 夜雨聆风
夜雨聆风课程回放:https://waytoagi.feishu.cn/minutes/obcnsl82a9w9jelv3fi4318t?from=from_copylink
课程文件:https://waytoagi.feishu.cn/wiki/P8LFwR1deipZGlkfZyRcyzSrnQd
🔭 课程回顾
🦞 赛博永生虾:为什么只做空壳不够?
上节课我们讲了"赛博永生虾"的概念,重点是让 Agent 换壳不换脑。但这节课讲清楚了一个更残酷的现实:
- 只做赛博永生:你只是有了一个可以继承的空壳。
- 只做自动化运营:能力无法沉淀,每次都得重头搭。
所以真正的闭环是:赛博永生(能力沉淀和迁移) + 自动化运营(持续产生价值)。
整个赛博永生的核心链路依赖三块:
1. 数据载体:作为"中枢"的 AI 表格 / 多维表格 / 钉钉 AI 表格。 2. 能力资产:Skill 库(技能库) + 记忆库(百炼平台等)。 3. 运行载体:具体的 Agent(虾)。
核心观点:当这三层打通,你就不是在"养一只虾",而是在"积累一套资产"。哪怕环境变了、模型切了,下一只虾依然能原封不动地继承前代的"生前技能"和"用户记忆"。
⚙️ 运营的本质:条件 × 动作
说白了,自动化运营就是建立"输入条件 → 自动动作 → 结果输出"的稳定映射关系。你丢给它一张表,它自动分析、提炼、输出结论、生成看板,这就算是一个跑通的简单运营闭环。
📊 关键能力一:数据分析(打破幻觉的推演)
这是最容易踩坑的地方!很多人觉得大模型自带分析能力,为什么非要套个 Agent?
别把"推测"当"计算"!直接用大模型分析:它是在"猜"结果,遇到大数据量极容易产生幻觉,甚至编造不存在的趋势。
而在 Agent(如 OpenClaw)框架里:底层是通过 Python 脚本进行真实计算的。它的执行流是:生成代码 → 运行代码 → 拿到结果。模型能力越强,代码写得越准,分析才越可靠。
实战建议:涉及数据计算的场景,别省钱!直接上最强的模型,这直接决定了结果的死活。
🔄 关键能力二:SOP 变 Workflow
自动化解决的从来都不是"能不能做",而是"能不能连续 30 天稳定做"。
一个标准的内容运营 SOP(信息获取 → 内容处理 → 生成 → 发布 → 数据回收 → 复盘),如果全靠人工,必然会因为碎片化和疲惫感断更。上工具之前,先拆清楚你的流程。连这 6 步都理不顺,AI 也救不了你。
🚀 关键能力三:Skill 加速器
在跑通 Workflow 的基础上,我们要给每个节点加上加速器:
- 信息抓取类 Skill(比如视频下载、链接读取):把"找内容"的成本压缩到极致。
- 内容生成类 Skill(比如一键生成 PPT 排版):把干巴巴的数据自动渲染成专业汇报,提升"做内容"的效率。
这让一条原需一两小时的运营链路,被压缩到只要几分钟。
📈 关键能力四:监控看板(ROI 分析台)
没有监控的自动化,就是在跑"黑盒"。你不看着它,就不知道它跑了多少数据、烧了多少 Token、带来了多少转化。
必须让 Agent 在流程中顺手记录自己的动作,最终落到一张"多维表格监控看板"上。这才是你作为"老板"去评估一条 Workflow 值不值得留下的唯一依据(ROI)。
👥 关键能力五:从单兵到"数字团队"
当你拥有多个 Agent,有的抓内容、有的写文章、有的做复盘时,你就成了管理者。
这时候你需要设计的机制:
1 汇报机制:每个 Agent 必须有结果输出。 2. 信息同步:别让几个 Agent 在不同数据源里各说各话,底层数据必须同源(这就又回到了多维表格)。
