🐉 龙哥读论文知识星球来了!还在为医学AI模型“知识匮乏”和“答非所问”发愁?星球每日拆解像KG-CMI这样的前沿融合架构,知识图谱、Mamba、多模态,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文巧妙地将两个“当红炸子鸡”——知识图谱和Mamba架构——结合到了一起,直击医学视觉问答(Med-VQA)的两大痛点:缺乏专业医学知识和难以处理开放式问题。它不仅用知识图谱给AI模型“灌输了”医学常识,还用高效的Mamba模块实现了跨模态深度交互,最终在多个权威数据集上实现了全面领先。更重要的是,它的设计思路清晰,模块化程度高,对于想将知识引入多模态模型的研究者来说,具有很高的参考价值。
原论文信息如下:
论文标题:
KG-CMI: Knowledge graph enhanced cross-Mamba interaction for medical visual question answering
发表日期:
2026年04月 (预印本)
发表单位:
西北工业大学(主要),天津中心妇产科医院,拉筹伯大学,CSIRO Data61,哈尔滨工业大学,天津大学,澳门理工大学,天津胸科医院等
原文链接:
https://arxiv.org/pdf/2604.00601v1.pdf
想象一下,一位AI医生看着你的X光片,你问它:“这片子上显示的肺部结节,可能是肺癌吗?”它如果只是根据图像纹理猜个“是”或“否”,你敢信吗?真正的医生会结合解剖位置、结节特征、你的病史等一系列知识来判断。
这正是当前医学视觉问答(Medical Visual Question Answering, Med-VQA)面临的瓶颈:模型缺乏专业的医学常识,且难以处理需要详细描述的开放式问题。
最近,一篇来自西北工业大学、天津中心妇产科医院等多家机构的论文,提出了一个巧妙的解决方案:给AI模型“装上”一个医学知识图谱大脑,并用高效的Mamba架构让它进行深度“思考”。
这个名为 KG-CMI (Knowledge graph enhanced cross-Mamba interaction)的框架,在多个权威医学VQA数据集上实现了全面领先。今天,龙哥就带大家拆解一下,这个“知识图谱 + Mamba”的组合拳,到底是怎么打的。
医学AI新突破:当知识图谱遇上Mamba
Med-VQA是医学AI里的一个关键任务。简单说,就是给模型一张医学影像(比如CT、X光)和一个相关问题,让它给出正确答案。
这个任务难在哪?第一,“看图说话”不够。 图像上一个阴影,可能是炎症,也可能是肿瘤。光看纹理形状,AI容易懵。必须结合医学知识:这个位置通常是什么器官?这个器官常见的病变有哪些?这些知识散落在海量文献里,模型很难自己学到。
第二,“选择题”太局限。 很多早期方法把VQA当分类题做,答案是从一个固定列表里选。但真实临床问题五花八门:“这个结节位于肺的哪个叶?”“脑部哪个区域有梗塞?”答案需要自由生成。处理这种开放式问题,对模型要求高得多。
KG-CMI的解题思路很直接:缺知识?那就引入知识图谱(Knowledge Graph)。你可以把它想象成一个结构化的医学百科全书,里面记录了“心脏-包含-左心室”、“肺炎-可能表现-肺部阴影”等各种实体和关系。模型在做判断时,可以随时查阅这本“书”。
跨模态交互计算量大?那就用Mamba。Mamba是近年来备受关注的一种序列模型,它的一大优势是能以线性复杂度处理长序列,比Transformer常用的二次方复杂度高效得多。这让模型能更“从容”地对图像、文本、知识进行深度关联思考。
最终目标,是让模型像一个受过专业训练的医生那样,能看、能读、能查资料、能综合推理。
四大模块拆解:KG-CMI如何炼成?
