 夜雨聆风
夜雨聆风Karpathy 用 LLM 搭知识库火了全网。巧的是,二哥在 3 月底就动手搭了一个 AI 能力宝库。7 天搭建完成,之后持续打磨优化,从 121 个标签精简到 46 个,从 18 个智能体瘦身到 10 个。今天把整个过程分享给你。
🔥 AI 大神都在搭知识库,你呢?

最近,AI 圈发生了一件有意思的事。
Andrej Karpathy——特斯拉前 AI 总监、OpenAI 联合创始人——发了一条推文,说自己最近用 LLM 做了一件"比写代码更有价值"的事:搭建个人知识库。
不是简单的笔记整理,而是让 LLM 当他的"全职研究馆员"——自动编译资料、提取概念、维护关联、持续更新。这条推文火了,全网几百万阅读,无数人恍然大悟:原来 AI 最正确的用法,不是让它帮你写代码,而是让它帮你管理知识。
说实话,看到这条推文的时候,我心里有一种"英雄所见略同"的感觉。
不是因为我跟 Karpathy 一样厉害——差远了,人家是 AI 圈的神级人物,我只是个折腾不止的技术大叔。而是因为,我在 3 月底就开始用 Trae 搭建自己的 AI 能力宝库了,思路跟他不谋而合:用 AI 来管理 AI 的能力。
只是我的角度不太一样。Karpathy 关注的是"研究知识"的管理,而我关注的是"AI 工具本身"的管理——技能、规则、智能体、提示词……这些东西散落一地的时候,AI 再强大也发挥不出威力。
😩 你是不是也这样?

你是不是也这样——看到好用的 AI 技能就收藏,看到有趣的提示词就保存,看到别人分享的智能体配置就抄一份?
结果呢?收藏夹里躺着 50 多条目,真正用到的不到 5 个。
更扎心的是,当你真正需要某个技能的时候,你甚至想不起来自己曾经收藏过。于是你又去搜、再去存,周而复始,收藏夹越来越长,能用的东西却没变多。
你的 AI 工具箱可能正在经历这些症状:
- ▹技能文件散落各处:桌面一堆、网盘一堆、收藏夹里还有一堆,想找个东西全凭记忆
- ▹标签命名随心所欲:同一个概念,今天叫"前端设计",明天叫"UI设计",后天又叫"组件设计"
- ▹智能体功能重叠:建了好几个智能体,仔细一看,干的事差不多
- ▹找个东西翻半天:明明记得存过,就是找不到在哪
别笑,这就是曾经的我。
📊 我的"案发现场"
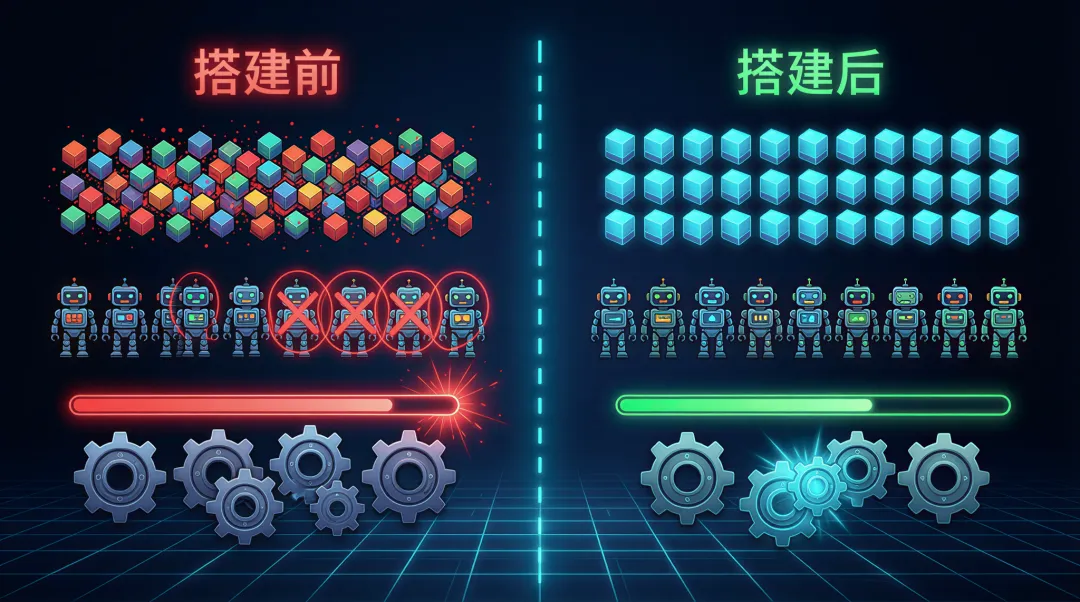
