 夜雨聆风
夜雨聆风Deep ResearchAI原生数据库
AI数据库发展调研
日期: 2026/4/14
核心摘要
2026年,随着生成式AI技术的全面爆发与数据要素市场化进程加速,中国数据库产业正经历从"云原生"到"AI原生"的关键转型期。国产数据库已从过去的"可用",转变为关键系统的"优选或必须用",形成"从被动跟跑"到"主动并跑"、部分领域"领跑"的新阶段。本报告将从技术演进路径、核心能力突破、行业落地案例及市场格局变化四个维度,全面解析当前数据库领域的最新发展动态与AI原生数据库的创新实践。
关键结论 (Key Takeaway)
国产数据库已从过去的"可用",转变为关键系统的"优选或必须用",形成"从被动跟跑"到"主动并跑"、部分领域"领跑"的新阶段。
一、数据库技术演进:从云原生到AI原生的范式转变
1.1 云原生阶段的技术特征与局限
云原生数据库阶段的核心特征是计算与存储分离的架构设计,通过容器化、微服务化等技术实现资源弹性扩展与高可用性。以阿里云PolarDB、腾讯云TDSQL和华为GaussDB为代表的产品,通过存算分离架构(olasFS、olasDB等)和HTAP能力,支撑了金融、政务等领域的核心业务系统。
然而,云原生数据库在AI时代面临多重挑战:
- 数据孤岛问题:传统架构下,结构化数据与非结构化数据(文本、图像、音频等)往往分布在不同系统中,导致AI应用开发复杂度高
- 实时性不足:大模型推理需要毫秒级响应,而传统数据库的批处理模式难以满足实时分析需求
- 资源利用率低:AI应用的冷热数据混合、低延迟与高吞吐并存等特点,使得单一数据库架构难以最优适配
1.2 AI原生数据库的三大技术特征
AI原生数据库(AI Native Database)是为AI时代专门设计的数据库架构,其核心特征包括:
- 原生多模态数据处理能力:支持结构化、半结构化、非结构化数据(文本、图像、音频等)的统一存储与检索,打破数据孤岛
- 内置向量检索与混合查询引擎:将大模型推理能力深度集成到数据库内核,实现"数据+模型"的协同工作
- 轻量化与边缘部署支持:从"百核千GB"到"1核CPU+2GB内存"的极致轻量化设计,支持从云中心到边缘设备的全场景部署
1.3 技术演进的关键转折点
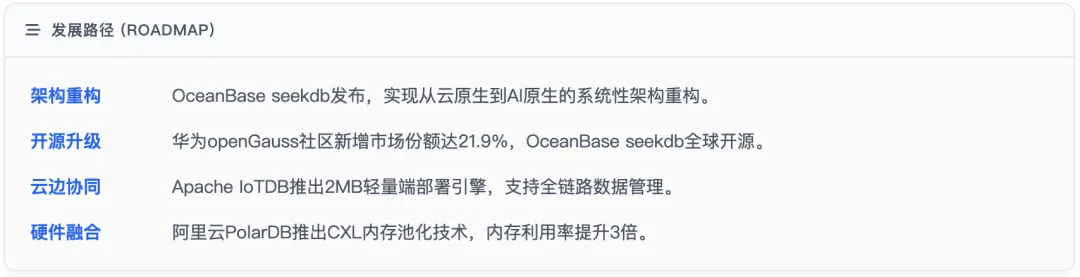
2025-2026年间,中国数据库产业经历了多个关键转折点:
- 架构重构:OceanBase seekdb于2025年11月发布,标志着国产数据库首次实现"从云原生到AI原生"的系统性架构重构