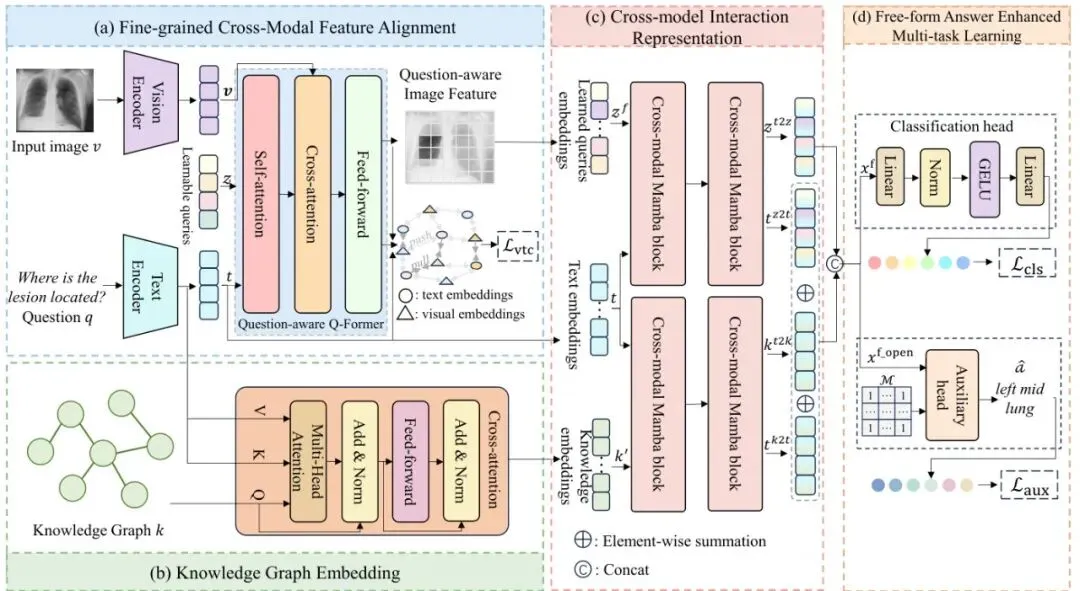
整个KG-CMI框架像一条精密的流水线,由四个核心模块串联而成。我们结合架构图来看。
图1:KG-CMI的整体架构图,包含四个核心模块:(a)细粒度视觉-文本特征对齐,(b)知识图谱嵌入,(c)跨模态交互表示,(d)自由形式答案增强的多任务学习。
模块一:细粒度特征对齐(FCFA)- 确保“看”和“问”对上号
首先,模型需要分别理解图像和问题。图像用Vision Transformer(ViT)编码,问题用RoBERTa编码。关键一步是让图像中与问题最相关的区域和问题中的关键词语义对齐。
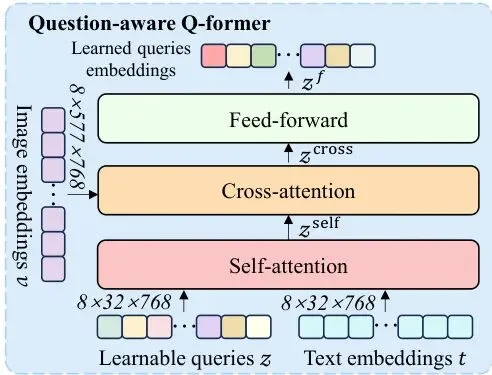
比如,问题问“肺部有结节吗?”,模型就应该把视觉特征聚焦在肺部区域,并和“肺”、“结节”这些词建立强关联。这个任务由一个叫做QQ-Former(问题感知的Q-Former)的模块完成,它通过对比学习损失,像老师纠正学生一样,拉近相关图文特征的距离,推远不相关特征的距离。
图2:QQ-Former(问题感知的Q-Former)的详细结构,包含自注意力和交叉注意力层,用于对齐视觉和文本特征。
模块二:知识图谱嵌入(KGE)- 给模型“开小灶”补课
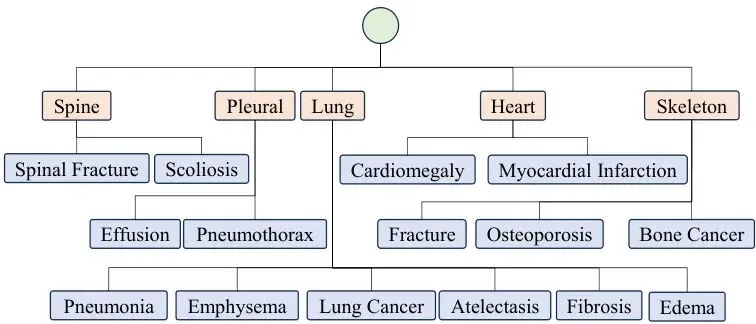
对齐了“所见”和“所问”,接下来要调用“所学”。这里用到了外部构建的医学知识图谱,论文采用的是SLAKE数据集提供的图谱。
图3:一个预构建的知识图谱示例。绿色圆圈代表全局节点,橙色框代表器官级实体,蓝色框代表关键发现(如病变)。它们之间通过边连接。
模型不是死记硬背整个图谱,而是用图注意力网络(GAT)对图谱信息进行编码,然后根据当前的问题,动态地从图谱中检索出最相关的知识片段。例如,问题涉及“心脏”,那么图谱中与“心脏”相连的“心室”、“瓣膜”、“心肌梗塞”等节点就会被激活并提取出来,形成一组知识特征向量。
