 夜雨聆风
夜雨聆风你能想象吗——你对着手机说一句"帮我把昨晚的照片发到工作群,顺便把今天日程整理成表格",AI就默默打开了相册、选好照片、切换到微信、找到群聊、发送,然后再打开日历、把行程一条条填进备忘录。
这不是Siri或小爱同学那种只能点按钮的助手,而是真正能像人一样操作任意图形界面的AI Agent。

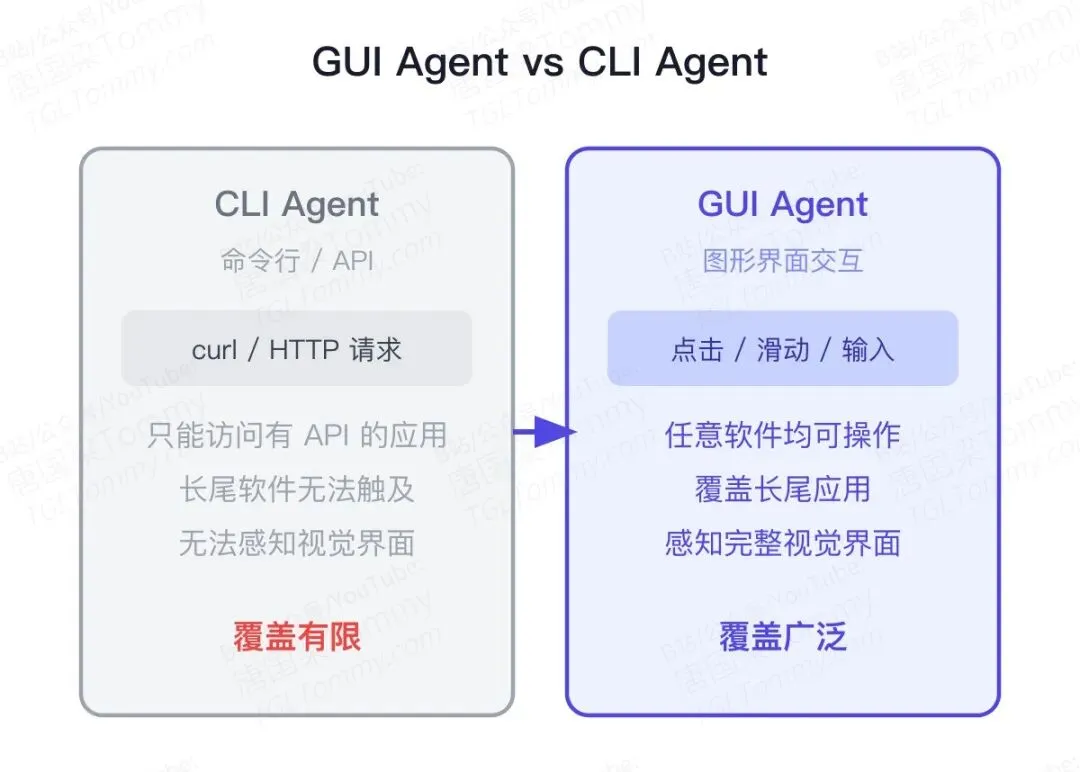
它叫 GUI Agent——通过视觉界面而非API来操控软件的智能体。它能点击、滑动、输入文字,覆盖从微信到银行App,从企业内部系统到各类长尾软件。
但这类Agent长期面临一个尴尬:模型不缺,缺的是一整套从训练到落地的基础设施。
浙江大学等机构近日开源的 ClawGUI 框架,正是为了解决这个全链路问题。
01 CLI Agent的天花板,恰好是GUI Agent的起点
过去几年,以Claude Agent、GPT Agent为代表的CLI式Agent发展迅速。它们能写代码、调用API、操控服务器——但有一个天然局限:只能作用于有程序化接口的软件。
没有开放API的老系统、没有接口的定制软件、数量庞大的移动端应用——这些CLI Agent完全触达不到。这就是为什么即便Agent概念如火如荼,真正能在普通人手机上帮你完成日常任务的AI助手,始终停留在演示视频里。