- 开源战略升级:华为openGauss社区新增市场份额达21.9%,OceanBase seekdb以Apache 2.0协议全球开源,加速技术生态建设
- 云边协同深化:Apache IoTDB推出2MB轻量端部署引擎,支持"端侧-边缘-云中心"的全链路数据管理与实时分析
- 硬件加速融合:阿里云PolarDB推出CXL内存池化技术,将内存资源利用率提升3倍,为AI原生数据库提供硬件支撑
二、AI数据库的核心能力突破
2.1 向量搜索:从独立系统到数据库内核
向量搜索能力已成为AI原生数据库的核心组件,主要突破体现在:
- 实时向量写入与事务支持:
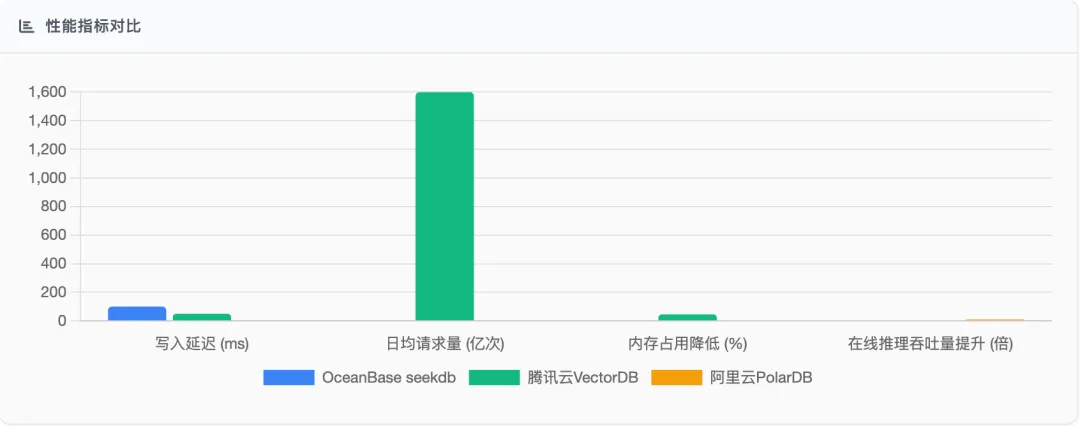
OceanBase seekdb通过"粗排+精排"多阶段检索机制,结合Paxos协议多副本架构,实现向量写入与ACID事务的融合,在反欺诈场景中实现<100ms延迟与99%召回率 腾讯云VectorDB采用Raft协议多副本架构和Segment化存储,实现写入延迟<50ms、QPS百万级,支持日均1600亿次请求的高吞吐 - 存储与计算优化:
腾讯云VectorDB通过FP16半精度量化技术,将内存占用降低45%,并利用共享GPU资源池实现算力成本节省50% 阿里云PolarDB通过CXL内存池化技术实现16TB内存共享,扩展性提升3倍,使在线推理吞吐量提升10倍 - 索引算法创新:
国产数据库普遍采用HNSW(分层可导航小世界)、IVF(倒排文件索引)等先进索引算法,支持千亿级向量检索 OceanBase seekdb的PowerMem分层记忆架构在LOCOMO Benchmark上以73.70分登顶SOTA,Token消耗降低96%
2.2 多模态处理:从单一模态到跨模态融合
多模态数据处理能力是AI原生数据库的另一核心突破,主要体现在:
- 统一存储引擎:
OceanBase seekdb支持向量、标量、文本、JSON和GIS等多模数据的统一存储与检索,实现"一个引擎,统一语义" 腾讯云VectorDB内置CLIP、ViT等预训练模型,自动完成图文特征提取,准确率较传统方法提升30% - 混合查询能力:
OceanBase seekdb的"粗排+精排"机制融合向量检索与结构化条件过滤,支持如"近7天交易超5万元、位置异常且行为类似历史欺诈样本"的复杂查询 腾讯云VectorDB支持"标量+向量"双通道查询机制,电商场景中可同时输入商品描述关键词和实物图片,实现跨模态精准匹配 - 数据融合逻辑
