 夜雨聆风
夜雨聆风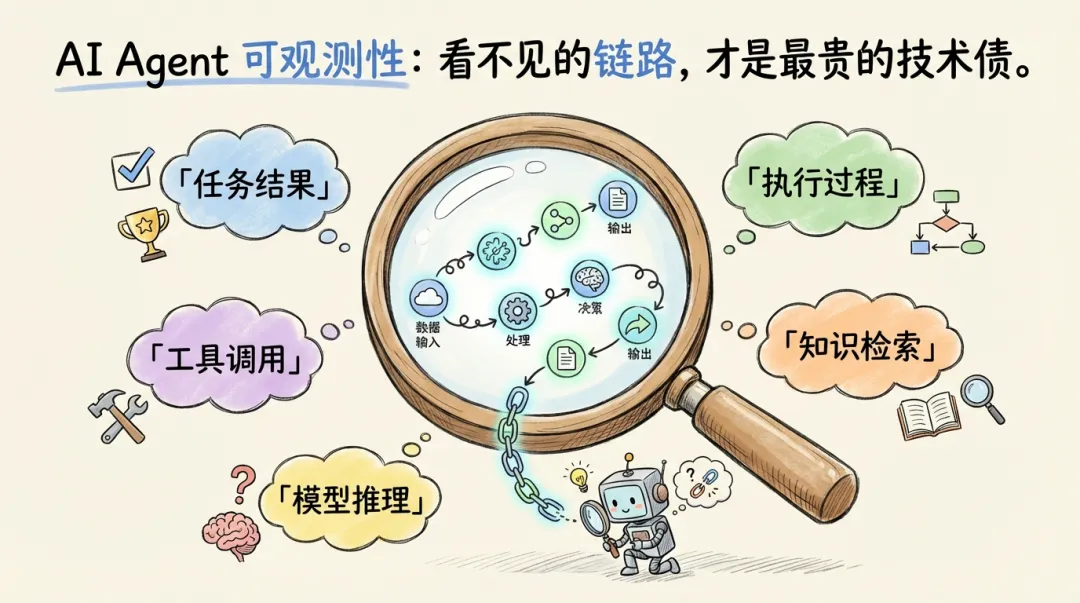
写在前面
很多团队在做 AI Agent 时都有一个共同体验:反复换模型、堆提示词、调参数,但效果始终不稳定。
核心问题往往不在模型本身,而在于——你看不见 Agent 是怎么完成任务的。
看不见,就没法诊断;没法诊断,就只能靠猜;靠猜,就容易陷入"感觉快成了"的循环。
这篇文章聊三个实在的问题:
1. Agent 的可观测性到底该看什么 2. 行业标准和真实工程实践是怎么做的 3. 一个团队该从哪里开始建
一、你的 Agent 是不是也有这些症状
Agent 项目最危险的状态不是"完全不能用",而是"有时很好用,有时很离谱"。这种不稳定最难处理,因为它会制造一种幻觉:好像再调一点就好了。
几个典型症状:
• 任务完成率忽高忽低,找不到规律 • 同一类任务,昨天能做今天又不行 • 复杂任务经常在中间某步卡住或跑偏 • 成本越来越高,但效果没有同步提升 • 出了问题,团队的第一反应是"再改改提示词"
如果这些症状你很熟,接下来的内容值得细看。
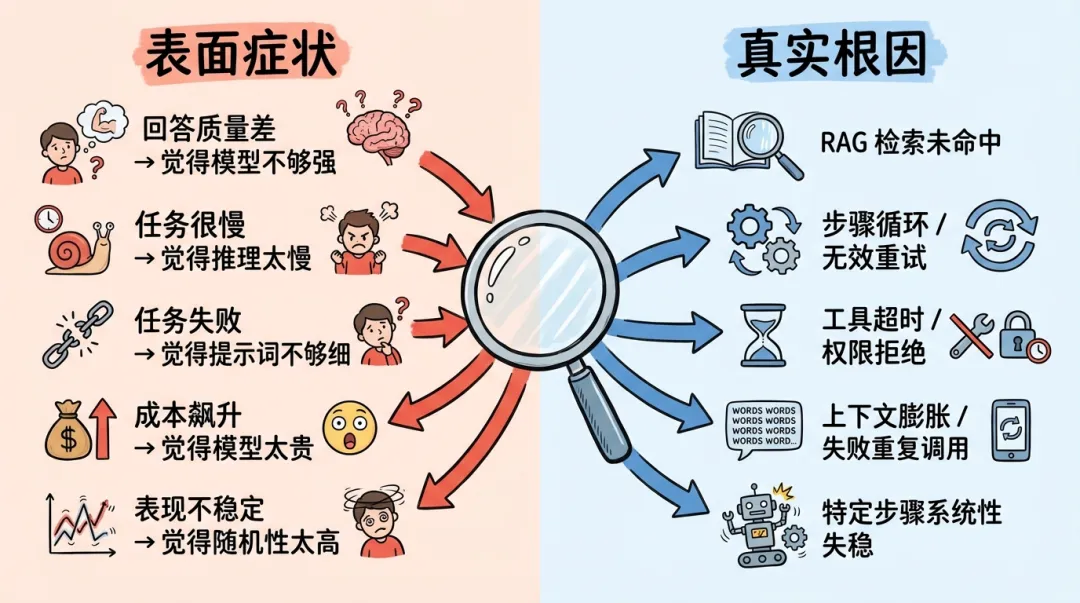
1.1 表面问题 ≠ 真实根因
先看一张在团队里反复出现的误判对照表。
这张表的重点不是"把锅甩给别处"。重点是:同一个表面问题,背后的根因可能完全不同。不先定位到真实原因,后面的优化大概率是在浪费时间。
1.2 四个常见的"条件反射"
Agent 项目里最常见的错误动作:
• 完成率不高 → 换更强的模型 • 输出不稳 → 继续堆提示词 • 成本高了 → 压缩调用次数 • 失败多了 → 增加重试逻辑
这些动作在局部场景下可能有效,但它们有一个共同的前提假设:你已经知道问题发生在哪里。
事实是,大部分团队连最基础的判断能力都还没有——分不清是模型问题还是工具问题,分不清是逻辑错误还是环境约束,分不清是 RAG 没检索到还是 LLM 推理偏了。
在不知道原因的情况下继续改参数,不是优化,是碰运气。
二、Agent 可观测性到底该看什么
讨论 Agent 可观测性时,常见一种按"层"划分的思路——任务结果层、执行过程层、模型调用层、工具执行层、宿主环境层。方向没错,但在实际工程落地中会遇到几个问题:
1. 缺了一个关键层:RAG / 知识检索。大量 Agent 输出质量差,根因不在模型推理,而在输入给模型的上下文就是错的——检索没命中、召回质量差、知识库过期。这一层不单独观测,很多问题永远找不到根因。Arize AI 在 2024 年的 LLM Observability 报告中也指出,RAG 质量是生产环境中最常被低估的故障源。 2. 宿主环境不该独立成层:CPU、内存、网络这些是基础设施监控的范畴,Datadog、Prometheus 等传统运维工具已经覆盖得很好。把它混进 Agent 可观测性讨论,反而模糊了重点。 3. 缺少 SLO 驱动的思维:列了一堆指标,但没有回答"什么情况算正常,什么情况该告警"。Google SRE 的核心原则之一是:没有 SLO,监控只是在"看数字",不是在"做决策"。
2.1 更贴近工程实际的观测模型
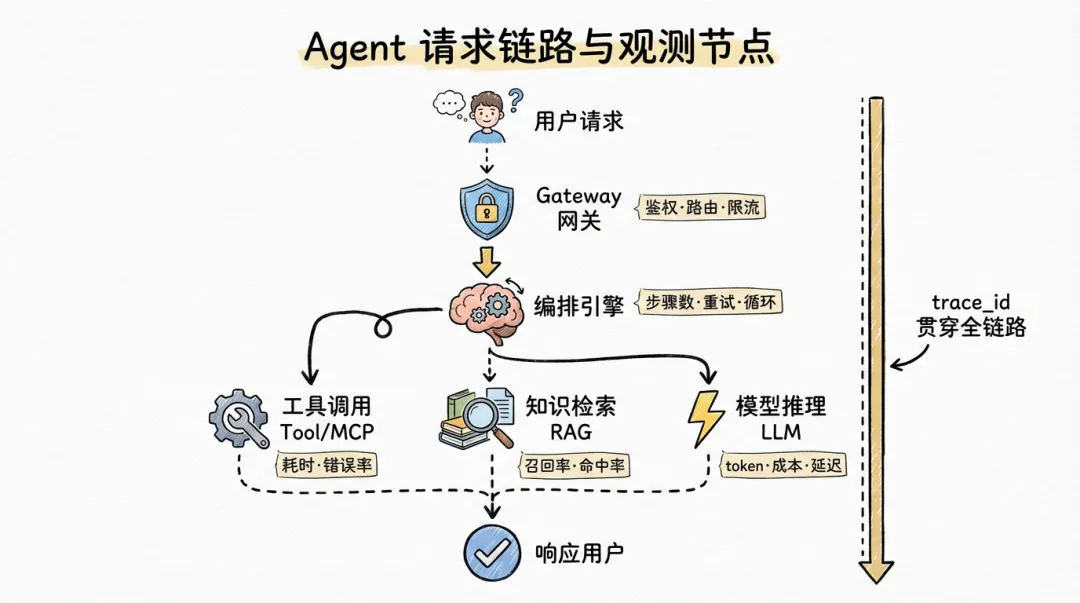
结合实际的 Agent 架构(Gateway → Engine → Tool/MCP → RAG → LLM),真正需要观测的是一条完整的请求链路,而不是孤立的"层"。
一个更实用的拆法,是沿着 Agent 处理一次任务的链路,在关键节点埋观测点:
用户请求 → Gateway(鉴权/路由/限流) → Engine(Agent 编排/规划/推理) → Tool/MCP 调用(外部工具执行) → RAG 检索(知识检索/向量匹配) → LLM 调用(模型推理) → 结果聚合 → 响应用户每个节点需要回答的问题不同:
| 任务/会话 | ||
| Agent 编排 | ||
| 工具/MCP | ||
| RAG 检索 | ||
| LLM 调用 |
这不是把"五层"硬改成"五个节点"——这是从链路追踪的视角重新组织观测,让每个数据点都能串在同一条 Trace 上,支持从结果到根因的逐层下钻。
2.2 为什么 RAG 层必须单独看
这一点值得展开讲,因为它是很多团队长期忽略的盲区。
一个典型场景:用户问了一个运维知识问题,Agent 回答得驴唇不对马嘴。团队第一反应是"模型不够强"或"提示词不够好"。
但如果你能看到 RAG 检索的中间结果,很可能会发现:
• 检索压根就没命中正确的文档片段 • 命中了,但召回排序不对,正确答案排在第 5 条,而只取了 Top 3 • 命中了正确文档,但文档本身已经过期
这些问题,换再贵的模型也解决不了。没有对 RAG 层的独立观测,你会一直在"调提示词 → 没效果 → 再调 → 还是没效果"的循环里。
具体需要观测的 RAG 信号:
• 检索输入:用户 query 经过何种改写 • 召回结果:返回了哪些文档片段、相似度得分分布 • 重排结果:rerank 后的排序变化 • 引用片段:最终送给 LLM 的上下文是什么
有了这些数据,你才能判断:是检索策略要调,还是知识库要更新,还是 rerank 模型要换。