说几个数字,你可能会有共鸣:
- ▹121 个标签——其中 tech 类 44 个,domain 类 64 个。很多标签的意思几乎一样,比如"前端设计""UI设计""UX设计""视觉设计""组件设计",五个标签指向的是同一类东西
- ▹18 个自定义智能体——其中 3 个都是做前端的,功能严重重叠
- ▹6 个规则文件——全部设为"始终生效",AI 每次响应都要加载,上下文被塞得满满当当
那感觉就像一个衣柜里塞了 200 件衣服,每天早上打开衣柜,却觉得没衣服穿。
更关键的问题是:AI 也不好用起来了。因为上下文里塞满了乱七八糟的规则和配置,AI 响应变慢、经常"理解偏了"、给出的方案文不对题。工具越来越多,效率反而越来越低。
AI 工具不是越多越好,管理能力的能力,才是真正的核心竞争力。
所以,我决定给自己搭一个 AI 能力宝库。从 3 月 26 日到 4 月 2 日,7 天完成了主体搭建,之后一直在持续打磨和优化,终于搭出了让我满意的系统。进化关键点在于新版 SOLO,没有它,我可能中途放弃了。
🏗️ 先看看最终效果
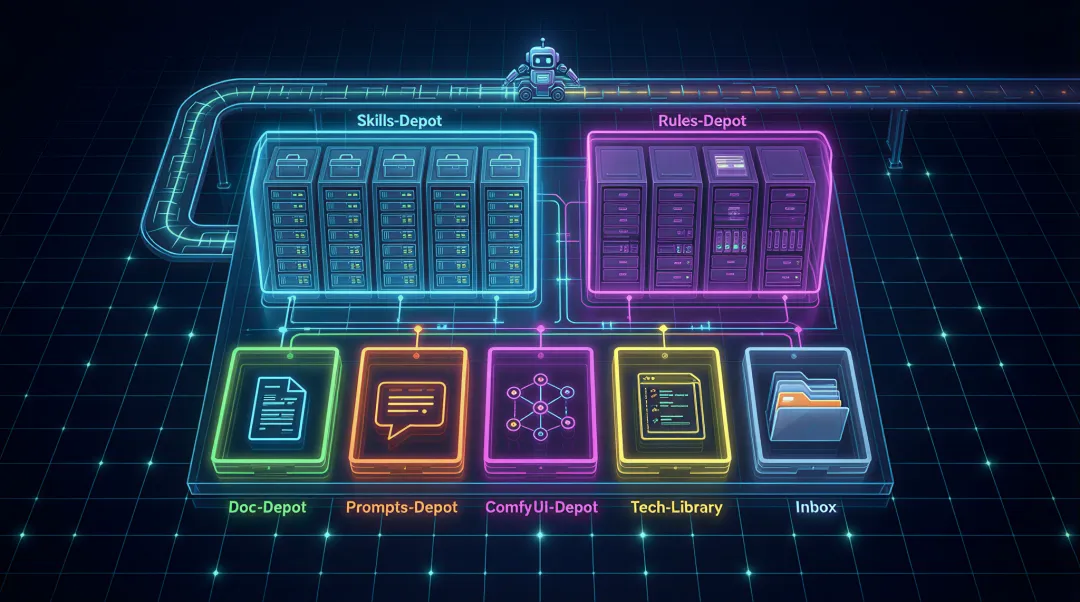
别被这些名字吓到,其实核心思想很简单——分类存放、按需取用。
整个系统叫 Capability Vault(能力宝库),结构长这样:
Capability Vault/├── Skills-Depot/ # 技能仓库(按使用场景分类)├── Rules-Depot/ # 规则仓库(个人/通用/专项三层)├── Doc-Depot/ # 文档仓库├── Prompts-Depot/ # 提示词仓库├── ComfyUI-Depot/ # ComfyUI 资源库├── Tech-Library/ # 技术栈脚手架母本库└── Inbox/ # 缓冲收件箱(暂存区)搭完之后,日常使用的变化是这样的:
举个例子:以前我想找一个"文档排版"相关的技能,要在 5 个不同的文件夹里翻,还不确定放的是最新版还是旧版。现在打开 skills-catalog.md,按标签一搜,10 秒定位。
再比如写公众号文章,以前我需要手动调格式、统一标点、检查错别字,半小时起步。现在我只要说一句"请用 L1 模式检查排版",文档质量排版智能体 30 秒搞定,连标点符号的半角全角都帮我统一了。