: 国产数据库普遍采用外部开源模型(如CLIP)生成跨模态向量,但通过自研的混合评分模型实现融合查询 腾讯云VectorDB采用"智能向量化"流程,支持PDF、Word、图片等10+种格式文档的一键解析,训练效率提升5-10倍
关键突破 (Key Breakthrough)
腾讯云VectorDB内置CLIP、ViT等预训练模型,自动完成图文特征提取,准确率较传统方法提升30%。
2.3 内生智能:从外挂式到内生式AI融合
内生智能能力是AI原生数据库的最高境界,主要突破包括:
- 模型算子化:
阿里云PolarDB将大模型封装为SQL函数(如 LLM Summarize()),支持库内推理,通过CXL内存池化和GPU+CPU异构资源调度,单位推理成本降至行业均值的30%微软HorizonDB通过SQL调用AI模型(如Foundry),实现"在查询中内置AI模型"的能力,用户可保留SQL结构,在合适位置调用语义运算符 - 实时分析能力:
OceanBase seekdb的PowerRAG智能文档解析框架与PowerMem分层记忆架构,支持大模型与私有数据融合计算的"实时入口层",实现毫秒级响应 阿里云PolarDB的In-DB模型算子化技术,开发者可在数据库内直接完成语义检索和推理加工,确保数据不出域的同时提升处理效率 - 智能决策支持:
南方医院HAIP平台整合AI算力、数据、模型资源,通过AI数据湖提供全院统一的数据视图,打破数据孤岛,构建AI训练的"数据粮仓" 浪潮KaiwuDB内置AI内核引擎实现原生预测分析及系统自治,在智慧矿山场景中,设备状态实时分析结果可帮助企业快速定位风险

三、AI数据库在重点行业的落地应用
3.1 金融领域:从风控到智能客服的全面渗透
- 实时反欺诈系统:
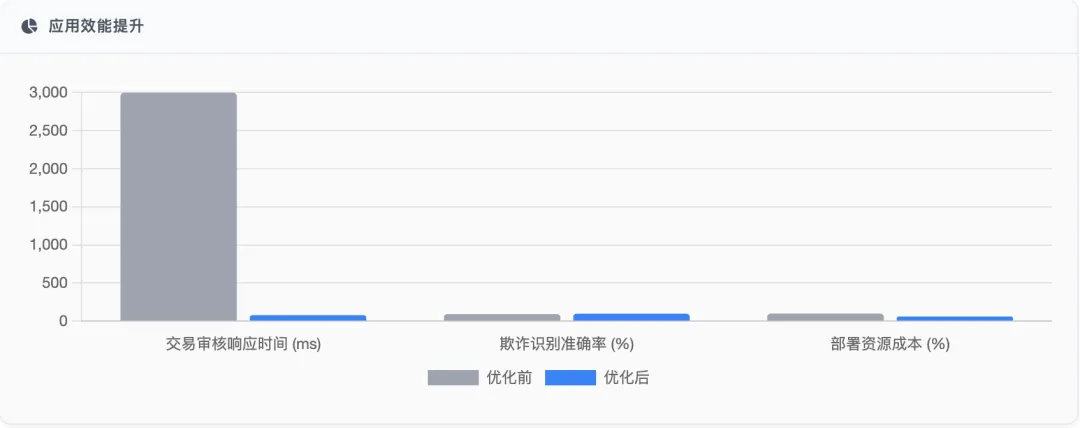
OceanBase seekdb在某头部股份制银行的应用案例中,将交易审核响应时间从3秒降至80ms,欺诈识别准确率从92%提升至98.5%,系统部署资源成本降低40% 该系统利用seekdb的"标量条件下压优化"技术,先通过结构化索引快速定位高风险交易子集,再对子集进行向量相似性计算,显著降低计算开销
智能投顾与客户服务: 腾讯云VectorDB支持企业私域知识库构建,存储和管理海量用户行为数据的向量表示,为精准营销和个性化推荐提供高效数据服务 中国人寿基于阿里云PolarDB完成400多套核心数据库向国产数据库的全面迁移,迁移数据总量超过1PB,日均处理千万级事务 - 跨境金融场景:
OceanBase在老中银行的案例中,上线新一代核心系统,性能提升20倍,批量处理时间从数小时压缩到30分钟,成本仅为同类方案20%,成为中国自研数据库首次在海外银行核心系统落地