GUI Agent 则另辟蹊径:它直接感知屏幕上的像素,理解界面布局,然后模仿人的操作——点击、滑动、输入。一个能操控任意图形界面的AI,理论上可以驾驭一切有屏幕的应用。
实际上,GUI Agent走到今天,最大瓶颈并不是模型本身,而是没有一套完整的基础设施支撑它从训练到评估再到部署的全流程。
02 三大缺口,卡住了GUI Agent的脖子
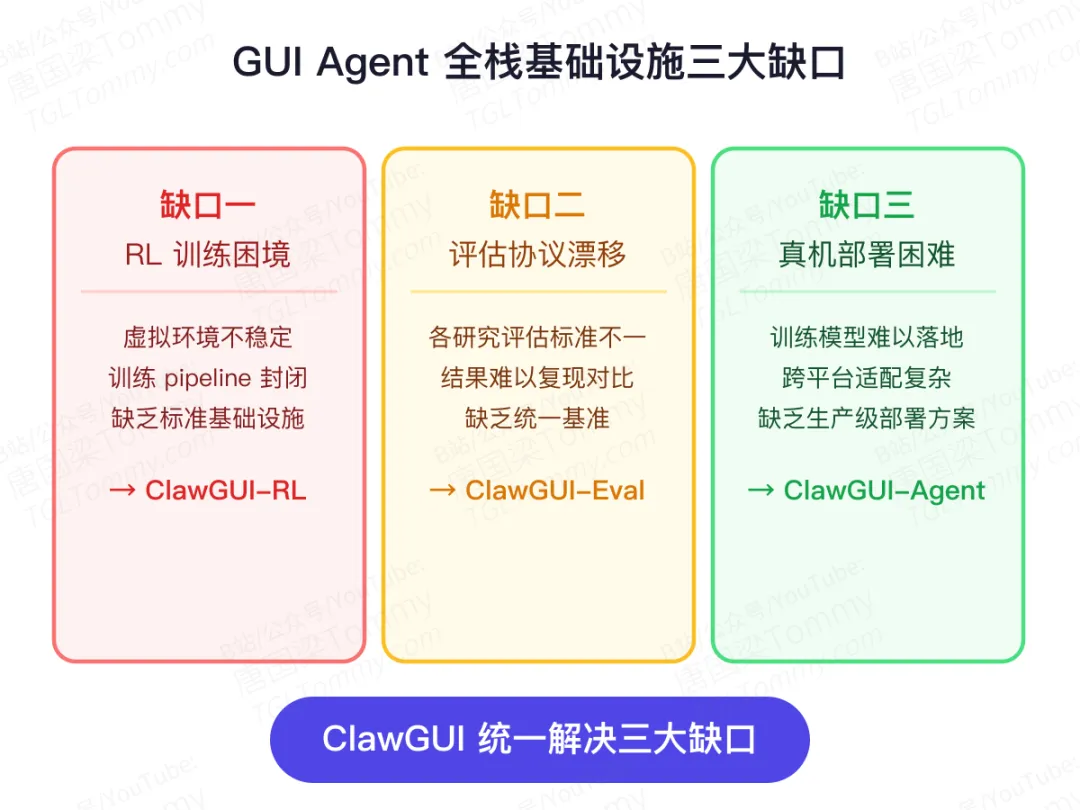
论文指出了当前GUI Agent研究中普遍存在的三个系统性缺口:
缺口一:RL训练困境。 在线强化学习是训练GUI Agent的核心路径,但现有方案面临虚拟环境不稳定、训练pipeline封闭、缺乏开源基础设施等问题。研究者往往自建环境,难以复现,也难以规模化。
缺口二:评估协议漂移。 不同研究团队使用各自的评测基准,标准各异,数字看着漂亮,但横向对比几乎不可能。更致命的是,95%以上的工作根本没有开源评测代码,论文报什么就是什么,无法验证。
缺口三:真机部署困难。 训练好的模型如何真正跑到用户手机上是另一个世界的问题。跨平台(Android、HarmonyOS、iOS)适配、聊天平台接入、个性化记忆持久化——每一条都是工程上的硬骨头。