模块三:跨模态Mamba交互(CMIR)- 启动高效“三边会谈”
现在,我们有了三组信息:对齐后的视觉特征、文本特征、以及检索到的知识特征。核心的推理发生在这里。
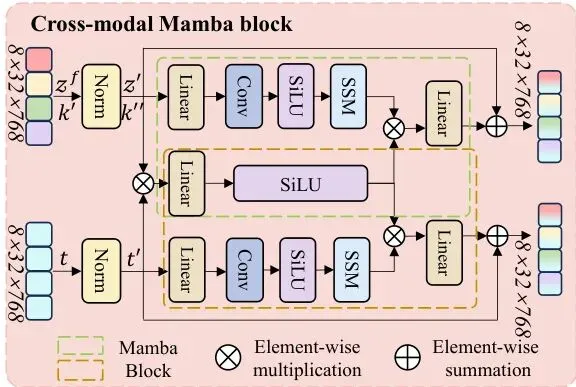
传统方法常用Transformer的交叉注意力,但计算量随序列长度平方增长。KG-CMI创新地使用了交叉Mamba块(Cross-Modal Mamba, CMM)。Mamba的核心是选择性扫描机制,能以线性复杂度处理序列,非常适合整合较长的多模态信息。
图4:交叉模态Mamba(CMM)块的详细结构。它通过Mamba的选择性扫描机制,高效地融合视觉、文本和知识特征。
CMM块让视觉、文本、知识三者进行深度“对话”:图像特征吸收文本和知识的描述,文本特征吸收图像和知识的佐证,知识特征也在与图文交互中被具体化。经过几层这样的交互,最终融合成一个富含多模态信息的联合表示。
模块四:自由答案增强多任务学习(FAMT)- “大作文”训练提升“选择题”能力
这是解决开放式问题的妙招。模型最终还是要输出答案(分类),但作者认为,让模型额外练习生成自由文本答案(像写小作文),能迫使它学习更精细、更全面的语义表示,从而反哺其分类判断的准确性。
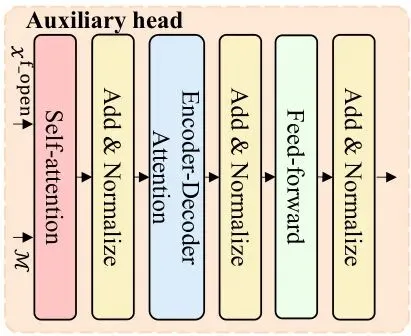
图5:辅助头(AHead)的详细结构。它基于T5解码器,用于在训练时生成自由形式的答案,通过一个可学习的注意力掩码聚焦于多模态特征中的重要部分。
因此,KG-CMI在训练时采用多任务学习:一个主任务(分类头)用来回答所有问题;一个辅助任务(辅助头)只针对开放式问题,要求模型生成完整的文字答案。两者损失加权求和。到了推理阶段,只使用分类头来预测答案,轻量且高效。
