 夜雨聆风
夜雨聆风
AI 正在重塑世界。与此同时,它也制造了一套让人头大的黑话体系:AGI、LLM、RAG、思维链、幻觉……这些词在公司会议室、投资人 PPT、科技媒体里铺天盖地,却鲜有人说清楚他们是什么意思,以及这对投资判断意味着什么。
这篇文章编译自 TechCrunch 的 AI 术语词典,覆盖当前最核心的 20 个 AI 概念。每个术语给出两个视角:一是「官方定义」,帮你搞清楚这个词在技术上到底在说什么;二是全息士自己的「投研视角」和「技术尽调」,帮你看清楚这个词在资本市场上意味着啥,有什么弦外之音。
不需要工程背景,但读完之后,下次再有人说出这些词,你至少知道该问什么问题。
1. AGI(通用人工智能)
官方定义: AGI 即 Artificial General Intelligence,是 AI 领域最重要、也最模糊的概念之一。
Sam Altman 的版本是「一个你可以雇来当同事的中等水平人类」;
OpenAI 官方章程写的是「在大多数有经济价值的工作上超越人类的高度自主系统」;
Google DeepMind 则定义为「在大多数认知任务上至少与人类持平的 AI」。
三家定义各不相同,且没有任何一家给出可量化的达标标准——这意味着「AGI 实现了」这句话,可以在任何时间点被任何人宣布。
投研视角: AGI 更像是一个「长期期权」,而非短期可验证的里程碑。在实际投资中,更重要的是判断在当前技术路径下,哪些环节已经开始兑现商业价值(例如算力、工具链和应用层),即「卖好铲子」。
2. AI Agent(AI 智能体)
官方定义: AI Agent 是能代替人类自主执行一系列任务的 AI 系统,远超普通聊天机器人的能力边界。
它可以调用外部工具、访问数据库、与其他 AI 系统协作,完成报销、订票、写代码、管理日历等多步骤任务,全程无需人工干预。Agent 的核心特征是「自主+多步」——你告诉它目标,它自己规划路径。
目前这个领域的基础设施仍在快速演进中,不同公司对 Agent 的定义和实现方式差异很大,从简单的工具调用,到多 Agent 协作都被称为 Agent。
投研视角: Agent 被很多投资人当成 SaaS 3.0,从「提供工具」转向「直接交付结果」。Salesforce、ServiceNow、Uipath 全部在 All in Agent,一夜间 SaaS 公司都变成了 AI Agent 公司。
看财报时需要关注 Agent attach rate,即多少老客户买了 Agent 模块。这个渗透率超过 30% 才算转型成功。
另外记住:Agent 如果「查信息」弄错了,用户可能只是皱皱眉;如果「执行操作」弄错了,可能直接删库。
技术尽调:投前让创始人现场 demo 「订一间明天香港四季酒店+开发票」,卡住就撤。
3. Chain of Thought(思维链)
