夜雨聆风
夜雨聆风前言:为什么需要分层学习?
在B站看到一个up主分享了AI工程的路线非常不错,尝试处理一下AI工程的递进路径,目前业界的AI 技术栈已从单一的 LLM 演进为复杂的工程体系。
面对纷繁的技术名词——Agent、Skills、MCP、LoRA——很多学习者感到迷茫:该从哪里开始?学到什么程度?如何串联?
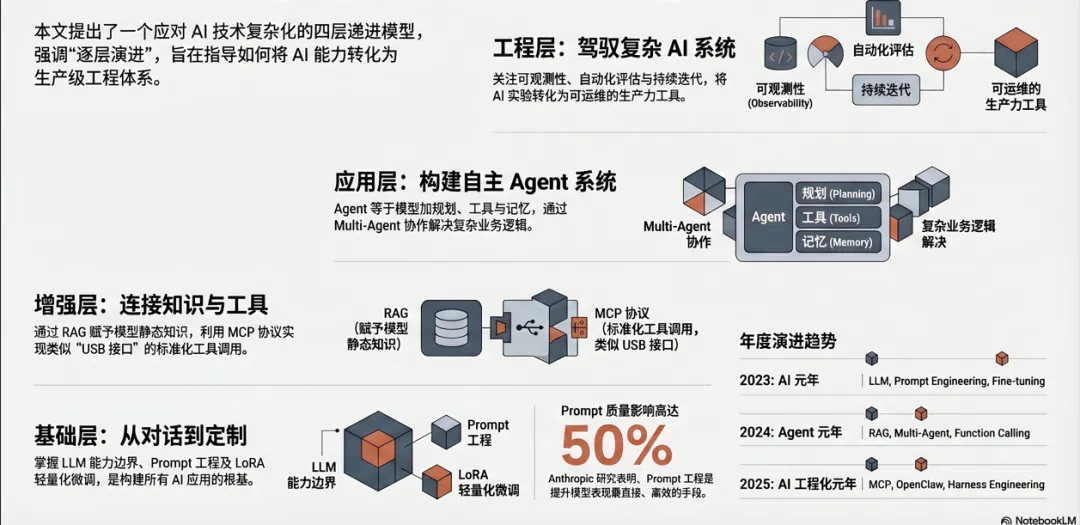
本文提出一个四层递进模型,帮助你建立清晰的认知框架:
工程层:OpenClaw → Harness Engineering(生产落地)
应用层:Agent → Multi-Agent → Context Engineering → Agent Skill(复杂系统)
增强层:RAG → Function Calling → MCP(能力扩展)
基础层:LLM → Prompt Engineering → Fine-tuning(核心基础)
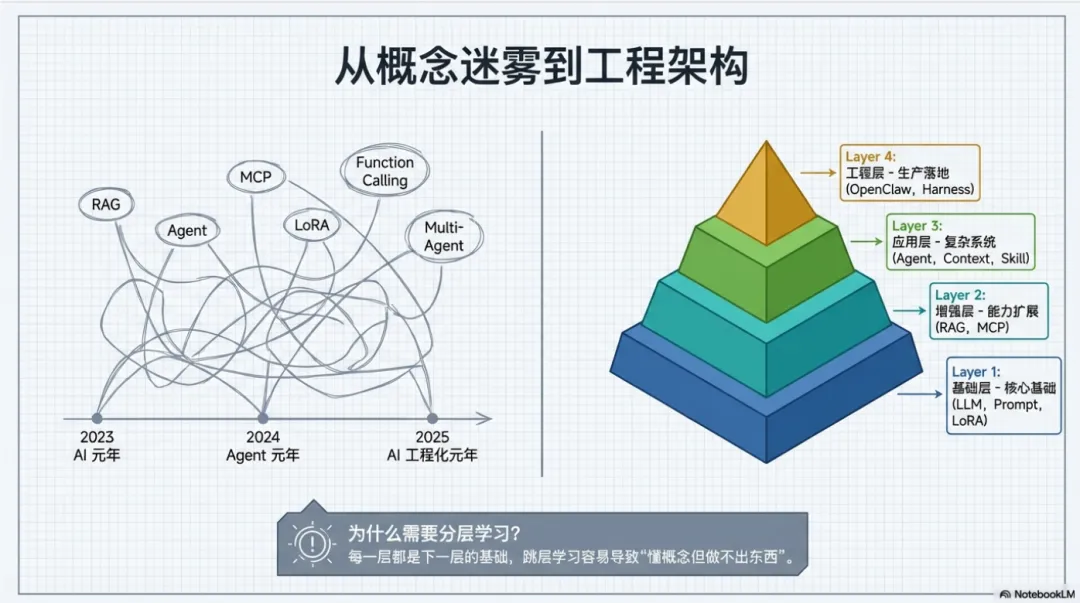
每一层都是下一层的基础,跳层学习容易"懂概念但做不出东西"。让我们逐层展开。