这就像一个学生,平时不仅做选择题,还坚持练习问答题。虽然考试(推理)时只考选择,但问答题的训练让他对知识点理解得更透,做选择自然更准。
实验验证:三大数据集全面领先
设计得好,更要效果硬。论文在三个主流Med-VQA数据集上进行了全面测试:SLAKE(涵盖多器官)、VQA-RAD(放射学)、OVQA(骨科学)。
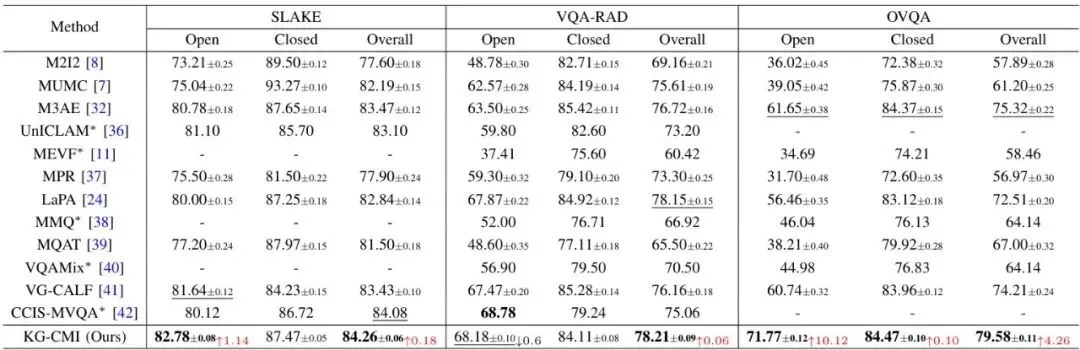
表1:在SLAKE、VQA-RAD和OVQA数据集上与最先进方法的性能比较(准确率,%)。不带星号的结果报告为平均值±标准差。最佳值用粗体标出,相对于第二好结果的改进用红色标出。
从表1可以清楚看到,KG-CMI在三个数据集的总体准确率、开放式问题准确率、封闭式问题准确率上,几乎全部取得了最佳成绩。尤其在开放式问题上优势更为明显,这说明其知识增强和多任务学习的策略确实有效。
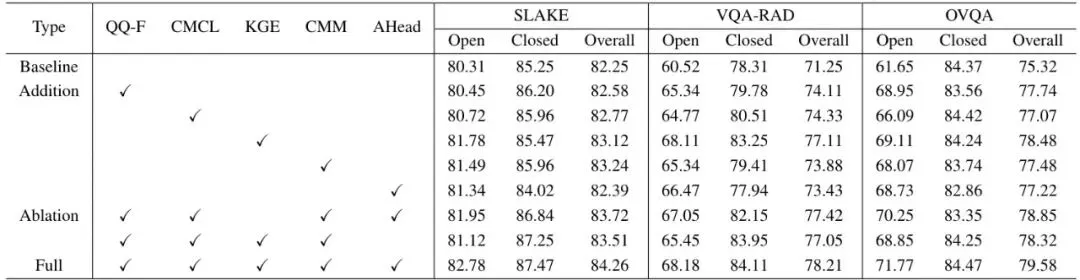
为了验证每个模块都不是“摆设”,作者做了详尽的消融实验。
表2:在多个数据集上的消融研究性能。QQ-F表示QQ-Former模块。
表2显示,移除任何一个模块(KGE, CMM, FAMT)性能都会下降,其中知识图谱(KGE)和自由答案多任务(FAMT)对开放式问题提升贡献最大,而跨模态Mamba(CMM)对整体效率和质量都有益。这完美印证了设计初衷。
作者还对比了CMM与标准交叉注意力(CA)的效率,如表7所示,CMM在保持相当甚至更好性能的同时,参数量和计算量显著更低,证明了Mamba在跨模态建模中的效率优势。
表7:CMM与交叉注意力(CA)的实证比较,显示CMM在性能和效率上的优势。
可视化洞察:模型真的“看懂”了医学图像吗?
