 夜雨聆风
夜雨聆风
想必大家在初涉 AI Infra 和大语言模型时,都曾有过类似的困惑:装好 GPU 驱动、配好 CUDA,再用 vLLM 把模型跑起来并不难,可模型一旦运转起来,底层的运行原理却仿佛蒙上了一层黑纱——比如,GPU 与 GPU 之间到底是如何通信的?有哪些通信方式?各自的优缺点又是什么?
今天,我们就以 NVIDIA GPUDirect 为切入点,一起揭开模型底层的运行奥秘。
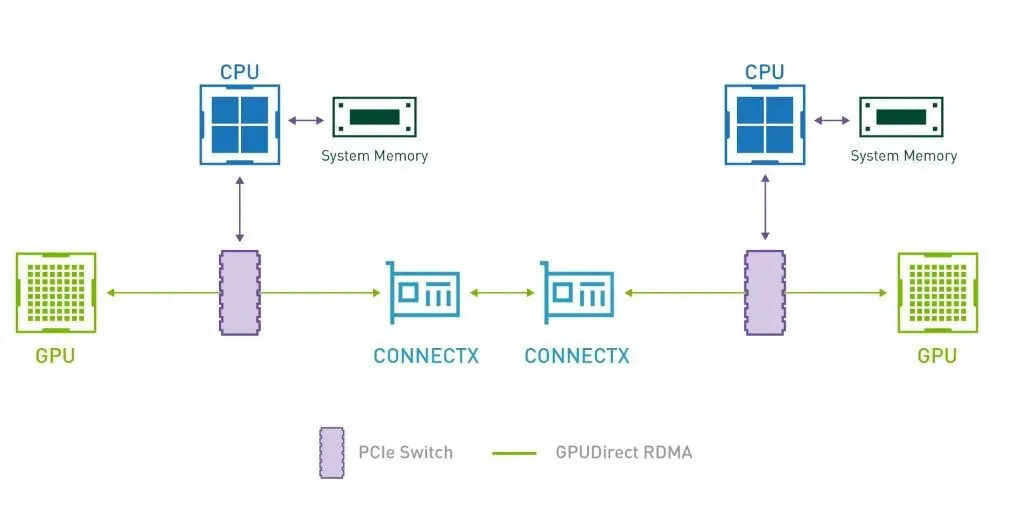
前一篇文章分享了NVIDIA NCCL,先做一个简单回顾:
AI Infra - NVIDIA GPU高效运维(五)大模型工程师都应掌握的NVIDIA集合通信库NCCL!
它是NVIDIA提供的一个高性能集合通信库,并具有拓扑意识,可通过PCIe、NVLink、以太网和InfiniBand互联实现高带宽和低延迟,所以NCCL强依赖于GPU Direct进行GPU间通信。
1、什么是NVIDIA GPUDirect
NVIDIA GPUDirect是一系列增强数据中心GPU之间的数据传输和访问的技术的统称,GPUDirect主要的目标是减少数据在GPU之间传输中的非必要拷贝、提升通信链路带宽和降低通信延迟,按是否在一个节点可以分为两大类:
(1)同一个节点内GPU-to-GPU的通信,如:GPU Direct Shared Memory、GPUDirect Peer to Peer(P2P)、NVLink、GPUDirect Storage等技术。