AI技术发展脉络:
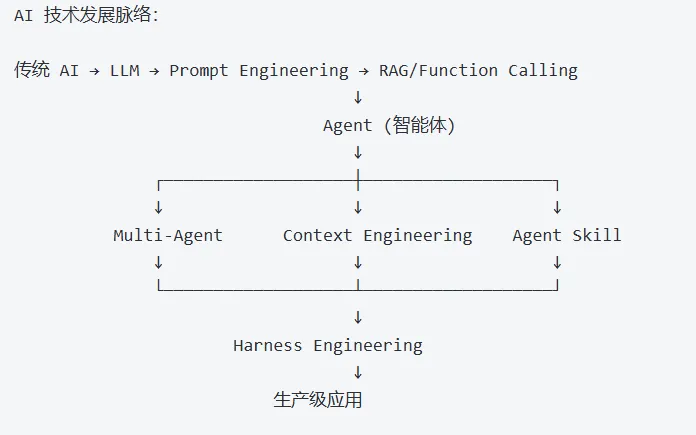
技术 | 一句话 |
LLM | AI 的大脑 |
Prompt Engineering | 教 AI 怎么听话 |
Fine-tuning | 培养 AI 的专业技能 |
RAG | 给 AI 配个知识库 |
Function Calling | 让 AI 能动手的工具 |
MCP | 工具的通用接口标准 |
Agent | 能自主思考行动的 AI |
Multi-Agent | 多个 AI 协作完成任务 |
Context Engineering | 给 AI 提供高质量信息 |
Agent Skill | 可复用的 AI 能力包 |
OpenClaw | 构建 AI 助手的工具箱 |
Harness Engineering | 让 AI 稳定可靠工作的工程方法 |
第一层:基础层
核心目标理解 LLM 的能力边界,掌握与模型高效沟通的方法,了解如何定制模型行为。
1.1 LLM:一切的基础
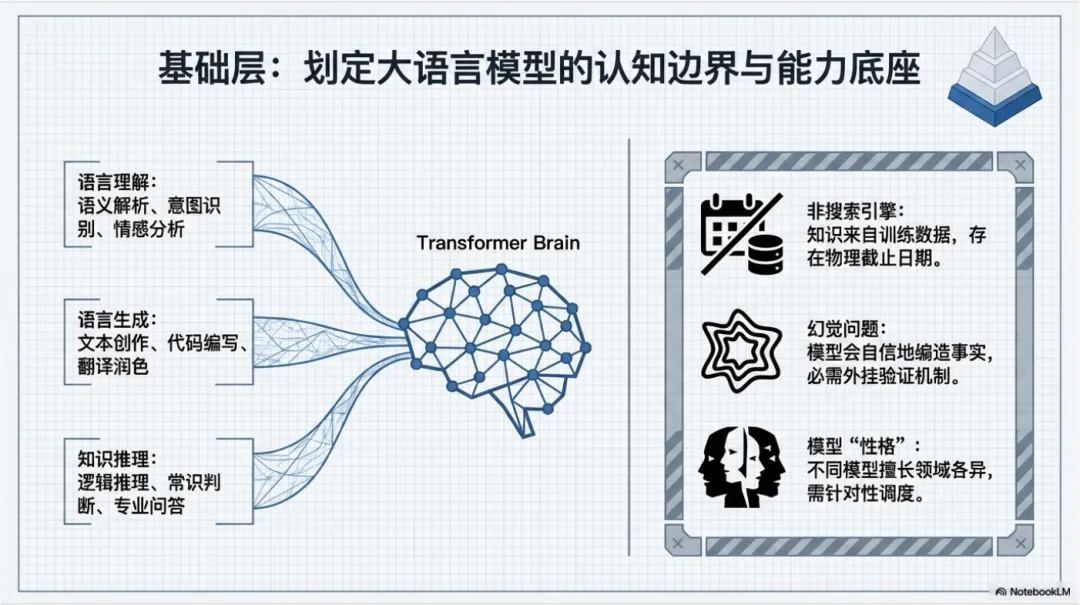
什么是大语言模型?