官方定义: Chain of Thought(CoT)是一种让大语言模型「一步一步想」的推理技术。
标准 LLM 直接从输入跳到输出;CoT 则让模型先生成中间推理步骤,再得出最终答案——就像人类解复杂题时需要打草稿。
研究表明,CoT 在数学推理、逻辑判断、代码生成等任务上能显著提升准确率。现在的推理模型(如 OpenAI o3、DeepSeek R1)本质上就是在思维链上用强化学习大规模优化的产物,「让模型多想一会儿」已经成为提升 AI 能力的核心路线之一。
投研视角: CoT 是 AI 应用公司毛利率的隐形杀手。开了 CoT,token 消耗暴涨 5~10 倍,成本从 $0.03 直接跳到 $0.3 / 千 tokens。
做量化、法律、医疗的 AI 公司,如果不开 CoT,准确率太低,客户不会续费。但开了 CoT,算力成本又覆盖不了客单价。所以 2025 年死了一批“AI 投研助手”,就是 CoT 成本算不过账。
技术尽调: 问「你们怎么平衡 CoT 精度与成本?」
答「缓存 + 投机解码 + 小模型路由」的,及格。
4. Compute(算力)
官方定义: 算力泛指驱动 AI 模型训练和运行所需的计算能力,既是抽象概念,也指 GPU、CPU、TPU 等具体硬件资源。
训练一个大型模型需要数千块 GPU 连续运行数周;推理(即模型上线后响应用户请求)则是持续性的算力消耗。
算力是整个 AI 产业的「燃料」,也是当前全球科技竞争中最稀缺的战略资源之一。美国对华芯片出口管制的核心,本质上就是对算力的管制。
投研视角: 算力是 AI 时代的「房地产」,英伟达是最大的地主。两年前的全球算力荒时,AI 公司估值 = 拿到的 H100 卡数 × 100 万美金。
但房地产有周期性—— H100 曾经一卡难求,现在 GPU 租赁价格已经在悄悄松动。投国产 AI 前还要先看「国产算力适配进度」。
技术尽调: 问「你们算力怎么解决?」
答「和云厂商签了长期协议,单位推理成本降到 $X」的,属于有备而来。
5. Deep Learning(深度学习)
官方定义: 深度学习是机器学习的一个子领域,核心是由多层人工神经网络构成的模型结构,灵感来自人脑神经元的连接方式。
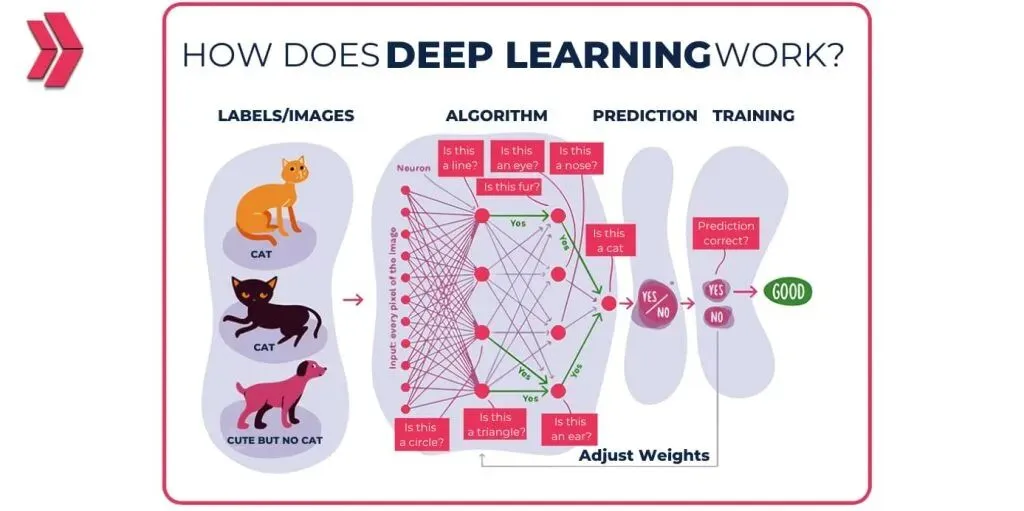
与传统机器学习需要人工设计特征不同,深度学习能够从原始数据中自动提取复杂规律,并通过反向传播算法从错误中迭代优化。它是图像识别、语音识别、自然语言处理等几乎所有现代 AI 应用的技术底座。
代价是对数据量、算力和训练时间的要求极高,且模型内部的决策过程往往难以解释——这也是「AI 黑箱」问题的根源。
投研视角: 深度学习在投资叙事里已经是「基础设施层」,不再性感,就像餐厅不会特意说「我们用了火」。现在值得问的是:谁手里有别人拿不到的专有数据?
