 夜雨聆风
夜雨聆风
论文题目:GeoMMBench and GeoMMAgent: Toward Expert-Level Multimodal Intelligence in Geoscience and Remote Sensing
论文链接:https://arxiv.org/pdf/2604.08896v1
论文代码:https://geomm-agi.github.io
核心矛盾:多模态大语言模型(MLLM)在通用场景上跑得飞快,但一落地地球科学与遥感领域,就暴露出一堆问题。
新思路:RIKEN AIP、武汉大学等多所机构联合研究团队提出首个专家级、知识驱动的多模态评测基准GeoMMBench,以及多智能体协同框架GeoMMAgent,让MLLM真正具备地球科学专家的解读能力。人类专家在验证集上准确率86.5%;最佳闭源模型Gemini-1.5 Pro只有70.7%;而GeoMMAgent在测试集上达到88.4%,在验证集上与人类专家持平,显著超过所有单模型。
一、核心
多模态大语言模型(MLLM)在通用场景上跑得飞快,但一落地地球科学与遥感领域,就暴露出一堆“水土不服”。原因很简单:遥感数据涉及光学、雷达、高光谱、LiDAR、DEM……学科交叉从物理、数学到地理、制图,任务类型从理论原理到感知、推理再到具体应用——现有评测基本只盯着“这张图里有没有飞机”这种感知级问题,完全不够用。

GeoMMBench 核心设计:
- 多学科覆盖:遥感、摄影测量、GIS、GNSS四大核心学科,底层还涉及数学、物理、光谱学、地图学等。问题往往需要跨学科知识才能答对。
- 多传感器模态:光学RGB、多光谱/高光谱、SAR、LiDAR、DEM、热红外……模型必须能区分不同传感器,理解各自成像特性。
- 多层次任务光谱:从理论原理(如大气窗口、光谱曲线)、低层感知(图像质量评估、辐射/几何校正)、中层识别(场景分类、空间关系、变化检测)到高层应用(环境监测、农业、经济分析),形成一条完整的认知阶梯。
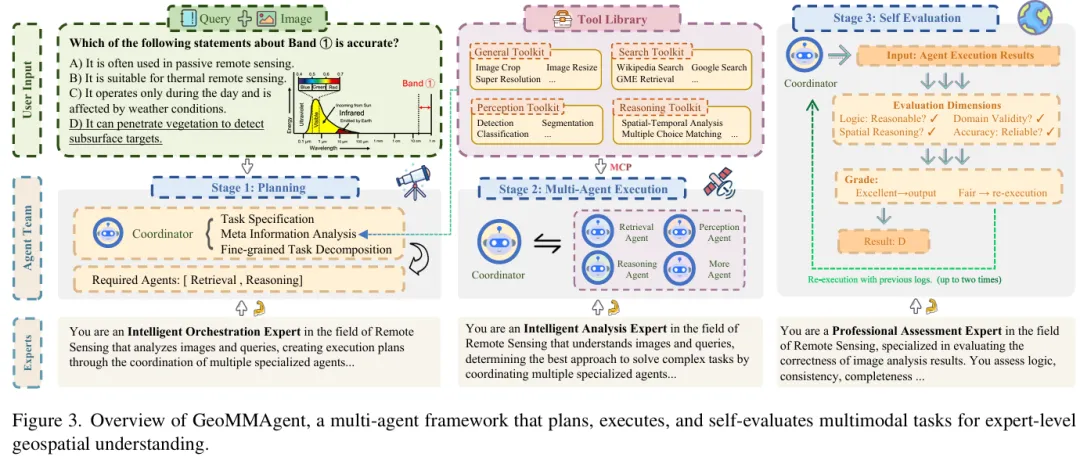
GeoMMAgent 核心设计: 面对GeoMMBench的挑战,单模型表现惨淡。于是团队构建了一个规划-执行-自评估的三阶段多智能体系统:
- 规划阶段:协调器解析图像+问题,分解为若干子目标,指定所需工具和调度顺序。
- 执行阶段:三个专门智能体分工——知识智能体调用Wikipedia、Google搜索、GME多模态检索;感知智能体调用场景分类、目标检测、语义分割等传统RS模型;推理智能体用Qwen-VL-Max做最终逻辑综合。
