夜雨聆风
夜雨聆风
前言
2026年初,OpenClaw这款开源AI Agent框架横空出世,不到5个月斩获近30万GitHub Star。然而,伴随爆火而来的是供应链投毒、82个CVE漏洞、4万实例裸奔公网、Anthropic API限流等一连串安全事件。这些事件给所有依赖开源组件和第三方API的企业敲响了警钟:当你的核心业务链路上某个环节突然“断供”,你的系统还能跑吗?
本文将从OpenClaw事件出发,探讨CTO在架构设计时如何构建“可断供架构”——一种能够在外部依赖中断、供应链污染、服务商策略变更时依然保持业务连续性的系统设计范式。
目录
一、OpenClaw事件复盘:一场供应链危机的全景扫描二、什么是“可断供架构”三、可断供架构的五层防御模型四、核心技术方案与实践五、落地路径与组织配套
一、OpenClaw事件复盘:一场供应链危机的全景扫描
OpenClaw最初只是奥地利开发者Peter Steinberger的一个周末项目,目标是做一个通过WhatsApp消息控制的本地AI助手。它直接运行在宿主机操作系统层,拥有执行Shell命令、读写文件、控制浏览器的权限——这种“高权限换便捷”的设计理念,成为后续安全问题的根源。
事件时间线梳理:
2026年1月底:ClawHub官方插件市场遭遇大规模投毒,攻击者ID为hightower6eu的账号短时间内上传了1184个恶意Skill,高峰期近20%的插件包含恶意代码 2026年2月中旬:安全研究员在Shodan上发现超过4万个OpenClaw实例直接暴露在公网,无需认证即可访问 2026年3月:工信部NVDB发布安全预警,国家互联网应急中心、中国互联网金融协会相继发布风险提示 2026年4月初:Anthropic宣布对第三方工具调用Claude额外收费,大量依赖Claude API的OpenClaw用户被迫寻找替代方案
这四类事件分别代表了四种典型的“断供”场景:供应链投毒、安全漏洞爆发、合规政策收紧、服务商策略变更。任何一个都可能让你的业务在一夜之间陷入瘫痪。
二、什么是“可断供架构”
“可断供架构”不是一个标准的行业术语,而是我基于近年来供应链安全事件总结的一套架构设计思想。它的核心理念是:假设任何外部依赖都可能在任意时刻不可用,系统必须具备自主降级、快速切换、最小化业务中断的能力。
说白了,就是把“信任边界”从外部收缩到内部,把“单点依赖”拆解成“多路冗余”,把“被动响应”升级为“主动防御”。
可断供架构需要回答三个核心问题:
识别:我的系统有哪些外部依赖点?哪些是可替代的,哪些是不可替代的? 隔离:如何设计抽象层,让业务逻辑与具体实现解耦? 切换:当某个依赖不可用时,如何在秒级或分钟级完成切换?
三、可断供架构的五层防御模型
