夜雨聆风
夜雨聆风摘要
Shuffle Box(光纤分纤盒/光纤重排器件)是AI互联时代实现高密度光纤互联的关键无源器件。此前市场认为Shuffle Box更多服务于CPO产品,但实际上其在当下的网络架构中就将大显身手,它本质上是个更高效的数据重排/交换结构,随着英伟达、博通等算力巨头加速推进大容量交换机量产,Shuffle Box作为其中不可或缺的信号分配与管理组件,正迎来放量拐点,成为光通信产业链中具备长期成长空间的新兴赛道,更能看做光纤入柜后的存在形式。
【基础功能:光纤布线管理器件】
Shuffle Box是一种被动的光纤管理器件,用于在有限空间内实现高密度光纤连接的重新分配与路由。它通过内部预设的光纤布线方案,将输入的光纤信号按特定拓扑结构分配到多个输出端口,起到信号分配、路径优化和空间压缩的作用。
在AIDC从十万卡向百万卡演进的当今,传统布线方案占用大量物理空间,挤压气流通道,安装维护难度极大。Shuffle Box通过简化光纤路由、优化部署以及确保高性能连接,解决了AI基础设施规模化发展带来的挑战。
高效的光纤路由:Shuffle Box在集中的、受控的封闭式机箱内组织和重新分配光纤连接,减少安装错误,确保高密度架构下的精确映射。
紧凑的空间利用:模块化的Shuffle Box减少机架空间需求,为AI工作负载所必需的供电和冷却系统腾出空间。
加速部署:预组织的Shuffle组件减少安装时间,简化大规模GPU集群的部署流程。
【核心驱动力:高速互联技术商用化浪潮】
2026年为CPO量产元年,英伟达已于2025年推出搭载CPO的Quantum-X InfiniBand交换机,2026年3月CPO以太网交换机Spectrum-X实现量产,台积电旗下硅光整合平台COUPE预计于2026年进入量产阶段。
CPO架构下,O/E芯片与光引擎间距大大缩短,传统连接器无法很好满足微距交叉布线需求,且散热与信号完整性矛盾凸显,故需采用shuffle方案进行光纤互联。
在CPO交换机架构中,Shuffle Box承担着关键的信号分配和处理功能——每一根从交换机外部MPO接口进入的光纤,经Shuffle Box可将信号拆分成多路并分别连接到不同的交换芯片上,从而实现信源切割和并行处理。CPO交换机内部需部署数千根光纤,Shuffle Box及配套的高密度连接器、保偏光纤等组件在BOM成本中占据重要地位。
【产业链与竞争格局】
上游核心器件:上游核心材料器件包括光纤光缆、高密度连接器、柔性基板材料等。
高密度连接器:Shuffle box依赖高密度连接器(如MPO/MMC连接器等)来实现高速、高密度的信号连接和传输。高速交换机内部需要大量光纤部署,采用高芯数的MPO可以有效缩减前面板所需端口数量。
柔性基板:高速率交换机常采用光纤柔性板Shuffle方案,需通过多层柔性基板堆叠,在有限空间内构建密集光路网络,实现面板与内部芯片的紧密连接。
竞争格局与壁垒:先发优势明显,呈强者恒强产业格局。
技术壁垒:自动布纤工艺:高密度、高一致性的光纤排布需要精密自动化设备;可靠性设计:高速互联光纤需长期稳定运行,对材料、工艺要求严苛;定制化能力:不同客户、不同拓扑结构需要差异化的路由方案
认证壁垒:Shuffle产品进入英伟达、博通等巨头的供应链需经过严格验证,周期较长,先发优势明显。