别急,这不是什么复杂的企业级系统,一个人就能搭。让我告诉你我是怎么想的、怎么做的、踩了哪些坑。
💡 三个设计原则(和三个坑)
// 原则一:Depot 是权威源,.trae 只是书桌

整个系统的核心原则就一句话:Depot 是权威源,.trae 是生效副本。
什么意思呢?Depot(仓库)里存放你最全、最新的能力文件。而 .trae/ 目录是 AI 工具实际读取配置的地方,里面的文件是从 Depot 按需复制过去的。
打个比方:Depot 是你的总图书馆,.trae 是你书桌上的几本常用书。你不会把图书馆的所有书都堆在书桌上对吧?
🕳️ 踩坑记录:一开始我根本没这个概念,所有东西直接塞进 .trae 目录。结果呢?版本冲突、文件覆盖、改了一个地方另一个地方就坏掉。
最崩溃的一次,我改了一个规则文件,结果另一个项目的同名规则被覆盖了,花了两个小时才恢复。直到 3 月 28 日,我才痛下决心建立了 Depot 架构——一个权威源,多处按需复制,从此天下太平。
可是想法很简单,实现起来却很复杂,后面越来越乱,直到 31 号,拿到了新版 SOLO的邀请码,才慢慢理清了思路。
单一权威源,多处按需生效 ——这个原则不仅适用于 AI 工具管理,也适用于任何知识管理系统。
// 原则二:Skills 是工具箱,Rules 是工作习惯
AI 编程工具里有两个核心概念:Skills(技能) 和 Rules(规则)。很多人把它们混为一谈,其实它们的加载逻辑完全不同。
- ▹Skills 是"专业能力",按需加载。就像你的工具箱,修电脑时才打开,平时不用背着
- ▹Rules 是"行为约束",全量或智能加载。就像你的工作习惯,时刻影响你的行为方式
🕳️ 踩坑记录:最初我把所有规则都设为 alwaysApply(始终生效),结果 AI 的上下文窗口被塞满了,响应速度明显变慢。后来我把规则分成了三层:个人规则(始终生效)→ 项目通用规则(匹配时生效)→ 项目专项规则(特定场景生效),这才解决了问题。
区分能力与约束,是系统设计的第一步。
// 原则三:AI 和人类需要不同的入口
这个原则是我踩了最多坑才悟出来的。
AI 需要的是什么?精确的路由指令——"遇到什么情况,去哪个目录找什么文件"。
人类需要的是什么?友好的导航地图——"这个系统是干什么的,大概怎么用"。
把这两者混在一份文件里,两边都不讨好:AI 觉得信息太多找不到重点,人类觉得技术细节太多看不下去。