大语言模型(Large Language Model)是基于 Transformer 架构、通过海量文本数据训练的深度学习模型。它的核心能力包括:
语言理解:语义解析、意图识别、情感分析
语言生成:文本创作、代码编写、翻译润色
知识推理:逻辑推理、常识判断、专业问答
主流模型对比(2025年视角)
闭源商业:GPT-4o、Claude 4、Gemini 2 → 能力最强,API 稳定 → 适用于生产应用、复杂任务
开源旗舰:Llama 4、DeepSeek V3、Qwen 2.5 → 可本地部署,可定制 → 适用于私有化、成本敏感场景
轻量模型:Phi-4、Gemma 2、Qwen 2.5-7B → 资源占用低,速度快 → 适用于边缘设备、实时场景
学习建议
先用起来:注册主流 API,每天使用,建立对模型能力的直观感受
读论文:《Attention Is All You Need》是起点,理解 Transformer 架构
跑模型:用 Ollama 或 vLLM 在本地运行开源模型,理解推理过程
看源码:nanoGPT、llm.c 等项目用极简代码实现 GPT,适合学习
关键认知
LLM 不是"搜索引擎",它的知识来自训练数据,存在截止日期
LLM 有"幻觉"问题,会自信地编造事实,需要验证机制
不同模型有不同的"性格"和擅长领域,需要针对性使用
1.2 Prompt Engineering:与 AI 对话的艺术
为什么 Prompt 如此重要?
同样的模型,不同的 Prompt 可能产生天壤之别的效果。Prompt Engineering 就是设计高质量输入以获得高质量输出的技术。
Anthropic 的研究表明,Prompt 质量对模型表现的影响可达 30-50%。这是一项"低门槛、高天花板"的技能。
核心原则
清晰具体:模糊的指令得到模糊的结果
❌ "帮我写个爬虫"
✅ "用 Python 写一个爬虫,爬取豆瓣电影 Top250,保存为 CSV,包含电影名、评分、简介"
提供上下文:给模型足够的背景信息
角色设定:"你是一位有 10 年经验的后端架构师"
任务背景:"这是一个电商系统的订单模块"
输出格式:"以 Markdown 表格形式输出"
迭代优化:第一条 Prompt 很少完美,需要持续调优
常用技巧
Few-shot Learning(少样本学习)
给模型几个示例,让它理解你的期望格式。
Chain-of-Thought(思维链)
引导模型展示推理过程,提高复杂问题的准确率。
Role-playing(角色扮演)
设定专业角色,获得更专业的输出。
进阶技巧
Self-consistency:让模型生成多个答案,投票选择最佳
Tree of Thoughts:构建思维树,探索多个推理路径