Shuffle Box作为高密度光纤互联的关键无源器件,正处于产业放量的关键拐点。AI算力互联密度的提升为Shuffle Box打开了确定性成长空间,Shuffle Box成为其中的标配组件。从产业格局看,Shuffle 产品呈现出高技术壁垒与长认证周期的特征,先发企业凭借精密自动化工艺和头部客户深度绑定,去年Shuffle仍处于概念导入期,今年有望在渗透率快速提升的浪潮中持续受益,相关厂商呈现强者恒强格局。
我们建议关注shuffle 及mpo相关标的:太辰光、蘅东光、长芯博创、仕佳光子。
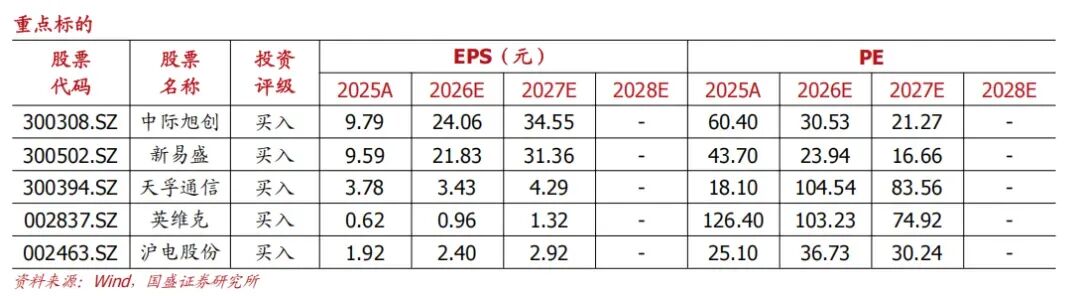
除此以外,我们继续看好光+液冷+太空算力,这三个方向按产业发展阶段,其所对应的风险偏好依次提升。继续推荐算力产业链相关企业如光模块行业龙头中际旭创、新易盛等,同时建议关注光器件“一大五小”天孚通信+仕佳光子/太辰光/长芯博创/德科立/东田微,建议关注国产算力产业链,如其中的液冷环节如英维克、东阳光等。
建议关注:
算力——
光通信:中际旭创、新易盛、天孚通信、源杰科技、太辰光、腾景科技、可川科技、光库科技、光迅科技、德科立、联特科技、华工科技、剑桥科技、铭普光磁、东田微、优迅股份、长光华芯。铜链接:沃尔核材、精达股份。算力设备:中兴通讯、紫光股份、锐捷网络、盛科通信、菲菱科思、工业富联、沪电股份、寒武纪、海光信息。液冷:英维克、东阳光、申菱环境、高澜股份。边缘算力承载平台:美格智能、广和通、移远通信。卫星通信:中国卫通、中国卫星、顺灏股份、海格通信。
IDC:润泽科技、光环新网、奥飞数据、科华数据、润建股份。
母线:威腾电气等。
数据要素——
运营商:中国电信、中国移动、中国联通。数据可视化:浩瀚深度、恒为科技、中新赛克。
风险提示:AI发展不及预期,算力需求不及预期,市场竞争风险。

1.投资策略:
Shuffle Box:从AI的“连接升级”走向“拓扑重构”
本周建议关注:
算力——
光通信:中际旭创、新易盛、天孚通信、源杰科技、太辰光、腾景科技、可川科技、光库科技、光迅科技、德科立、联特科技、华工科技、剑桥科技、铭普光磁、东田微、优迅股份、长光华芯。
铜链接:沃尔核材、精达股份。
算力设备:中兴通讯、紫光股份、锐捷网络、盛科通信、菲菱科思、工业富联、沪电股份、寒武纪、海光信息。
液冷:英维克、东阳光、申菱环境、高澜股份。
边缘算力承载平台:美格智能、广和通、移远通信。
卫星通信:中国卫通、中国卫星、顺灏股份、海格通信。
IDC:润泽科技、光环新网、奥飞数据、科华数据、润建股份。
母线:威腾电气等。
数据要素——
运营商:中国电信、中国移动、中国联通。
数据可视化:浩瀚深度、恒为科技、中新赛克。
本周观点变化:
本周海外算力板块走势强势。从整体市场看,中东局势稍有缓和,市场风险偏好回升。AI芯片股走势强势,英伟达本周股价累计上涨6.3%,英特尔本周股价累计上涨23.8%,博通本周股价累计上涨18.1%。光通信板块持续强势,Lumentum表示能在两个季度售罄整个2028年的产能,股价本周累计上涨8.5%,coherent股价本周累计上涨17%。国内光通信龙头走势强势,中际旭创、新易盛、天孚通信本周分别累计上涨21%、14.8%、7.5%。
我们继续看好光+液冷+太空算力,这三个方向按产业发展阶段,其所对应的风险偏好依次提升。继续推荐算力产业链相关企业如光模块行业龙头中际旭创、新易盛等,同时建议关注光器件“一大五小”天孚通信+仕佳光子/太辰光/长芯博创/德科立/东田微,建议关注国产算力产业链,如其中的液冷环节如英维克、东阳光等。
2. 行情回顾:通信板块上涨,光通信表现相对最优