三、行业标准:OpenTelemetry + LLM 可观测性工具
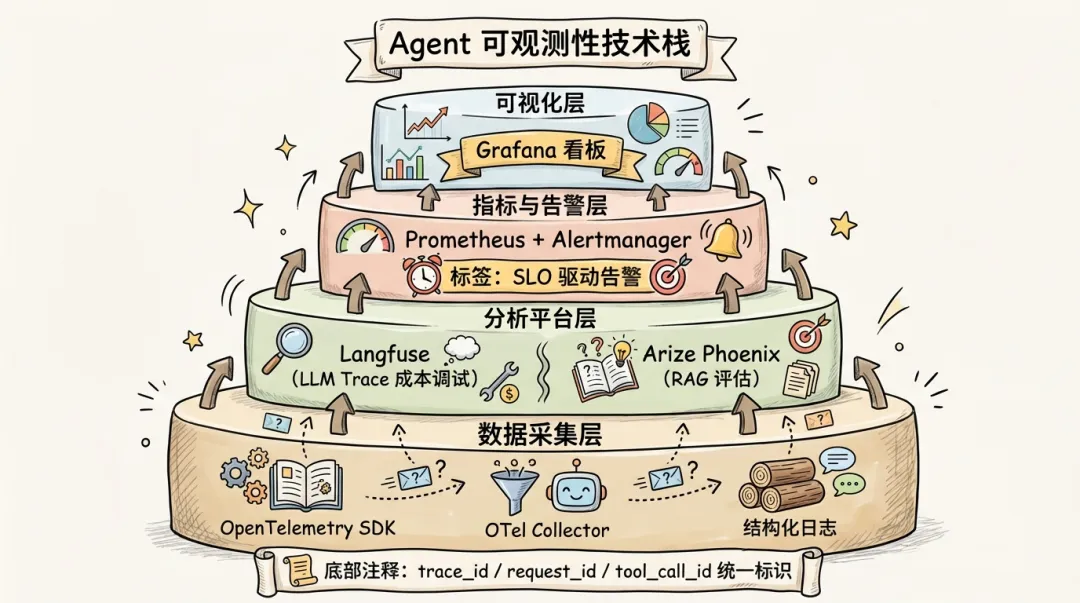
Agent 可观测性不是从零发明的——它建立在可观测性领域已经成熟的工程实践之上。
3.1 可观测性三支柱
任何严肃的可观测性方案,都围绕三个数据类型构建:
• Metrics(指标):聚合数值,回答"系统整体健康吗"——请求量、成功率、延迟分位数、成本 • Logs(日志):结构化事件记录,回答"具体发生了什么"——错误详情、工具返回值、审计记录 • Traces(链路追踪):跨组件的调用链,回答"一次请求是怎么走完的"——从 Gateway 到 LLM 的全链路
很多团队在做 Agent 观测时,只关注了"事件"这个笼统的概念,没有区分这三种数据类型各自的用途和关系。这会导致落地时数据混在一起,该聚合的没聚合,该详查的查不到。Honeycomb 的创始人 Charity Majors 有一个经典观点:可观测性不是三个工具的简单拼凑,而是三种数据视角的协同。Agent 场景下尤其如此。
3.2 OpenTelemetry:Agent 链路追踪的事实标准
OpenTelemetry(OTel) 是 CNCF 的开源可观测性标准,已经成为行业事实标准。它提供了统一的 SDK、数据模型和 Collector 架构,覆盖 Metrics / Logs / Traces 三个支柱。目前 OTel 已经是 CNCF 中仅次于 Kubernetes 的第二活跃项目,Microsoft、Google、AWS、Datadog 等主要云厂商和观测平台都已原生支持。
对 Agent 来说,OTel 最大的价值是:用一个 trace_id 把整条链路串起来。
一次用户请求的 Span 层级大致如下:
gateway.request(入口 span)├── engine.run(Agent 编排 span)│ ├── rag.search(向量检索 span)│ ├── llm.call(模型调用 span)│ ├── mcp.call(工具调用 span #1)│ ├── llm.call(模型调用 span #2)│ └── mcp.call(工具调用 span #2)└── response(响应 span)每个 Span 上需要打的关键属性:
gateway.request | request_iduser_id, tenant_id, 状态码 |
engine.run | conversation_id |
mcp.call | systemtool_name, timeout, retry_count, result_status |
