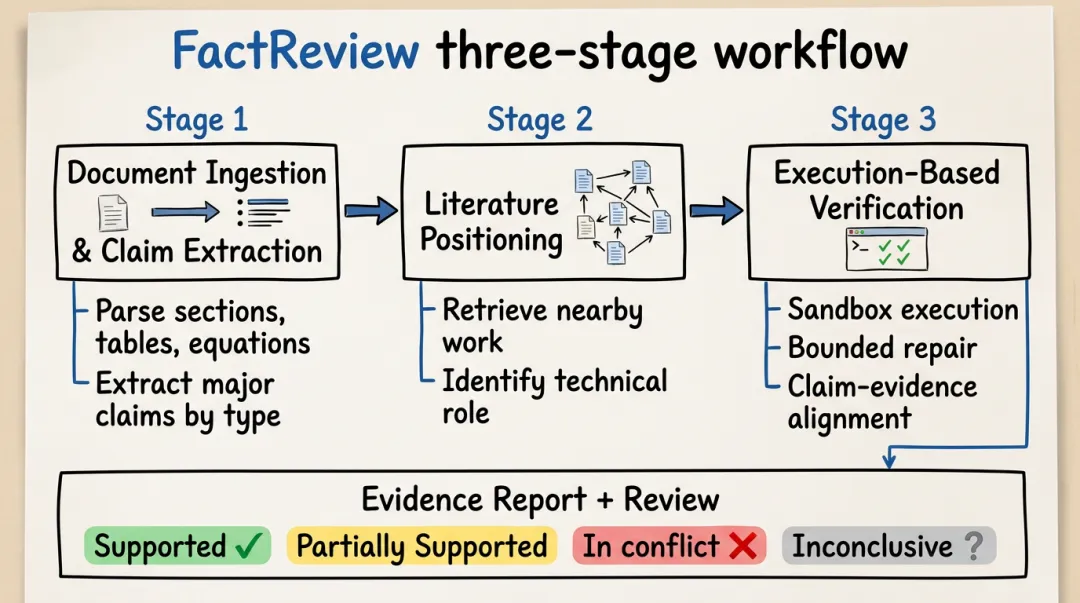 图1:FactReview 三阶段工作流示意。Stage 1 从提交论文中提取结构化声明;Stage 2 通过检索相关文献明确论文的技术定位;Stage 3 在沙箱环境中执行代码仓库验证实证声明;最终输出声明-证据链接的结构化评审报告。
图1:FactReview 三阶段工作流示意。Stage 1 从提交论文中提取结构化声明;Stage 2 通过检索相关文献明确论文的技术定位;Stage 3 在沙箱环境中执行代码仓库验证实证声明;最终输出声明-证据链接的结构化评审报告。
2.1 核心形式化:审稿即声明评估
FactReview 将自动审稿问题重新定义为一个声明评估(claim assessment)任务。设一篇提交论文 包含一组可提取的声明集合 ,每条声明 具有类型属性 。系统的目标是为每条声明寻找证据集合 ,并据此分配标签 。
证据集合 的构成可形式化为三类来源的并集:
其中 为论文内部论证(如数学证明、内部实验对比), 为外部文献检索获得的证据, 为代码执行产出的验证轨迹。标签分配函数 根据证据集合的组成和一致性做出判定——例如,当 且执行结果与声明一致时,;当仅有 可用时,。
这一形式化与传统的"端到端审稿评分"有本质区别:系统不被要求给出 accept/reject 决策,也不生成自由形式的评审散文。每一条审稿判断都必须追溯到具体的证据来源——论文内部论证、外部文献或代码执行轨迹。
2.2 Stage 1:文档解析与声明提取
FactReview 首先将提交论文解析为保留章节边界、表格、公式、图引用和结果位置的结构化表示。在此基础上,系统基于 DeepReview v2(Zhu et al., 2025b)的提示策略进行适配,执行模式约束的声明提取(schema-constrained extraction)。
每条提取的声明存储以下信息:
声明类型:经验性(empirical)、方法论(methodological)、理论性(theoretical)、可复现性(reproducibility) 声明范围(scope):具体涉及哪些任务、数据集、指标 证据目标(evidence targets):后续评估阶段需要检验的具体对象
关键操作是宽泛声明的分解(claim decomposition)。设一条宽泛声明 覆盖 个任务、 个数据集和 个指标,则 被分解为子声明集合:
例如,"本方法在多个任务上优于所有基线"这一声明会被拆分为按任务、数据集和指标分别独立的子声明。后续验证对每个 独立评估,从而使系统能够区分局部成功与整体过度概括。当且仅当所有子声明均获得 Supported 标签时,原始声明 才被标注为 Supported;否则降级为 Partially supported。
2.3 Stage 2:文献定位
系统从被引方法、命名基线和语义相似论文中构建一个局部比较集(local comparison set)。其目的不是给出泛化的新颖性评分,而是回答一个更精确的问题:相对于邻近工作,这篇论文扮演什么技术角色?