Prompt Chaining:将复杂任务拆分为多个 Prompt 串联
1.3 Fine-tuning (LoRA):定制你的模型
为什么需要微调?
通用大模型虽然能力强,但在特定场景下存在局限:
领域知识不足:医疗、法律、金融等专业领域
风格不匹配:企业语调、个人写作风格
任务特定需求:特定格式的输出、特定流程的遵循
成本与隐私:减少对 API 的依赖,数据不出域
LoRA:高效的微调方案
LoRA(Low-Rank Adaptation)是一种参数高效微调技术,核心思想是:冻结预训练模型的权重,只在旁边添加小规模的可训练参数。
对比传统全量微调:
训练参数量:全量微调 100% vs LoRA 微调 0.1%-1%
显存需求:全量微调极高 vs LoRA 微调较低
训练时间:全量微调长 vs LoRA 微调短
模型文件:全量微调完整模型 vs LoRA 微调几十 MB 适配器
效果:全量微调最优 vs LoRA 微调接近最优
实操路径
准备数据:高质量指令数据集(100-10000 条)
选择基座模型:根据任务选择合适的开源模型
配置 LoRA 参数:rank、alpha、target_modules
训练与评估:使用 LLaMA-Factory、Axolotl 等工具
合并与部署:将 LoRA 权重合并到基座模型
第二层:增强层
核心目标让 LLM 突破自身限制,获得外部知识、调用外部工具、连接外部系统。
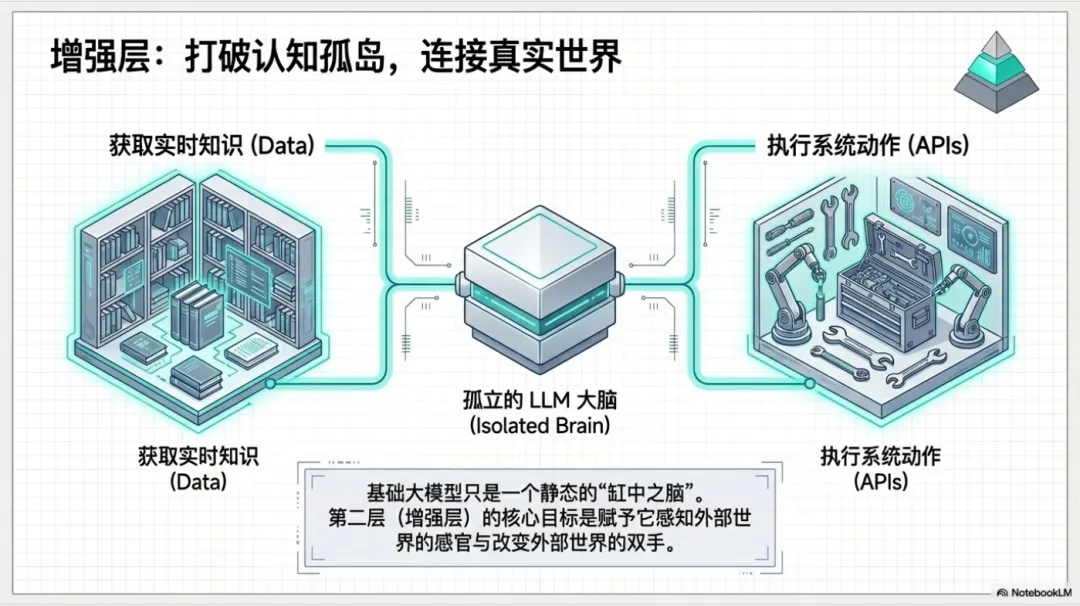
2.1 RAG:让模型拥有知识
RAG 是什么?
RAG(Retrieval-Augmented Generation,检索增强生成)的核心思想是:在生成回答前,先从知识库检索相关文档,将检索结果作为上下文提供给 LLM。
这就像是开卷考试——不用背诵所有知识,但能在需要时查到。
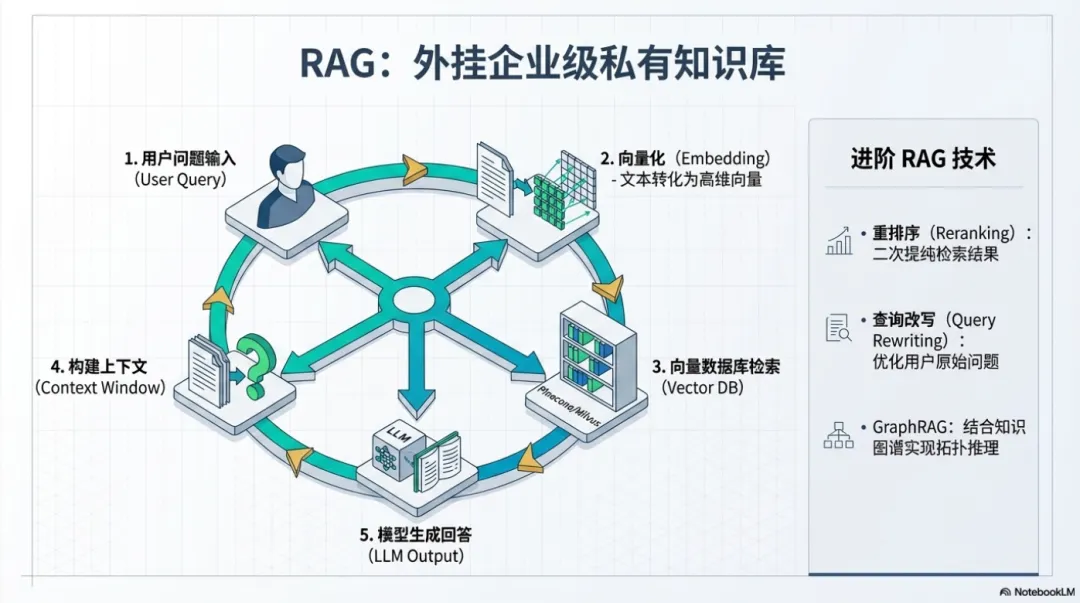
RAG 的核心流程
用户问题 → 向量化 → 检索相似文档 → 构建上下文 → LLM 生成回答
关键组件
文档处理:文档解析、文本分块、元数据提取
向量化(Embedding):将文本转换为高维向量表示
向量数据库:Pinecone、Milvus、Weaviate、Chroma、Qdrant
检索策略:稠密检索、稀疏检索、混合检索
进阶技术
重排序(Reranking):对检索结果进行二次排序
查询改写(Query Rewriting):优化用户问题
多轮检索(Multi-hop RAG):针对复杂问题进行多轮检索
GraphRAG:结合知识图谱,实现结构化知识检索
2.2 Function Calling:连接外部世界
Function Calling 是什么?
