 夜雨聆风
夜雨聆风"RAG就像让AI每次都重新读一遍图书馆,而LLM Wiki是给AI建了个自己的书房——知识不再被'检索',而是被'记住'。"
说实话,作为一个AI产品经理,我曾经是RAG的忠实信徒。向量数据库、Embedding模型、Top-K召回……这些词儿说得比自家地址还溜。但用着用着,我发现一个尴尬的事实:AI好像永远都在"重新学习"。
每次我问它一个问题,它都要先去检索、拼接、理解,然后才能回答。这就好比你有个朋友,每次聊天前都要先翻一遍你的朋友圈——效率低不说,还特没"人情味"。
直到我看到了Andrej Karpathy的那篇推文,我才恍然大悟:原来我们一直在用错误的方式和AI共处。
Karpathy 原始文章:
Gist: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
📌 核心要点(省流版)
RAG的本质缺陷:每次提问都从零开始,AI永远在"重新学习",没有知识积累
Karpathy的解法:抛弃RAG,直接用LLM读写Markdown,三层架构搞定知识沉淀
我的实践:飞书+OpenClaw,5个Skill联动,打造自动化知识库流水线
真实数据:11篇文章归档,单篇处理时间从30分钟→2分钟,效率提升15倍
避坑指南:Skill架构别瞎搞,过度设计会把自己绕进去,Claude Code重构救了我
RAG到底哪里不对劲?
先说说RAG的问题。RAG(Retrieval-Augmented Generation)这套玩法,本质上是把知识库当成搜索引擎在用。
你有问题?好,我去知识库里搜一圈,找到最相关的几段文字,拼在一起喂给AI,让它基于这些内容回答。听起来很合理对吧?
但问题在于:AI从来没有真正"学会"这些知识。
每次对话都是新的开始,上次聊的内容,这次它"假装"记得——其实全靠你把历史记录塞进Prompt里。知识库越来越大,检索成本越来越高,但AI的理解深度却原地踏步。
更尴尬的是,RAG特别擅长"一本正经地胡说八道"。检索到的片段可能断章取义,拼接出来的上下文可能逻辑不通,但AI还是会信心满满地给你编一个看似合理的答案。
案例:Notion AI的教训
Notion在2023年推出AI功能时,采用了类似RAG的检索增强方案。用户反馈最多的问题是什么?"AI经常引用错误的文档段落"、"同样的问法,每次答案都不一样"。Notion后来不得不花大力气优化检索算法和重排序策略,但根本问题始终没解决——AI没有形成稳定的知识表征。
Karpathy的观点很直接:与其让AI每次都去"检索"知识,不如让它直接"读写"知识库。 把知识写成Markdown,让LLM自己去读、去理解、去更新。这样知识才能真正沉淀下来,AI才能真正"长记性"。
三层架构到底是什么鬼?
Karpathy提出的方案,核心是一个三层架构:
Raw Sources(原始资料层)→ Wiki(维基层)→ Schema(规则层)
这个结构其实特别好理解,类比一下你做产品的流程:
Raw Sources = 需求池:各种乱七八糟的原始输入,用户反馈、竞品分析、市场调研……先扔进去再说
Wiki = PRD:经过整理、结构化、有逻辑关联的知识文档,真正有价值的东西
Schema = 设计规范:定义怎么写、怎么存、怎么查的规则,保证整个系统不跑偏
关键的操作就三个:
Ingest(录入):把Raw Sources扔进去
Query(查询):从Wiki里找答案
Lint(体检):定期检查知识库的健康状况,看看有没有矛盾、重复、过时的内容
这套玩法和RAG最大的区别是:知识被"编译"过一次,而不是每次现查现用。 就像编译型语言和解释型语言的区别,前者运行更快、更稳定。
案例:维基百科的协作模式
维基百科其实就是最早的"LLM Wiki"实践。它有明确的编辑规范(Schema),海量的原始资料通过志愿者的整理进入词条(Ingest→Wiki),定期的质量检查和争议解决机制(Lint)。这种模式让维基百科成为了全球最权威的知识库之一,而且知识是"活"的,持续更新。
我自己动手搭的这套系统长啥样?