📌 最后总结
说实话,这节课把 OpenClaw 的价值完全拔高了一个层级。前面 7 节课我们像是在攒装备(各种 Skill、对接平台),但这节课教我们怎么把装备穿成一套体系。
不要为了自动而自动
很多人自动化,很容易陷入一个误区:为了自动而自动。流程刚写了两步就急着调 API,结果一跑全是幻觉和错漏。其实就像课程里说的,SOP 拆解比写 prompt 重要一万倍。
如果你自己人工都没跑通一个完整的闭环(找素材、处理、发布、看数据),直接丢给 Agent,它只会十倍速地给你放大错误。
另外,多维表格作为数据中枢的地位不可动摇。不要试图让 Agent 用脑子记住所有事,其实最稳的做法就是:它只负责跑腿和算数,所有的记忆、技能库、中间数据,全部死死地钉在多维表格或者百炼这样的外挂记忆库里。
铁打的表格,流水的虾~
✏️ 作业
微信公众号多角色 agent 运行系统
这个也算是基于我自己的一个运营需求吧,对于微信公众号这种需要从热点挖掘、长图文撰写到最终排版发布的复杂业务,我们可以利用 OpenClaw 的"最小可行代理三角(Captain + Executor + Critic)"架构来设计这套多角色系统 。
我的一个设计思路如下:
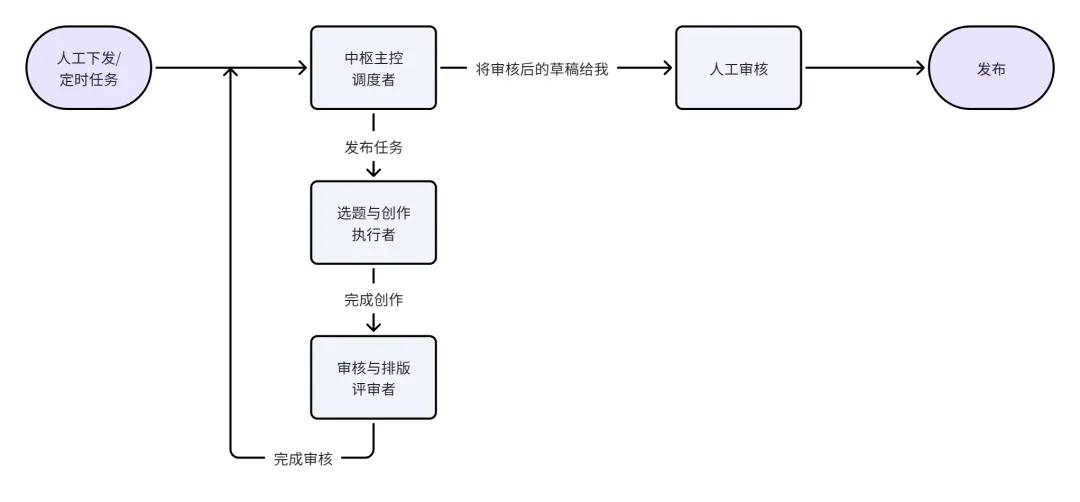
这套系统划分出了三个角色:调度者、执行者与评审者。
中枢主控 Agent(Captain/调度者)
这是整个运营系统的"大脑",也是我在微信端唯一直接对话的角色 。
因为这是一个主控角色,所以我会为其配置能力较强的推理模型,负责接收我的任务(例如"今天写一篇关于苹果发布会的文章"),并将其拆解为具体的可执行子任务 。
它的 SOUL.md 我将其定义为"自媒体主理人",拥有任务路由权限,能够在下达指令后跟进下游 Agent 的进度,并在各环节完成后向我汇总最终结果 。
选题与创作 Agent(Executor/执行者)
该角色的核心职责是资料检索与文案生成 。
在技能(Skill)配置上,它需要绑定网页搜索、Google Trends 趋势抓取和文章读取等工具 。如果有需要,则还要添加类似 deep-research 这样的上下文处理技能。
在收到主控 Agent 拆解的任务后,它会自动抓取全网相关热点资料,并根据我"调教"好的,在 SOUL.md 中的"个人风格"(最近爆火了一个"同事 skill",正好可以拿来蒸馏一下自己)和"爆款结构框架"生成初稿 。
为了降低成本,这个跑脏活累活的 Agent 可以配置轻量级模型或本地 Qwen 模型 。
审核与排版 Agent(Critic/评审者)
这个 Agent 扮演"责任编辑"的角色,把控最终的输出质量和发布流程 。
它接收到创作 Agent 的初稿后,会根据公众号的受众定位进行敏感词过滤、逻辑校验以及字数压缩 。并对生成出来的内容进行"交叉验证",确保内容来源可靠。
同时,它需要绑定基于 Make/Notion 的图文匹配技能和微信公众号后台的 API 发布技能 。它会在微信中将定稿排版预览发送主控 Agent,由主控先行审核一遍,确认没太大问题后再给我确认,并在我确认后一键将内容推送到公众号草稿箱 。
最终整个系统的实践路径就是:
基于我的个人数据,以任务拆解(SubAgent)机制串联"主控规划-研究创作-审核排版"三个专业角色,并利用定时任务与微信接口实现"自动生稿到人工一键分发"的极具个人风格的高质量内容产出流水线。