这三个缺口互相缠绕,形成了一个恶性循环:训练不稳定→评估不可信→部署难落地→没人敢真正用。
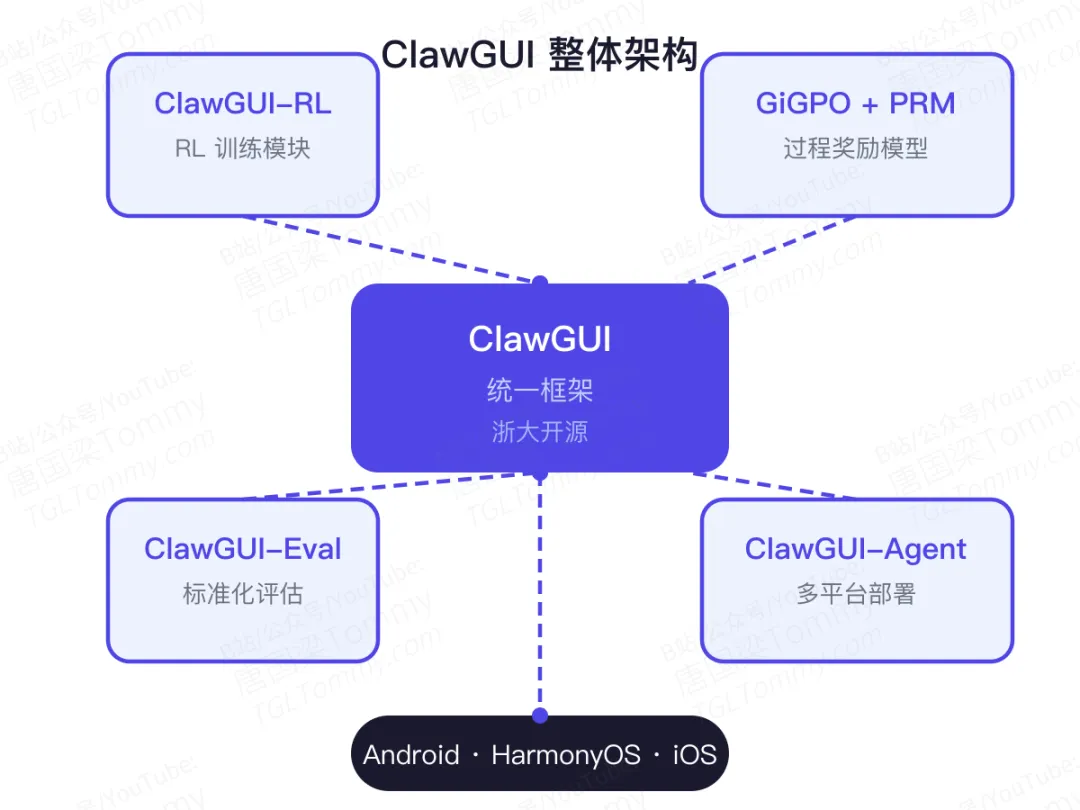
ClawGUI的思路是:用一个统一框架同时解决这三个问题。
03 ClawGUI-RL:第一次真正意义上的开源RL训练
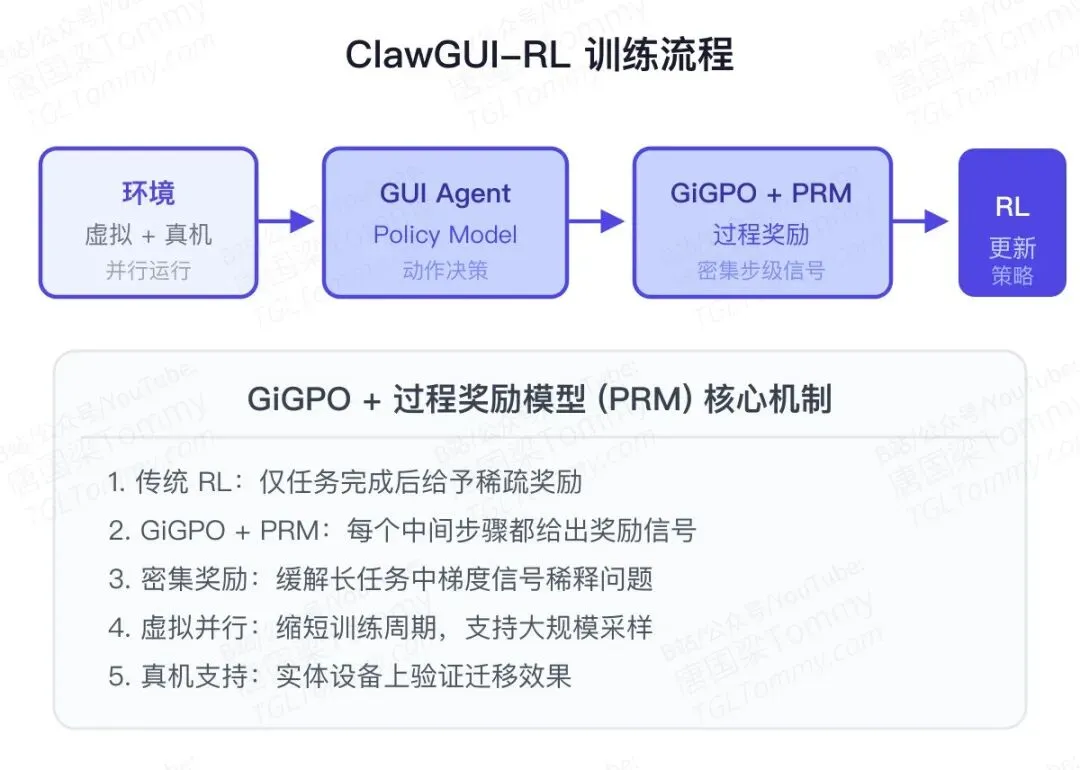
ClawGUI-RL是整个框架的训练核心。
它集成了GiGPO(一种面向GUI任务的策略优化方法)与过程奖励模型(Process Reward Model,PRM),为GUI Agent提供密集的步级奖励信号。
这有什么稀奇的?
传统RL通常只在任务完成时给予一个稀疏奖励:成功了给1,失败给0。但在GUI任务中,一个复杂操作可能包含几十上百个步骤——仅靠最终结果的奖励信号,梯度会在长序列传播中严重稀释,学不到有效策略。
PRM的核心思路是:每一步都给评分。模型当前操作是否让任务更接近完成目标?这个评分信号会伴随每一步反向传播,让策略学习更高效。
GiGPO则负责在虚拟并行环境和真实物理设备上稳定地运行这个RL循环,并支持大规模的并发采样,显著缩短训练周期。
