 夜雨聆风
夜雨聆风
有次我跟小龙虾聊了一个上午。从产品定位到功能设计,改了七八轮,终于把方案定稿了。
下午我接着问它:"早上那个方案,第三点是什么来着?"
它回我:
抱歉,我不太确定您说的"那个方案"是指哪个。
我:跟你聊了两个小时,283,000 个 token 的对话,你现在问我指的是哪个?这已经不是笨了。这是健忘。
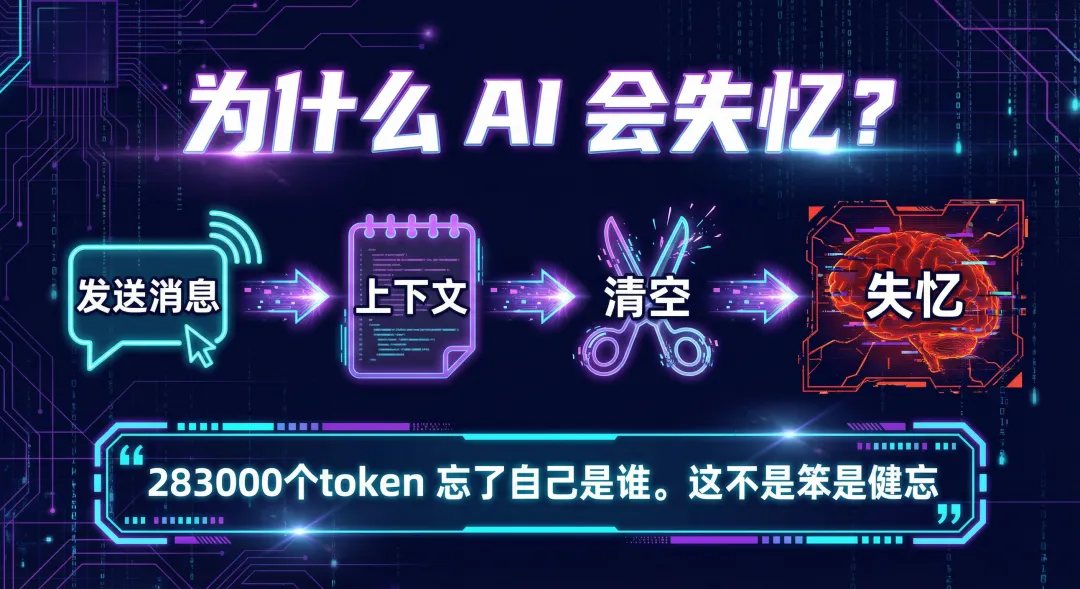
现在的 AI 很聪明,写代码、写文案、翻译、做,什么都会。但有一个致命的毛病——它没有记忆。
为什么 AI 会失忆?
你以为 AI 记得你,它其实根本不记得。每次你发消息给它,它都是从零开始看的。它不知道自己昨天跟你聊过天,也不知道你是谁,更不记得你说过"我的猫叫沙雕"。
所谓 AI"记得"你的偏好,不过是把之前的对话历史重新喂给它,让它假装记得。
你可以把 AI 的上下文窗口理解成一张有限的草稿纸。128K、204K、1M 的模型,等于小桌子、中桌、大桌子。桌子越大,能同时放的东西越多。但桌子再大,清空了就什么都没了。
纸写满了怎么办?旧内容被压缩、裁剪、甚至丢掉。
"三页纸的详细讨论"被缩成一句话:"用户问了关于产品方案的事"——关键词留下了,细节没了。
记忆有两种死亡方式:
渐进式遗忘:对话越来越长,AI 被迫把旧内容压缩成摘要。就像你把"三小时的会议记录"缩写成"讨论了 Q2 目标"——关键词在,细节没了。
暴力清空:打开新对话窗口、上下文溢出——所有记忆瞬间清零。
记忆的分类:短期 vs 长期
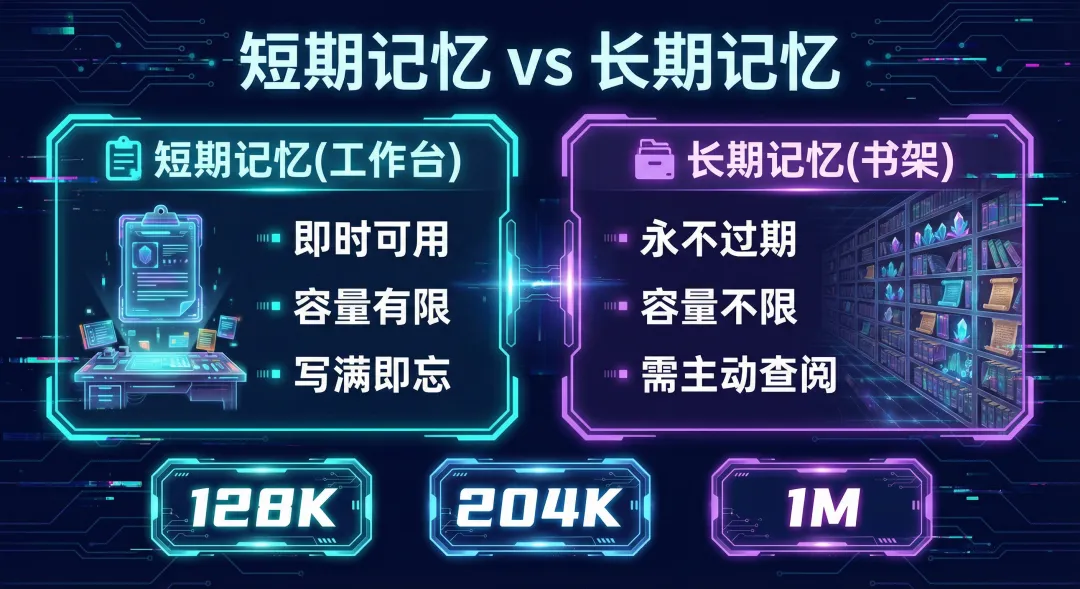
AI 也分两种记忆,跟人很像。
短期记忆 = 工作台(上下文窗口):即时可用,不需要翻找。但桌子只有那么大,写满了就得擦旧的。类比人脑的工作记忆——你只能同时记住 7±2 个东西。
长期记忆 = 书架上的笔记本:把重要信息写下来,放到书架上,需要时再翻出来。永不过期,容量不限。但需要主动查阅,AI 不会自己"突然想起来"。
关键区别:短期记忆是"现在能想起来的",长期记忆是"存在某处可以查到的"。
就像你不可能记住所有事,但你有备忘录、笔记本、手机相册——AI 也一样。
AI 的记忆限制与现实挑战