- 自评估阶段:检查推理链路和答案一致性,发现问题就触发重试或修正。
所有工具遵循MCP协议,即插即用,无需微调。
二、亮点
- 1053道专家级题目,每一道都“没图不行”
GeoMMBench不是从现有数据集里扒拉出来的,而是由遥感领域的博士/研究员团队手工出题,来源包括权威教材、学术文献和在线资源。每道题都经过严格同行评审,筛掉了那些“只看文字就能蒙对”的题目,确保真正考验多模态理解。最后还专门留了37道验证集用于人类专家测试,1016道测试集用来跑模型。 - 36个模型一测,发现问题比想象的多
团队评测了闭源(GPT-4o、Gemini-1.5 Pro、o1等)、开源通用(LLaVA、Qwen-VL、InternVL等)和遥感专用(GeoChat、TeoChat、LHRS-Bot等)共36个模型。结果遥感专用模型反而表现不佳,可能是它们的指令微调过于聚焦感知任务,缺乏推理和多学科知识。 - 错误分析挖出四大“病灶”
论文对GPT-4o和Gemini-1.5 Pro的错误做了细致解剖:- 视觉-语言错位:知识有,但视觉编码器没对齐。- 空间关系误判:看不懂图例和刻度。- 传感器模态混淆:把高光谱当成RGB,分不清SAR和光学。- 专业学科盲区:GIS、摄影测量里的基础概念也答不上来。 - GeoMMAgent:工具增强的智能体反超人类
GeoMMAgent在测试集上达到88.4%,在验证集上与人类专家持平(86.5%),显著超过所有单模型。消融实验显示:去掉推理模块,性能腰斩(88.4%→67.3%);去掉感知模块,掉到80.3%;去掉自评估,掉到80.1%。说明逻辑综合、外部感知工具和反思机制都至关重要。 - 案例拆解:可追溯的推理链条
论文完整展示了一个典型case。GeoMMAgent的推理过程:视觉分析定位波段在微波区 → 知识检索“微波穿透植被” → 初始答案选B(被动遥感),自评估发现证据不足 → 重新检索“微波穿透植被地下目标” → 确认D正确。整个链条清晰可追溯,而不是黑箱输出。
三、实验表现
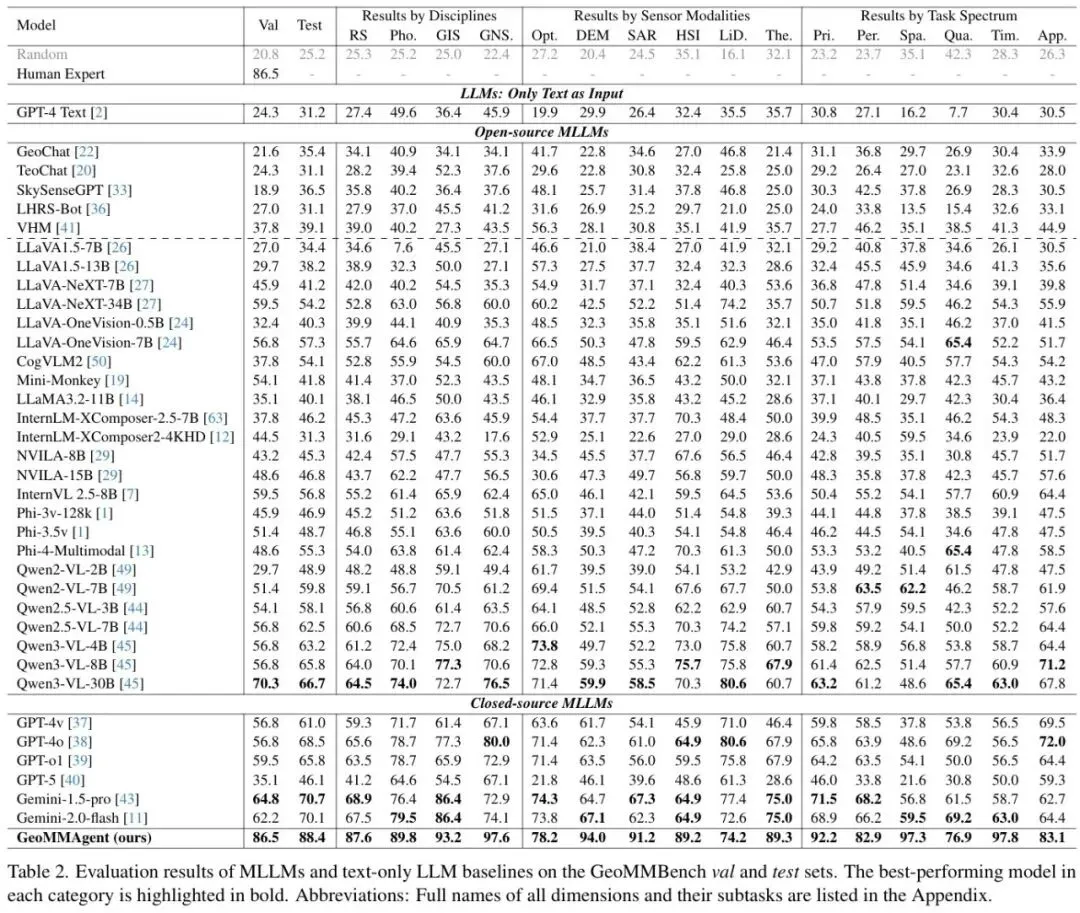

更多图表和详细数据请参阅原论文。
四、美中不足
- 基准的覆盖面和偏差
—— 虽然GeoMMBench已经是目前最全面的,但手工选题难免有采样偏差,不可能穷尽所有地球科学知识。比如SAR相关的题目相对较少,海洋、冰川等方向也涉及不多。 - 工具库目前以评测任务为导向
