 夜雨聆风
夜雨聆风一条推文,把日本 AI 三十年的努力变成了一个笑话
摘要:3.6 万赞的推文说"日本造不出 DeepSeek 是因为起步太早,直接从 AI 跳到了 AV"。笑完之后发现,这可能是今年最精准的行业诊断。
昨天刷到一条推文,我盯着屏幕笑了足足一分钟。
不是那种礼貌性的嘴角上扬,是真的被击中了笑点的笑。
笑点在哪?
"
Why can't Japan produce a DeepSeek?
Because Japan's AI development started too early, while others were still in the AI stage.
Japan had already skipped past AII, AIII, AIV and reached AV level.
—— Roland W. (@rwayne) · 3.6万❤️ · 250万浏览
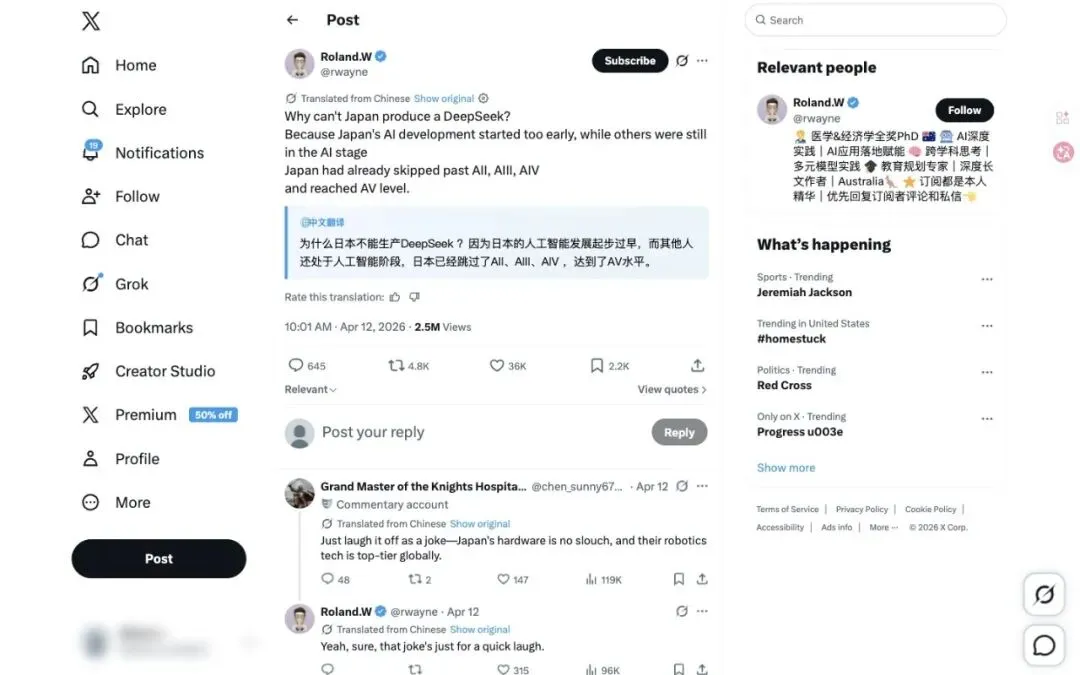
原推文截图 · 来源 X/Twitter
如果你没 get 到,我解释一下。
AI、AII、AIII、AIV —— 看起来像是某种版本号对吧?AI 1.0、AI 2.0、AI 3.0、AI 4.0……循序渐进,一步一个脚印。
但 AV 不是什么 AI Version 的缩写。
⚡ 笑掉大牙
Adult Video。
日本最著名的全球出口产品类别之一
这条推文的完整逻辑链是这样的——别人还在搞人工智能的时候,日本人因为起步太早,已经把 AI、AII、AIII、AIV 全部跳过了,直接到达了 AV 级别。
用最体面的方式,说了最难听的话。而且你没法反驳它,因为它每一层都在事实的基础上又往上叠了一层讽刺。
但这不仅仅是个段子
我刚看到这条推文的时候,第一反应跟大多数人一样——哈哈好笑,转发,划走。
然后我想了想,决定去查一下日本 AI 到底是个什么状况。
不查不知道,一查才发现,这个段子可能比我以为的要精准得多。
先说一个真事
今年 3 月 17 号,日本乐天集团高调发布了 Rakuten AI 3.0。
定位非常宏大——"日本最大、性能最强的开源大语言模型",7000 亿参数,背后还有日本经济产业省的 GENIAC 项目撑腰,基本上就是戴着"国家队"的光环出场。
📊 Rakuten AI 3.0 官方宣称
7000 亿 参数规模 | Apache 2.0 开源 | GENIAC 国家项目支持
日语优化 | "日本最强 AI" 官方定位
发布会开得很风光,新闻稿写得很漂亮,日本媒体纷纷报道说这是"全村的希望"。
然后几个小时之后,就翻车了。
开源社区的开发者跑去 Hugging Face 上看了源码,发现问题有点大:
这个号称"日本最强 AI"的模型,配置文件里清清楚楚写着架构来源——DeepSeek V3。
671B 总参数,激活 37B。跟 DeepSeek V3 一个数都不差。

Rakuten AI 3.0 的"原创"底座,扒开后是 DeepSeek V3
乐天做的事情说白了就是拿 DeepSeek 的底座,灌了一批日文数据进去做了个微调,然后把 DeepSeek 的 MIT 开源协议删掉,换上了自己的 Apache 2.0 协议,再发个新闻稿说"融合了开源社区的精华"。
连 DeepSeek 的名字都没提。
日本网友当时的反应可以总结成一句话——
"
拿着政府补贴,调了个中国模型,还要假装是日本自研。
—— 日本网友集体反应
更魔幻的是,这件事后来被扒出来说,日本前十大的 AI 模型里头,有 6 个都是基于 DeepSeek 或者阿里千问做的二次开发。
也就是说,段子里的"日本跳到了 AV 级别",在现实里对应的是——日本的 AI 级别,其实建立在中国的模型之上。
那日本到底差在哪儿?
