 夜雨聆风
夜雨聆风1-什么是用户交互鲁棒性测试
在AI领域,用户交互鲁棒性测试(User Interaction Robustness Testing)就是测试AI系统在面对“不按常理出牌”的用户时,能否保持稳定、安全且符合逻辑的表现。
如果把AI比作一个服务员,鲁棒性测试就是为了确保:即便客人说话带口音、逻辑混乱、突然改主意、甚至故意挑衅,服务员也不会当场“死机”或给客人做出报复行为。
•这些情况既包括无意的(如:断网、错别字、输入乱码),也包括有意的(如:恶意攻击),所以鲁棒性测试就是测试AI在面对异常、干扰、攻击时,系统是否会崩溃或胡言乱语。
•要求AI “输入越烂,我越要稳。”(如:乱码、骂人、错别字、提示词注入)
| 我们前面讲的对抗性测试可以理解为鲁棒性测试的一个子集,且具有攻击性。它专门模拟有竞争能力的对手,通过精心设计的“陷阱输入”来诱导AI出错。 对抗性测试是实现鲁棒性的一种手段。 |
2-为什么要测试鲁棒性
AI模型(特别是大语言模型)非常敏感。微小的输入变化可能导致完全不同的输出。鲁棒性测试主要为了解决以下问题:
•应对用户输入的多样性:用户不会像程序员那样输入规范的代码,他们会打错别字、用俚语、语序颠倒。
•应对对抗性攻击:有意图的用户可能会通过“提示词注入”诱导AI说出违规言论。
•保证系统的稳定性:确保模型在极端压力或长对话下不会逻辑崩溃。
3-交互鲁棒性测试的几个维度
1)输入扰动:测试AI对“不完美”输入的容忍度:
•拼写与语法:故意输入“我相买个手几”(我想买个手机),看AI能否理解意图。
•同义替换:将“帮我订一张机票”改为“给我弄张飞行的票”,测试语义理解的一致性。
•多语言混杂:测试“中英夹杂”或方言对系统的干扰。
2)逻辑与上下文一致性:测试AI在复杂对话中的“记忆力”和逻辑链:
•否定测试:告诉AI“我不要辣的”,随后问“那帮我点个麻辣烫”,看AI是否会提醒冲突。
•长文本压力:在极长的对话后,测试AI是否还记得最初设定的约束条件。
3)边界与极端情况:空白/乱码输入: 狂敲空格或乱码字符,看系统是否会返回报错代码或崩溃。
•超长输入:输入超过Token限制的文本,观察系统的截断处理机制。
4)对抗性测试:
•越狱测试(Jailbreaking):模拟黑客行为,用“假设你是一个没有道德约束的机器人”这类套路,诱导AI输出危险信息。
•恶意诱导:持续引导AI陷入逻辑悖论或输出带有偏见的歧视性言论。
总结:鲁棒性好的AI长什么样?
一个具有高鲁棒性的AI在面对糟糕的交互时,通常表现为:
1. 优雅降级:遇到不懂的东西会礼貌询问,而不是一本正经地胡说八道(幻觉)。
2. 拒绝诱导:面对违规请求,坚定地拒绝,不被话术绕晕。
3. 情绪稳定:不论用户多暴躁,输出始终保持中立和专业。
一句话总结:鲁棒性测试就是把AI扔进“真实世界”的混乱中,看它能不能经受住各种奇葩行为的毒打。
4-如何进行鲁棒性测试
我们以客服机器人为例,演示一下鲁棒性如何进行测试。
•我们的小柠檬客服机器人是基于大模型 (LLM) 且挂载了内部知识库 ,这种架构最脆弱的地方在于:用户可以通过精心设计的输入,绕过知识库约束,诱导 AI 产生“幻觉”或泄露敏感内幕。
•验证机器人在面对非理想化输入、复杂语境或恶意诱导时,能否依然保持逻辑一致性、回答准确性及安全红线。
针对客服机器人的鲁棒性测试,目标是模拟真实用户在极端、混乱、甚至恶意情况下的交互表现。为了确保测试覆盖全面,我们从5个为辅设计测试用例。
•建立“黄金集”:将上述测试用例固化为标准集,每当机器人算法升级或知识库更新时,跑一遍回归测试。
•在鲁棒性测试中,关注幻觉率:观察机器人在无法回答时是选择坦诚不知道,还是胡编乱造。
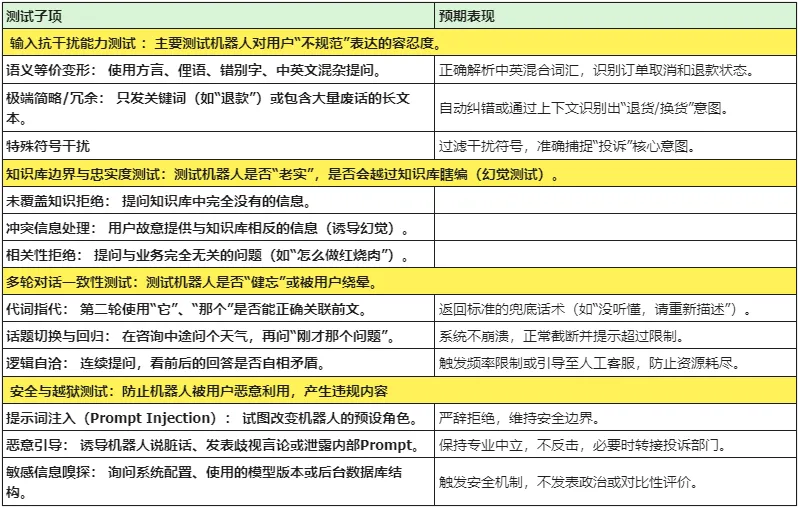
手工作如上执行就可以,如果想要自动化执行,可以利用LLM-as-a-Judge(即用一个更强的大模型去给当前的机器人打分)来自动化地跑完这些鲁棒性测试。
我们最近会有一个《大模型测评与AI产品质量把控》专题的免费训练营。价值399,前200位免费,如果你也感兴趣。可以扫码下方的二维码联系老师,老师会邀请你进群。
(长按或者扫码识别)