ClawGUI-RL的另一个关键价值是开源:它是目前第一个真正开放、可复现的GUI Agent RL训练基础设施,打破了此前训练代码封闭、各家自建环境的局面。
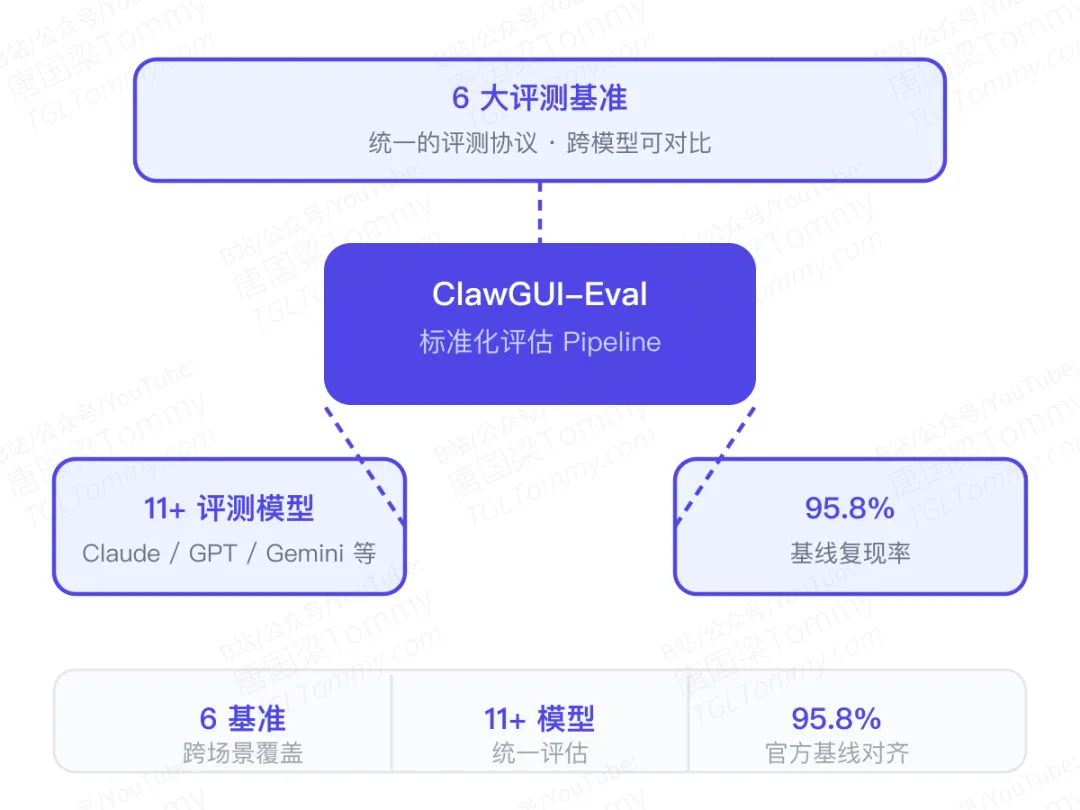
04 ClawGUI-Eval:标准化评测,让比较成为可能
ClawGUI-Eval构建了一套跨模型、跨基准的标准化评测pipeline,覆盖6大主流评测基准、11款以上模型(包括Claude、GPT、Gemma等),实现了95.8%的官方基线复现率。
这意味着什么?
过去你看到一篇论文说"我们超越了SOTA 20%",但仔细一看:评测基准不一样、评估协议不同、有的用成功率有的用步骤数有的用人工打分——根本无法直接比较。
ClawGUI-Eval强制所有模型在同一套协议、同一套环境、同一个评测集下跑,结果可直接对比。这不仅对研究者有价值,对想选型的工程师同样重要。
05 ClawGUI-Agent:从实验室到真机,一条管道打通
训练好了、评测完了,最后一步是让Agent真正跑到用户的设备上。
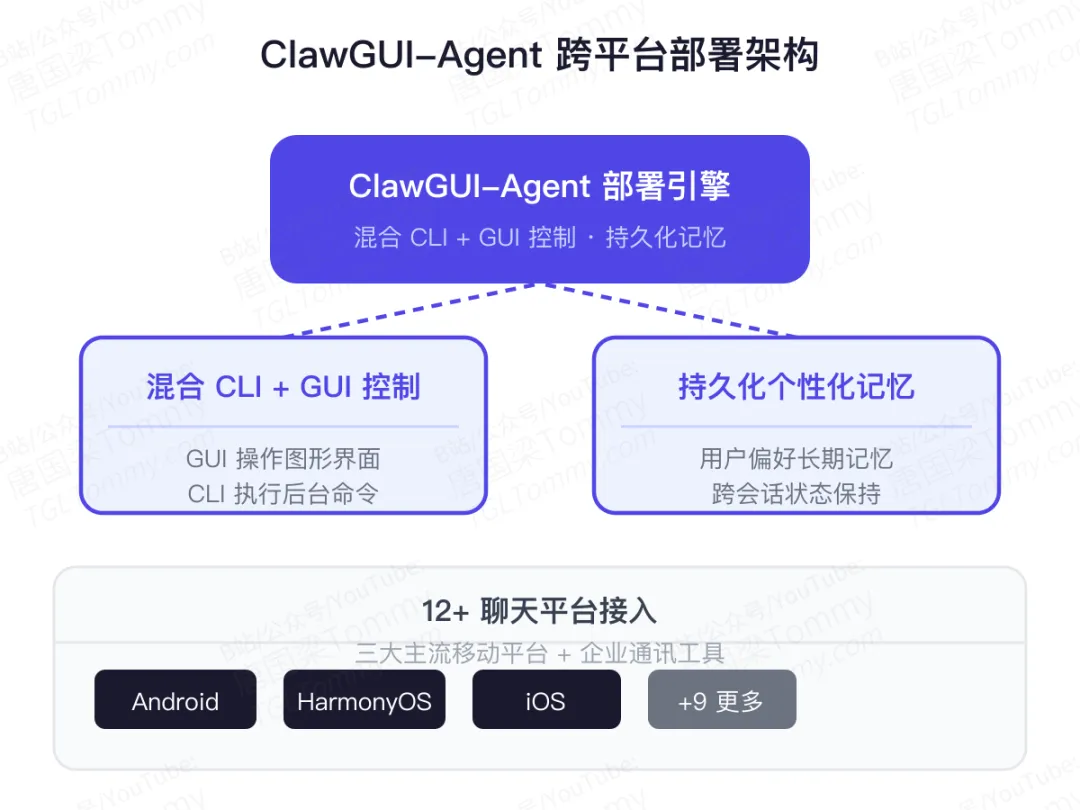
ClawGUI-Agent解决了三个实际问题:
多平台支持:通过统一的抽象层,支持Android、HarmonyOS、iOS三大主流移动操作系统,以及12个以上的聊天平台接入(企业微信、飞书、Slack等)。
混合控制:GUI负责图形界面操作,CLI负责后台命令执行,两者协同,取长补短。很多场景下CLI的效率和精度反而更高。
个性化记忆:每个用户的使用习惯、操作偏好,Agent都能记住并在后续会话中复用。这不是简单的历史记录,而是一个持久化的、跨会话的个性化记忆系统。
最终效果是:训练好的模型可以通过ClawGUI-Agent直接部署到真实手机,通过聊天平台与用户交互,并且越用越懂你。
06 实战效果:2B参数,真实超越同规模基线
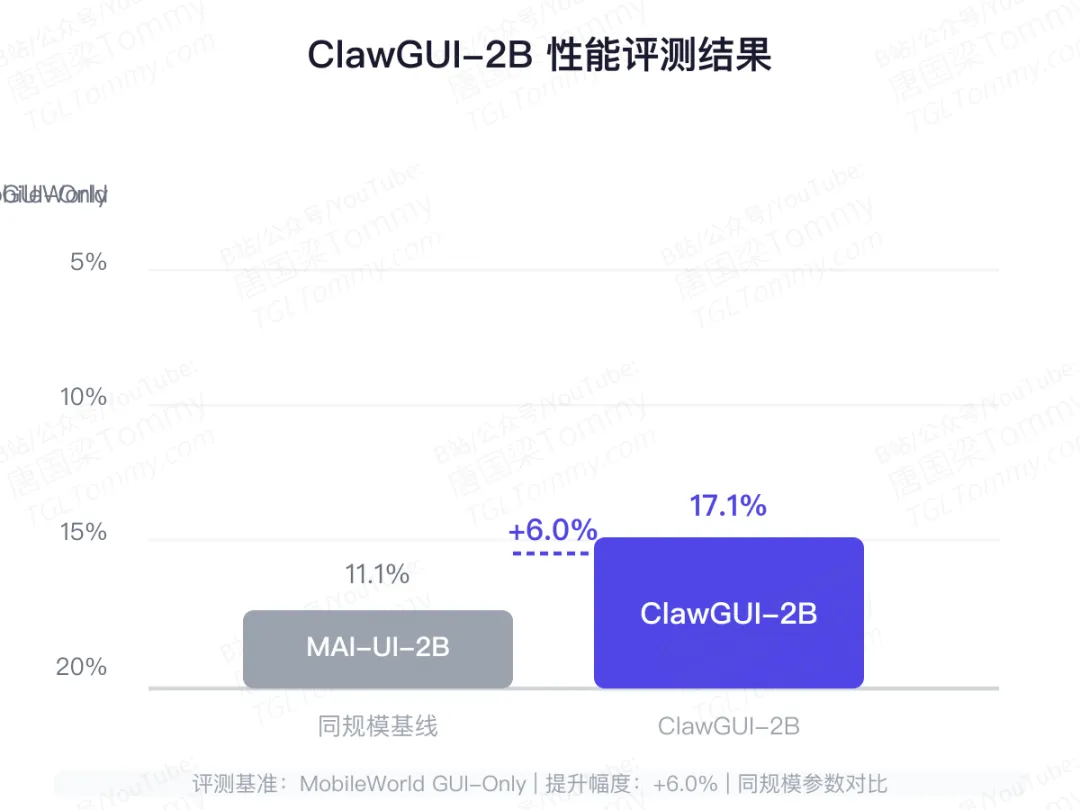
ClawGUI团队在自家框架上端到端训练了一个2B参数的模型——ClawGUI-2B。
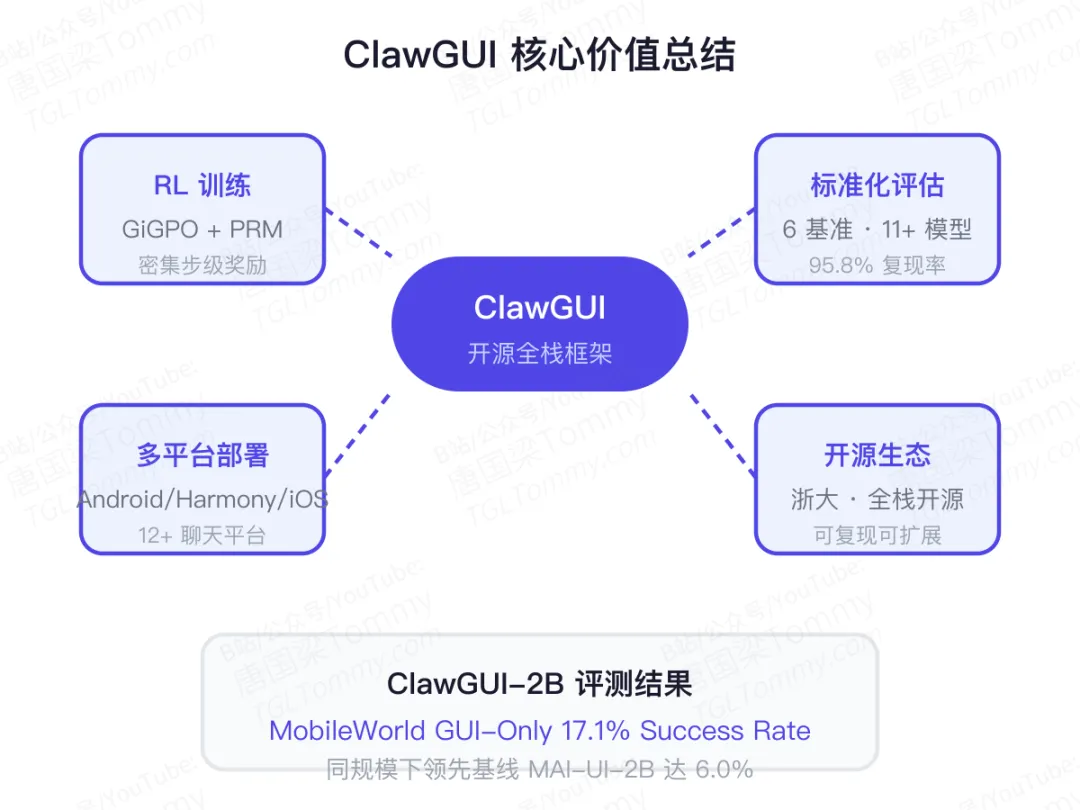
在MobileWorld GUI-Only评测基准上,ClawGUI-2B达到了17.1%的任务成功率,比同规模的基线模型MAI-UI-2B(11.1%)提升了6个百分点。