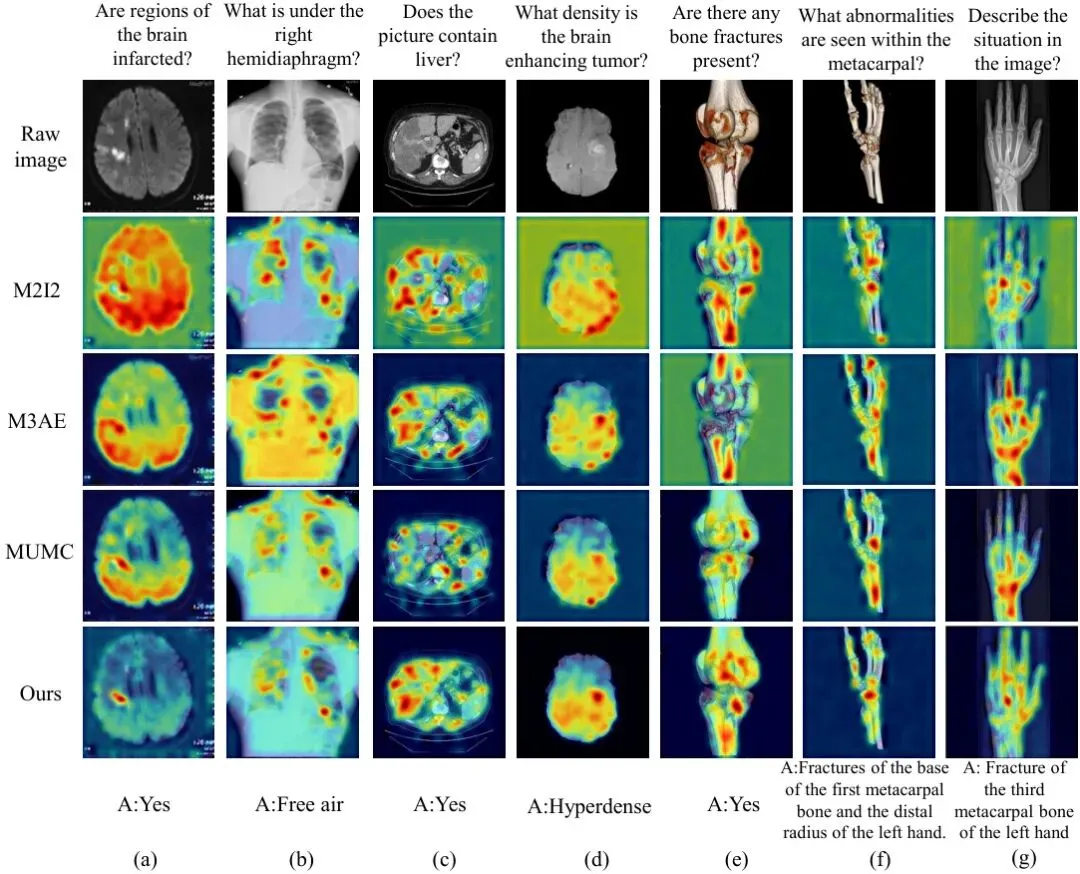
对于医学AI,光有高准确率不够,我们还得知道它是不是“蒙对的”。可解释性至关重要。论文使用Grad-CAM技术生成了视觉显著性图,直观展示模型在做决策时到底关注图像的哪些区域。
图7:代表性方法的视觉显著性图对比。KG-CMI(我们)的注意力更精确地聚焦在与问题相关的病灶区域。
看图7的例子,对于问题“Is there air in the pericardium?”(心包里有空气吗?),基线模型M3AE的注意力散乱,而KG-CMI的注意力(红色高亮区)清晰地集中在了心包区域的异常亮斑(空气)上。这强烈表明,KG-CMI不仅答对了,而且是真的“看懂”了图像,并基于正确的区域做出了推理。
论文也分析了失败案例(图8),主要是对一些非常细微或罕见的病变判断不准。这很正常,也指明了未来改进的方向:需要更高质量、更全面的数据和知识。
未来展望:临床落地还有多远?
KG-CMI在学术数据集上表现亮眼,但走向真实临床,仍有几座大山要翻越:
1. 知识与数据的质量与规模: 当前知识图谱和训练数据仍有限。构建覆盖全疾病谱、实时更新的权威医学知识图谱是巨大工程。数据中的标注噪声和偏见也需要谨慎处理。
2. 实时性与可靠性: 临床要求毫秒级响应。虽然Mamba提升了效率,但整合多模块的完整流程仍需优化。更重要的是,模型必须极其可靠,任何错误都可能导向严重后果,因此需要严格的临床验证和“人机协同”机制。
3. 可解释性与信任建立: 像本文做的可视化是好的开始,但医生需要更深入的推理链条解释:为什么是A不是B?用了图谱里的哪条知识?增强模型的“说理”能力是建立临床信任的关键。
尽管如此,KG-CMI清晰地指明了一个有价值的进化方向:让AI从“模式匹配”走向“知识驱动”的推理。 它提供的模块化设计思路(如何嵌入知识、如何高效交互、如何通过生成任务增强理解)对后续研究和产品开发具有很高的参考价值。
龙迷三问
这篇论文解决的核心问题是什么?主要解决医学视觉问答(Med-VQA)中的两大难题:1)模型缺乏专业的医学领域知识,难以进行准确关联推理;2)传统分类方法无法很好地处理需要自由文本回答的开放式临床问题。
Mamba和知识图谱分别在这里起什么作用?知识图谱的作用是“注入专业知识”,为模型提供一个结构化的医学常识库,帮助它将图像特征与抽象的医学概念联系起来。Mamba的作用是“高效深度交互”,它以线性复杂度融合图像、文本和知识这三种模态的信息,比传统的Transformer交叉注意力更高效,使深度推理成为可能。
为什么训练时让模型生成自由答案,能提升它做分类(选择题)的能力?这是一种“多任务学习”策略。生成自由答案(问答题)是一项更难的任务,它强迫模型必须理解问题的所有细节,并组织准确、完整的语义信息来作答。这个过程让模型学到了更丰富、更精细的特征表示。当它回头去做分类(选择题)时,由于对问题的理解更深了,所以判断也会更准。可以理解为“做难题锻炼了思维,简单题自然不在话下”。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
本文的核心创新在于将知识图谱与Mamba架构进行深度、系统的融合,并设计了多任务学习策略来应对开放式问题。这不是简单的“1+1”,而是针对Med-VQA领域痛点的有机组合与创新应用,思路清晰且完整。扣一星是因为知识图谱和Mamba本身均为现有技术,属于出色的组合创新而非底层原始创新。
