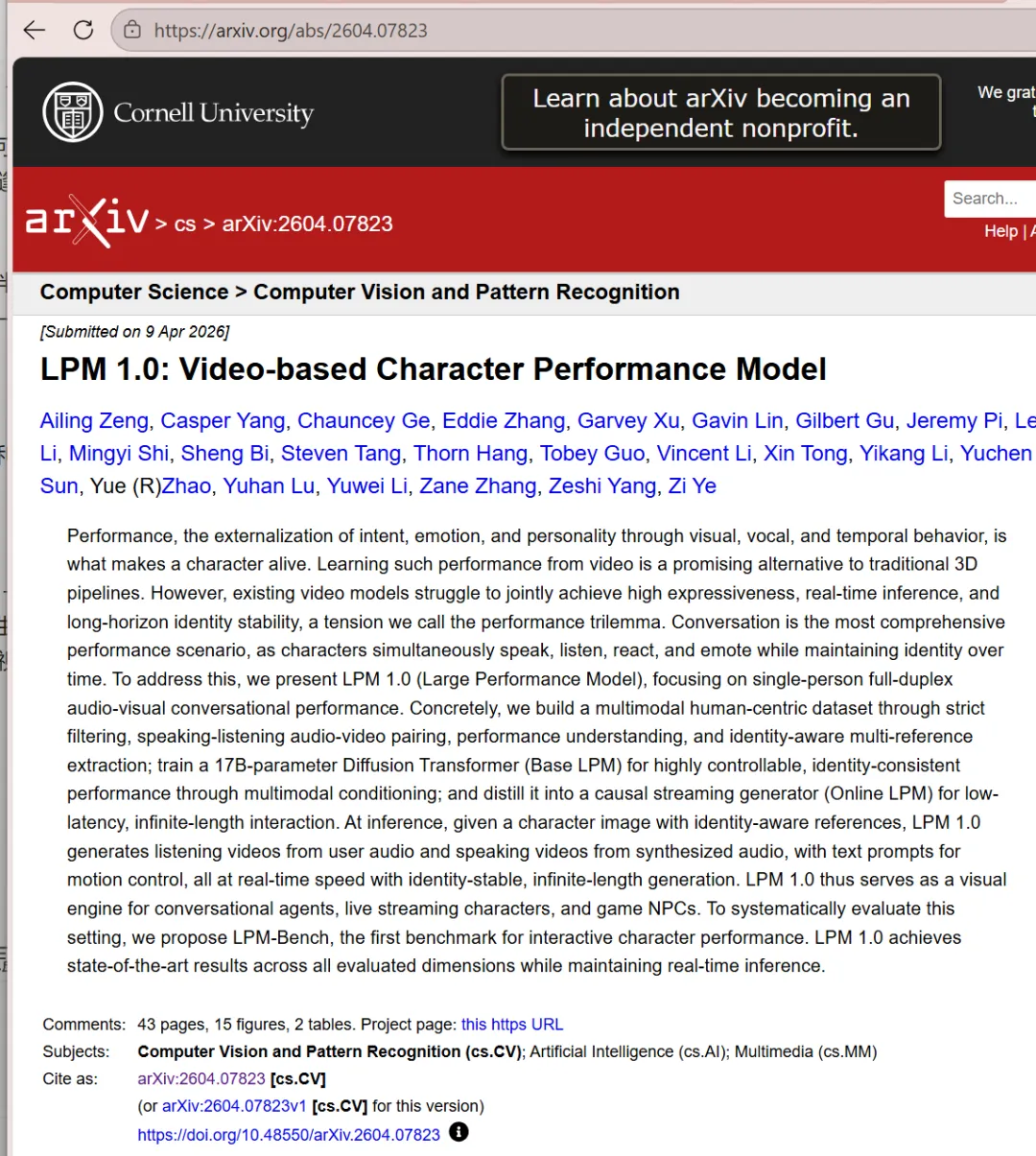
未来工作三轴扩展,时间轴、社交轴、物理轴。展望未来,我们看到有三个关键方向可以拓展这项工作。在时间轴上,较长的互动将需要话语层面的记忆、角色持续性,并能够使当前行为与先前事件保持一致。在社会轴上,多方互动引入了新的挑战,例如收件人跟踪、视线分配和群体层面的轮流发言。在物理轴上,位于环境中的角色必须将其行为与场景几何、物体和接触联系起来。随着这些维度的融合,目前分解——语言生成、语音合成、视听渲染和在线稳定——可能会让位于更统一的角色模型,这些模型能够共同决定说什么、如何表达以及行为如何随时间展开。LPM 1.0 被视为对这一更大问题的首次系统级回答,展示了视频生成不仅可以作为渲染机制,还可以作为互动角色成为可感知参与者。我们相信,视频生成表演模型具有显著的潜力,可以通过为老年人护理、心理健康支持和在线教育提供可获取的 AI 伴侣,民主化各类用户的内容创作,以及推动跨语言和能力的包容性教育体验,从而造福社会。在透明度方面,我们主张所有 AI 生成的角色视频应明确披露,并支持包括《欧盟人工智能法案》、中国《深度合成管理规定》和 NIST 人工智能风险管理框架在内的新兴监管框架,这些框架为生成式 AI 系统建立了披露和问责标准。我们致力于与更广泛的研究社区、政策制定者和公民社会合作,不断迭代这些保障措施,以确保角色表演生成方面的进步服务于集体利益,使对话对每个人来说更加自然、包容和可信。(论文引用94篇参考文献),包括字节跳动的seed模型、阿里Wan、Veo、Kling、商汤的seko、OmniHuman等主流视频生成模型,以及ACE、UniLS等数字人系统。资料来源:论文LPM 1.0: Video-based Character Performance Model
 夜雨聆风
夜雨聆风