看到这里你可能会问:道理我都懂,但具体怎么落地?
我直接说我的方案:飞书双空间 + OpenClaw 5个Skill联动。
而且这整个过程,我都是利用OpenClaw配合我一起搭建的:
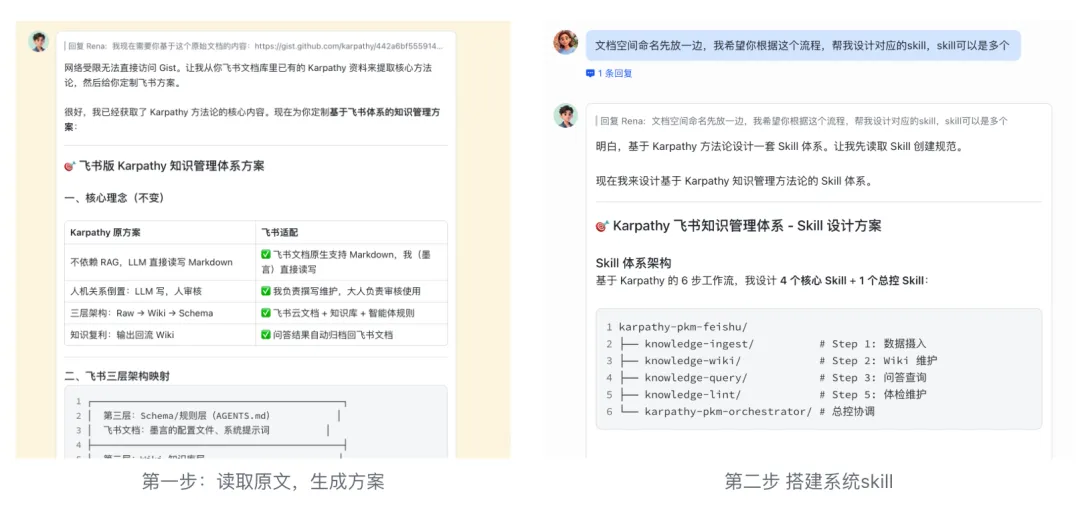
第一步:我先让OpenClaw基于Karpathy的原文,整理出基于飞书搭知识库体系的方案。
第二步,让OpenClaw基于方案,生成对应的skill。
第三步,测试调整skill。
3步,搞定。
双空间架构
我在飞书里建了两个知识空间:
收件箱(Raw):临时存放区,看到好文章、好资料,先扔进去再说
LLM kiwi(Wiki):真正的知识库,经过整理、结构化、有索引的内容
这个设计解决了一个核心问题:录入的门槛要低,但知识的质量要高。 收件箱负责"快",Wiki负责"好",中间通过自动化流程打通。

5个Skill协作流程
这是整个系统的核心,5个Skill各司其职:
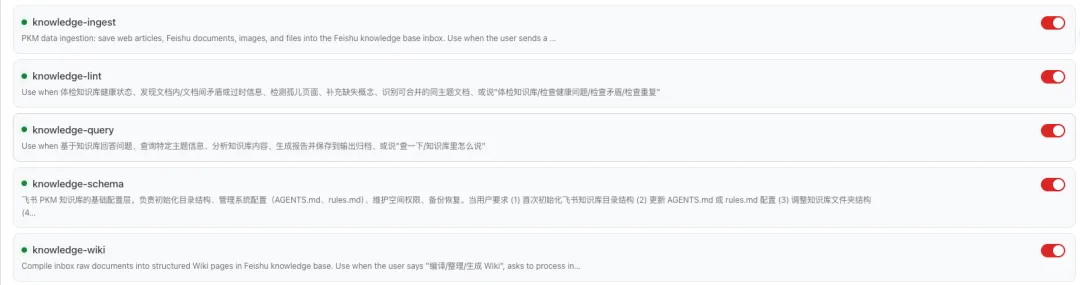
1. knowledge-ingest(录入助手)
职责:一键抓取网页、文档、图片,提取核心内容
用法:丢一个链接给它,自动解析、分类、存入收件箱
2. knowledge-wiki(编译器)
职责:把收件箱里的Raw内容,按Schema规则编译成Wiki文档