Bloomberg 的金融语料、Epic 的医疗记录、Palantir 的政府数据——这些才是下一阶段的护城河。大模型会越来越便宜,数据不会。
技术尽调: BP 里写「我们用深度学习颠覆 XX」,是 2016 年话术。
2026 年要问「你比 Transformer 强在哪?」答不出来就是套壳。
6. Diffusion(扩散模型)
官方定义: 扩散模型是当前图像、音频、视频生成 AI 的主流技术路线。其原理来自物理学中的扩散现象:先对原始数据(图片、音频等)逐步添加随机噪声,直至完全「损毁」;再训练模型学习「去噪」的逆过程,从而掌握从纯噪声中生成新内容的能力。
Midjourney、Stable Diffusion、DALL·E、Sora 的底层都用到了扩散模型。它的优势是生成质量高、多样性强;劣势是推理速度相对较慢,计算成本较高。
投研视角: 扩散模型技术本身已高度开源,真正的竞争已转移到数据授权(谁的训练集合法)和产品分发(谁离用户更近)。
Adobe Firefly 主打「商用安全」,这才是企业客户愿意付费的理由——因为不怕被 Getty 起诉。对于商用 AIGC,版权 > 效果。
技术尽调: 问「你们训练数据的版权怎么处理?」
答「授权数据集 + 内容溯源机制」的,至少法务部门能睡着觉。
答「爬的网上数据」的——尽快走人。
7. Distillation(蒸馏)
官方定义: 模型蒸馏是一种「以大带小」的训练技术:用一个已经训练好的大模型(称为「教师模型」)的输出,来训练一个更小、更轻量的模型(称为「学生模型」),使小模型在更低成本下尽量逼近大模型的表现。
蒸馏可以大幅降低模型的推理成本和部署门槛,是当前边缘端 AI 部署的核心技术之一。值得注意的是,用竞争对手的模型输出来蒸馏自己的模型,通常违反对方的服务条款——这在法律上仍是灰色地带,虽然大家都这么做。

投研视角: 自研大模型属于重资产,估值 10 x PS,蒸馏模型属于轻资产,估值 1 x PS。
蒸馏模型没壁垒,但「蒸馏 + 私有数据微调」有。Harvey.ai 通过蒸馏 GPT-4 再喂法律数据,客户律所愿意付 10 万美金/年。纯蒸馏模型,变不了现。
对投资人来说,蒸馏技术意味着领先模型的技术优势衰减速度比想象中快得多。护城河不在大模型本身,在于数据、分发和生态。
技术尽调: 问「你们的模型是自研还是蒸馏的?」
答「基于开源模型 + 自有数据微调」的,诚实加分。
答「完全自研从头训练」的——好,那我们来对一下 GPU 小时数和训练成本,看看账能不能对上。
8. Fine-tuning(微调)
官方定义: 微调是在已有大模型基础上,用特定领域的数据进行进一步训练,使模型在目标任务上表现更好的技术。
与从头训练相比,微调所需的数据量和算力要少得多,是目前 AI 应用层创业公司最常见的技术路线。
微调可以让通用模型「专业化」——比如用法律文书微调出法律 AI,用医疗记录微调出医疗 AI。但微调的效果高度依赖数据质量,「垃圾数据微调出垃圾模型」是这个领域最常见的坑。
投研视角: 微调是 AI 应用层最常用的技术路线,却也是壁垒最薄弱的一环。
如果核心竞争力只是「我们把 Kimi 2.5 或 Qwen 3.5 微调得更好」,那当基础模型迭代或价格大幅下降时,护城河又在哪里?
Harvey(法律 AI)、Abridge(医疗 AI) 等公司能维持高估值,靠的从来不是微调技术本身,而是微调后积累的客户工作流数据与领域专有知识——这才是真正难以复制的壁垒。
技术尽调: 问「如果基础模型厂商直接进你的垂直领域,你怎么办?」
答「我们有 X 年客户数据 + 工作流集成,迁移成本极高」的,有防御性。