3.2 政务领域:从数据治理到智慧决策的转型
- 政务知识库与智能问答
: 中国联通基于OceanBase seekdb构建统一AI知识库,实现"政策条款+地理位置+相关案例"的混合检索,文档解析准确率达98.7%,响应时间<100ms 该系统通过PowerRAG解析多格式文档,支持15种格式自动处理,显著提升政务信息检索效率与准确性 - 人社与民生系统:
OceanBase支撑全国约1/3省级人社系统,通过AI原生混合搜索能力实现养老保险全国统筹系统升级,江西率先试点并获人社部肯定,海南、重庆、浙江等十余省份跟进 华为openGauss与南方医院合作的HAIP平台,构建100%自主创新AIDC算力集群,AI算力利用率提升30%以上,为医疗AI应用提供统一数智化底座 - 交通与城市治理:
浪潮KaiwuDB在数字交管等车联网场景中,高频车机数据存储于内存层以实现毫秒级响应,历史轨迹数据则下沉至低成本对象存储,实现"热数据内存处理、冷数据对象存储"的分层管理 该系统支持时序与关系数据的关联查询分析,解决因接口协议不一致导致的数据孤岛问题
3.3 医疗领域:从数据整合到智能诊断的突破
- 医疗AI全场景智慧平台:
南方医院联合华为发布的HAIP平台,整合全院算力、数据、模型资源,将分散的AI能力整合为可共享、可进化、向基层赋能的统一数智化底座 平台通过AI数据湖提供全院统一的数据视图,构建AI训练的"数据粮仓";通过AI数据平台的知识库、记忆库和KV Cache加速能力实现毫秒级检索响应,提升推理准确率 - 医疗影像与病理分析:
南方医院HAIP平台支持病理AI辅助诊断、病案质控、电子病历AI助手等场景化应用,覆盖临床诊疗、患者服务、科研创新与运营管理 腾讯云VectorDB在医疗影像分析场景中,可将CT图像转换为特征向量后匹配病历文本,实现辅助诊断功能,支持"以图搜文"和"以文搜图"双向检索 - 临床决策支持系统:
OceanBase seekdb已服务多家三甲医院HIS系统,未来计划通过同态加密与联邦学习机制,满足医疗等敏感场景的数据安全需求,实现医疗数据的隐私保护与价值挖掘 南方医院已落地"智肾"慢性肾脏病综合管理大模型、"南方智麻"围手术期麻醉管理大模型等,覆盖临床诊疗全流程
四、国产数据库厂商的市场格局与竞争策略
4.1 市场格局:三足鼎立,头部集中
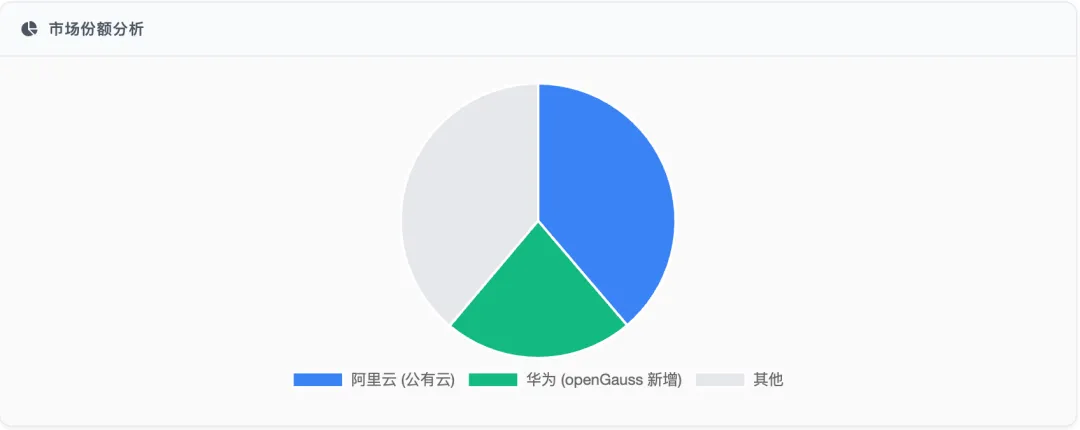
根据IDC、DB-Engines和墨天轮三大权威榜单的分析,当前中国数据库市场格局呈现以下特点:
- 市场份额分布:
- OceanBase
:在2025年上半年IDC中国分布式事务数据库本地部署市场以2810万美元营收位居第一;在整体市场(含公有云)以4060万美元营收位列独立厂商第一、全市场第四。客户数已突破4000家,连续5年年均增速超100% - 阿里云
:连续6年公有云关系型数据库市场份额第一(38%),PolarDB在DB-Engines全球榜单排名第42位。其客户数已突破2万家,部署规模超300万核,覆盖全球86个可用区 - 华为
:openGauss开源生态新增市场份额达21.9%(2023年数据),与南方医院合作的HAIP平台整合AI算力与医疗数据,磐维数据库覆盖31个省份4000+实例 - 腾讯云
:TDSQL已服务超千家金融机构,在国际金融数据库市场榜单名列前茅;VectorDB通过轻量化部署(1核CPU)和FP16量化技术强化向量搜索能力,但整体分布式事务数据库排名未明确
技术路线分化: - 集中式数据库
:以达梦、金仓为代表,架构简单、运维成熟,对Oracle的语法兼容深度高,适合传统核心交易系统、政务医疗场景 - 分布式数据库
:以OceanBase、TiDB、GoldenDB为代表,数据分片存储在不同节点上,支持水平扩展,但运维复杂度高 - 云原生数据库
:以PolarDB、TDSQL、GaussDB为代表,存算分离架构,计算节点无状态化,存储节点独立扩展,资源利用率高 - 市场集中度
: IDC数据显示,中国分布式事务数据库市场前五大厂商已占据82.5%的市场份额,行业"马太效应"凸显 本地部署市场增速高达24.9%,远超公有云部署模式,预计2024-2029年复合增长率将达24.2%
市场洞察 (Market Insight)
IDC数据显示,中国分布式事务数据库市场前五大厂商已占据82.5%的市场份额,行业"马太效应"凸显。
4.2 竞争策略:技术路线差异化与生态建设
国产数据库厂商在AI原生转型过程中,形成了各具特色的竞争策略:
- OceanBase:AI原生技术引领者
: - 技术路径
:从"AI原生"理念出发,发布并开源首款AI数据库产品seekdb,通过"一体化"架构将数据形态、负载类型与模型能力、多云原生合而为一 - 产品创新
:seekdb支持向量、全文、标量及空间地理数据的统一混合搜索,采用"粗排+精排"多阶段检索机制,将PowerRAG智能文档解析框架与PowerMem分层记忆架构开源 - 市场拓展
:客户数突破4000家,覆盖金融、政务、能源、通信、医疗等关键领域,在海外银行核心系统市场取得突破 - 阿里云:公有云生态与AI原生双轮驱动