Function Calling 让 LLM 能够调用外部函数/API,实现与真实世界的交互:
查询天气、股票、航班
操作数据库、文件系统
发送邮件、消息通知
执行计算、数据处理
与 RAG 的互补关系
RAG:让模型"知道"更多信息(静态知识)
Function Calling:让模型"做到"更多事情(动态操作)
2.3 MCP:标准化的工具协议
MCP 是什么?
MCP(Model Context Protocol)是由 Anthropic 在 2024 年底推出的开放协议,旨在标准化 LLM 应用与外部数据源、工具之间的连接。
可以理解为"AI 时代的 USB 接口"——统一标准,即插即用。
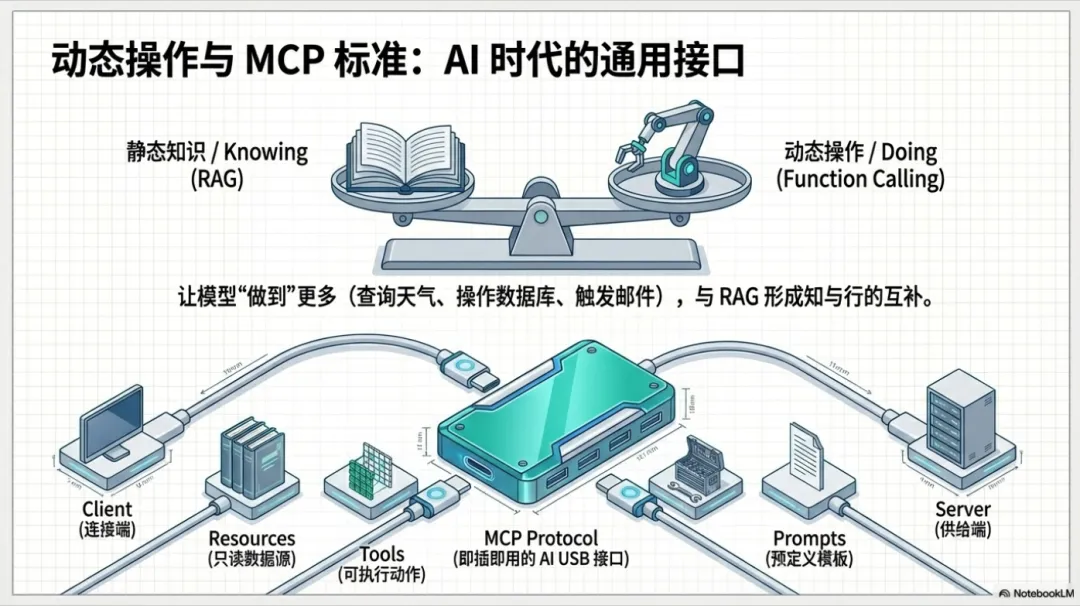
MCP 的核心概念
MCP Server:提供资源、工具、Prompt 的服务器
MCP Client:连接 MCP Server 的客户端
Resources:只读数据源
Tools:可执行操作
Prompts:预定义的 Prompt 模板
第三层:应用层
核心目标构建能够自主完成复杂任务的智能体系统。
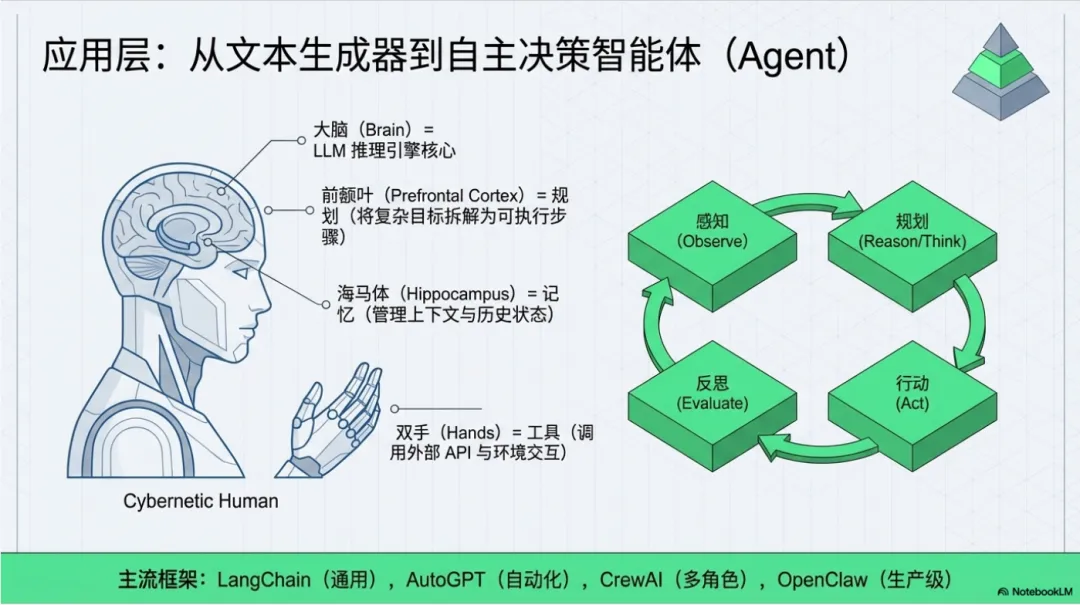
3.1 Agent:自主决策的 AI
什么是 Agent?
如果说 LLM 是"大脑",那么 Agent 就是"完整的人":
