当前时间: 2026-06-18 03:59:05
分类:办公文件
评论(0)
你以为你了解AI,其实你用的是去年的AI每次我跟AI兴趣群友聊AI,总会碰到两种截然相反的反应。一种人会笑着甩给我一个短视频,说"你看AI连洗车要开车还是走路都分不清";另一种人则语气急促,几乎带着某种焦虑:"你试过最新的Codex和Claude Code吗?它能连续跑一个小时,把整个代码库重写一遍。"这两种人聊的都是AI。但他们聊的,根本不是同一个东西。Karpathy 最近点破了这件事。他说,人们对AI能力的理解正在出现越来越大的裂缝。这条裂缝不是因为谁更聪明谁更蠢,而是因为大多数人对AI的印象,还停留在上次使用它的那个瞬间。大多数人对AI的判断,来自一次过期的体验
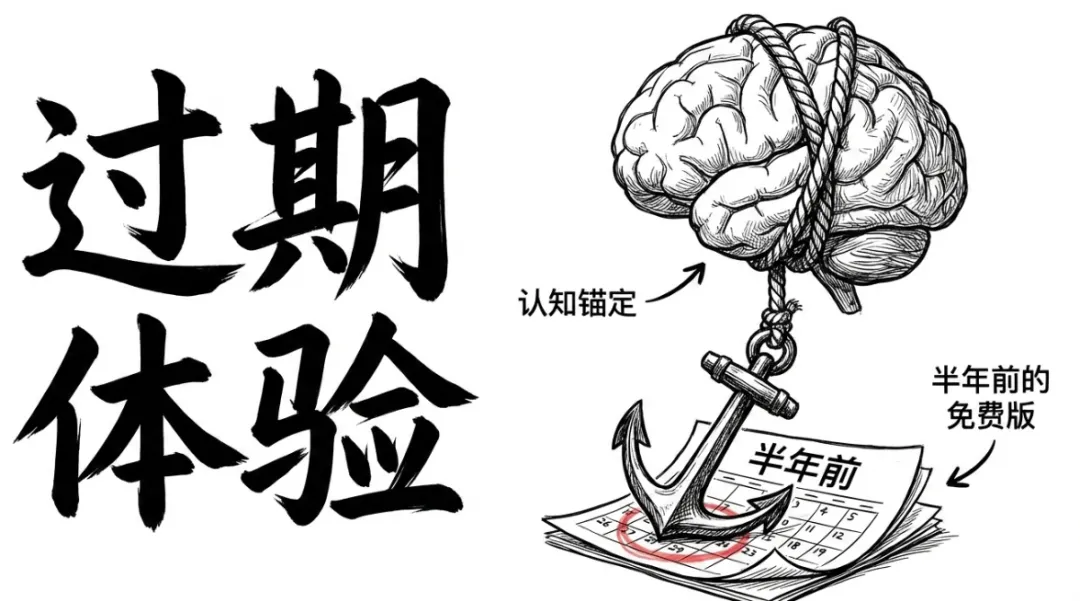
你身边一定有这样的人:去年某个时候试了一次ChatGPT的免费版,问了几个问题,觉得回答还行但偶尔胡说八道,然后关掉了页面。从此以后,"AI就那样"变成了他们的底层判断,再也没更新过。他们不是不聪明。恰恰相反,很多是受过良好教育、在自己领域很有判断力的人。但正因为他们在某一次试用中形成了一个"够用"的印象,这个印象就变成了他们认知AI的天花板。问题是,AI的进化速度和你换手机壳的速度不是一个量级。去年的免费版模型和今年最前沿的智能体模型之间的差距,不是"好了一点",而是"换了一种物种"。这就像你2015年用过一次外卖App觉得不靠谱,然后在2026年还在坚持"外卖不行"。你不是错了,你只是活在自己上一次体验的平行世界里。这种认知锚定效应在AI领域尤其致命。因为AI的能力曲线不是线性的,它是台阶式跳跃的。你不用的那段时间里,它可能已经跳了两三级台阶。真正的能力爆发,藏在大多数人看不见的地方
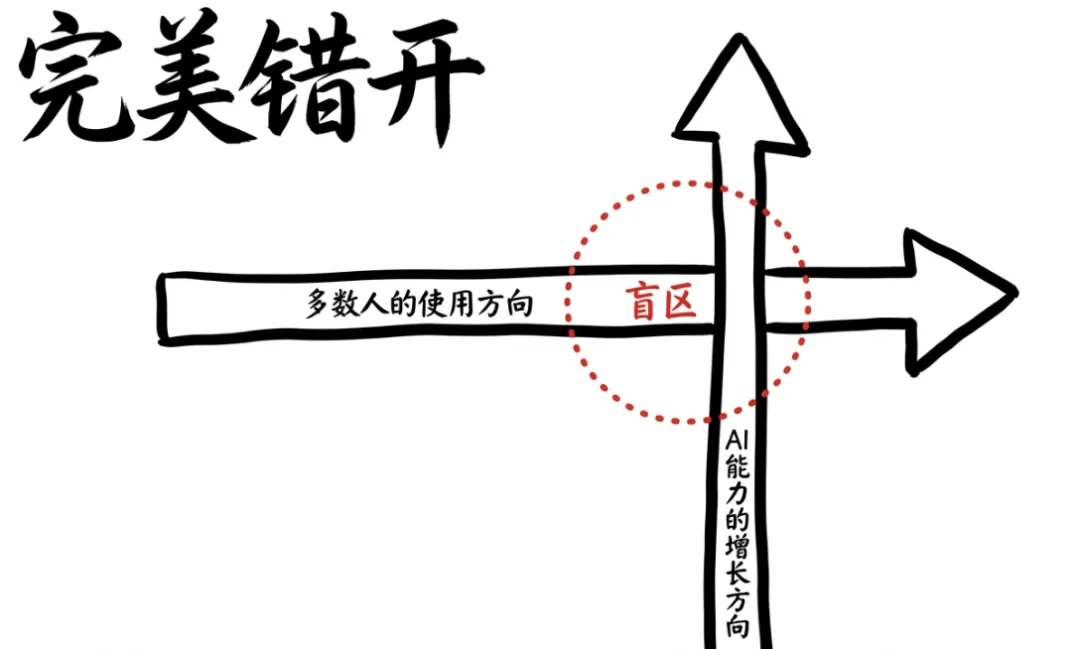
还有一个更深层的原因:即使你花了钱、用了最新的模型,AI最惊人的进步也未必发生在你最常用的功能上。搜索、写邮件、帮你想个标题、给你出出主意,这些是大多数人和AI打交道最多的场景。但恰恰是这些场景,不是过去一年进步最猛的方向。第一个原因是技术层面的。当下AI能力提升最快的方向,高度依赖一种叫"可验证奖励"的强化学习机制。简单来说,AI在那些"对错一眼能看清"的任务上进步最快。代码能不能跑通、学题对不对、测试用例过不过——这些都有清晰的判对判错标准,天然适合用来训练。但"这篇文章写得好不好""这个建议是否得体",些事情的好坏标准是模糊的、主观的、很难被算法精确捕捉的。