所以我把系统分成了三层:
🕳️ 踩坑记录:最初只有一份 README,AI 经常"迷路"——不知道该去哪找东西,人类也抱怨信息太多。拆成三层之后,AI 有了精确的路由指令,人类有了清爽的导航入口,两边都满意了。
🔧 四个核心机制(可复现)
// 标签系统:从 121 到 46 的断舍离
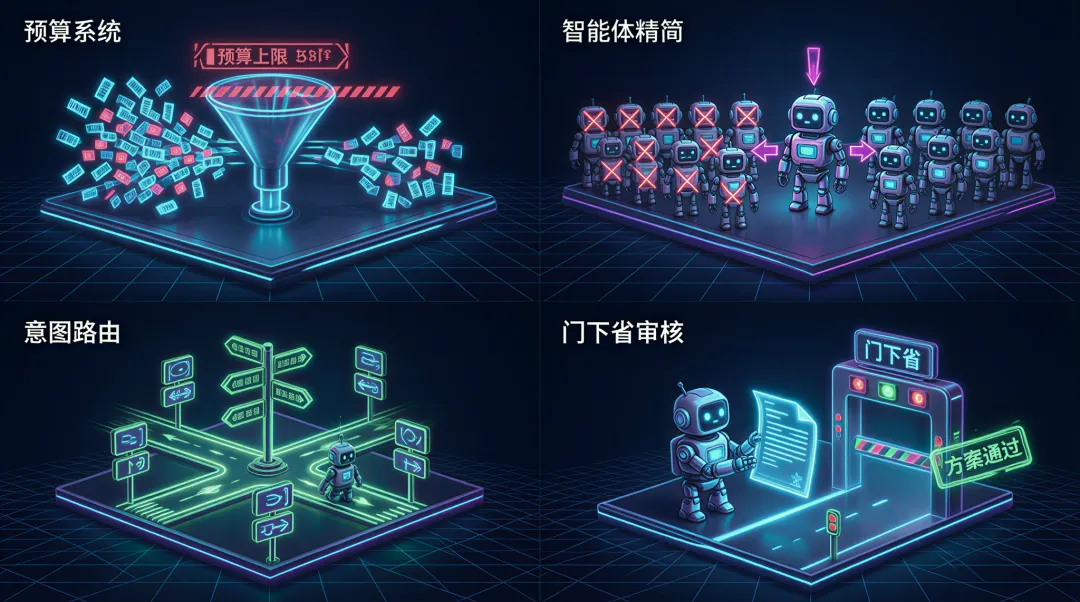
标签是整个系统的"神经系统"。我的标签体系分四层:
标签的组合规则很简单:[type/]domain[+tech]
ref+前端开发+react ← 外部参考 + 领域 + 技术栈note+架构设计+rust ← 笔记 + 领域 + 技术栈bug+调试排错+tauri ← 报错记录 + 领域 + 工具听起来不难对吧?但我走了很大弯路。标签膨胀到 121 个的时候,我发现"前端设计""UI设计""UX设计""视觉设计""组件设计"——五个标签,其实说的是同一件事。
那天我花了半天时间做合并,从此立下规矩:
- ▹标签预算:tech 上限 20 个,domain 上限 25 个,总计不超过 58 个
- ▹准入门槛:新标签必须预计被 ≥3 个文件使用才能加
- ▹合并触发:发现同义词或包含关系时,主动合并
好的标签系统,应该让你在添加新标签时感到"心痛",而不是随手一加。
// 智能体:宁要精兵,不要冗兵
智能体是 AI 编程工具里的"子助手",你可以让它们独立执行专业任务。我最终保留了 10 个:
🕳️ 踩坑记录:曾经我有 3 个前端智能体——UI Designer、前端架构师、前端开发专家。功能重叠到什么程度呢?我让它们分别做同一个任务,给出的方案几乎一模一样。
最离谱的是,三个智能体各自维护一份配置,改了一个忘了改另一个,行为越来越不一致。最终合并为 1 个增强版,同时删除了 8 个冗余智能体(比如"后端架构师"——Java/Spring 微服务,跟我的 Tauri+Rust 技术栈完全不搭;还有"DevOps Architect"——K8s/Terraform,我一个做桌面应用的人用不上这些)。
宁要 10 个各司其职的精兵,不要 18 个互相抢活的冗兵。
// 意图路由:让系统自己找路
有了仓库、标签、智能体,下一个问题是:当我说"帮我入库这个技能",AI 怎么知道该去哪?
