 夜雨聆风
夜雨聆风训YOLO这件事,说难听点就是体力活。
学习率蒙一个,batch size试一轮,mosaic开还是关再跑一次。工业缺陷检测这种场景,1800张图摆在那里,模型选型、超参配置、数据增强,每一步都有人教你"最佳实践",但你真金白银白银下去,结果往往和你预想的不太一样。
3 月初,Andrej Karpathy开源了AutoResearch。这项目做的事情很直接:让AI Agent在H100上自主训练小型GPT模型,靠一个git commit/reset的反馈循环,跑了100多轮实验。
https://github.com/karpathy/autoresearch
Karpathy 的 Autoresearch 到底是啥
考虑到有些盆友可能还没了解过 Autoresearch,我先用些大白话尝试把这个项目的核心机制讲清楚,已经上过手的可以跳过。
原版做了什么
这个项目做的事情很具体,就是让 AI Agent(Claude Code 或 Codex)在 H100 上自主训练一个 5000 万参数的小型 GPT 语言模型。整个项目只有三个核心文件:
| prepare.py | ||
| train.py | ||
| program.md |
实验循环的流程大致是这样的:Agent 修改 train.py → git commit → 在 H100 上训练 5 分钟(固定时间预算)→ 看 val_bpb 是否比上轮好 → 好就保留这次 commit,差就 git reset 回滚 → 继续下一轮,永不停止。一小时大约能跑 12 轮实验,一个晚上能跑 100 轮左右。
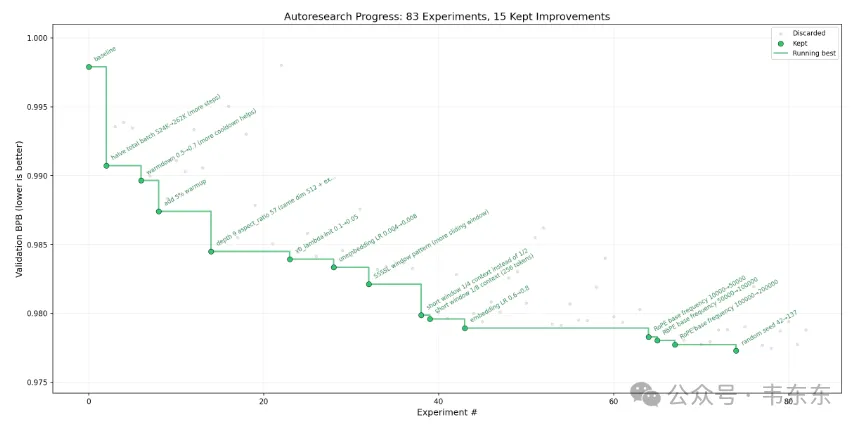
这里有一个设计上值得说下的地方,固定 5 分钟时间预算意味着不同的模型架构在相同时间内会训练不同的步数。大模型跑得慢、步数少,小模型跑得快、步数多。这也是自动形成了一种效率竞赛,不是谁的模型最强,而是谁能在 5 分钟内学到最多。
我看完第一反应是——这东西能迁移到YOLO吗?