这个数字看起来不高,但需要理解背景:GUI任务的难度远高于传统NLP任务。一个任务可能涉及几十个步骤,每一步失误都会导致全盘失败。17.1%的成功率意味着每6次尝试能成功1次——对于实际辅助任务来说,这个水平已经具有实用价值。
而且这是在2B参数规模下的结果。随着模型规模增大、方法持续优化,上升空间还很大。
07 全方位对比:ClawGUI带来了什么
一张表看清ClawGUI和现有方案的差异:

核心结论是:ClawGUI是第一个真正意义上的全栈开源GUI Agent框架,从RL训练基础设施、到标准化评估、再到多平台部署,全部开源且可复现。
在此之前,研究者要么自己造轮子(训练环境),要么用不统一的评测(评估),要么干脆不做部署那一步。而企业想用GUI Agent,基本只能找方案商定制——没有标准基础设施,一切都靠手工作坊。
08 想象空间:GUI Agent能做什么
GUI Agent的潜力远超我们的刻板印象。来看几个典型场景:

个人助手终极形态:不只是定闹钟、查天气,而是帮你处理邮件、管理日程、操作任何手机App。你在开会时,AI帮你回微信;你刚拍完照,AI自动分类整理到对应相册——不是靠应用开放API,而是像人一样看屏幕、操作界面。
企业 RPA 的下一代:传统RPA(机器人流程自动化)依赖预设规则和坐标点击,脆弱且难维护。GUI Agent能理解界面语义,自主规划操作步骤,适配变化的能力远超传统RPA。