文献定位模块识别邻近方法族(neighboring method families)、区分它们的设计选择,以及论文是引入了新机制、组合了已有组件,还是主要贡献了经验性改进。这一局部地图为后续评审提供了讨论技术定位和声明新颖性的具体基础。
2.4 Stage 3:基于执行的声明验证
当代码仓库可用时,FactReview 执行一个有状态的验证工作流(stateful workflow),而非生成单一的 shell 脚本:
仓库解析与环境构建:解析 artifact,创建运行专用工作空间,构建受控环境 任务规划:从 README 命令、配置文件、入口脚本和仓库结构中推导出显式任务列表——验证从固定计划开始,而非临场试错 有界执行:每项任务在显式的时间和资源预算下运行,系统记录命令、返回码、日志、中间输出和归档 artifact 有界修复(bounded repair):设仓库代码空间为 ,其中 为环境配置(依赖、路径、启动脚本), 为核心逻辑(模型架构、损失函数、评估逻辑)。修复策略被严格约束为 ,即修复仅允许作用于环境配置空间——依赖安装、路径修正、启动脚本的小修补、缺失命令参数的补全。FactReview 不修改 中的任何元素。 这一设计确保了验证的保守性。 声明-证据对齐:执行完成后,系统将产出的输出与论文中提取的声明和数值进行对齐。当对齐关系薄弱或不可用时,声明标注为 Inconclusive,而非强制给出正面或负面判定。
三、五级声明标签体系:审稿判断的精细化分解
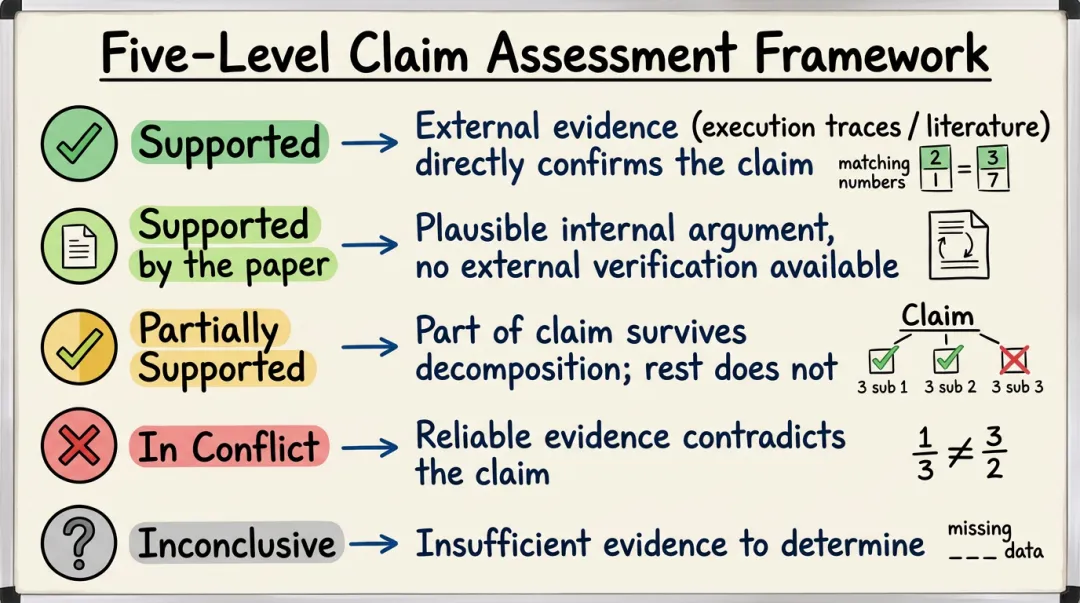 图2:FactReview 的五级声明标签体系。每条核心声明根据证据来源和支持强度被分配一个明确的标签,使审稿判断可追溯、可检查。
图2:FactReview 的五级声明标签体系。每条核心声明根据证据来源和支持强度被分配一个明确的标签,使审稿判断可追溯、可检查。
FactReview 定义了五个层级的声明标签,每个标签对应不同的证据状态:
| Supported | ||
| Supported by the paper | ||
| Partially supported | ||
| In conflict | ||
| Inconclusive |
这一标签体系的核心设计原则是**区分"外部验证的支持"与"仅基于论文自述的支持"**。这一区分在传统审稿实践中通常是隐式的——审稿人可能不自觉地将论文内部论证等同于已验证事实。FactReview 通过标签的显式区分,迫使这一判断过程透明化。