Agent = LLM + 规划 + 工具 + 记忆
Agent 的核心能力:
感知:理解环境和任务
规划:分解复杂目标为可执行步骤
行动:调用工具完成任务
反思:评估结果,调整策略
经典框架:ReAct
ReAct(Reasoning + Acting)是最具影响力的 Agent 设计模式,通过"思考-行动-观察"的循环完成任务。
主流 Agent 框架
LangChain:生态丰富,组件完善 → 通用 Agent 开发
AutoGPT:自主性强 → 自动化任务
CrewAI:多角色协作 → 复杂工作流
OpenClaw:工程化友好 → 生产级 Agent
3.2 Multi-Agent:协作的力量
为什么需要 Multi-Agent?
单个 Agent 的能力有限,面对复杂任务时存在认知负荷过重、专业能力不足等问题。Multi-Agent 系统通过分工协作解决这些问题。
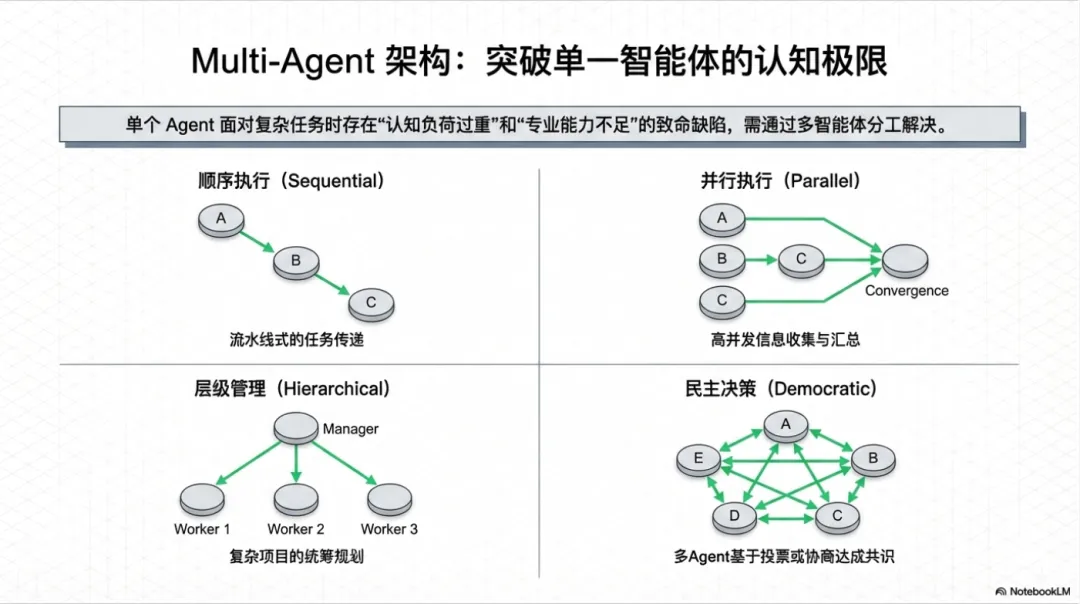
常见架构模式
顺序执行:A → B → C → D
并行执行:A、B、C 同时工作,最后汇总
层级管理:Manager Agent 协调多个 Worker Agent
民主决策:多个 Agent 投票/协商
3.3 Context Engineering:上下文管理
为什么上下文是核心挑战?