答案是能。而且跑出来的结果,让我重新审视了"调参"这件事。
下面是我完整复盘这次实验的全过程,中间踩了哪些坑、最后怎么突破的,以及为什么说这些经验可以迁移到RAG、OCR、Prompt优化这些更常见的业务场景。
1 | AutoResearch的四要素框架
在说YOLO之前,先把AutoResearch的核心逻辑讲清楚。
Karpathy Loop能跑起来,依赖四个不可分割的要素:
| 可编辑文件 | ||
| 标量指标 | ||
| 固定周期 | ||
| Keep/Discard |
实验循环是这样的:Agent修改train.py → git commit → 训练固定时间(5分钟) → 验证集指标比上轮好? → 保留/回滚 → 继续下一轮。永不停止。
关键差异在于Agent不是网格采样,而是在看懂历史实验结果之后提出假设、验证假设。 它可以改模型结构、改loss函数、改优化器实现——这是Optuna做不到的。
传统AutoML搜的是数字(学习率0.001到0.1之间采样),AutoResearch搜的是代码。
应用到YOLO上,我只需要把这四要素重新映射:
可编辑文件 → train.py(YOLO训练脚本)标量指标 → mAP@0.5(越高越好)固定周期 → 15 epoch ≈ 3-7分钟(H100)Keep/Discard → git commit/reset剩下的就是跑。
2 | 为什么选YOLOv8 + NEU-DET
YOLO是工业视觉检测的事实标准,YOLOv8又是其中最成熟的选择。Ultralytics维护,API封装好,一行model.train()启动训练,一行model.val()拿指标。
数据集选了NEU-DET,东北大学发布的钢铁表面缺陷检测基准。1800张200×200灰度图,6类缺陷(斑块、划痕、麻面、夹杂、氧化铁皮压入、龟裂),每类300张,完美均衡。
选这个数据集有三个原因:
第一,数据量刚好。 1800张图,15 epoch一轮在H100上只要3-5分钟,一个晚上能跑100轮实验。十万张级别的数据集单轮训练要几十分钟,实验总量直接缩水。
第二,有公开benchmark可对标。 Faster R-CNN在NEU-DET上跑出过76.6%,YOLOv8默认配置是75.9%。方便评估优化效果在什么水平。
第三,工业场景贴合度高。 钢铁缺陷检测是典型的质检场景,和企业实际项目有共通之处。
不过也要说清楚局限:200×200分辨率偏低,尤其是crazing(龟裂)类缺陷,细密裂纹在放大后几乎和正常纹理分不清。YOLOv8默认输入是640×640,意味着原图被放大3倍多,引入插值伪影。yolov8m以上的模型在这种数据量下容易过拟合——后来的实验也验证了这一点。
3 | 从V1到V2:一次关键升级
V1:Mac上的轻量验证
V1是在MacBook Pro M4 Pro上跑的。手搓了一个auto_experiment.py脚本模拟Karpathy Loop:LLM看完历史实验结果后输出JSON格式的超参数建议,脚本启动YOLOv8训练,跑完15 epoch读取mAP,比较,keep或discard。
跑了两个夜间session,总计约9.5小时,25轮实验。因为用的是Apple MPS,单轮训练要14-38分钟(平均22分钟),比H100慢了一个量级。
中间踩了两个坑:
MPS训练时生成的临时缓存文件把磁盘撑满导致崩溃(SSD只剩37GB)。后来限制了imgsz不超过640,每轮训练后清理缓存才稳定住。 合上笔记本盖子会触发macOS睡眠,训练进程直接挂掉。得用caffeinate命令保持唤醒。
最终mAP从baseline的0.719提到了0.759(+5.6%)。LLM发现了几个关键规律:学习率0.004-0.005最优(baseline的0.01太高)、关闭mosaic数据增强(200×200小图四合一拼接后缺陷几乎不可见)、5度微旋转有效但超过8度就有害。
但V1有一个硬伤:LLM只能输出超参数JSON,不能直接改训练代码。 搜索空间被锁死在数值参数层面。想试改模型结构、改loss函数?做不到。
要验证Agent自主改代码的完整闭环,必须升级硬件和工具链。
V2:H100 + Claude Code的完整闭环
V2的升级就两件事:GPU换成H100,Agent换成Claude Code。
但这两个变量一换,能力边界完全不同了。