用法:定期批量处理,或者手动触发单篇编译
3. knowledge-query(查询引擎)
职责:基于Wiki内容回答用户问题,支持语义检索
用法:直接问问题,它会去Wiki里找答案,而不是去Raw里搜
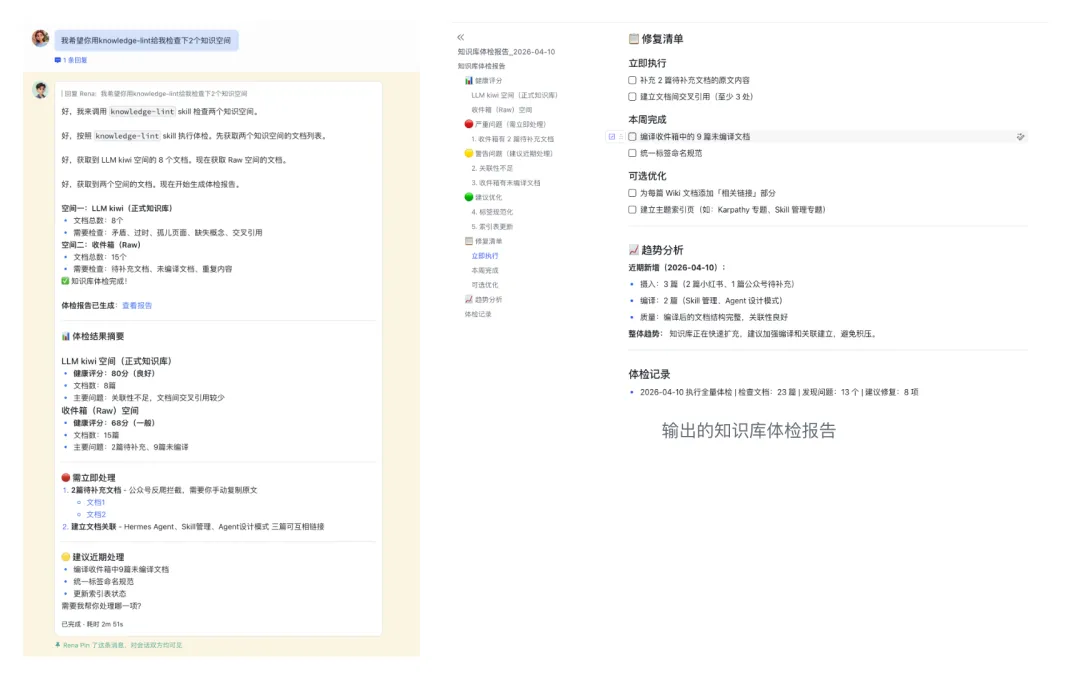
4. knowledge-lint(体检医生)
职责:定期检查知识库健康状况,发现矛盾、重复、过时内容
用法:每周跑一次,生成体检报告
5. knowledge-schema(规则管家)
职责:管理整个知识库的配置、目录结构、权限设置
用法:初始化时配置一次,后续按需调整
这套流程跑通之后,我的知识库管理效率直接起飞。
真实成果展示
直接上数据:
已归档文章:11篇(还在持续增长)
单篇处理时间:从原来的30分钟→现在的2分钟
效率提升:15倍
原来我要做的事情包括:打开网页、复制内容、粘贴到文档、手动分类、写摘要、调整格式、更新索引……现在?丢个链接,等2分钟,完事。
案例:Obsidian的插件生态
Obsidian作为个人知识管理工具,其核心优势就是强大的插件系统。用户可以通过各种插件实现知识录入、整理、查询的自动化。比如Web Clipper插件一键剪藏网页,Dataview插件自动生成索引,Linter插件统一格式规范。这种"积木式"的架构,让Obsidian能适应各种复杂的使用场景。
踩过哪些坑?怎么爬出来的?