答案是一个两层的意图路由系统:
第一层:模式识别(快速路由)┌──────────────┬──────────────────────────┐│ 你说了什么 │ AI 去哪找 │├──────────────┼──────────────────────────┤│ 入库/整理技能 │ Skills-Depot / Rules-Depot││ 编辑/格式文档 │ Doc-Depot ││ 查找/搜索 │ 各 catalog.md 索引 ││ 开发新项目 │ Tech-Library │└──────────────┴──────────────────────────┘第二层:对话式头脑风暴(复杂/模糊任务)→ 先理解,再动手,一次只问一个问题🕳️ 踩坑记录:最早我设计了三层架构——关键词精确匹配 → 模式识别 → 头脑风暴。结果关键词匹配层太死板,经常误判。3 月 31 日砍掉了关键词层,简化为两层,准确率反而提高了。
好的系统不是让用户记住所有路径,而是让系统自己知道该去哪。
举个实际例子。有一天我在 GitHub 上看到一个很棒的 Trae 技能,想入库到自己的系统里。我只需要对 AI 说一句:"帮我入库这个技能",然后把链接贴过去。
AI 会自动完成以下流程:
- 0 1意图识别:判断这是"能力管理"任务 → 路由到 Skills-Depot
- 0 2内容分析:读取技能内容,提取用途、标签、适用场景
- 0 3分类推荐:建议放入哪个分类目录,推荐索引入库还是本地入库
- 0 4执行入库:确认后自动创建文件、更新 catalog 索引
整个过程我不需要告诉它"去 Skills-Depot 的哪个目录""记得更新 catalog""标签要符合规范"——系统自己知道该怎么做。
// 门下省:给 AI 方案加一道审核
最后一个机制,可能也是最有意思的一个。借鉴自(三省六部制)[https://github.com/cft0808/edict]。
我在系统里设计了一个"审核关卡"——借用古代"门下省"的概念。唐朝的门下省有一项权力:可以封驳皇帝的诏书。连皇帝的圣旨都能驳回,何况 AI 的方案?
具体来说,当 AI 要执行一个较复杂的任务时(比如初始化新项目),需要先过一道审核:
- ▹三级分类:轻量任务(跳过审核)→ 标准任务(简短报告)→ 重量任务(逐项清单)
- ▹三维审核:可行性、完整性、风险
- ▹封驳机制:最多 3 轮,未通过则转为自由讨论模式
听起来是不是有点像代码审查?没错,思路确实类似。只不过审查的对象从"同事的代码"变成了"AI 的方案"。你会发现,加了这道关卡之后,AI 给出的方案质量明显提高了一个档次——因为它知道自己的方案会被"检查",所以会更认真地思考。
AI 给你方案之前,先让它过一道审核。这不是不信任 AI,而是对结果负责。
🌟 这套方法论,不只适用于程序员
看到这里,你可能会说:"二哥,我又不用 Trae IDE,这东西跟我有什么关系?"