LLM 的上下文窗口有限,但实际应用中需要处理长文档、长对话、多轮任务、多 Agent 协作等场景。
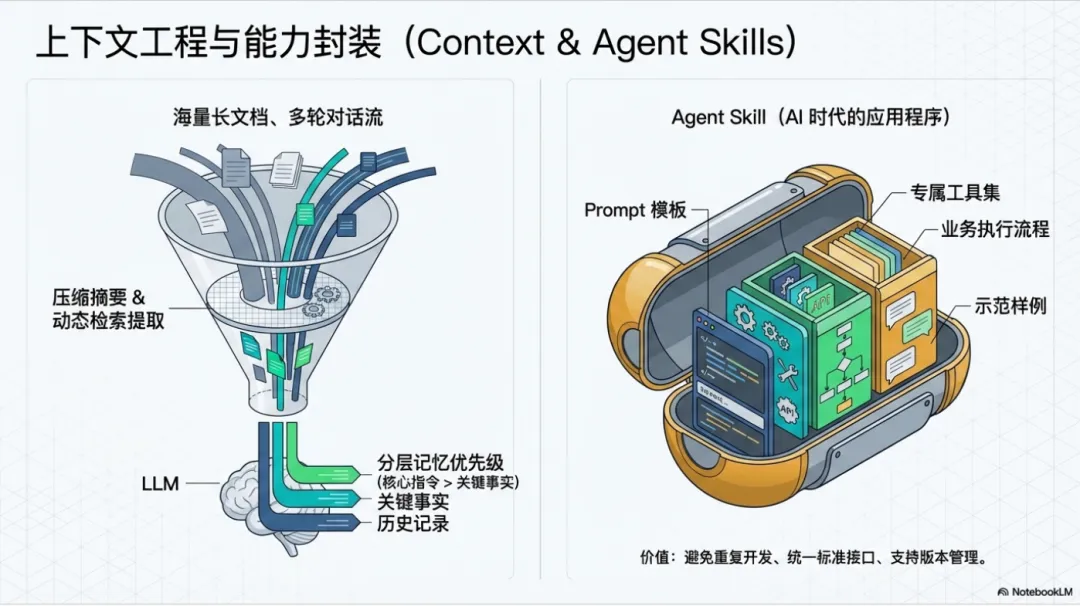
上下文管理的核心策略
压缩与摘要:对话历史定期摘要
分层记忆:工作记忆、短期记忆、长期记忆
动态检索:按需检索相关信息
上下文优先级:核心指令 > 关键事实 > 历史记录
3.4 Agent Skill:能力复用
什么是 Skill?
Skill 是可复用的能力模块,封装了特定领域的知识和工具调用:
Skill = Prompt 模板 + 工具集 + 执行流程 + 示例
类比:
LLM 是操作系统
Tool 是系统调用
Skill 是应用程序
为什么要封装 Skill?