与传统 accept/reject 决策的区别:FactReview 明确不输出最终录用建议。其设计哲学是——AI 在审稿中的最有效角色不是充当最终决策者,而是充当证据收集者,帮助人类审稿人做出更有证据基础的判断。
四、CompGCN 端到端案例研究:宽泛声明如何被精确修正
论文以 CompGCN(Vashishth et al., 2019)为案例,展示了 FactReview 的端到端运行效果。CompGCN 是一个有价值的测试案例,因为它同时包含多种类型的审稿相关声明:特定的架构机制提案、多个任务上的实验结果报告、框架对先前多关系图卷积模型的理论统摄声明,以及基分解(basis decomposition)在保持性能的同时改善可扩展性的声明。
4.1 声明提取与文献定位
FactReview 将 CompGCN 定位于两条邻近研究路线之间:显式建模关系的知识图谱嵌入方法(TransE、DistMult、ConvE)和在结构化图上执行消息传递的多关系图卷积模型(R-GCN、D-GCN、W-GCN)。这一定位揭示了 CompGCN 的核心设计选择:在消息传递过程中组合节点与关系表示,同时使用基分解控制参数增长。
声明提取阶段识别出三条高影响声明:
4.2 执行验证:局部成功 vs. 整体过度概括
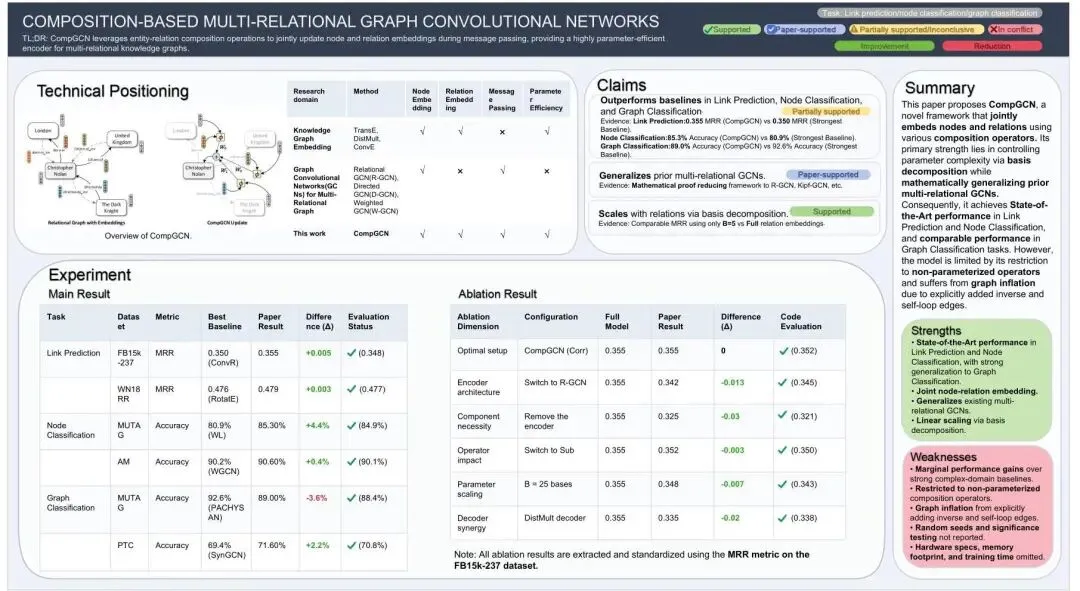 原论文 Figure 3 | FactReview 对 CompGCN 的完整输出。系统将宽泛的性能声明分解为按任务和数据集的子声明,链接到论文、文献和执行证据,并将图分类部分标注为"Partially supported"。
原论文 Figure 3 | FactReview 对 CompGCN 的完整输出。系统将宽泛的性能声明分解为按任务和数据集的子声明,链接到论文、文献和执行证据,并将图分类部分标注为"Partially supported"。
执行改变了对第一条声明的解读。 具体复现结果如下:
| 92.6% (PACHYSAN) | Partially supported | |||||
链路预测和节点分类的复现结果接近论文报告数值,且保持了论文声称的排名模式。然而,全范围声明在图分类上未能维持:MUTAG 图分类的复现准确率为 88.4%,而论文中列出的最强基线 PACHYSAN 为 92.6%,仍然领先。因此,C1 声明的正确标签是 Partially supported 而非 Supported——系统没有否定论文,但将一条宽泛声明修正为更精确的陈述。
C2(理论统摄声明)标注为 Supported by the paper:其主要证据是论文内部的数学推导,属于文本内论证,无外部验证可用。