—— 集成的感知模型主要针对GeoMMBench中出现的任务类型,要扩展到更广泛的遥感应用还需不断接入新工具。 - 多智能体的计算开销
—— 一次推理要经过规划、多次工具调用、自评估甚至重试,延迟和成本明显高于端到端模型,对实时性要求高的场景可能不太友好。 - 未评估训练数据泄漏风险
—— 论文没有检查闭源模型是否在训练中见过GeoMMBench中的某些图片或知识点,虽然题目是专家新编的,但基础图像可能存在于预训练语料中。
五、启发
这篇工作最大的冲击是:评测先行,能力才跟得上。在遥感领域,一上来就想着“微调一个模型去做某类任务”,但如果没有一个像MMLU、MMMU那样的高水平、多学科、真多模态的评测基准,就不知道自己模型的真实水平——可能只是记住了训练集里的场景,换张图就崩了。GeoMMBench的意义在于,它第一次把遥感评测从“看图识物”拉到了专家级知识推理的层面。
另一个启发是:工具增强的智能体,比“更大更强的单模型”更靠谱。当GPT-4o和Gemini-1.5 Pro在70%左右挣扎时,GeoMMAgent通过调用专门的目标检测器、搜索引擎和多模态检索,直接飙到了88.4%。这说明在专业领域,让模型学会“用什么工具”比“把一切塞进一个黑箱”更有效。尤其是遥感这种数据格式多样、空间推理强依赖外部知识的领域,“检索+感知+推理”的分工协作可能是更务实的AGI路径。
最后,这个框架的自评估与重试机制也很值得借鉴。很多多智能体系统只是“一次性规划+执行”,错了就错了。GeoMMAgent加了一个反思环节,发现推理链条不完整就重新检索或重新推理——这种“知道自己不知道”的能力,才是迈向可信AI的关键。
📚 参考文献
[1] Aoran Xiao, Shihao Cheng, Yonghao Xu, et al. GeoMMBench and GeoMMAgent: Toward Expert-Level Multimodal Intelligence in Geoscience and Remote Sensing. arXiv: 2604.08896, 2026.
免责声明:本文内容基于个人理解,并结合AI辅助整理而成。由于个人分析能力有限,文中观点仅代表个人见解,仅供参考。如有疏漏或不足之处,敬请谅解。论文版权归原期刊或出版方所有,本账号不提供全文下载服务。如发现任何版权问题,请及时联系,将尽快处理。第三方如需转载,请保持内容完整并注明出处。对于第三方内容的准确性及其转载行为的合法性,本账号不承担任何责任。