2026年04月06日-2026年04月12日上证综指收于3986.22点。各行情指标从强到弱依次为:创业板综>中小板综>万得全A(除金融,石油石化)>万得全A>沪深300>上证综指。通信板块上涨,表现强于上证综指。
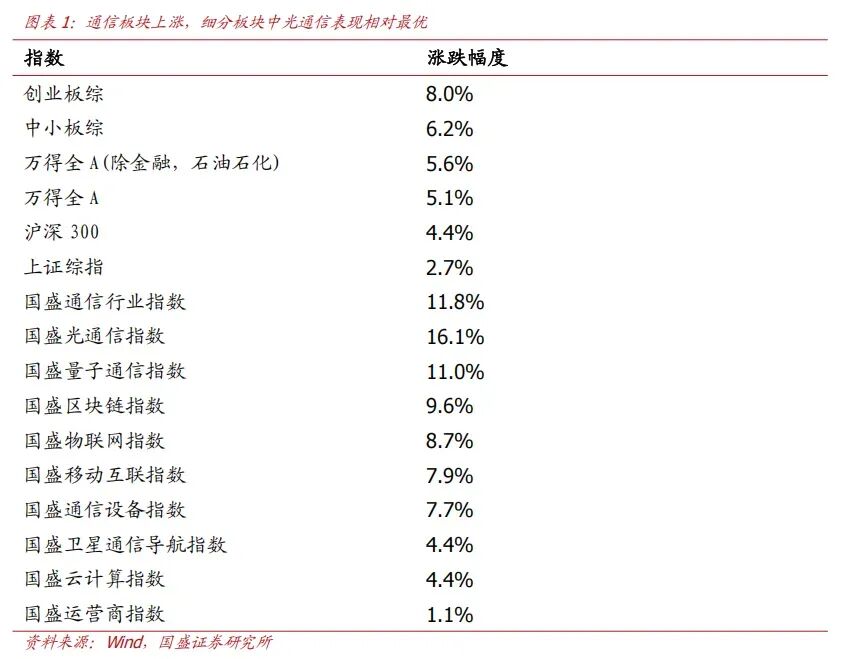
从细分行业指数看,光通信、量子通信、区块链、物联网、移动互联、通信设备、卫星通信导航、云计算、运营商分别上涨16.1%、11%、9.6%、8.7%、7.9%、7.7%、4.4%、4.4%、1.1%。
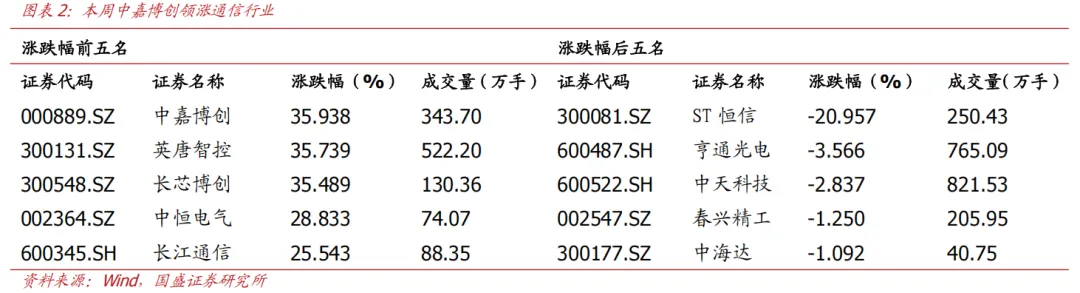
本周受益于区块链概念,中嘉博创上涨36%,领涨板块;受益于存储芯片概念,英唐智控上涨36%;受益于数据中心概念,长芯博创上涨35%;受益于宁德时代概念,中恒电气上涨29%;受益于华为概念,长江通信上涨26%。
3. Shuffle Box:从AI的“连接升级”走向“拓扑重构”
Shuffle Box(光纤分纤盒/光纤重排器件)是AI互联时代实现高密度光纤互联的关键无源器件。此前市场认为Shuffle Box更多服务于CPO产品,但实际上其在当下的网络架构中就将大显身手,它本质上是个更高效的数据重排/交换结构,随着英伟达、博通等算力巨头加速推进大容量交换机量产,Shuffle Box作为其中不可或缺的信号分配与管理组件,正迎来放量拐点,成为光通信产业链中具备长期成长空间的新兴赛道,更能看做光纤入柜后的存在形式。
【基础功能:光纤布线管理器件】
Shuffle Box是一种被动的光纤管理器件,用于在有限空间内实现高密度光纤连接的重新分配与路由。它通过内部预设的光纤布线方案,将输入的光纤信号按特定拓扑结构分配到多个输出端口,起到信号分配、路径优化和空间压缩的作用。
在AIDC从十万卡向百万卡演进的当今,传统布线方案占用大量物理空间,挤压气流通道,安装维护难度极大。Shuffle Box通过简化光纤路由、优化部署以及确保高性能连接,解决了AI基础设施规模化发展带来的挑战。
高效的光纤路由:Shuffle Box在集中的、受控的封闭式机箱内组织和重新分配光纤连接,减少安装错误,确保高密度架构下的精确映射。
紧凑的空间利用:模块化的Shuffle Box减少机架空间需求,为AI工作负载所必需的供电和冷却系统腾出空间。
加速部署:预组织的Shuffle组件减少安装时间,简化大规模GPU集群的部署流程。
【核心驱动力:高速互联技术商用化浪潮】
2026年为CPO量产元年,英伟达已于2025年推出搭载CPO的Quantum-X InfiniBand交换机,2026年3月CPO以太网交换机Spectrum-X实现量产,台积电旗下硅光整合平台COUPE预计于2026年进入量产阶段。
CPO架构下,O/E芯片与光引擎间距大大缩短,传统连接器无法很好满足微距交叉布线需求,且散热与信号完整性矛盾凸显,故需采用shuffle方案进行光纤互联。
在CPO交换机架构中,Shuffle Box承担着关键的信号分配和处理功能——每一根从交换机外部MPO接口进入的光纤,经Shuffle Box可将信号拆分成多路并分别连接到不同的交换芯片上,从而实现信源切割和并行处理。CPO交换机内部需部署数千根光纤,Shuffle Box及配套的高密度连接器、保偏光纤等组件在BOM成本中占据重要地位。
【产业链与竞争格局】
上游核心器件:上游核心材料器件包括光纤光缆、高密度连接器、柔性基板材料等。