: - 技术路径
:从云原生向"AI就绪"再到"AI原生"演进,提出"AI就绪的云原生数据库"概念的四大核心支柱:多模态AI数据湖库、高效融合搜索能力、模型算子化服务及面向Agent应用开发的后端服务 - 产品创新
:PolarDB通过模型算子化将大模型内嵌到数据库引擎中,利用三层解耦架构和多主多写能力弹性伸缩出人工智能推理节点,将在线推理吞吐量提升10倍 - 市场拓展
:客户数已突破2万家,部署规模超300万核,覆盖全球86个可用区,服务多家国有大型商业银行、7家股份制商业银行、90%已上市商业银行 - 腾讯云:高性能与信创适配并重
: - 技术路径
:基于存算分离架构的向量引擎数据底座重构,让向量数据库从单纯的AI检索工具演进为智能数据系统的关键中枢 - 产品创新
:VectorDB采用Raft协议多副本架构和Segment化存储,支持日均1600亿次请求的高吞吐;腾讯云向量数据库通过半精度量化技术,在保证召回率的前提下将内存成本降低45% - 市场拓展
:TDSQL已服务超千家金融机构,在国际金融数据库市场榜单名列前茅;VectorDB深度适配国产信创生态,支持公有云、私有云和混合云部署模式 - 华为:开源生态与政企场景深耕
: - 技术路径
:通过openGauss开源社区构建生态,与南方医院合作HAIP平台,整合算力、数据、模型资源 - 产品创新
:HAIP平台采用"能力底座、智能中枢、工具引擎"三位一体架构,依托昇腾、鲲鹏等自主创新算力底座,构建100%自主创新AIDC算力集群 - 市场拓展
:openGauss社区新增市场份额达21.9%,磐维数据库覆盖31个省份4000+实例,在政企市场形成深厚积累 - 浪潮:标准制定与垂直领域突破
: - 技术路径
:面向AIoT场景打造分布式多模数据库KaiwuDB,结合自身在分布式架构、多模一体化、云边端协同、运维自治等领域的技术积累 - 产品创新
:KaiwuDB采用多模融合架构,支持时序、关系、文档等多模型数据统一存储;通过"就地计算"技术支持百万级数据秒级入库,千万级查询毫秒级响应 - 市场拓展
:已参与20余项国行团标制定,连续两年入选Gartner《中国数据库管理系统代表厂商》,在物联网场景下获得国际权威认可
4.3 未来发展趋势:从替代到引领的格局重构
根据Gartner、IDC等权威机构的预测,国产数据库未来发展趋势主要体现在以下方面:
- 技术方向
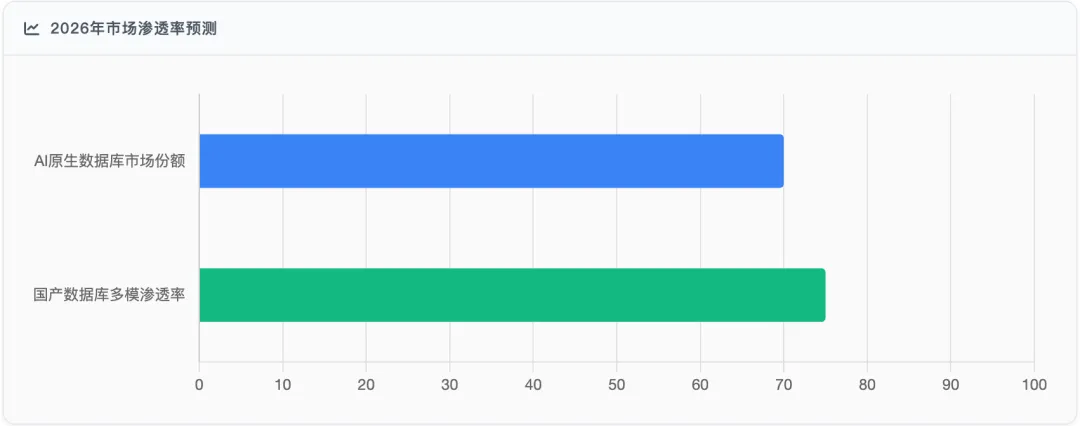
: - AI原生普及
:Gartner预测,2026年具备AI原生能力的数据库将占据市场份额的70%以上,可减少80%的DBA日常运维工作量 - 多模态融合