rag.search | |
llm.call | modelprovider, input_tokens, output_tokens, finish_reason |
有了这条链路,出问题时的排查路径就是:先看 Trace 总览 → 找到耗时最长或失败的 Span → 下钻看详情。不需要猜,不需要人工复现。
3.3 多轮会话:被忽略的追踪维度
单轮请求的 Trace 相对直观。但 Agent 真正复杂的地方在于多轮会话——用户和 Agent 持续交互,上下文在不断累积。
多轮会话带来两个追踪层面的特殊挑战:
1. 上下文窗口膨胀:随着对话轮次增加,送给 LLM 的上下文越来越长。token 成本线性增长,但大部分团队在单轮 Trace 里看不到这个趋势。你需要用 conversation_id把同一会话的多条 Trace 串起来,观察 token 消耗随轮次的变化曲线。2. 跨轮次依赖关系:第 3 轮的失败,可能根因在第 1 轮的工具调用结果被错误缓存。如果每条 Trace 都是孤立的,这种跨轮次因果关系根本看不出来。
解决方式也不复杂:
• 在所有 Span 上打 conversation_id,作为多轮聚合键• 在 Langfuse 中按 conversation_id查看完整会话轨迹和成本趋势• 对多轮会话设置独立的上下文膨胀告警:当单次会话的累计 token 超过阈值时触发
Anthropic 在 Claude 的运营实践中就大量使用了 session-level 的指标聚合,而不仅仅是单次 request-level 的监控。
3.3 LLM 可观测性工具
除了 OTel 这个基础层,Agent 还需要专门的 LLM 可观测性工具来解决两个 OTel 不擅长的问题:
| LLM Trace 与成本管理 | ||
| RAG 调试与评估 |
这两类工具与 OTel 不是替代关系,而是互补:OTel 负责跨组件链路串联,LLM 工具负责 AI 特有的深度分析。它们通过共享 trace_id / request_id 实现互相跳转。值得一提的是,Langfuse 在 2024 年已获得 Y Combinator 投资并被 LangChain 官方文档推荐为首选 LLM 观测方案,Arize Phoenix 则被 LlamaIndex 和 Haystack 社区广泛采用。
一个推荐的组合方案:
四、指标不是越多越好,关键是能驱动决策
一个常见的误区是:做可观测性就是罗列尽可能多的指标。但真正的问题是——什么数值算正常?什么数值该告警?