高密度连接器:Shuffle box依赖高密度连接器(如MPO/MMC连接器等)来实现高速、高密度的信号连接和传输。高速交换机内部需要大量光纤部署,采用高芯数的MPO可以有效缩减前面板所需端口数量。
柔性基板:高速率交换机常采用光纤柔性板Shuffle方案,需通过多层柔性基板堆叠,在有限空间内构建密集光路网络,实现面板与内部芯片的紧密连接。
竞争格局与壁垒:先发优势明显,呈强者恒强产业格局。
技术壁垒:自动布纤工艺:高密度、高一致性的光纤排布需要精密自动化设备;可靠性设计:高速互联光纤需长期稳定运行,对材料、工艺要求严苛;定制化能力:不同客户、不同拓扑结构需要差异化的路由方案
认证壁垒:Shuffle产品进入英伟达、博通等巨头的供应链需经过严格验证,周期较长,先发优势明显。
Shuffle Box作为高密度光纤互联的关键无源器件,正处于产业放量的关键拐点。AI算力互联密度的提升为Shuffle Box打开了确定性成长空间,Shuffle Box成为其中的标配组件。从产业格局看,Shuffle 产品呈现出高技术壁垒与长认证周期的特征,先发企业凭借精密自动化工艺和头部客户深度绑定,去年Shuffle仍处于概念导入期,今年有望在渗透率快速提升的浪潮中持续受益,相关厂商呈现强者恒强格局。
我们建议关注shuffle及mpo相关标的:太辰光、蘅东光、长芯博创、仕佳光子。
我们继续看好光+液冷+太空算力,这三个方向按产业发展阶段,其所对应的风险偏好依次提升。继续推荐算力产业链相关企业如光模块行业龙头中际旭创、新易盛等,同时建议关注光器件“一大五小”天孚通信+仕佳光子/太辰光/长芯博创/德科立/东田微,建议关注国产算力产业链,如其中的液冷环节如英维克、东阳光等。
4.Mac 跑 AI 模型更方便了,Tiny Corp 称苹果已为英伟达、AMD 外置显卡开绿灯
据IT之家报道,当地时间4月5日,据外媒 Tom's Hardware 报道,苹果已经批准英伟达 eGPU(外置显卡)驱动,使其能够在 Apple silicon 平台上运行。
Tiny Corp 在社交平台披露,其软件已通过审核,用户可以直接将 GPU 连接至 Mac,用于处理 AI 大语言模型。Tiny Corp 还表示,驱动安装流程已大幅简化,“连 Qwen 都能完成”。此前在 2025 年 5 月,Tiny Corp 已实现相关测试,但当时仍需通过关闭系统完整性保护等方式才能运行,而现在这些变通手段都已经不再需要。
Tiny Corp 是 tinybox 的开发方,后者是一款基于四块高端 GPU 的 AI 加速设备。Tiny Corp 此前曾因驱动问题与 AMD 产生冲突,更一度让 AMD 首席执行官苏姿丰亲自介入。
目前,Tiny Corp 在售两款产品:搭载四块 AMD 9070XT 的 red v2,售价 12000 美元(IT之家注:现汇率约合 82707 元人民币);以及搭载四块 RTX Pro 6000 Blackwell 的 green v2 Blackwell,售价 65000 美元(现汇率约合 44.8 万元人民币)。公司还计划在 2027 年推出 exabox,配备 720 块 RDNA5 AT0 XL GPU,计算能力约为 1 exaflop,价格约 1000 万美元。
随着 OpenClaw 等 AI 智能体兴起,市场对高端 Mac 的需求显著增加。大容量统一内存机型供不应求,交付周期从 6 天延长至 6 周。苹果甚至取消了 Mac Studio 的 512GB 统一内存配置,同时将 256GB 版本价格上调 400 美元。