:IDC预测,2026年具备完整多模支持能力的国产数据库市场渗透率将突破75%,成为政务、金融等核心领域的首选架构 - 自治能力提升
:AI原生数据库将实现从"AI建议型"到"自设计型"的跨越,具备自我优化、自我诊断、自我修复的全链路自治能力,使企业数据处理效率提升300%以上
市场预测:
- 规模增长
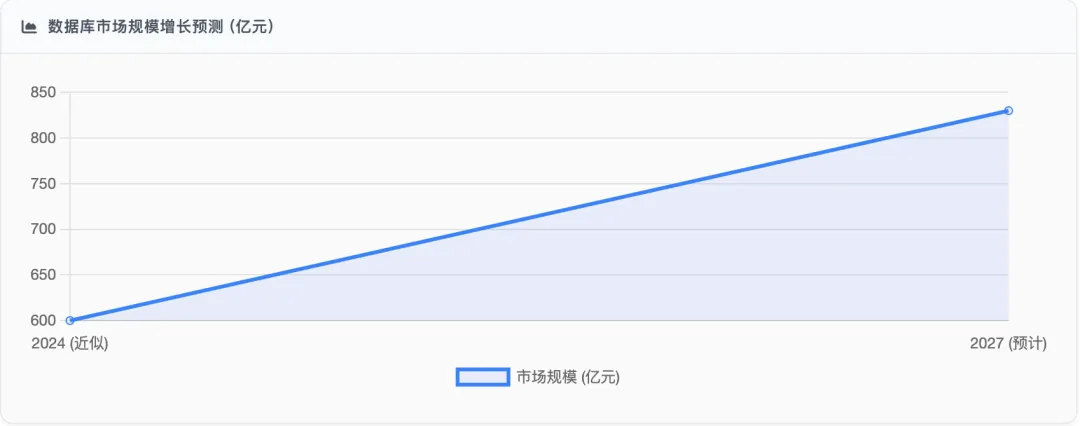
:中国信通院数据显示,我国数据库市场规模已近600亿元,预计到2027年有望超830亿元。IDC预计,到2026年,中国关系型数据库软件市场规模将达95.5亿美元,未来5年市场年复合增长率为28.8% - 向量数据库爆发
:2025年国内向量数据库市场规模已突破80亿元,2026年将延续高增态势,成为数据库细分领域增速冠军 - 垂直领域深化
:AI原生数据库将在医疗、金融、工业物联网等垂直领域形成差异化优势,如医疗多模态模型单病例诊断收费达50美元,是通用模型的3倍
政策驱动:
- 数据要素流通:世界互联网大会亚太峰会聚焦数据要素流通、AI与大数据融合治理,将加速数据要素市场化进程,公共数据授权运营、隐私计算等赛道迎来落地窗口期
- 数据主权与合规:Gartner预测,到2028年,由于采用超过3种以上不同区域的AI模型,所产生数据主权合规与AI偏见问题将占AI数据管理量的50%,推动国产数据库在隐私计算、数据确权等核心技术领域加大投入
- 信创政策深化:IDC指出,随着国家数据库测评名单的发布和政策深入推进,具备核心技术能力与成熟实践案例的厂商优势将更加凸显
五、结论与展望
5.1 核心结论
当前数据库产业发展呈现三大核心趋势:
- 技术架构重构:从云原生到AI原生的范式转变已成为不可逆趋势,向量数据库成为AI基础设施的核心环节,不再是可有可无的附属品
- 应用价值提升:AI原生数据库的价值从单纯的数据存储扩展到智能决策支持,企业通过AI原生数据库构建的AI应用,其业务价值将是传统AI开发方式的2-3倍
- 市场格局重塑:国产数据库已从"跟跑"到"并跑",在金融、政务等关键领域形成规模化落地,前五大厂商占据82.5%的市场份额,行业集中度持续提升
价值倍增 (Value Multiplier)
企业通过AI原生数据库构建的AI应用,其业务价值将是传统AI开发方式的2-3倍。
5.2 未来展望
面向2026-2028年,中国数据库产业将迎来三大关键机遇与挑战:
- 机遇:
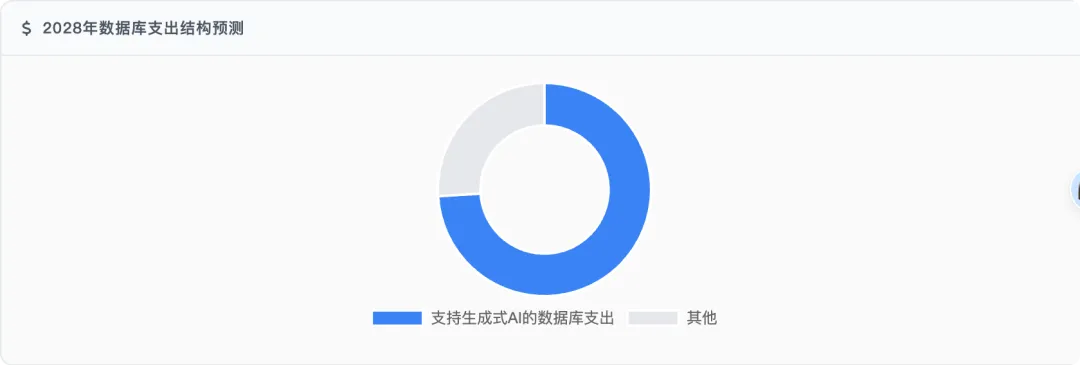