关系大了。
这套方法论的本质不是某个工具的配置方案,而是一套管理能力的能力。无论你用什么 AI 工具,都可以借鉴这三个思路:
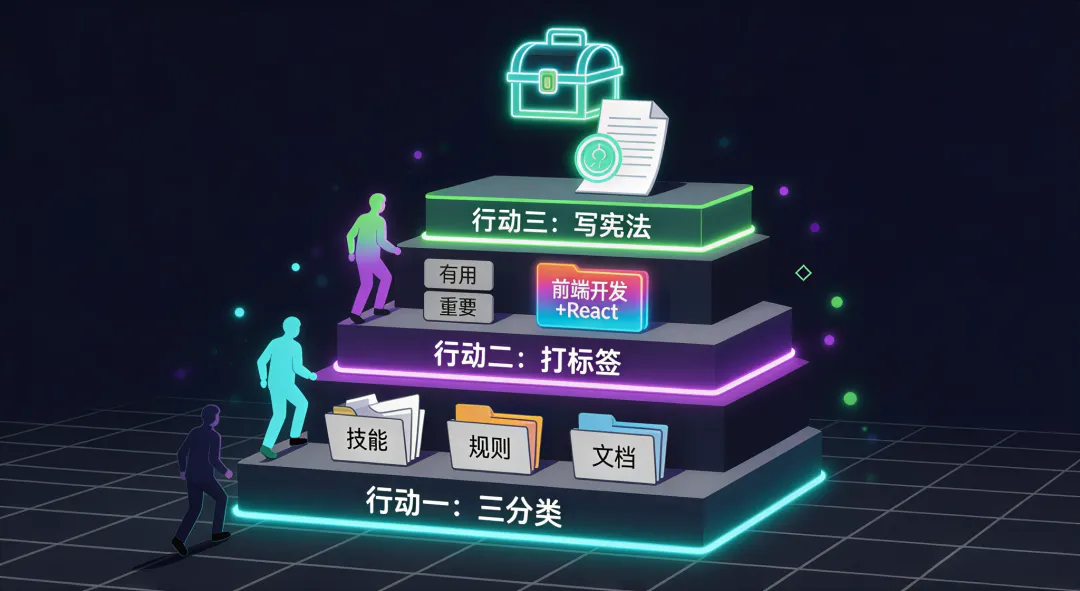
行动 1:给你的 AI 工具做个"三分类"
把你的提示词、技能、规则分三类存放。别再全部堆在一个文件夹里了。分类不需要多复杂,"技能 / 规则 / 文档"三个文件夹就够了。
具体怎么做?打开你存放 AI 相关文件的目录,新建三个文件夹。然后把文件往里分:能执行特定任务的放"技能",约束 AI 行为的放"规则",参考资料和笔记放"文档"。5 分钟就能搞定,效果立竿见影。
行动 2:给文件打标签,试试"领域 + 技术栈"
别再用"有用""重要""待看"这种万能标签了。试试"领域 + 技术栈"的组合,比如"前端开发 + React""内容创作 + AI"。你会发现检索效率提升一个量级。
如果你觉得一开始想不好标签体系,可以先从 5 个领域标签开始:前端开发、后端开发、内容创作、效率工具、学习笔记。等用起来之后,再根据实际需要逐步增加。记住,宁缺毋滥。
行动 3:写一份你的"AI 使用宪法"
花 10 分钟写一份文档,明确你的 AI 工具该做什么、不该做什么。比如"代码修改前必须先说明方案""文档润色前必须先确认需求"。这份文档就是你的 AI 宪法,它能帮你省下无数反复沟通的时间。
不知道写什么?可以从这三条开始:
- 0 1"修改代码前,必须先解释修改思路,等我确认后再动手"
- 0 2"回答问题时,优先引用我提供的资料,不要自己编造"
- 0 3"遇到不确定的问题,先问我,不要猜"
我不是大牛,但我走过的弯路,你不必再走。
如果这篇文章对你有启发,欢迎关注二哥,技术不迷路。
下一期我会详细演示这套系统的实际操作,手把手教你搭建自己的能力宝库。