C3(基分解的可扩展性声明)标注为 Supported:论文分析和复现的经验趋势均表明,使用少量基()即可控制参数增长而不改变局部经验结论。
4.3 与纯文本 LLM 审稿的对比
论文同时展示了标准纯文本 LLM 审稿(Figure 2)与 FactReview 输出(Figure 3)的对比。纯文本审稿将提取、解读和判断压缩为单一的无差异化生成步骤,基本上原封不动地接受了论文的宽泛实证声明。FactReview 则将声明隔离出来,逐一对照任务级证据进行检验,并在图分类结果不再支持全范围陈述时将标签降级。
五、后端模型敏感性:选择哪个 LLM 做审稿代理?
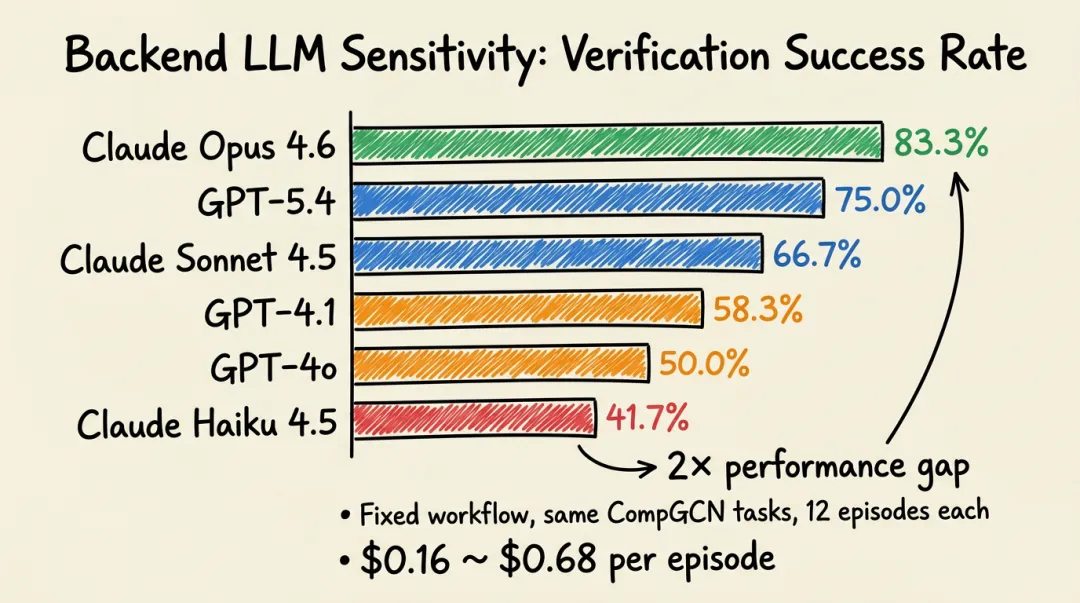 图3:在固定 CompGCN 工作流下,六种后端 LLM 的执行验证成功率。模型能力直接影响证据质量,最高与最低之间存在约 2 倍的性能差距。
图3:在固定 CompGCN 工作流下,六种后端 LLM 的执行验证成功率。模型能力直接影响证据质量,最高与最低之间存在约 2 倍的性能差距。
为了隔离后端模型的影响,论文固定了目标仓库(CompGCN)以及整个编排逻辑(沙箱、任务集、修复策略、停止规则),仅变更底层语言模型。每个模型在涵盖链路预测、节点分类、图分类和基分解分析的 12 个验证回合上进行评估。只有产出了可与某条审稿相关声明关联的执行证据的回合,才被计为成功。
| 83.3 | |||
数据来源:论文 Table 2。成功率为 12 个验证回合中的成功比例;耗时为每回合平均挂钟时间;成本为每回合平均 API 费用。
三个关键观察:
模型家族内的缩放趋势清晰:Claude 家族内,性能从 Opus → Sonnet → Haiku 递减;GPT 家族内,GPT-5.4 优于 GPT-4.1 和 GPT-4o。后端语言模型不是一个可以忽略的实现细节——它直接塑造了最终证据的质量。
性能差距在复杂任务上更大:差距最大的任务是图分类和基分解分析,而非简单的链路预测运行。这支持了论文的核心论点:基于执行的审稿不仅仅是软件自动化问题,模型必须将代码仓库交互关联回声明级别的判断。
成本-性能权衡:低成本模型(如 Claude Haiku 4.5,$0.16/回合)显著降低了 API 开支,但验证可靠性也大幅下降(41.7% vs. 83.3%)。对于审稿这一高要求场景,在后端模型上的投入是值得的。
六、失败分析:执行验证在哪里失效?
论文进一步对 72 个验证回合(6 个后端模型 × 12 回合)中的失败案例进行了分类分析。每个失败回合被分配一个主要失败类型,对应阻断声明级证据的最早因素。