答「我们会继续微调更新的模型」的——本质上是在给 OpenAI 打工,还是免费的那种。
9. GAN(生成对抗网络)
官方定义: GAN 即 Generative Adversarial Network,由两个相互博弈的神经网络组成:「生成器」负责造假,「判别器」负责鉴别真假。
两者在对抗中共同进化——生成器不断提升造假水平,判别器不断提升识别能力——最终使生成内容达到以假乱真的效果。
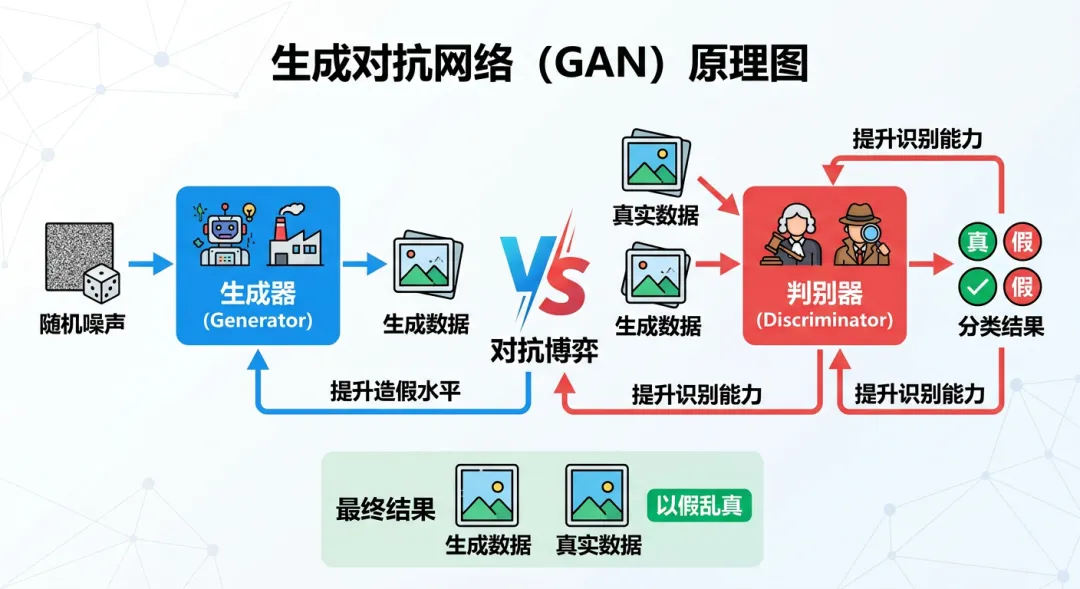
GAN 是深度伪造(Deepfake)技术的早期核心,但目前在图像生成领域已基本被扩散模型取代。
投研视角: GAN = Deepfake。2024 年香港「假 CFO 视频诈骗」 2 亿港币后,全球银行 KPI 加了「反 GAN」。
GAN 催生了身份验证赛道(liveness detection、数字水印)的真实需求。iProov、Jumio 这类公司本质上是在卖「GAN 的解药」,欧盟 AI Act 的合规要求正在把监管压力转化成这条赛道的收入。
而投「GAN 生成」公司则是监管地雷。
技术尽调: 做 GAN 生成的公司,2026 年 PS 只有 2x。
做 GAN 检测的,PS 10x。
攻防转换,钱在防守方。
10. Hallucination(幻觉)
官方定义: AI 幻觉指模型「一本正经地胡说八道」——生成看起来合理、格式正确,但实际上完全错误的信息。
这是当前所有大语言模型的固有缺陷,根源在于模型的本质是「预测下一个最可能的词」,而非「检索事实」。
幻觉可以是细节错误(错误的日期、数字),也可以是完全捏造的引用、人名、法律条文。
几乎所有 AI 产品的用户协议里都有一行小字:「请自行核实 AI 生成内容」——但没人会在按下发送键之前去读那行字。
投研视角: 幻觉是 B2B AI 销售周期长的核心原因之一。
金融、法律、医疗对幻觉容忍度接近于零,因为这是涉及到钱袋子或人命的。2023 年纽约法院真实发生过律师用 AI 写了引用不存在判例的诉状,直接被法官罚款。
当下甚至做「幻觉保险」的公司都出现了:AI 输出造成损失,保险赔付。Lemonade、Lloyd’s 都在看。
幻觉率从 5% 降到 1% 容易,从 1% 降到 0.1% 极难,这个「最后一公里」的成本,是高风险行业 AI 落地最大的障碍,也是 RAG + 幻觉检测赛道的核心机会。
技术尽调: 问「你们的幻觉率是多少?」
答「我们有行业基准,幻觉率 < X%,有实时检测机制」的,认真对待。
答「我们通过优化提示词工程,幻觉已大幅降低」的——纯忽悠。
11. Inference(推理)
官方定义: Inference 是 AI 模型「上岗干活」的过程——训练完成后,模型接收用户输入、生成输出的实际运行阶段。每次你向 ChatGPT 发送消息,背后就是一次推理。
推理可以在各种硬件上运行,从手机芯片到云端 GPU 集群,性能和成本差异巨大。
推理速度(延迟)和推理成本(每次调用的算力消耗)是 AI 产品体验和商业模型的两个核心变量。随着 AI 应用规模化,推理成本占总算力支出的比例正在持续上升。
投研视角: 推理是 AI 产业链里增长最快的环节。
训练是一次性成本,推理是持续性成本,有估计推理已占总算力支出的 60% 以上。英伟达 70% 收入已来自于推理。
Groq 用定制 LPU 把推理速度提升 10 倍,Cerebras 靠晶圆级芯片打低延迟。
2026 年,AI 应用公司能否赚钱,越来越取决于推理效率——包括延迟、吞吐和单位成本,而不仅仅是模型能力本身。
MoE、投机解码、量化,都是为了降推理成本。
技术尽调: 问「你们单次推理成本是多少?」
答「量化 + 批处理优化,成本降到 $X / 千次调用」的,及格。