复用:避免重复开发
标准化:统一接口和行为
可维护:独立更新、版本管理
可分享:社区贡献和传播
第四层:工程层
核心目标将 AI 能力转化为可落地、可运维、可扩展的产品。
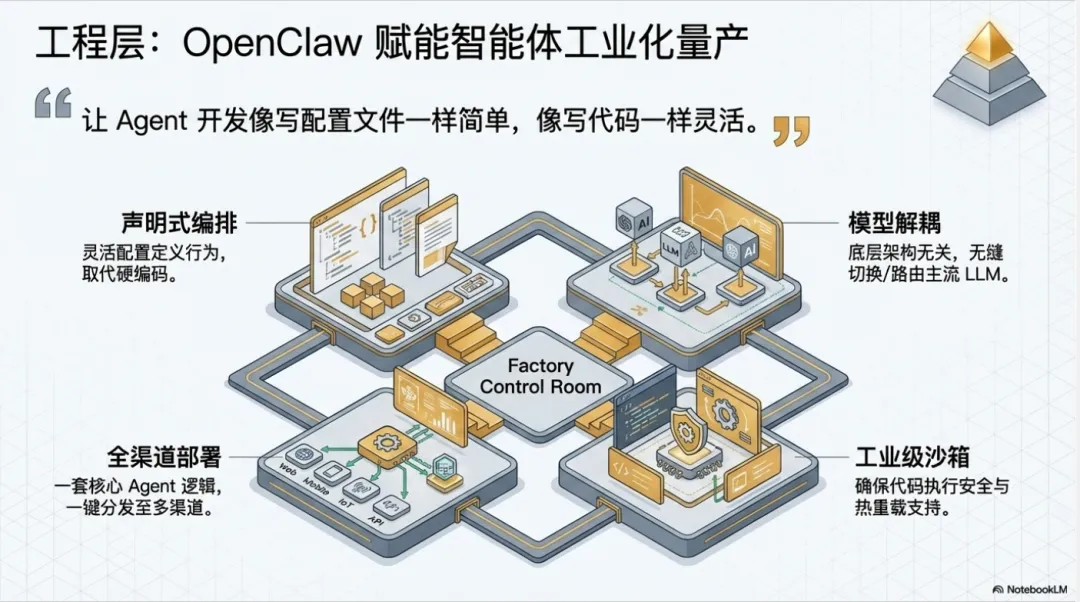
4.1 OpenClaw:Agent 工程化平台
OpenClaw 是什么?
OpenClaw 是一个开源的 Agent 工程化平台,定位是:让 Agent 开发像写配置文件一样简单,像写代码一样灵活。
核心能力
多渠道接入:一套 Agent 逻辑,多渠道部署
灵活的编排:声明式配置定义 Agent 行为
模型无关:支持主流 LLM
工程能力:可观测性、热重载、安全沙箱
4.2 Harness Engineering:驾驭复杂系统
什么是 Harness Engineering?
Harness Engineering 是对AI 系统工程化能力的总称,包括:
如何监控 AI 系统的运行状态
如何调试 AI 系统的异常行为
如何评估 AI 系统的效果质量
如何迭代优化 AI 系统
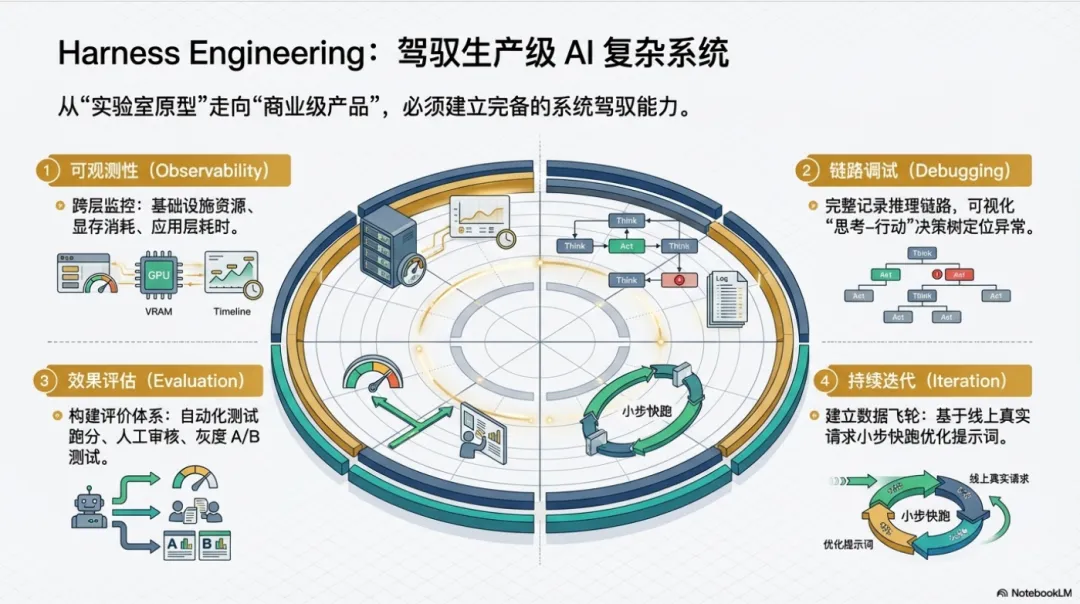
核心维度
可观测性(Observability):基础设施层、模型层、应用层、业务层监控
调试能力(Debugging):记录推理链路、可视化决策过程
评估体系(Evaluation):自动化评估、人工评估、A/B 测试
持续迭代(Iteration):数据驱动,小步快跑