数据来源:论文 Table 3。
Artifact 级失败(29.6%):缺失或模糊的入口点、不清晰的仓库结构 执行级失败(51.9%,最大类别):依赖漂移、不可用的数据或检查点、资源不匹配 解读级失败(18.5%):输出无法与论文中的表格、基线或作用域声明干净对齐
这一分类的意义在于:它让 FactReview 能够区分"负面证据"和"缺失证据"。 一个难以定位或运行的仓库与可复现性相关,但它本身不是针对论文技术声明的反面证据。更广泛地说,基于执行的审稿需要的不仅仅是一个通过/失败状态,而是关于"什么出了问题"以及"是否仍可得出结论"的结构化不确定性。
七、与现有系统的对比及局限性讨论
7.1 系统对比:FactReview 在设计空间中的位置
论文 Table 1 将 FactReview 与现有 AI 审稿范式进行了系统对比:
| FactReview | 有 | 有 | 有 | 有 | 有 | 有 |
数据来源:论文 Table 1。"部分"表示有限支持而非核心能力。
FactReview 的独特定位在于:它是唯一同时具备文献检索、声明评估、基于执行的验证和审稿-证据显式链接的系统,并且明确不输出 accept/reject 最终建议。
7.2 局限性
评估规模有限:论文仅以 CompGCN 一个仓库为端到端案例,虽然另有 72 回合的后端敏感性分析,但缺乏大规模多论文的评估。
适用范围约束:当前仅针对有代码仓库的经验性机器学习论文。对于以理论、数据集或系统贡献为核心的论文,执行验证模块的适用性有限。
有界修复的边界:修复策略严格限制在环境级,这确保了验证的保守性,但也意味着仓库的小改动(如 API 弃用导致的代码不兼容)可能导致验证失败,而非真正反映论文声明的问题。
未与活跃审稿人协作测试:论文未在真实审稿流程中评估 FactReview 对人类审稿人决策质量的影响。
声明提取依赖 LLM 能力:声明的质量和完整性受限于底层 LLM 的理解能力,可能遗漏重要的隐含声明或错误分解复杂声明。
参考文献
Xu H, Yue L, Ouyang C, Liu Y, Zheng L, Pan S, Di S, Zhang ML. FactReview: Evidence-Grounded Reviews with Literature Positioning and Execution-Based Claim Verification. arXiv preprint arXiv:2604.04074, 2026.