(2)不同节点间GPU-to-GPU的通信,如:GPUDirect Remote Direct Memory Access (RDMA)技术。
本文先分享单个节点内GPU Direct,下篇文章介绍多节点间GPU通信原理。
2、节点内GPUDirect技术
(1)GPU Direct Shared Memory
这是最早且最传统的一种通信方式,GPU到GPU的数据访问基于操作系统提供的共享内存(SHM),不同进程或者GPU能够访问同一块物理内存,数据先从GPU的缓存复制到CPU可访问的系统共享内存中,再由其他GPU从系统内存中读取,这里就需要CPU的协调和内存复制,数据需要经过2次拷贝才能达到目标GPU。
这种方式仅用于在GPU可能由于硬件或驱动限制,无法有效地利用P2P通信,此时,NCCL通常会退回到使用共享内存作为数据传输的中转站。
优点:这个方案的优势就是灵活性和兼容性,它可以在不支持P2P或者NVLink的情况下提供GPU间通信。
缺点:需要CPU和系统内存参与,且受限于PCIe总线、内存带宽、CPU负载等因素的影响,带宽低、延迟高、传输路径长。
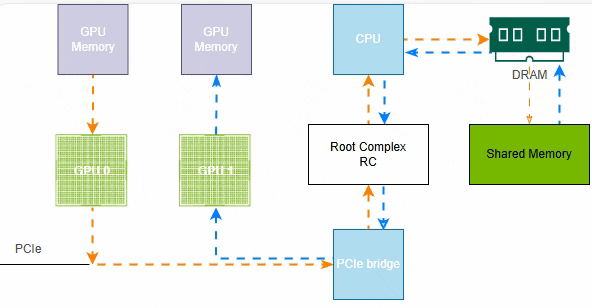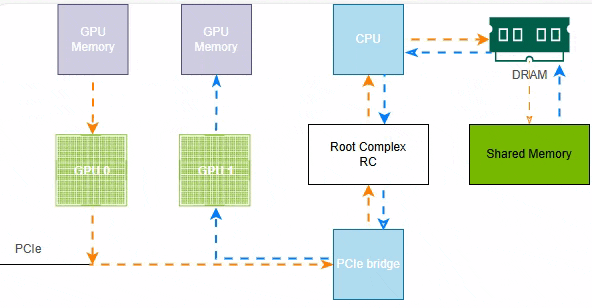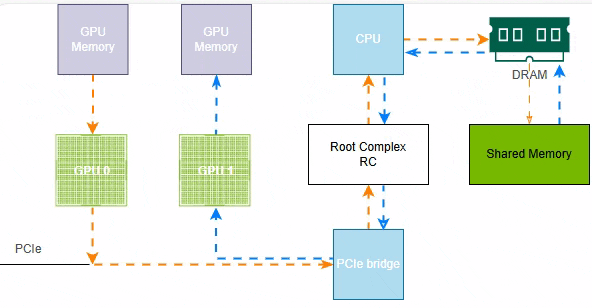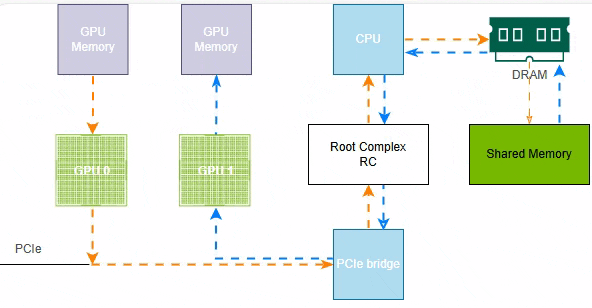