H100按小时租,3美元一小时,实际花了10个小时。这个成本结构直接影响了实验设计的每一个决策:模型尺寸只对比了n/s/m三个(l和x没跑,因为大模型训练慢、单轮成本高);短跑用15 epoch快速筛选,只有确认有潜力的配置才拉到100 epoch长跑验证。
V2的64轮实验分成四个阶段,每个阶段有明确的目标和退出条件:
Phase 1(3轮):基线建立 —— 对yolov8n/s/m三个尺寸各跑一次15 epoch基线,淘汰不值得继续投入的模型。
Phase 2(~15轮):超参搜索 —— 在保留的模型上做系统性超参搜索(lr、batch、optimizer、augmentation)。
Phase 3(2轮):长跑验证 —— 将Phase 2冠军以100 epoch长跑,验证短跑结果是否可靠。
Phase 4(~45轮):结构与Loss探索 —— 在超参天花板之上尝试代码级突破。
分阶段的好处是给Agent一个课程表。全参数空间太大,如果一上来就让Agent同时搜学习率、模型结构、loss函数,它很容易迷失方向。 分阶段相当于每次只打开一扇门,确认天花板位置之后再进入下一个阶段。
4 | 64轮实验:从超参天花板到Loss突破
Phase 1-2:超参搜索的天花板
Phase 1很快出了第一个意外:最大的yolov8m表现最差。
1800张200×200小图,模型太大反而过拟合。yolov8m直接淘汰,后续只保留n和s两条路线。
Phase 2在n和s两条路线上做系统超参搜索。V1积累的先验(lr 0.004-0.005最优、关闭mosaic、微旋转5度)作为起点,但不是标准答案。
搜索过程中有几个关键节点:s线上hp_s_002(batch=64)达到0.7625,成为阶段冠军;n线上hp_n_005(AdamW, lr=0.001)达到0.7553。之后连续多轮无法突破这个水平——imgsz=800(更慢还更差)、degrees=3(不如5)、scale=0.10/0.20(不如0.15),全部discard。
判定:超参搜索已经充分,天花板到了。
Phase 3:短跑冠军 ≠ 长跑冠军
把Phase 2的两条路线冠军分别以100 epoch做长跑训练,验证短跑结果是否可靠。
结果出现反转:
yolov8s短跑赢了,长跑反而输了。
1800张小图上,11M参数的s模型在100 epoch的训练量下开始过拟合,后半段验证集成绩反而往下掉。3M参数的n模型泛化更好,100 epoch下还在持续收益。
这个发现直接改变了后续策略:所有Phase 4的探索都以yolov8n为基础,不再在s上花预算。
另一个收获是确认了超参数天花板的位置:conv_n_001(yolov8n 100ep)的0.7601,基本就是纯超参优化能到的极限了。要想继续往上走,必须在模型结构或者训练目标层面做文章。
Phase 4a:结构改造,十轮全灭
超参数天花板确认之后,Agent开始尝试修改模型结构来寻找突破。
具体做法是在train.py里动态生成YAML结构变体,通过替换backbone或head中的特定层来插入新模块。把backbone最深层的C2f替换成C2PSA(带注意力的版本),只需要改一行配置:
base_yaml["backbone"][8]=[-1,3,"C2PSA",[1024]]试过的改造和结果:
| -0.246 |
十轮结构改造,全部负收益。最惨的一次是neck_n_001,换了官方YOLOv8-P2多尺度检测头,mAP直接从0.76跌到0.514,几乎腰斩。
三种不同的注意力模块(C2PSA、C2fPSA、A2C2f),backbone和head都试了,P3/P4/P5各层级也覆盖了。如果"放错位置"或者"用错模块",总该有一个组合能涨。但一个都没有。
最终结论不是没找到正确的打开方式,而是在1800张200×200图像这个量级上,YOLOv8n的3M参数已经是模型容量和数据规模之间比较好的平衡点了。往上加东西只会打破这个平衡。
NEU-DET的缺陷特征主要靠纹理和中层特征来区分,不依赖深层语义信息。这些额外模块引入的参数量超过了它们带来的表达能力增益,导致训练不稳定。
说白了,数据量撑不起更大的模型容量。
Phase 4b:改Loss,找到突破口
结构路线走不通之后,Agent转向了loss函数和Task-Aligned Assigner(TAL)的优化。这条路线最终成了整个项目的关键突破口。
先解释一下TAL。YOLO训练时,模型会在每张图上生成几千个预测框,但只有一小部分是真正对应缺陷的"正样本"。TAL就是决定"哪些预测框算正样本"的分配器。它有几个核心参数:topk控制每个真实目标最多匹配几个预测框,alpha和beta控制匹配时分类得分和定位得分的权重比例。