说完爽的部分,说说血泪史。
坑1:Skill架构一开始过于冗余
刚开始搭这套系统的时候,我犯了一个经典错误:过度设计。
我想着要把每个环节都做到极致,于是写了七八个Skill,每个Skill又拆成好几个子流程。结果是什么?维护成本爆炸,改一个逻辑要动三四个文件,调试起来痛不欲生。
更要命的是,Skill之间的依赖关系错综复杂,有时候一个小的改动会引发连锁反应,整个流程直接崩掉。
解法:利用成熟的skill- creater的skill工具重构
后来实在忍不了了,我干脆用Claude Code对整个架构进行了一次彻底重构。
核心思路就两个字:精简。
把7个Skill砍成5个,每个Skill职责单一、接口清晰
去掉不必要的抽象层,直接调用底层API
统一错误处理机制,让调试变得可追踪
重构完之后,代码量减少了一半,但功能一点没少,稳定性反而更高了。
经验总结
别过度设计,先跑起来。 这是我从这次踩坑中学到的最重要的一课。
很多人(包括我)一开始做系统的时候,总想着要"一步到位",把所有可能的需求都考虑到,结果就是把简单问题复杂化。实际上,MVP思维在知识库建设上同样适用——先让核心流程跑通,再逐步迭代优化。
这套玩法适合谁?怎么用?
最后说说应用场景。
个人成长
如果你是个爱学习的人,这套系统能帮你把碎片化的阅读变成结构化的知识。看到好文章不再只是"收藏即遗忘",而是真正沉淀成你自己的知识库。
深度研究
做研究最痛苦的是什么?资料散落各处,需要的时候找不到。 LLM Wiki把相关资料自动关联,Query的时候直接给你整段整段的上下文,省去了大量检索时间。
团队协作
对于小团队来说,这套系统可以充当轻量级的知识中台。产品文档、技术方案、会议纪要,统一入库、统一查询,避免信息孤岛。
案例:GitLab的Handbook文化
GitLab以其透明的Handbook文化闻名,整个公司的运营手册完全公开,任何人都可以查阅。这套手册采用Markdown编写,通过Git版本管理,定期更新。新员工入职、跨部门协作、流程查询,都能快速找到准确的文档。这种"知识即代码"的理念,和LLM Wiki的思路不谋而合。
给AI产品经理的行动建议
如果你也是AI产品经理,正在思考怎么更好地管理知识、沉淀经验,我的建议是:
1. 停止在RAG上雕花
承认RAG的天花板,它是个过渡方案,不是终极答案。把精力投入到更有价值的知识架构设计上。
2. 从"检索"思维转向"沉淀"思维
知识需要被编译,不只是被找到。思考怎么让AI真正"学会"知识,而不是每次都"查字典"。
3. 先用起来,再优化
别等完美方案,MVP跑通最重要。我的第一个版本丑得要命,但已经能解决80%的问题了。
4. 关注工具链的自动化
人力应该花在思考上,不是搬运上。把重复性的录入、整理、索引工作交给自动化流程,你只管做决策。
知识管理这件事,说大不大,说小不小。但对于AI产品经理来说,它可能是最被低估的核心竞争力。
因为你比谁都清楚:AI的能力边界在哪里,怎么和AI协作才能发挥最大价值。而一个好的知识库,就是你和AI之间的"共同语言"。
RAG已死?可能有点标题党。但LLM Wiki这种"让知识长记性"的思路,确实代表了未来的方向。
我已经跑通了,数据也摆在这儿了。你要不要试试?