值得注意的是,该驱动并非来自 GPU 厂商,而是由 Tiny Corp 自主开发,因此其主要面向 AI 大模型运算,而非游戏用途。
尽管如此,这一进展对 AI 开发者意义重大。在一定限制条件下,用户有望在普通 Mac 设备上完成训练或推理任务,而无需依赖 tinybox 等专用 AI 计算设备。
5.Anthropic 最强 AI 模型 Claude Mythos 登场:成软件“抓虫大师”,苹果、微软等合力推进网安项目
据IT之家报道,4月7日,Anthropic发布公告,宣布联合苹果、英伟达、微软、亚马逊云服务(AWS)、谷歌、Linux 基金会等 11 家科技巨头,启动 Project Glasswing 项目,发布前沿 AI 模型 Claude Mythos Preview 用于网络防御。
该项目汇聚亚马逊云服务(Amazon Web Services)、Anthropic、苹果、博通(Broadcom)、思科(Cisco)、CrowdStrike、谷歌、摩根大通(JPMorganChase)、Linux 基金会、微软、英伟达和 Palo Alto Networks 共计 12 家科技巨头,共同应对 AI 时代的网络安全挑战。
项目核心是部署名为 Claude Mythos Preview 的前沿模型,旨在利用 AI 技术发现并修复关键软件中的安全隐患,防止高危技术扩散带来的安全风险。
Claude Mythos Preview 展现出惊人的自主“抓虫”漏洞挖掘能力。在过去数周内,该模型自主识别了数千个高危零日漏洞,覆盖所有主流操作系统及网页浏览器。典型案例包括:
发现 OpenBSD 中存在 27 年的远程崩溃漏洞;
定位 FFmpeg 代码中经 500 万次自动化测试未检出的 16 年陈旧漏洞;
自主串联 Linux 内核多个漏洞实现权限提升
这些发现证明 AI 已具备挑战人类安全专家的技术实力。
技术评估数据进一步印证了模型的飞跃式进步。在 SWE-bench Verified 测试中,Mythos Preview 得分达 78.5%,显著高于 Claude Opus 4.6 的 70.1%。
在 Terminal-Bench 2.0 任务中,其得分高达 92.1%。在涉及网络安全的 CyberGym 基准测试中,该模型在漏洞复现能力上展现出对前代模型的压倒性优势。合作伙伴反馈证实,该模型能发现前代技术完全遗漏的复杂漏洞。
Anthropic 为项目提供了强有力的资源支持。公司承诺提供最高 1 亿美元的模型使用额度,并向 Linux 基金会及 Apache 软件基金会捐赠 400 万美元,专门用于支持开源软件维护者。
参与方可通过 Claude API、Amazon Bedrock 等平台接入模型,后续定价为输入每百万 token 25 美元(IT之家注:现汇率约合 172.2 元人民币)、输出每百万 token 125 美元(现汇率约合 861.1 元人民币)。项目已向超过 40 家关键基础设施维护组织开放访问权限。
合作伙伴指出,AI 技术已使漏洞发现到被利用的时间窗口从数月缩短至数分钟。Anthropic 计划在 90 天内公开项目进展,并与政府及行业机构合作制定 AI 时代的安全实践标准。鉴于模型具有潜在双重用途风险,Anthropic 暂不计划公开发布该模型,将优先建立安全防护机制。