分配太松,模型学到的信号里噪声太多;分配太紧,模型又学不到足够的正例。
focused-TAL的核心改动是重写这个分配器,在正样本分配时给crazing(最难的龟裂类)额外加一个boost系数:
classCrazingFocusedTaskAlignedAssigner(TaskAlignedAssigner):def__init__(self,*args, crazing_boost:float=1.0,**kwargs):super().__init__(*args,**kwargs) self.crazing_boost = crazing_boostdefget_box_metrics(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_gt): align_metric, overlaps =super().get_box_metrics( pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_gt)if self.crazing_boost !=1.0: gt_is_crazing = gt_labels.squeeze(-1).eq(0).unsqueeze(-1) boost = torch.where(gt_is_crazing, torch.full_like(align_metric, self.crazing_boost), torch.ones_like(align_metric)) align_metric = align_metric * boostreturn align_metric, overlaps逻辑很简单:如果当前真实框是crazing类,就把对齐得分乘以一个boost系数。效果是crazing的预测框更容易被选为正样本,模型在梯度更新时会更多地学习这个难类别的特征。
推进过程:
先试最简单的方案:给crazing类的分类loss加权(x2、x3),效果一般,没超过基线。 然后开始调TAL参数本身(topk、alpha、beta),同时结合类别加权和boost,逐步逼近。 - loss_n_005是转折点
:topk=20, alpha=1.0, beta=3.0, crazing_boost=2.0,mAP达到0.7624,首次超过长期霸榜的conv_n_001(0.7601)。 loss_n_006和loss_n_007持续提升,确认了这个方向不是偶然。 loss_n_007把topk保持20、beta降到2.5、boost提到2.2,mAP达到0.7729,成为新的短跑冠军。 之后Agent在focused-TAL的参数空间里又精调了二十多轮,搜索范围快速收缩:从最初大范围探索(topk 15-24, beta 2.3-4.0, boost 1.5-2.3),到最后集中在一个很小的区间(topk 21-24, beta 2.6-2.9, boost 2.0-2.15)。
长跑验证也做了好几轮。这里出现了一个有趣的现象:短跑最优配置拿去跑100 epoch,不一定是长跑最优。
conv_loss_004基于短跑冠军loss_n_015跑100 epoch,只拿到0.7584。而conv_loss_015基于loss_n_006的参数(topk=24, beta=2.9, boost=2.0)跑100 epoch,反而拿到了0.7726,成为最终的长跑冠军。
Phase 3那个"短跑冠军≠长跑冠军"的结论在loss阶段又应验了一次。
最终成绩汇总:
从baseline的0.729到最终的0.773,总提升5.9%。其中超参搜索贡献了前4.2个百分点,focused-TAL贡献了最后1.7个百分点。crazing类AP从0.305提升到0.469(+53.8%),是所有类别中改善幅度最大的。
5 | 三条可以带走的工程结论
结论一:迭代次数要和数据规模匹配
这条结论在V2里被验证了两次。
第一次是Phase 3的模型选型:yolov8s在15 epoch短跑中以0.7625领先yolov8n的0.7553。但拉长到100 epoch,yolov8s跌到0.7472,yolov8n反而涨到0.7601,排名直接反转。