一个人的记忆不可能是无限的,AI 也一样。
现实限制 1:上下文窗口的硬限制
就算模型号称 1M token(约 70 万字),实际好用的远没有这么多。上下文越大,每次回复越慢、越贵。就像桌子越大,找东西越难。
现实限制 2:存了≠能找到
存了很多信息,但需要用关键词才能找回。很多时候你记不起该搜什么词——就像你知道自己记过某个东西,但忘了记在哪个笔记本里。
现实限制 3:"提醒也没用"的场景
失忆后提醒它"之前我们说过 XXX"——但那段对话已经不在"工作台"上了。就像你给别人发微信,对方手机丢了——"你再发一遍"解决不了问题。
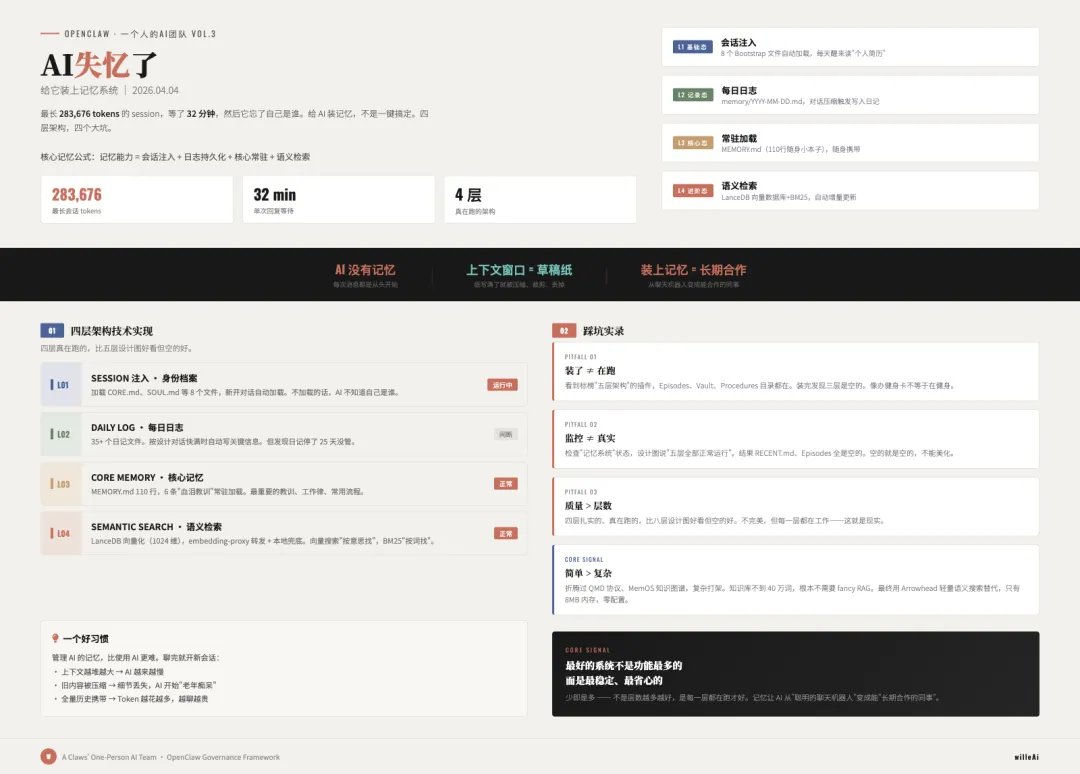
给小龙虾装记忆:我的真实四层架构
给 AI 装记忆,不是一键搞定那么简单。我的过程是一步一步摸索出来的。
四层架构,不是五层。四层真在跑的,比五层设计图好看但空的好。
L1:身份档案——每次醒来先看"我是谁"
我给自己准备了 8 个 bootstrap 文件:CORE.md、SOUL.md、MEMORY.md、TOOLS.md、AGENTS.md、USER.md、IDENTITY.md、HEARTBEAT.md。每新开对话就自动加载。不加载的话,AI 连自己是谁都不知道。
就像一个演员上台之前要先看剧本——不然连自己演的是谁都不清楚。
L2:每日日志——每天写日记
35 个文件,从去年 2 月到今天。按设计,对话上下文快满时系统会自动把关键信息写进当天日志。但有一次发现,日记停了 25 天没人管。
为什么?因为这个"自动"不是每次对话都触发——只有对话太长、上下文快撑爆了才会写。如果对话都不长,它就永远不会触发,日记也就断了。
你以为是它在自动记日记,其实是它忘了写,你也没发现。
L3:核心记忆——110 行随身小本子
最重要的教训、工作律、常用流程,常驻加载。6 条"血泪教训",每一条都是踩了坑、被教训之后总结的,比如"独立思考,不要把题丢给用户"、"格式问题不能反复犯"、"内容发布前必须自我审核"。
L4:语义检索——图书馆查书
这就是 LanceDB 向量数据库。它的做法不是关键词匹配,而是把每段记忆都转化成一个 1024 维的向量——就像给每句话打上一个"语义指纹"。