6.英特尔加入马斯克Terafab AI芯片制造计划
据C114网报道,4月7日,据路透社报道,英特尔宣布将加入埃隆·马斯克(Elon Musk)旗下的Terafab AI芯片综合体项目,并与SpaceX和特斯拉合作,为马斯克在机器人技术和数据中心领域的宏图提供处理器支持。
受此消息提振,英特尔股价在公告发布后上涨逾 2%。该公司还晒出了一张首席执行官陈立武与马斯克握手的照片,并透露马斯克刚在上周末造访了其公司园区。
这项公告发布数月前,马斯克曾公布特斯拉的一项计划:斥巨资建造一座大型AI芯片晶圆厂,以推动这家电动汽车制造商在自动驾驶领域的宏大抱负;当时他还暗示,特斯拉可能会与英特尔展开合作。
英特尔在社交媒体平台X上发文称,其技术能力将有助于加速Terafab实现“年产1太瓦(terawatt)算力”的目标,以推动AI和机器人技术的未来发展。
陈立武在另一篇帖子中表示:“埃隆拥有重塑整个行业的成功经验。这正是当今半导体制造业所迫切需要的。Terafab项目代表了未来硅逻辑芯片、存储芯片和封装构建方式的一次飞跃。”
上个月,马斯克表示,SpaceX将与特斯拉在德克萨斯州奥斯汀的一处庞大设施中建造两座先进的芯片工厂。其中一座工厂生产的芯片将主要用于驱动汽车和人形机器人;而另一座工厂则将为部署于太空环境的AI数据中心提供算力支持。
与此同时,SpaceX已秘密提交了美国首次公开募股(IPO)的申请,此举有望使其创下史上最大规模的企业上市纪录。该公司计划在今年晚些时候上市。
对于在AI竞赛中一度落后于竞争对手的英特尔来说,随着其转型努力势头增强,此次合作有望提振投资者信心。随着对其处理器需求的增加,英特尔的财务状况也呈现出稳步改善的积极态势。
D.A. Davidson分析师Gil Luria表示:“英特尔亟需向外界证明,它有能力为那些最顶尖的客户提供支持,并协助他们完成最关键、最重要的项目;而此次与特斯拉建立的合作伙伴关系,似乎恰恰印证了英特尔具备这样的实力。”他称这是该芯片制造商重组过程中的“重要一步”。
7.智谱 GLM-5.1“Day0”上线华为云,在昇腾算力上实现 Layer 级 MOE 绝对均衡
据IT之家报道,4月8日,智谱正式发布新一代旗舰模型 GLM-5.1。华为官方宣布,智谱 GLM-5.1“Day0”上线华为云。
据介绍,智谱 GLM-5.1 在昇腾算力上实现了 Layer 级 MOE 绝对均衡,通过框架能力优化让专家均衡产出 Token,同时结合昇腾 Attention 算子特征,通过推理框架和硬件协同的定向优化,提升算力均衡和 HBM 访存均衡能力。华为云通过系统级优化,实现推理加速,整体吞吐提升 30%。
当前,华为云 MaaS 模型即服务平台已为开发者提供免部署、一键调用智谱 GLM-5.1 API 的 Tokens 服务,支持在线体验。企业也可通过华为云魔坊(ModelArts)模型训推平台,一键完成推理服务部署上线,支持公共池和专属池两种资源部署方式,满足独占和非独占算力的使用诉求。
据IT之家4月8日早些时候报道,智谱 GLM-5.1 号称目前全球最强的开源模型。官方表示,其是唯一达到 8 小时级持续工作的开源模型,在最接近真实软件开发的 SWE-bench Pro 基准测试中,GLM-5.1 实现国产模型首次超越 Opus 4.6。
8.中国电信携手阿里云打造粤港澳大湾区首个“真武”国产万卡智算集群,可承载千亿参数级 LLM 推理任务