答不上具体数字的——那对方的财务模型大概是用信念支撑的。
12. LLM(大语言模型)
官方定义: 大语言模型是 ChatGPT、Claude、Gemini 等 AI 助手的底层引擎。本质上是由数十亿乃至数千亿个数值参数构成的深度神经网络,通过对海量文本数据的训练,学习词语、句子和概念之间的复杂关系,构建出一张「语言的多维地图」。
每次生成回复,模型都在基于上下文预测「下一个最可能出现的词」,不断重复,直到输出完整答案。
LLM 的能力边界取决于训练数据的规模和质量、模型参数量,以及训练方法——这三个变量的组合,决定了不同模型之间的能力差异。
投研视角: 2026 年,闭源 LLM 公司 50 x PS,开源 LLM 公司 5 x PS,应用层 10 x PS。模型层已成红海,应用层才开始。
Scale AI 2023 年融资 BP 里写“不做基础模型”,结果估值 130 亿美金;Inflection AI 自研模型失败,烧光 15 亿美金后只能卖身。
技术尽调: 问「你们做的到底是 LLM,还是应用?」
答「我们要做最好的 LLM」或者「我们是通用大模型公司」的,赶紧看看团队里有没有图灵奖获得者,没有就走人。
答「用 LLM + 私有工作流 + 专有数据,在垂直领域里做深」的——值得看。
13. Memory Cache(内存缓存)
官方定义: 缓存是一种推理优化技术,通过保存已经计算过的中间结果,避免对相同内容的重复计算,从而提升响应速度、降低算力消耗。
在 LLM 中最常见的是 KV 缓存(Key-Value Cache),广泛应用于 Transformer 架构,能显著减少生成每个 token 所需的计算量。对于长上下文场景(如分析一份 100 页的合同),有效的缓存策略可以将推理成本降低 60% 以上。
Anthropic 和 OpenAI 都已推出 prompt caching 功能,按缓存命中率向企业客户提供折扣。
投研视角: 缓存是 AI 基础设施里最「闷声发财」的技术——不性感,但直接影响毛利率。KV Cache 做得好,推理成本降 80%。DeepSeek 能把 API 价格卖到 OpenAI 的百分之一,靠的就是 3 级缓存。
1M 上下文长度下,KV 缓存往往会占用高达数百 GB 的显存,成为长上下文部署的最大瓶颈。
谁能大幅压缩 KV 缓存(结合量化、稀疏注意力等技术),谁就能显著降低长上下文的推理成本和显存需求,这也是 MiniMax 高估值的逻辑之一。
技术尽调: 问「你们的缓存命中率是多少?」
答「语义缓存命中率约 X%,推理成本降低了 Y%」的,工程扎实。
答「我们用云厂商默认配置」的——相当于开着空调开着窗,钱烧得很有仪式感。
14. Neural Network(神经网络)
官方定义: 神经网络是深度学习的算法底座,也是整个生成式 AI 浪潮的技术根基。其设计灵感来自人脑神经元的连接方式:由大量相互连接的「节点」(人工神经元)组成多层结构,每层负责提取不同层次的特征。
这个概念早在 1940 年代就已提出,但真正爆发是因为 GPU 的普及——游戏产业催生的图形处理芯片,意外成为训练深层神经网络的完美工具,直接解锁了语音识别、图像识别、自动驾驶、药物发现等一系列应用。
神经网络的「深度」(层数)是深度学习名称的由来。
投研视角:2012 年深度神经网络 AlexNet 用 GPU 训练成功后,英伟达开启了长达十余年的超级牛市。过去十几年,AI 的每一次技术浪潮,几乎都是硬件先行、硬件吃肉。
因此在投资 AI 时,硬件链(英伟达、台积电、HBM、先进封装)往往是更确定性的 beta,而算法和应用则是更高风险、更高回报的 alpha。