没有这个标准,监控就是"看了个寂寞"。
4.1 SLO 驱动:先定义"什么算好"
SLO(Service Level Objective)不是运维团队的专利。对 Agent 来说,SLO 要回答的问题很直接:
• 任务成功率应该 ≥ 多少? • 端到端延迟 P99 应该 ≤ 多少? • 单次工具调用超时率应该 < 多少? • 单任务平均成本应该 ≤ 多少?
有了 SLO,告警才有依据。否则你只是每天看一堆数字,看完了也不知道该不该紧张。
Google SRE 的经验很简单:以 SLO 违约为告警标准,不是以"指标变化"为告警标准。成功率下降 0.5% 但还在 SLO 范围内,不需要半夜叫人起来。这个原则在《Site Reliability Engineering》(O'Reilly) 中有系统阐述,Netflix、LinkedIn 等公司也在各自的 SRE 实践中验证了其有效性。
4.2 四组核心指标
指标不需要一上来就搞几十个。先盯住这四组,每组都能直接驱动一个决策:
第一组:结果指标 —— Agent 到底有没有在创造价值
第二组:过程指标 —— 问题到底集中发生在哪
第三组:成本指标 —— 钱到底花在了哪里
第四组:质量指标 —— RAG 和模型表现如何
4.3 告警原则
两条原则就够了:
1. 以 SLO 违约为主:成功率跌破阈值、P99 恶化超过上限、成本突破预算 2. 以依赖隔离为辅:单一 MCP 系统异常单独告警,不要因为一个工具挂了就把整个 Agent 标红
五、不同类型的 Agent,观测策略完全不同
这是一个务实的问题:你能看到多少,取决于你控制多少。不同的 Agent 部署形态决定了你的观测策略和投入重点。
| 代表产品 | |||
| 可见性范围 | |||
| 核心策略 | |||
| 推荐工具 | |||
| 投入优先级 |
云端黑盒 Agent(SaaS 产品)
你最多能拿到:任务状态、用量统计、成本额度。拿不到内部步骤、工具细节、模型调用明细。
正确策略:不追求全链路透明,聚焦结果监控 + 成本监控 + 用户满意度反馈。这已经足够你做 80% 的决策了。OpenAI 的 Usage Dashboard 和 Anthropic 的 Admin Console 提供的就是这个层级的可见性,对大部分企业用户来说够用。
本地/桌面 Agent(Cursor、Claude Desktop、GitHub Copilot 等)
能拿到更多:步骤级事件、工具调用明细、文件操作、权限请求。Cursor 的 Activity Log、GitHub Copilot 的 Telemetry 都提供了比 SaaS 更细粒度的观测窗口。