据IT之家报道,4月8日,中国电信广东公司联合阿里云宣布在广东韶关数据中心集群上线“粤港澳大湾区首个基于‘真武’芯片的万卡智算集群”,该集群实现了从芯片、云平台到模型应用的全链路自主研发。
IT之家获悉,该集群在技术层面实现了多项关键突破。通过卡间 RoCE 高性能组网、双平面多轨通信等技术创新,集群端到端网络时延低至 4 微秒,网络峰值利用率超过 95%,能够高效满足大模型训练过程中 AllReduce、AlltoAll 等超大流量通信需求,稳定承载千亿参数级大模型的预训练与推理任务。
在生态兼容方面,“真武”芯片全面适配主流 AI 生态,自研软件栈高效适配各类主流模型、框架、算子库及操作系统,具备统一的编程接口,可端到端支持用户自主业务落地与扩展,大幅降低客户迁移成本。
为进一步推动算力普惠,该集群资源同步在“广东电信算力超市”上线,通过集约运营,面向中小企业提供按卡、按小时计费的算力零售服务。同时,集群未来预计持续扩容至十万卡规模,惠及大湾区更多科研机构、企业政务部门以更低成本、更高效率使用算力资源。
9.腾讯 QClaw V2 大版本发布:上线多 Agent、跨应用直连,业内首发“龙虾管家”
据IT之家报道,4月9日,腾讯云官宣 QClaw V2 大版本正式上线,新版本(V0.2.5)带来三大核心能力升级:
1.上线多 Agent 功能
以前的龙虾,一次只能干一件事,而且遇到复杂的长任务,很容易撑爆它的记忆(上下文)。
现在,QClaw V2 版本上线了多 Agent 功能,你可以同时拉起最多 3 个 Agent 并行工作,把复杂长任务拆解、消化。
每个 Agent 的性格、口吻与经验均可自定义。如果你不愿手动设置,系统也自带三位风格独特的 Agent:包括毒舌撰稿人“无不言”、爹系辅导员“林且慢”、务实程序员“代可行”,一键即可调用。
比如你手头有个复杂的项目,你可以一边让“无不言”去写推文文案,一边让“代可行”去写代码爬数据,同时还能让“林且慢”帮你梳理和复盘上周的工作进展。
它们各司其职、同步开工、互不干扰,大幅缩短工期耗时。
2.上新连接器,跨应用直连
AI 办公场景中,Agent 帮你写好内容后,还得手动复制粘贴到第三方应用中。
QClaw V2 版本推出的连接器功能,只需在对话框里输入指令,AI 不仅能生成周报、调研等内容,还能自动创建文档或直接发送邮件。
同时,跨应用频繁扫码登录问题也解决了,只需授权一次,以后都能随时调用。另外,系统还内置了“场景模板”,无需手动配置,两步即可完成连接。
目前,QClaw V2 版本首期已经接入了腾讯文档、腾讯会议、ima、金山文档、腾讯问卷、Notion、邮箱等工具。
3.业内首发“龙虾管家”
QClaw V2 版本上线了业内首个自带安全防护的“龙虾管家”。
开启这个功能后,电脑上会挂一个“龙虾管家保护条”,实时监控拦截高风险的执行脚本、文件误删和网络访问。
后台还备齐了安全守护日志,清楚记录拦截过哪些风险。
据IT之家此前报道,腾讯 3 月 20 日官宣 QClaw 龙虾开启全量公测,无需邀请码,用户通过官网下载最新版本,20 秒即可完成安装,并向“龙虾”下达指令。
QClaw 基于 OpenClaw 极简封装,宣称是一款“人人都能轻松使用的 AI Agent”。不用配环境、不用写命令、也不用调模型,下载、安装、开工,三步就能在微信里远程操作,让电脑帮你干活。
10.亚马逊 CEO 安迪·贾西:AWS 到 2027 年底将实现电力容量翻倍