从终局来看,当前的神经网络架构大概率并非智能的最终形态,状态空间模型(SSM)、脉冲神经网络(SNN)等新范式已在悄然追赶。但在未来 5–8 年内,Transformer 凭借深厚的生态壁垒,仍将是绝对主流。真正的投资机会,在于看清「当前谁吃肉」与「未来谁可能颠覆」之间的时间差。
15. RAG(检索增强生成)
官方定义: RAG 即 Retrieval-Augmented Generation,一种把“搜索”和“生成”结合的技术。
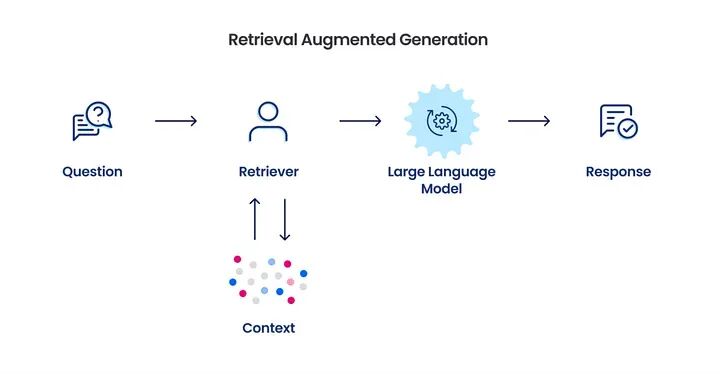
大模型回答问题前,先去你指定的知识库里检索相关文档,把搜到的原文片段塞进 prompt,再让模型基于这些材料组织答案。目的是减少幻觉,也让 AI 能够处理训练截止日期之后的最新信息,以及模型从未见过的私有数据。
RAG 是目前企业 AI 落地主流技术。
投研视角: RAG 解决了一个真实的企业痛点:公司内部文档、合同、财报——这些数据 LLM 没有训练过,但员工每天都需要查。
Glean、Notion AI 的核心卖点就是这个。向量数据库赛道(Pinecone、Weaviate)因此受益,成为 RAG 架构的基础设施层。
但 RAG 的质量高度依赖检索准确率——「垃圾进,垃圾出」的问题依然存在。
技术尽调: BP 里只写「我们用RAG」的,估值先砍一半,直接问「PDF表格怎么拆、跨页上下文怎么保、时效性怎么更新」。
然后让创始人当场测「公司去年 Q3 财报第 5 页讲了啥」,答不对,RAG 就是玩具。
16. RAMageddon(内存末日)
官方定义: RAMageddon 是媒体和业界分析师新造的词,描述 AI 数据中心对 RAM 芯片需求的爆炸式增长所引发的全球内存供应紧张局面。
训练和运行大型 AI 模型需要消耗大量高带宽内存(HBM),这种需求的急剧攀升正在挤压整个内存市场的供给。
受波及的不只是 AI 行业——游戏主机、智能手机、企业服务器都在承压,这可能导致近十年来最大幅度的智能手机出货量下滑。
投研视角: SK 海力士(存储巨头)因为提前押注 HBM3E,成为英伟达 H100/H200 的核心供应商,股价在 2023 ~ 2024 年翻倍。
对消费电子投资人来说,内存价格上涨是双刃剑:内存厂商利润率改善,但下游手机等厂商 BOM 成本上升。
技术尽调: 问「你们的内存供应链怎么保障?」
答「和 SK 海力士签了长期协议,锁定了未来 X 季度的 HBM 配额」的,值得看。
17. Tokens(词元)
官方定义: Token 是 AI 处理语言的基本单位——像是一个「词的碎片」。
一段文字在进入 LLM 之前,会被「分词器」切成一个个 token:英文中一个单词通常对应 1~2 个 token,中文则因语言结构不同而有所差异。
Token 既是输入单位(你发给模型的内容),也是输出单位(模型返回的内容),还是计费单位——几乎所有 AI API 都按 token 数量收费。
上下文窗口(Context Window)的大小,决定了模型在一次对话中能处理的最大 token 数量,直接影响模型处理长文档的能力。
投研视角: 过去两年,主流模型的 token 价格下降超过 90%,对 AI 应用公司是利好,对基础模型公司是压力。
值得注意的是:企业客户在做 AI 预算时,实际 token 消耗往往比预期高出 3~5 倍——这是 AI 项目超支最常见的原因,也是很多 AI 应用公司毛利率不及预期的直接解释。
技术尽调: 所有成本、收入、性能,最终都要换算成 $/M tokens。投 AI 前先学会 token 算术。
上下文 8K tokens,只能做客服。