看起来更"难管",但长期反而更容易优化。因为至少能被看清——你可以统计哪些工具调用最耗时、哪类操作失败率最高,从而有针对性地优化工作流。
自建 Agent
上限最高。你可以统一控制事件模型、追踪标识、工具网关、模型代理。
这也是 LangChain、AutoGen、CrewAI 等主流 Agent 框架都在积极集成 OpenTelemetry 和 Langfuse 的原因——框架层面内置了可观测性钩子,减少了自建团队的接入成本。做得好的团队,领先点往往不在模型选型,而在于更完善的可观测性和治理能力。
六、一个可落地的排查流程
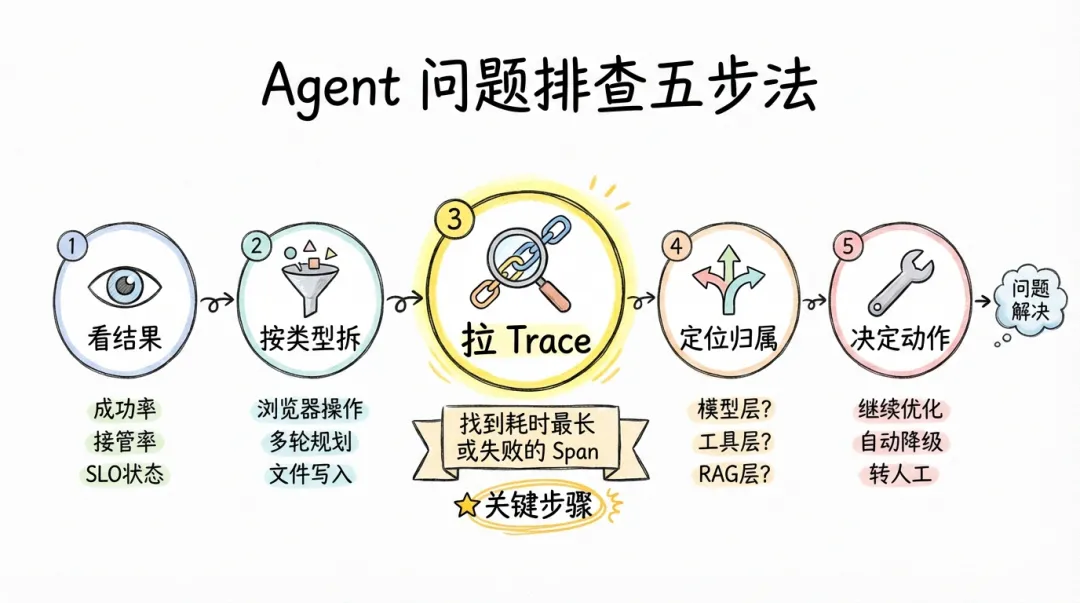
出问题时别急着改参数。按这个顺序来:
第一步:先看结果。 成功率是否稳定?人工接管是否上升?先确认 Agent 在 SLO 范围内还是外。
第二步:按任务类型拆分。 很多时候不是整体不行,而是某类任务明显不行。比如需要浏览器操作的任务差、需要多轮规划的任务慢、需要文件写入的任务容易失败。不按类型拆,会误以为整个 Agent 都有问题。
第三步:拉出失败任务的 Trace。 这是最关键的一步。打开一条失败任务的完整 Trace,看它从 Gateway 到 LLM 到工具每一步的耗时和状态。通常很快就能定位到:是工具超时了?是 RAG 没检索到?还是 LLM 拒答了?
第四步:用下面这张表快速定位根因归属。
第五步:决定动作。 定位到根因后,只有三种决策路径:继续优化自动执行、在特定场景自动降级、或者明确转人工。没有前面四步的判断,任何动作都是在碰运气。
七、建设路径:从看得见到管得住
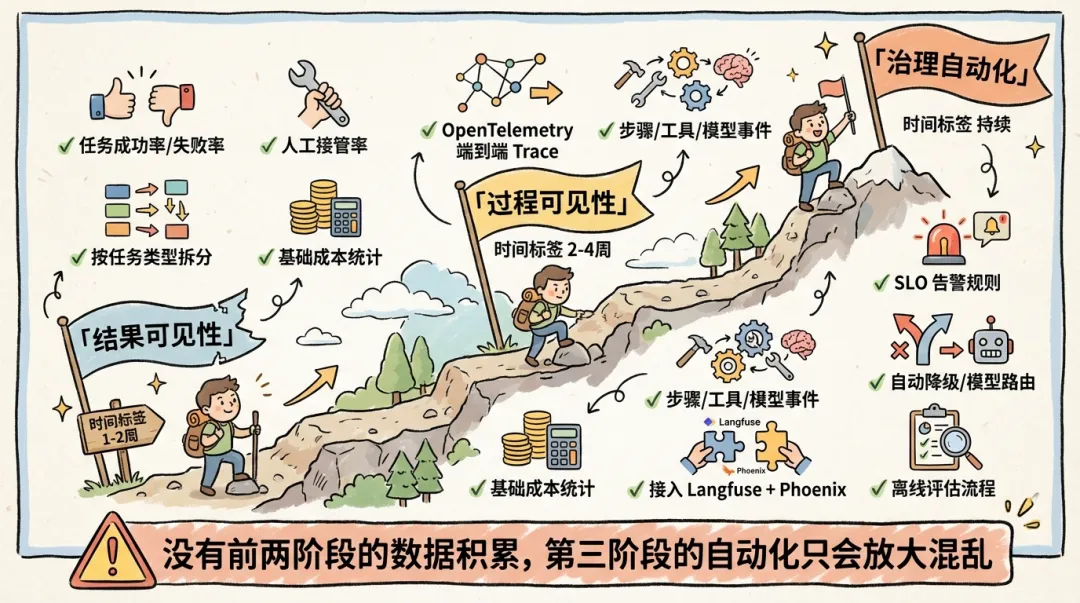
别一上来追求大而全的监控平台。更现实的路径是分三步走。
阶段一:结果可见性(1-2 周)
目标:回答"Agent 到底有没有用"。
• 采集任务级事件: task_started/task_finished/task_failed• 看清成功率、失败率、人工接管率 • 按任务类型拆分,找到最差的那类 • 建立基础的成本统计
最小字段集:trace_id, task_id, event_type, status, duration_ms, error_type
阶段二:过程可见性(2-4 周)
目标:回答"问题到底出在哪一步"。