很多人第一反应会觉得,是不是技术不行?
还真不是。
东京大学有个松尾丰教授,在日本被称为"AI 教父"。他的实验室从 2013 年就开始做 AI 孵化,比 AlphaGo 震惊世界还早了好几年,到现在孵化了 32 家 AI 创业公司。
日本本土做 AI 的公司有 300 到 500 家,NEC、NTT、富士通、日立这些老牌巨头全都有庞大的 AI 团队。索尼的 AI 研发甚至可以追溯到上世纪九十年代。
💡 关键判断
论人才储备、论研发积累、论产业基础,日本一点都不弱。但问题出在一个更深的地方。
日本有一句特别能代表国民思维的话——
🗾 日本国民思维
「で、それ、何の役に立つの?」
翻译过来就是"那玩意儿到底有什么用"
这不是一句随便说说的口头禅,它几乎决定了日本整个科技产业的发展路径。
DeepSeek 或者 OpenAI 的模式是什么?先砸几百亿人民币训练一个大模型,亏它个三年五年,赌的是未来某一天这个东西能变成像电力一样的基础设施。
这种"先烧钱造核弹,再去各行各业实习"的逻辑,在日本社会几乎是行不通的。
日本企业的思维方式更像丰田生产方式——你给我一个问题,我就针对这个问题给你一个最优解。工厂质检效率低?我给你做个 AI 质检系统。医院影像诊断人手不够?我来做个辅助诊断工具。
每一个解决方案都极其精准、极其实用、立刻能看到投资回报率。
但你让它去做一个"不知道有什么用但未来可能改变一切"的东西?
它会问你——で、それ、何の役に立つの?
还有一个很现实的原因
中国为什么会出现 DeepSeek?
其中一个很重要的推动力是 ChatGPT 在国内用不了。
用不了,就会产生巨大的"国产替代"需求。有需求,就有市场;有市场,就有资本愿意投;有资本投,就有人敢去干。
日本不存在这个问题。
OpenAI 的产品在日本正常使用,Google 的全家桶日本职场人士用得飞起,Amazon AWS 是日本云计算市场的老大。既然美国最好的东西都能无缝接入,日本企业为什么要花巨资去从零做一个?
🔴 日本:缺乏痛点驱动
个人用户 AI 使用率仅 9.1%(2024)美国产品无缝接入 = 没有替代动力
🔵 中国/美国:强痛点驱动
美国使用率 46.3% | 德国 34.6%ChatGPT 用不了 = 国产替代需求爆发
没有痛点,就没有爆发的动力。
然后,今天发生了最有意思的事
就在我写这篇文章的时候——字面意义上的"就在刚才"——日本那边传来了新消息。
软银联合 NEC、本田、索尼等七家日本巨头,正式宣布组建一家新的 AI 公司。
📢 今日重磅(2026年4月14日)
目标是什么?打造一个 1 万亿参数的"物理 AI"模型。
注意,不是通用大语言模型,是 Physical AI——面向机器人的实体智能。

SoftBank 联合七大巨头 all in 物理AI
日本经济产业省编列了专项预算,计划从 2026 年度起 5 年内拨付 1 万亿日元(约合 460 亿人民币)的资助金。软银自己也要追加巨额投资。
有人发推嘲讽日本 AI 跳到了 AV 级别,3.6万人点赞
日本绕过通用大模型赛道,all in 物理机器人 AI,砸一万亿日元
从"造不出 DeepSeek"到"老子不造 DeepSeek 了"中间只隔了一条爆款推文的距离
我不是说软银的这个决策是因为那条推文——人家这种级别的战略规划肯定早就开始了。
但这条推文像一根针,精准地戳破了那个一直没人明说的事实——
★ 文章核心论点
日本不是造不出 DeepSeek,而是日本选择了不造。
或者说得更准确一点,日本在"要不要造一个通用大平台"这个问题上,用脚投了一张反对票,然后转身走向了它更熟悉的赛道——制造业升级、机器人智能化、产业端深度应用。
这条路好不好?当然也好。
比亚迪式的产业链深耕和特斯拉式的颠覆式创新,没有高下之分,只是选择不同。
但有一个细节让我觉得不太妙
回到乐天那个事儿。如果乐天一开始就大大方方地说"我们基于 DeepSeek V3 做了一个优秀的日语优化版",这不丢人。开源协议本来就允许这么做,MIT 协议几乎是最宽松的那一档。
问题不在于用了谁的技术。问题在于明明用了,却要装作没用。
删除别人的版权声明,换上自己的开源协议,新闻稿里绝口不提 DeepSeek 这四个字——这套组合拳打下来,给人的感觉不是一个技术公司在做技术,而是一个学生在抄作业的时候把名字都涂掉了。
这才是那条推文真正刺痛人的地方吧。
不是因为日本 AI 技术不行——技术从来都不是日本的问题。
是因为当你拼尽全力想要证明"我能行"的时候,翻开你的代码一看,里面写的全是别人写的字。而且还把别人的名字擦掉了。
这条路如果能跑通,说不定真的会走出一条和美国、中国都不一样的第三条路。
前提是,下次别再把人家的名字擦掉了。
毕竟,自信这件事,装是装不来的。
END