- AI原生红利
:据Gartner预测,到2028年,支持生成式AI的数据库支出将达2180亿美元,占市场74%。国产数据库厂商有望在这一巨大市场中分得更大份额 - 技术自主可控
:随着中美科技竞争加剧,中国数据库产业在核心技术、开源生态、标准制定等方面加速自主化进程,为长期发展奠定基础 - 全球化布局
:以OceanBase为代表的国产数据库厂商加速海外布局,"一套架构、全球运行"的多云数据库战略将助力中国数据库走向世界 - 挑战:
- 技术深度:尽管在应用层面取得突破,但在底层核心技术(如新型索引算法、分布式事务协议、硬件加速架构)方面仍需加大投入,缩小与国际领先水平的差距
- 生态建设:国产数据库需构建更开放、更繁荣的开发者生态,吸引全球开发者参与,提升技术影响力与商业价值
- 人才培养:随着数据库与AI技术的深度融合,既懂数据库架构又懂AI应用的复合型人才短缺将成为制约产业发展的关键因素,需加强产教融合与人才培养
2028年数据库支出结构预测
5.3 发展建议
对国产数据库厂商及用户的建议:
- 厂商侧
: - 技术路线选择
:根据业务场景选择适合的技术路线,金融、政务等高敏场景优先考虑分布式或集中式架构,AI应用开发场景可优先考虑AI原生架构 - 生态建设
:加大开源社区建设力度,降低开发者使用门槛,吸引全球开发者参与,提升技术影响力 - 国际化布局
:加速全球化战略实施,通过多云数据库架构降低客户出海门槛,拓展海外市场 - 用户侧
: - 选型策略
:综合参考DB-Engines(技术影响力)、IDC(市场份额)和墨天轮(国内热度)三大榜单,结合自身业务场景与技术能力进行选型 - 架构演进
:从"功能补齐"向"体验跃升"、从"单点突破"向"生态协同"转型,逐步构建AI原生的数据架构 - 人才培养
:重视数据库与AI融合领域的人才培养,建立跨领域的技术团队,为AI原生数据库的落地应用提供人才保障
AI原生数据库的崛起,不仅是一场技术革命,更是一场产业重构。它将重新定义数据库在企业数字化转型中的角色,从"数据存储系统"升级为"智能决策中枢"。对于国产数据库产业而言,这既是挑战也是机遇——挑战在于需要突破更多底层核心技术,机遇则在于中国丰富的应用场景与庞大的数据规模,将为AI原生数据库的创新提供肥沃土壤。在这一历史性机遇面前,国产数据库厂商需保持战略定力,加大研发投入,构建开放生态,才能真正实现从"替代者"到"引领者"的历史性跨越。
最终展望 (Final Outlook)
AI原生数据库的崛起,不仅是一场技术革命,更是一场产业重构。它将数据库从“数据存储系统”升级为“智能决策中枢”。