据IT之家报道,4月9日,亚马逊 CEO 安迪·贾西(Andy Jassy) 在其 2025 年度致股东信中表示,其云服务部门 AWS 在 2025 年新增了 3.9GW 的数据中心电力容量,而到 2027 年底其总电力容量将实现翻倍。亚马逊当前仍存在算力瓶颈,客户的需求仍未被充分满足。
AWS 在 2025 年第 4 季度实现了 24% 的同比收入增长,同期总年化营收规模达 1420 亿美元;而在 2026 年第 1 季度其 AI 业务实现了 150 亿美元以上的年化营收。
亚马逊 AWS 的自研芯片大致可分为 Nitro NIC、Graviton CPU、Trainium XPU 三大部分。这位 CEO 表示,已有两位大客户有意包下今年所有的 Graviton CPU 实例容量(IT之家注:当然已被亚马逊拒绝),而未来的 AI 芯片 Trainium4 预计于 2027 年 10 月全面上线。
AWS 的自研芯片业务目前仅通过 EC2 弹性云服务器间接变现,年营收规模突破 200 亿美元。而如果这部分业务独立,同时向 AWS 外的第三方销售,则年营收有望达到 500 亿美元上下。亚马逊未来很可能会对外直接销售芯片。
安迪·贾西提到,亚马逊今年约 2000 亿美元的资本支出大部分很快会在 2027~2028 年变现,目前已有相当规模得到了客户的承诺。
11.小而强,Meta 推出超级智能实验室首款 AI 模型 Muse Spark
据IT之家报道,4月9日,Meta 正推出自九个月前高薪聘请 Scale AI 的亚历山大·王(Alexandr Wang)以来的首个重大人工智能模型。
这款名为 Muse Spark(原代号“牛油果”)的 AI 模型于当地时间周三发布,是 Meta 超级智能实验室(Meta Superintelligence Labs)全新 Muse 系列的首款产品。该 AI 部门由亚历山大·王掌管。亚历山大·王于去年 6 月加入 Meta,此前他是 Scale AI 的首席执行官,Meta 对该公司投资了 143 亿美元(IT之家注:现汇率约合 982.73 亿元人民币)。
Meta 并未将 Muse Spark 定位为顶级模型,而是强调其高效性及在各类任务中的“竞争力表现”。
全新 Muse Spark 将为专有模型,公司表示“有望开源该模型的未来版本”。Meta 此前通过 Llama 系列模型奉行 AI 开源策略。
Meta 正探索新的 AI 模型营收方式:通过 API 向第三方开发者开放 Muse Spark 底层技术。目前仅未具名的“特定合作伙伴”可使用该模型的“私有 API 预览版”,但公司计划未来向更广泛用户提供付费 API 访问。
Meta 称,新模型现已支持独立 Meta AI 应用与桌面端的数字助手。未来数周,Muse Spark 将接入 Facebook、Instagram、WhatsApp、Messenger,以及雷朋 Meta AI 智能眼镜。Meta 还计划让 Muse Spark 最终支持 Meta AI 应用中的 Vibes AI 视频功能 —— 该服务目前依赖 Black Forest Labs 等第三方 AI 模型。
Meta 表示,借助 Muse Spark,独立 Meta AI 应用及相关网站用户可根据提示词复杂度切换模式。简单问题可切换至快速应答模式,复杂查询(如分析法律文件、从超市商品照片提取营养信息)则使用另一模式。
12.风险提示
AI发展不及预期,算力需求不及预期,市场竞争风险。