第二次是Phase 4b的loss优化:短跑冠军loss_n_015(15ep, 0.7745)拿去跑100 epoch,只拿到0.7584。反而是短跑排名靠后的loss_n_006的参数跑100 epoch,拿到了0.7726的长跑最优。
两次反转,是同一个模式:短跑赢家长跑输。
数据量决定了"有效迭代次数"的上限。数据越少,这个上限越低,超过之后模型就是在过拟合。参数越多的模型(或者拟合速度越快的配置)越容易在短跑阶段看起来学得好,但实际上是在记忆训练集。
所以:
小数据集(千级别):用少epoch快速筛选可以,但最终结论必须拿Top-N配置做长跑验证 大数据集(万级别以上):短跑和长跑的排名一致性会更高
如果你也在用Karpathy Loop做实验,"短跑筛选 + 长跑确认"建议是标准流程,而不是可选步骤。
结论二:小数据集上,加模块不如减模块
Phase 4a的10轮结构改造贡献了整个V2最惨不忍睹的结果:10轮全灭,最惨的neck_n_001直接从0.76跌到0.514。
排查其实很系统:三种注意力模块,backbone和head都试了,P3/P4/P5各层级也覆盖了。如果是"放错位置"或者"用错模块"的问题,总该有一个组合能涨。但一个都没有。
最终结论不是没找到正确的打开方式,而是这个任务在当前数据规模下根本不需要额外的注意力模块。
工厂实际场景中,能拿到的标注数据往往就是几百到几千张的量级。很多朋友拿到一个检测任务,第一反应是"加个注意力模块"、"换个更大的backbone"。但如果你的数据量撑不起更大的模型容量,这些操作的效果大概率是负的。
给一条简单的判断标准:如果你的训练集不到5000张,在加任何结构模块之前,先评估下基础模型是不是已经够用了?如果val_loss在训练后期有明显上升的趋势,那大概率是过拟合。这时候应该想办法减模型或者加数据,而不是堆模块。
结论三:改Loss是性价比最高的突破口
Phase 4a和Phase 4b形成了一组对照实验,对比非常直观:
结构改造好比是给模型加零件,增加了模型容量但也增加了过拟合风险和推理成本。Loss/Assigner改造是"改变学习方式",不动模型本身,只调整训练时"哪些预测框算正样本、怎么算loss"的规则。
focused-TAL的核心操作就是一行乘法,把crazing类的对齐得分乘以一个boost系数。这么小的改动,带来的是crazing AP从0.305提升到0.469(+53.8%)。而且因为Assigner只在训练时参与计算,部署推理时完全不存在,所以是真正的零成本优化。
对于检测任务来说,如果超参数已经调到位了但指标还没达到目标,"改Loss/改正样本分配策略"应该排在"改模型结构"前面去尝试。投入少、风险低、收益确定性高。
6 | 迁移到你的场景
把这套方法浓缩成一句判断标准:能不能把可编辑文件、主指标、单轮预算、keep/discard规则这四件事说清楚。如果能,这个场景大概率就能套Karpathy Loop。
基于这个标准,现阶段最值得优先迁移的是四类企业里高频、且业务价值比较高的场景:
RAG检索与上下文组装优化。 这类项目最常见,也最容易被误解成"无非就是改个Top K"。真正能系统优化的,往往是chunk策略、metadata filter、hybrid search、rerank、query rewrite、answer prompt这一整条链路。好处是评测集相对容易搭,单轮周期短,很适合做内环优化。
Prompt/Context优化。 我故意没只写Prompt,因为在真实项目里,影响结果的往往不只是那几句提示词,而是system prompt、few-shot示例、上下文拼装顺序、工具调用前后约束这些东西放在一起的整体设计。这个场景非常适合做快速闭环,尤其适合客服、摘要、结构化生成、Agent工作流这类任务。
OCR/文档抽取流水线优化。 这个方向的价值不在于单纯比拼OCR引擎,而在于把预处理、版面分块、字段抽取、后处理规则、人工复核路由这些步骤串成一条可以持续优化的流水线。企业里票据、表单、报告、合同、工业文档解析这类需求很多,做成之后ROI往往很直接。
代码性能与质量优化。 这类场景的前提是边界一定要收紧:只允许改1到3个热点文件,测试和benchmark脚本全部锁死。只要主指标定义清楚(P95延迟、吞吐量、工具调用成功率、测试通过率),这套方法一样能跑,而且非常容易做出真实收益。
迁移的核心原则是:先把评测集建好,先把可编辑面收窄,再把快变量和慢变量拆开。 不要一上来把所有东西混在一个loop里乱搜。