第二个原因是商业层面的。AI公司的资源是有限的,它们会把最好的工程师和最多的算力投向回报率最高的方向。而回报率最高的方向,不是帮你写一条更好的朋友圈文案,而是帮企业写代码、做数据分析、跑安全测试。B2B场景的客单价和付费意愿远高于个人用户的随手一问。钱在哪里,能力就往哪里跑。所以我们看到了一个非常有趣的局面:AI在普通人最常用的场景里进步平缓,在大多数人根本接触不到的专业场景里进步惊人。这就是认知裂缝真正的成因。不是谁比谁笨,而是能力的增长方向和多数人的使用方向,恰好错开了。两个平行世界,已经互相听不懂了
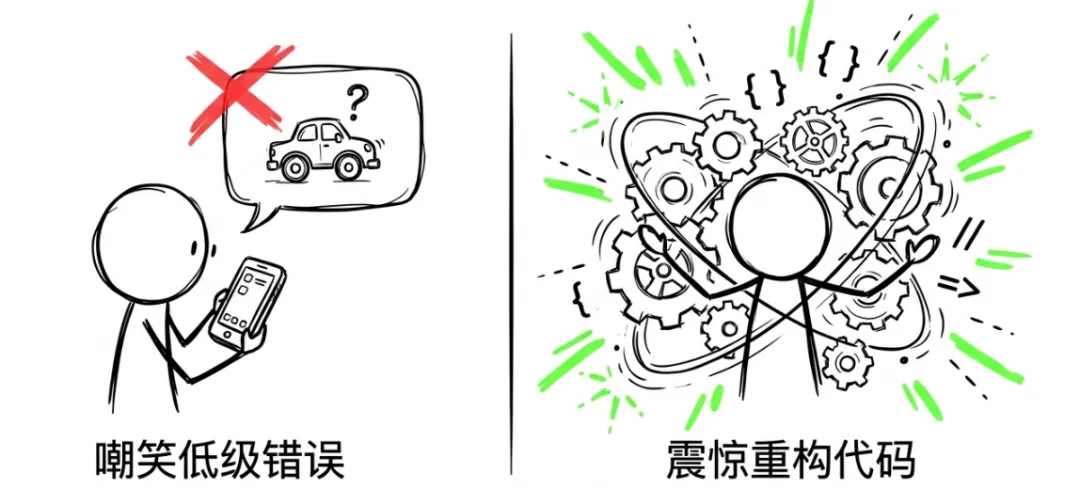
理解了上面两层,你就能理解为什么今天关于AI的公共讨论变得越来越撕裂。一边是"AI不行派"。他们的论据真实、案例生动、短视频传播力还特别强。免费版ChatGPT回答一个常识问题犯了低级错误,语音助手被简单的逻辑题绕晕。这些确实发生过,确实可笑,截图发到社交媒体上确实很容易获得共鸣。另一边是"AI已经疯了派"。他们正在付费使用最顶级的智能体工具,亲眼看着AI在一个小时内把一个大型代码仓库从头重构,发现系统漏洞,写出能通过所有单元测试的全新模块。这些人的震惊是真实的,他们的焦虑也是真实的,因为他们看到的能力增长斜率,意味着很多事情的时间表可能需要被大幅提前。问题是,这两拨人在公共空间里碰面时,几乎完全无法对话。"AI已经疯了派"会觉得另一边活在过去、拒绝睁眼。两边都不是在撒谎。他们只是站在同一条河的不同位置,一边水深一米,另一边已经水深十米。这条河叫"AI能力"。而它的水位,在不同区域的涨速完全不同。这道裂缝,正在变成一道关乎个人竞争力的鸿沟
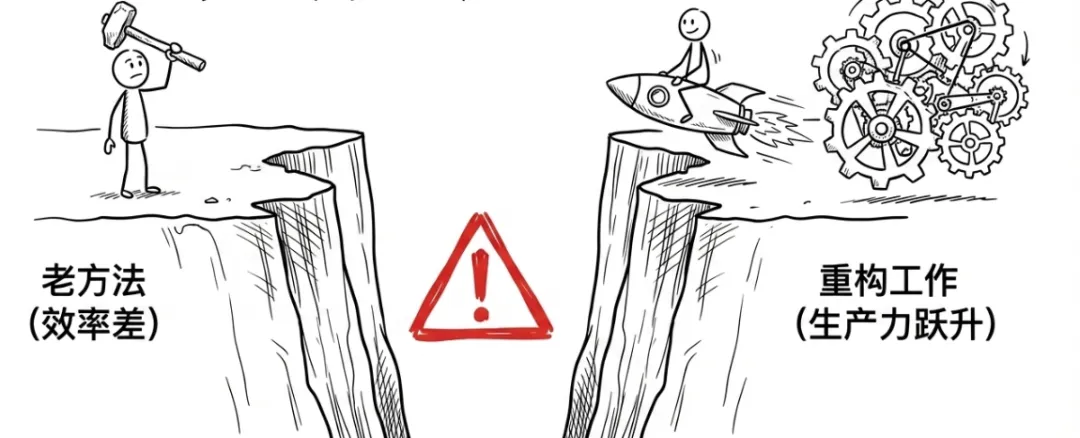
如果这只是互联网上两拨人的嘴仗,那写到这里就够了。这道认知裂缝正在变成一道真实的能力鸿沟,而且这道鸿沟的两边,差距只会越来越大。一边是那些持续追踪最前沿模型、在专业场景中深度使用AI的人。他们不只是在"体验"AI,而是在拿AI重构自己的工作方式。写代码的人让AI帮自己并行处理多个任务,做研究的人让AI在几分钟内扫完一个领域的文献,做分析的人让AI同时跑十个因子模型。这些人的生产力正在以月为单位跳升。另一边是那些用了一次、觉得"不过如此"、然后再也没回来的人。他们不是懒,很可能只是忙,忙着用老方法做老任务。但当竞争对手或同事已经在用新工具的时候,"不了解"就不只是信息差了,而是效率差。2010年前后,有一批人很早就认真学会了用Excel的数据透视表、VLOOKUP和简单的VBA宏。