• 接入 OpenTelemetry,建立端到端 Trace • 补齐步骤级事件: step_started/step_failed• 补齐工具事件: tool_called/tool_failed(含system,tool_name,result_status)• 补齐模型事件: llm_request/llm_response(含model,tokens,finish_reason)• 接入 Langfuse,看清 token 成本分布 • 如有 RAG,接入 Arize Phoenix,建立检索质量基线
到这一步,团队具备了"从结果定位到根因"的能力,可以开始做有针对性的优化。
阶段三:治理自动化(持续)
目标:从"人看数据做决策"走向"系统自动响应"。
• 定义 SLO,配置告警规则 • 实现自动降级:特定工具持续失败时自动切换备选路径 • 实现模型路由:按任务复杂度自动选择模型(简单任务用小模型降本,复杂任务用强模型保质量) • 实现自动转人工:识别 Agent 能力边界,超出时及时交给人 • 建立离线评估流程:定期用 Phoenix 跑 RAG 质量回归测试
重要提醒:没有前两个阶段的数据积累,第三阶段的自动化只会放大混乱。 自动降级需要知道"什么时候该降级",模型路由需要知道"什么任务用什么模型效果好"——这些判断都依赖前两个阶段建立的数据基线。
八、真正危险的不是失败,而是"长期不知道为什么失败"
Agent 是复合系统,失败很正常。
真正危险的是这些状态长期持续:
• 失败越来越多,但团队不知道集中在哪类任务 • 成本越来越高,但团队不知道 token 浪费在哪一步 • 用户觉得不好用,但团队的唯一手段是改提示词 • 每次排障都靠人手动复现,而不是打开一条 Trace
一旦进入这种状态,技术团队越来越疲惫,业务团队越来越不信任。很多 Agent 项目不是死在模型能力不够,而是死在"不可解释、不可运营、不可治理"。
Anthropic 的 CEO Dario Amodei 在多次公开场合都强调过:Agent 系统的安全性和可靠性依赖于可解释性和可观测性。Google DeepMind 在其 Agent Safety 白皮书中也将"行为可审计性"列为 Agent 上生产的前置条件之一。这不是某个团队的内部偏好——而是行业正在形成的共识。
写在最后
真正的分水岭不是"有没有 Agent",而是:
有没有能力把用户请求、Agent 编排、工具调用、知识检索、模型推理串成一条可追溯、可诊断、可治理的链路。
这条链路的技术底座已经成熟——OpenTelemetry 提供标准,Langfuse / Arize Phoenix 提供 AI 原生能力,Prometheus / Grafana 提供指标与看板。缺的不是工具,是团队把这件事排上优先级的决心。
AI Agent 真正的差距,很多时候不在模型参数,而在你能不能看清它为什么成功,又为什么失败。