向量化用的是 BAAI/bge-m3 模型(1024 维),通过自建的 embedding-proxy 代理转发。代理还有本地兜底——万一远程挂了自切到本地的 Qwen3-Embedding-0.6B,保证不中断。
检索方面,向量搜索负责"按意思找",另一套 SQLite+BM25 关键词搜索负责"按词找",两套系统各管各的。
假设你问它:"我之前提到的项目进度如何?"这句话被转化成向量后,在数据库里搜索所有语义相近的记忆,找到最相关的几条,注入到 AI 的当前上下文里——AI 就"想起来"了。
就像你去图书馆找书,不需要准确知道书名——说个大概意思,就能搜到。

踩坑实录
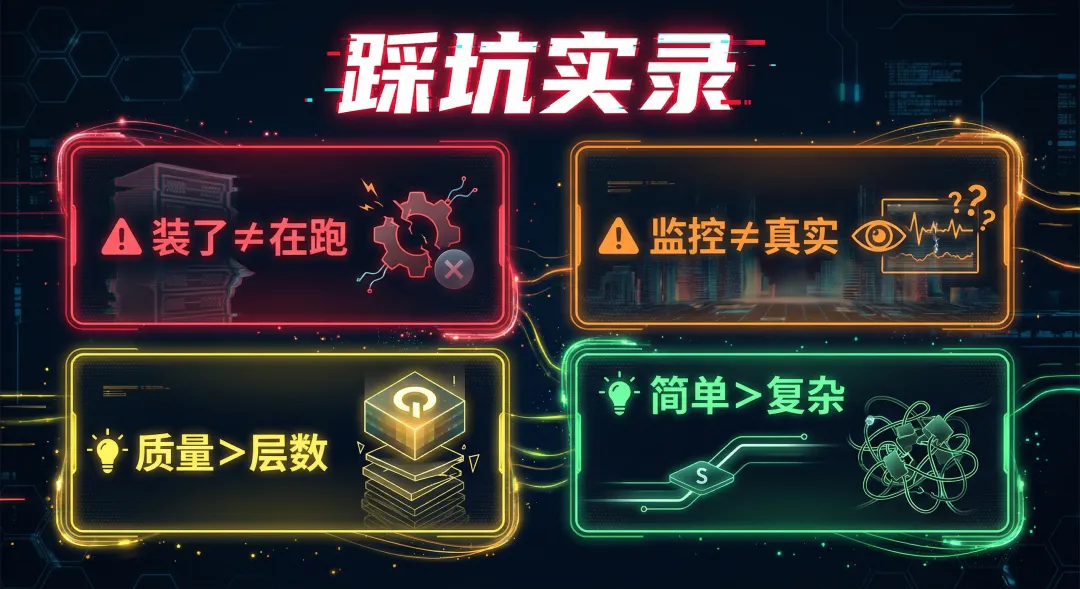
装了记忆系统,不代表就好了。这中间我踩了四个大坑。
踩坑 1:装了插件 ≠ 它在跑
看到一个很酷的记忆插件,设计上标榜"五层记忆架构",看起来非常专业。Episodes、Procedures、Vault——目录都在。装完之后我以为 AI 就有完美记忆了。结果呢?五层里有三层是空的。里面一个字都没有。
就像你办了健身卡不等于在健身。
踩坑 2:监控说正常 ≠ 真正常
有次我让AI自己检查一下系统的记忆系统运行得怎么样。AI只是看了看设计图,说"五层全部正常运行"。结果后来被真实数据查出来——RECENT.md 是空的,Episodes 是空的。AI把空的叫"今日起跑了"。
这个教训不只是给 AI 的。人在汇报工作的时候,不也常常美化吗?数据不好看?"趋势向好"。没完成?"在推进"。
空的就是空的,不能美化。
踩坑 3:质量比层数重要
四层扎实的、真在跑的,比八层设计图好看但空的好。不完美,但每一层都在工作——这就是现实。
踩坑 4:fancy RAG 不如简单方案
早期我折腾过很多复杂的记忆方案:QMD(Question-Memory-Delta)协议、Lossless-Claw 上下文压缩、MemOS 知识图谱……每个方案设计上都很专业,但组合起来互相打架。配置复杂,维护成本高。
后来看到 Karpathy 和 Yanhua 两人分别得出了同一个结论:
知识库不到 40 万词,根本不需要 fancy RAG。简单加个索引就够了。