另一批人觉得"Excel嘛,我会用就行了,复杂的不需要"。五年后,前者成了团队里不可或缺的分析引擎,后者还在手动复制粘贴对数据。今天AI正在制造一道类似但更陡峭的分水岭。因为AI的能力天花板远比Excel高,而且它还在每个月抬高。你不用它,它也在进化。而用它的人,会被它一起带着进化。怎么不被这道裂缝甩到错的那一边
不要让半年前的一次体验定义你对AI的判断。设一个提醒,每个季度花半天时间,认真试一下当前最新的模型。不是随便问两个问题就关掉,而是拿一个你真正在做的工作任务去测。你会发现,你的印象和现实之间的差距,可能比你愿意承认的要大得多。AI在帮你写一段朋友圈文案和帮你重构一个数据分析流程之间的能力差距,可能是十倍级别的。如果你只在前者上体验过AI,你永远不会理解后者的人为什么那么兴奋。把AI放进你最难、最耗时、最有价值的工作场景里,你才能真正感受到它的能力边界在哪里。每当你或你身边的人得出"AI做不了这个"的结论时,追问一句:用的是哪个模型?哪个版本?什么时候试的?怎么提问的?很多时候你会发现,结论本身没问题,但它的前提已经过期了。最后说两句
Karpathy 说的那道裂缝,本质上不是技术问题,是信息更新频率的问题。AI的能力在以月为单位进化,但大多数人对AI的认知在以年为单位更新。这中间的时差,就是裂缝的来源。越是觉得AI不行的人,越不会去用新版本;越不用新版本,就越觉得AI不行。这是一个完美的认知闭环。反过来,越是深度使用的人,越能发现新的能力边界,越会投入更多时间去探索和应用,能力优势就越滚越大。所以,今天最重要的不是"AI到底行不行"这个问题。而是,你对AI的判断,是基于今年的现实,还是去年的记忆?
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-07-05 07:36:03 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/521229.html
- 运行时间 : 0.118802s [ 吞吐率:8.42req/s ] 内存消耗:4,829.10kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=2643011ebe9f4c9b4fbcc6a7200e57da
- CONNECT:[ UseTime:0.000639s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.000818s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000311s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000309s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.000525s ]
- SELECT * FROM `set` [ RunTime:0.000215s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.000595s ]
- SELECT * FROM `article` WHERE `id` = 521229 LIMIT 1 [ RunTime:0.000528s ]
- UPDATE `article` SET `lasttime` = 1783208163 WHERE `id` = 521229 [ RunTime:0.017727s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.000603s ]
- SELECT * FROM `article` WHERE `id` < 521229 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.002818s ]
- SELECT * FROM `article` WHERE `id` > 521229 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.004527s ]
- SELECT * FROM `article` WHERE `id` < 521229 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.000883s ]
- SELECT * FROM `article` WHERE `id` < 521229 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.001101s ]
- SELECT * FROM `article` WHERE `id` < 521229 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.005349s ]

0.120499s

 夜雨聆风
夜雨聆风