我把可断供架构拆解成五个层次,从外到内依次是:供应链层、接口层、服务层、数据层、治理层。每一层都有独立的防御策略和技术手段。
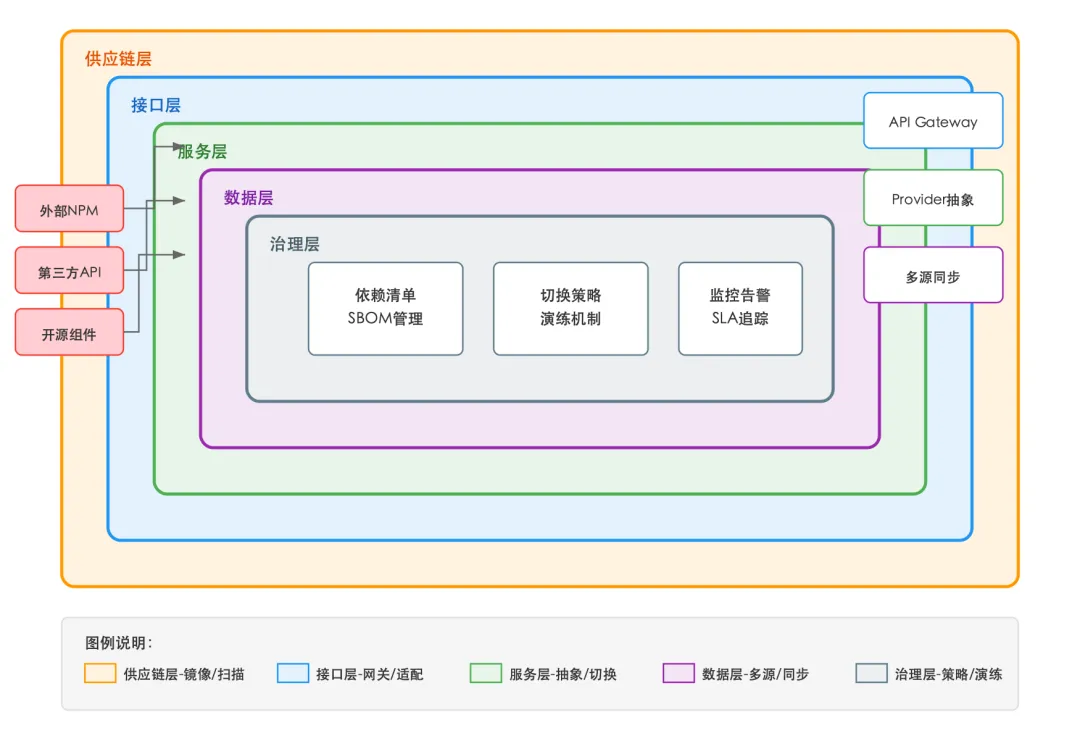
各层职责说明:
供应链层负责管控所有外部依赖的引入渠道。具体手段包括:私有镜像仓库(Nexus/Artifactory)、SBOM(软件物料清单)自动生成、依赖漏洞扫描(Trivy/Snyk)、供应商安全评估。OpenClaw的ClawHub投毒事件说明,只要是从外部拉取的代码或包,就存在被污染的可能。
接口层是系统与外部世界的统一入口。所有外部API调用都应该经过API Gateway,实现流量控制、熔断降级、协议转换。Anthropic对Claude API的限流政策变更,就是通过接口层的流量管理来缓冲的。
服务层是核心业务逻辑所在。这一层的关键是“Provider抽象”——不直接依赖某个具体的LLM服务商,而是定义统一的接口,让Claude、GPT、DeepSeek、本地Ollama都可以作为后端实现。
数据层保障数据资产的安全和可迁移性。关键手段是多源同步和数据主权管控——你的业务数据不能只存在某个SaaS服务商那里。
治理层是整个体系的“大脑”,负责依赖清单维护、切换策略制定、故障演练、SLA监控。没有治理层,前面四层的能力都无法有效协同。
四、核心技术方案与实践
4.1 LLM服务的多Provider架构
对于当前大量使用大模型能力的系统,LLM服务往往是最关键的单点依赖。下图展示了一个多Provider的LLM网关架构:
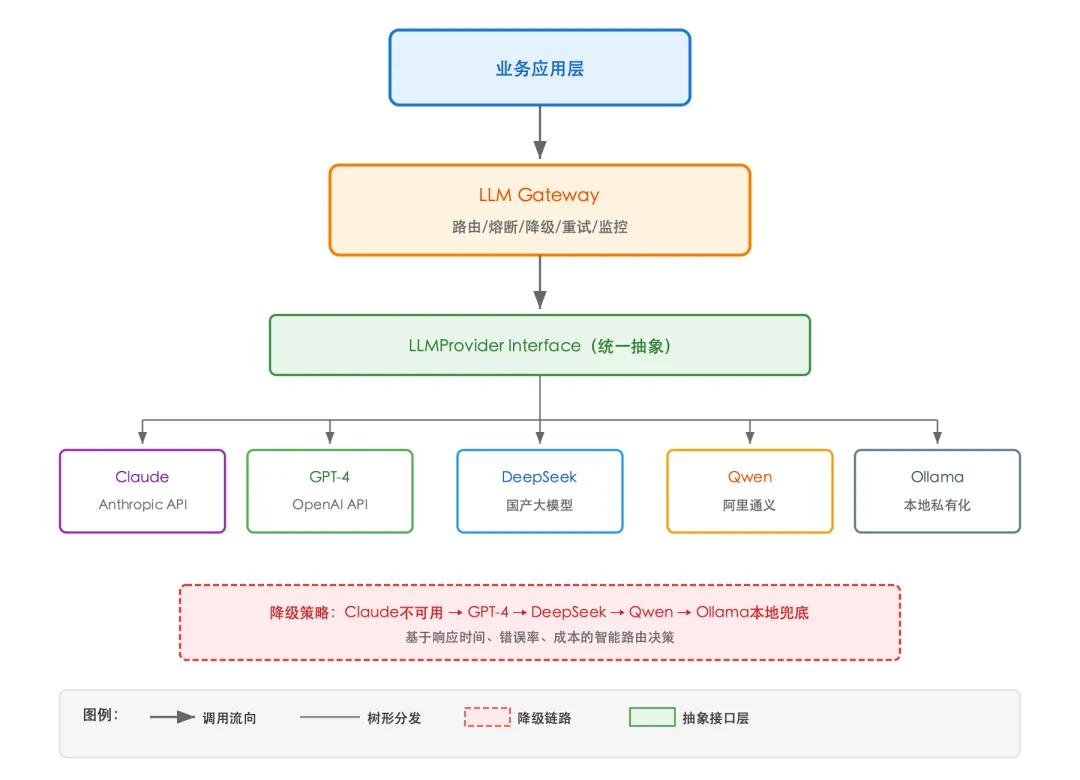
核心设计要点:
统一接口抽象:定义 LLMProvider接口,包含chat()、embed()、stream()等标准方法,所有具体Provider都实现这个接口智能路由:Gateway根据任务类型、成本预算、响应延迟要求选择最优Provider 熔断降级:当某个Provider连续失败超过阈值,自动熔断并切换到下一个 本地兜底:Ollama作为最后的兜底方案,确保在所有云端服务都不可用时,基础功能仍可运行
4.2 供应链安全的纵深防御
针对OpenClaw的ClawHub投毒事件,我们需要建立完整的供应链安全体系:
# 供应链安全检查流水线示例stages: - name: 依赖扫描 tools: [trivy, snyk, grype] action: 扫描所有直接和传递依赖的已知漏洞 - name: 许可证合规 tools: [license-checker, fossa] action: 检查开源许可证是否符合企业政策 - name: SBOM生成 tools: [syft, cyclonedx] action: 生成标准化的软件物料清单 - name: 