Vashishth S, Sanyal S, Nitin V, Talukdar P. Composition-based multi-relational graph convolutional networks. arXiv preprint arXiv:1911.03082, 2019.
Pineau J, Vincent-Lamarre P, Sinha K, et al. Improving reproducibility in machine learning research (a report from the NeurIPS 2019 reproducibility program). J. Mach. Learn. Res., 2020, 22: 164:1–164:20.
Raff E. A step toward quantifying independently reproducible machine learning research. arXiv preprint arXiv:1909.06674, 2019.
D'Arcy M, Hope T, Birnbaum L, Downey D. MARG: Multi-agent review generation for scientific papers. arXiv preprint arXiv:2401.04259, 2024.
Zhu M, Weng Y, Yang L, Zhang Y. DeepReview: Improving LLM-based paper review with human-like deep thinking process. Proc. ACL, 2025, pp. 29330–29355.
Sahu G, Larochelle H, Charlin L, Pal C. ReviewerToo: Should AI join the program committee? arXiv preprint arXiv:2510.08867, 2025.
Idahl M, Ahmadi Z. OpenReviewer: A specialized large language model for generating critical scientific paper reviews. 2024, pp. 550–562.
Li R, Gu JC, Kung PN, et al. LLM-ReVal: Can we trust LLM reviewers yet? arXiv preprint arXiv:2510.12367, 2025.
Asai A, He J, Shao R, et al. OpenScholar: Synthesizing scientific literature with retrieval-augmented LMs. arXiv preprint arXiv:2411.14199, 2024.
Wadden D, Lo K, Wang LL, et al. Fact or fiction: Verifying scientific claims. arXiv preprint arXiv:2004.14974, 2020.
Lu C, Lu C, Lange RT, Foerster J, Clune J, Ha D. The AI Scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292, 2024.
理解要点补充:
为什么"基于执行的验证"至关重要? 传统审稿流程中,审稿人通常仅阅读论文中的实验结果表格,但极少有充足时间去实际拉取代码仓库、配置运行环境、执行实验来验证数值是否可复现。FactReview 的执行验证模块正是将这一"审稿人最需要但最缺乏时间完成"的证据收集工作进行了系统性自动化。
声明分解(claim decomposition)的核心意义是什么? 大量论文在摘要中使用"our method outperforms all baselines across multiple tasks"等宽泛表述,但实际上在某些特定任务或数据集上优势可能极为微弱甚至出现性能倒挂。FactReview 将此类宽泛声明分解为按任务、数据集和指标独立的子声明,逐一对照证据检验,从而系统性地避免了"以偏概全"的审稿盲区。CompGCN 案例中图分类任务上的反例(复现 88.4% vs. 最强基线 92.6%)正是这一设计价值的直接实证。
五级标签体系与传统评分制的本质区别是什么? 传统审稿(无论人类还是 AI)通常给出 1-10 分的综合评分,将多维度信息压缩为单一标量。FactReview 不做综合评分,而是对每条声明分别给出证据驱动的离散标签。这一设计更接近科学声明验证(scientific claim verification)的逻辑——不做整体的"好"与"坏"的判定,而是逐条评估"每一条陈述是否有充分证据支持"。
这篇论文与 The AI Scientist(Nature, 2026)的关系是什么? The AI Scientist 追求的是科研的全自动化生成(从 idea 到论文到自动审稿),其 Automated Reviewer 模块做的是 accept/reject 决策。FactReview 走了一条互补的路线:它不生成论文,不做最终决策,而是专注于审稿过程中的证据收集和声明验证。两者可以被视为 AI 辅助科研的"攻"(生成)与"守"(验证)两面。
推荐学习路径:
先了解 LLM 审稿的基本范式:阅读 Liang et al. (2023) 关于 LLM 是否能提供有用论文反馈的大规模实证分析 理解科学声明验证的形式化框架:阅读 SciFact(Wadden et al., 2020) 阅读本论文(arXiv: 2604.04074)的完整版本,特别关注 Section 3(方法)和 Figure 3(CompGCN 完整输出) 代码实践:GitHub 仓库 DEFENSE-SEU/Review-Assistant