最终我用 Arrowhead(一个 Obsidian 笔记搜索工具)替代了 QMD。没有 BM25+向量+rerank 三件套,就一个轻量语义搜索,跑起来只有 8MB 内存,零配置,自动增量更新。
能用简单方案解决的,别上复杂架构。最好的系统不是功能最多的,而是最稳定、最省心的。
一个好习惯:聊完就开新会话
除了给 AI 装记忆,我自己也养成了一个好习惯——聊完一个会话就开新的。很多人(包括我自己)都有个毛病:一个会话聊到底,从早聊到晚。坏处很明显:
养成"聊完就重开"的习惯。聊完一个任务或话题后,主动开新会话。新会话会自动加载所有 bootstrap 文件(AI 知道"我是谁"、"要干什么"),带着清晰的状态重新开始。之前的内容已经写进了日志,不会真正丢失。
一个会话聊到底 = 从来不记笔记,也不整理桌面,东西越堆越乱
聊完就开新的 = 每天下班前整理桌面,带上笔记本第二天重新开始
个人思考
管理 AI 的记忆,比使用 AI 更难。这个月的又一个感悟。给 AI 装记忆系统,本质上是在做一件事:
让它从一个"聪明的聊天机器人",变成一个"能长期合作的同事"。
没有记忆的 AI = 每天醒来都不知道自己是谁
有了记忆的 AI = 有经验积累,越用越顺手
少即是多。不是层数越多越好,是每一层都在跑才好。四层能用的,比八层设计图好看的好。
记忆之上:还有什么?
记忆让 AI 不失忆。但有一个更庞大的系统还没聊到。
记忆是"我的东西"——我知道自己是谁、有什么教训、正在做什么。
知识是"怎么做"——系统怎么配、有哪些工具可用、团队做过哪些决策。
一个完整的 AI 助手,两者缺一不可:
没有记忆 → 不知道自己是谁
没有知识库 → 不知道怎么做事
在我的系统里,知识库是用 Obsidian 搭建的——一个本地笔记软件,但我把它改造了 AI 可以随时查阅的"维基百科"。Agent 通过专用的搜索工具直接查知识库,就像可以随时翻手册的实习生,不用什么都问老板。
搭建一个 AI 能用的知识库,比想象中复杂。目录结构怎么设计,才能让 AI 找得到?哪些信息该放知识库,哪些放记忆?怎么维护知识库,才不会变成"堆积如山的垃圾文件"?

下一篇预告:「给 AI 搭一个维基百科:我的知识库搭建之路」