实验合理度:★★★★☆
实验设计全面,在三个主流数据集上与多类SOTA方法对比,并进行了详尽的消融实验、参数敏感性分析、效率对比和可视化分析,验证充分。消融实验清晰证明了每个模块的有效性。扣一星在于对模型在更广泛、未见疾病或跨中心数据上的泛化能力验证可以进一步加强。
学术研究价值:★★★★✰
价值很高。它为解决多模态AI中“如何有效整合外部知识”和“如何实现高效深度推理”这两个共性难题,提供了一个经过验证的优秀范式。其模块化设计(FCFA, KGE, CMIR, FAMT)思路清晰,对后续研究者在医疗乃至其他专业领域的视觉-语言任务研究中,具有很好的启发性。
稳定性:★★★☆☆
在论文测试的基准数据集上表现稳定(报告了均值和标准差)。但医学模型稳定性极端重要,其表现严重依赖于知识图谱的完整性和训练数据的质量。面对图谱未覆盖的罕见病或低质量图像,性能可能出现显著波动,离“开箱即用”的临床稳定性尚有距离。
适应性以及泛化能力:★★★☆☆
框架设计本身具有通用性,可适配不同的知识图谱和数据集。但其性能上限受限于所用知识图谱的领域和规模。从放射学(VQA-RAD)到骨科(OVQA)的测试显示了跨子领域的适应性,但泛化到全新医学领域(如病理、眼科)需要重建或扩展知识图谱,成本较高。
硬件需求及成本:★★★☆☆
采用Mamba降低了核心交互模块的计算复杂度,是一大优点。但整体框架仍包含ViT、RoBERTa、GAT、T5等多个组件,训练阶段对显存和算力有较高要求(论文使用RTX 4090)。推理阶段只使用分类头,会轻量很多,但相较于纯小型分类模型,部署成本仍偏高。
复现难度:★★★☆☆
论文方法描述清晰,但涉及模块多、流程复杂,复现需要较强的工程能力。最大的门槛在于医学知识图谱的构建与准备,论文虽提及使用SLAKE的图谱,但其具体构建细节和是否开源未明确说明,这可能成为完整复现的关键障碍。
产品化成熟度:★★☆☆☆
目前主要处于学术验证阶段。要产品化,尤其是用于辅助诊断,面临严格监管、知识图谱维护更新、实时性保证、与医院信息系统集成、以及最重要的临床落地验证等一系列挑战。可考虑先在医学教育、报告初筛等风险较低的场景中尝试应用。
可能的问题:本文是一项扎实的研究,主要问题在于其效果对高质量知识图谱的强依赖,而这本身就是一项艰巨的工程。此外,多任务学习中的辅助生成任务与主分类任务之间的相互作用机制,可进一步从理论上进行更深入的分析和解释。
[1] X. Zheng, H. Yu, H. Cui, et al., "KG-CMI: Knowledge graph enhanced cross-Mamba interaction for medical visual question answering," arXiv preprint arXiv:2604.00601, 2026.[原论文链接] https://arxiv.org/pdf/2604.00601v1.pdf*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想让你的AI模型也拥有“医学知识库”和“高效推理脑”吗?快来加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 AI医疗+北京+协和+小医),根据格式备注,可更快被通过且邀请进群。


 夜雨聆风
夜雨聆风