自动化测试:App频繁更新,UI变化快,自动化测试用例维护成本高。GUI Agent能自主探索新界面、发现回归问题,并发运行于多台设备,显著降低测试成本。
无障碍辅助:为视觉障碍用户提供自然的语音交互界面,AI代替用户操作完成各种App任务。
长尾软件自动化:企业里大量定制化软件、内部系统没有开放API,GUI Agent是唯一可行的自动化方案。
09 局限与挑战
客观讲,ClawGUI虽然解决了很多问题,但仍有一些局限值得注意:
成功率仍有很大提升空间:17.1%的成功率意味着当前技术还远未成熟。对复杂多步骤任务,当前进度条还是很初级的。
真机环境的复杂性:虚拟环境训练再稳定,迁移到真实设备仍有Gap。屏幕分辨率、系统版本、应用版本差异都可能影响效果。
安全与隐私:GUI Agent需要操控用户的真实应用,涉及账号安全、隐私数据等敏感问题,当前框架层面尚未有完善的安全机制。
评估基准的覆盖度:6大基准虽然覆盖主流场景,但GUI应用的多样性远不止这些,评测覆盖仍有盲区。
10 一个新起点
ClawGUI最有价值的地方,不是某一个算法创新,而是一次系统性的基础设施建设。
它证明了GUI Agent从训练到评估到部署,可以被纳入一套统一、可复现、可扩展的框架中。这为后续研究提供了统一的起点,为工业落地降低了门槛。
论文信息:ClawGUI: A Unified Framework for Training, Evaluating, and Deploying GUI Agents,来自浙江大学等机构,2026年4月发表于arXiv。
开源地址见论文主页,有训练代码、评测pipeline和部署工具链。
进阶学习
👉如果你想系统掌握多模态大模型前沿技术与应用,推荐你学习我的精品课程:
📚课程覆盖主流多模态架构、多模态Agent、数据构建、训练流程、评估与幻觉分析,并配套多个项目实战:LLaVA、LLaVA-NeXT、Qwen3-VL、InternLM-XComposer(IXC)、TimeSearch-R视频理解等,包含算法讲解、模型微调/推理、服务部署、核心源码解析。
💡本课程目前正在更新中,你可以在我的个人官网或B站课堂参与学习:
📺B站课堂(点击左下角“阅读原文”直接跳转)https://www.bilibili.com/cheese/play/ss33184
🌐官网链接(国内访问需科学上网):https://www.tgltommy.com/p/multimodal-season-1