128K tokens,能读财报和法律文本。
1M tokens,能审复杂合同和企业知识库。
模型上下文长度决定 TAM(总目标市场规模)的天花板。
18. Training(训练)
官方定义: 训练是 AI 模型「从无到有」的过程:将大量数据输入模型,让它从中学习规律,通过反复调整内部参数(权重),逐步提升在目标任务上的表现,直到达到可用水平。
训练前的模型只是一堆随机数字;训练后,它才真正「成型」。
训练大型模型需要数千块 GPU 连续运行数周乃至数月,成本动辄数千万乃至数亿美元,是 AI 公司最重要的资本支出之一。训练数据的质量和规模,在很大程度上决定了模型的能力上限。
投研视角: GPT-4 训练成本据估计超过 $1 亿,GPT-5 超过 $5 亿。能领导大模型训练的牵头人,全世界不超过 100 人。这道门槛把大多数竞争者挡在门外。
但 DeepSeek 用 $600 万训练出接近水平的模型,让这个叙事出现了裂缝。
当训练成本持续下降,应用层的机会窗口会打开,但基础模型层的竞争会更加惨烈。
技术尽调: 看对方负责模型训练的团队,有没有 OpenAI、DeepMind、DeepSeek 出来的 VP of Training,没有就别投。
19. Transfer Learning(迁移学习)
官方定义: 迁移学习是「站在巨人肩膀上」的训练方式:把一个已经在大量数据上训练好的模型,作为新任务的起点,而不是从零开始训练。这样可以大幅节省数据量和算力需求,尤其适合目标任务数据量有限的场景。
迁移学习是当前 AI 应用层创业公司最常用的技术路线——Fine-tuning(微调)是其最主要的实现方式。正是因为迁移学习的存在,一个十人团队也能基于 GPT 或 Qwen 做出像样的 AI 产品,而不需要从头训练模型。
投研视角: 迁移学习降低了创业门槛,也降低了竞争壁垒——当所有人都在用同一个基础模型做迁移学习,差异化只能来自数据、场景理解和产品执行力。
Cohere、Hugging Face 本质上是在迁移学习的基础上构建差异化的分发和服务层。
迁移学习还直接影响毛利率结构。使用 OpenAI 等闭源模型的 API 进行迁移学习,成本极低,但会面临被闭源模型「收割」且数据主权受限的风险。
反之,基于开源模型自建私有化迁移路径,虽然前期投入大,但长期来看具备更好的单位经济效益,且数据安全可控。
技术尽调: 迁移学习 + 独家数据 = 壁垒。只迁移学习没数据,等于套壳。看 BP 就看「你独家数据在哪」。
20. Weights(权重)
官方定义: 权重是 AI 模型的「记忆载体」——训练过程中,模型通过不断调整数十亿个数值参数(即权重),来学习数据中的规律和模式。
权重决定了模型对不同输入特征的重视程度,是模型「学到的知识」的具体存储形式。训练结束后,这些权重固定下来,构成了模型的核心资产。
开源模型(如阿里的 Qwen、英伟达的 Nemotron)会公开权重,任何人都可以下载和修改;
闭源模型(如 GPT-5、Claude)则将权重视为核心机密,严格保密。
投研视角: 「开权重」的模型才是真的开源模型。有了权重,模型就能本地跑、微调、商用。没权重,API 再便宜也是给别人打工。7000 亿参数 = 7000 亿个权重。
权重是AI公司唯一真资产,但财报上体现不了,所以 AI 公司 PS 几百倍。
美国曾经讨论过「700B 权重禁运」,「权重合规」已成为尽调的必考题。
技术尽调: 问「你们的核心模型权重是自有的还是第三方的?」
答「自训练模型,部署在私有化环境,客户数据不出域」的,有真正的技术资产,且权重合规。
本文编译自 TechCrunch,投研视角和技术尽调为全息士编辑加工整理,不构成投资建议。
相关阅读