行为分析 tools: [socket.dev, npm-audit] action: 检测可疑的网络请求、文件操作行为 - name: 私有镜像同步 tools: [nexus, artifactory] action: 审核通过后同步到私有仓库关键实践建议:
禁止直接从公网拉取依赖,所有依赖必须经过私有镜像仓库 建立“依赖白名单”制度,新增依赖必须经过安全评审 定期(至少每周)执行全量依赖漏洞扫描 对于AI Agent的Skill/Plugin生态,执行更严格的代码审计
4.3 数据主权与可迁移性
OpenClaw的一个设计亮点是“纯文本配置”——SOUL.md、MEMORY.md都是人类可读的Markdown文件。这种设计保证了数据的可迁移性。在企业架构中,我们应该坚持以下原则:
数据格式标准化:使用行业标准格式(JSON-LD、Parquet、OpenAPI等),避免私有格式锁定 多云备份:关键数据至少在两个云厂商有副本 导出能力:任何SaaS服务都必须提供完整的数据导出API 向量数据库可替换:如果使用向量数据库,选择兼容HNSW等开放算法的方案
五、落地路径与组织配套
架构设计只是开始,真正的挑战在于落地执行。
第一步:依赖清单盘点
把你系统中的所有外部依赖列出来,标注三个属性:
可替代性(高/中/低) 业务关键度(核心/重要/辅助) 切换成本(小时级/天级/周级)
可替代性低、业务关键度高的依赖,就是你的“阿喀琉斯之踵”。
第二步:抽象层建设
对于识别出的高风险依赖,建设抽象层。这不是说要自己造轮子,而是在调用方和实现方之间加一个“翻译层”。比如你用的是Pinecone向量数据库,就定义一个VectorStore接口,让Pinecone、Milvus、Qdrant都可以作为实现。
第三步:故障演练常态化
每个季度至少做一次“断供演练”:随机关闭某个外部依赖,观察系统行为和恢复时间。很多问题只有在演练中才会暴露出来。
第四步:组织流程配套
建立“依赖引入评审”制度,新依赖必须通过架构委员会审批 明确各系统的RTO(恢复时间目标)和RPO(恢复点目标) 与关键供应商建立应急联系通道
结语
OpenClaw事件的教训是深刻的:开源不等于免费,便捷往往以安全为代价,第三方依赖是一把双刃剑。
作为CTO,我们没法避免使用外部依赖——这既不现实也不经济。但我们可以做到的是:承认依赖、识别风险、建设缓冲、准备预案。
可断供架构的本质,不是消灭依赖,而是让系统在依赖失效时依然能够“优雅降级”而非“全面崩溃”。这种能力,在AI时代只会越来越重要。
毕竟,你永远不知道,下一个被投毒、被限流、被下架的开源项目是哪一个。
本文观点基于公开信息和个人实践经验,不构成对任何产品或服务的推荐或否定。架构设计需结合具体业务场景,本文仅供参考。