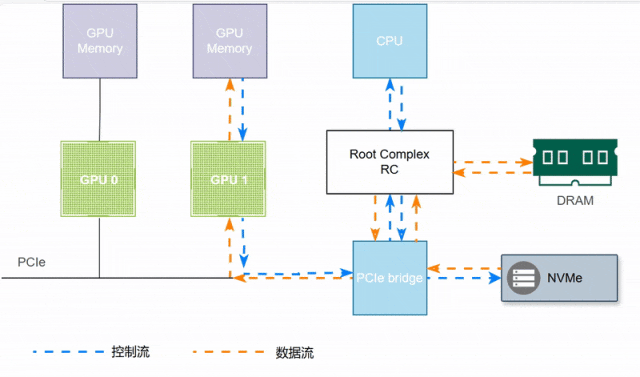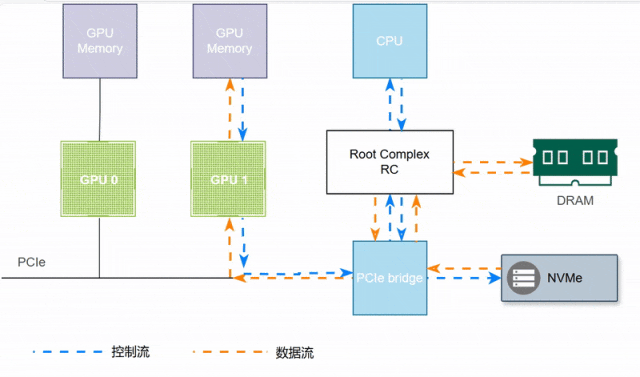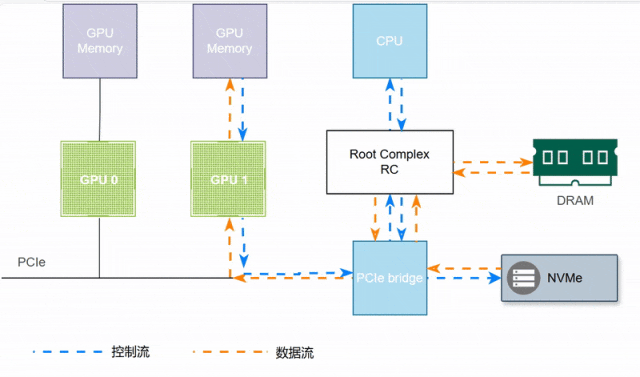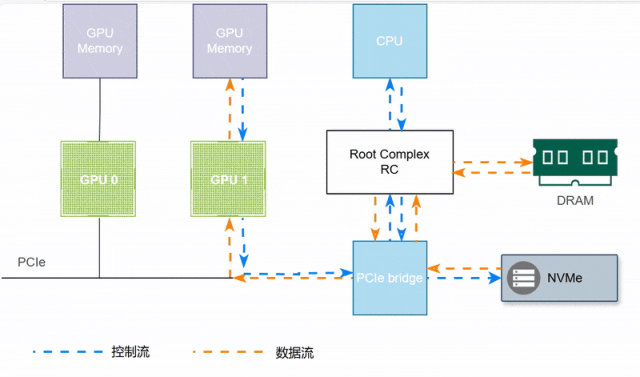
如下示例,受限于硬件条件,无NVLink、不支持PCIe P2P,GPU0的数据要发送给GPU1,首先GPU0的显存数据通过PCIe和CPU协调存储到系统共享内存(Shared Memeory),然后GPU1通过CPU和PCIe将数据读取到GPU1的显存中。
(2)GPUDirect Peer to Peer
在共享内存方式之后,NVIDIA又引入了GPUDirect P2P技术,允许GPU之间直接交换数据而无需经过CPU和系统内存,大大提高了传输的效率。
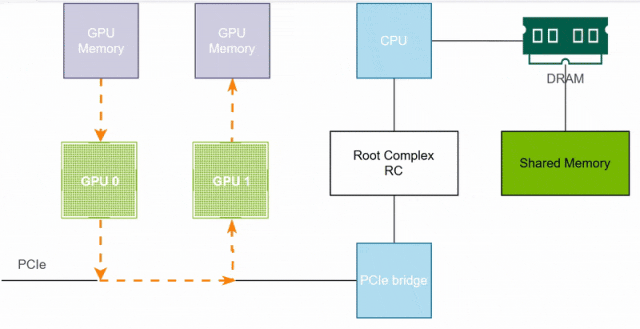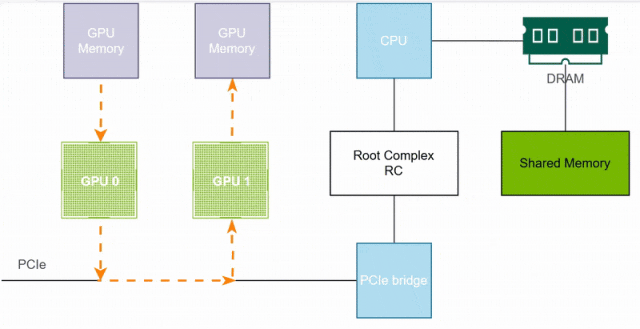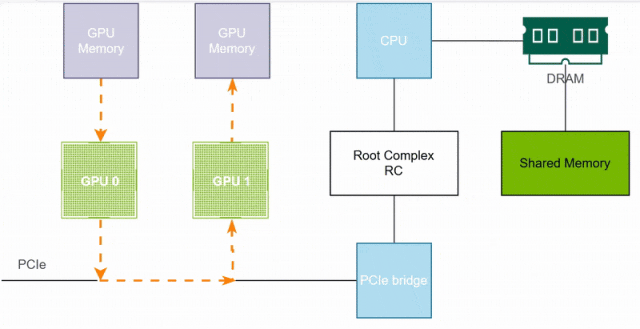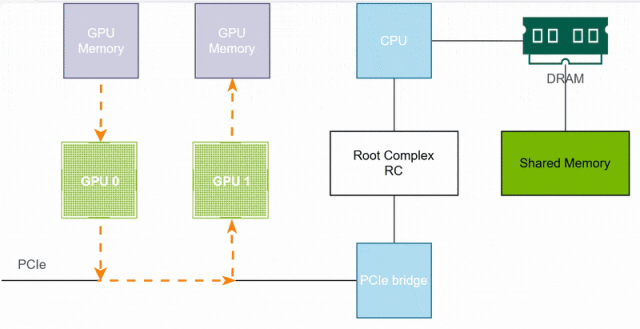
GPU直接绕过CPU和系统内存通过PCIe直接读写另一个GPU的显存,就只有一次数据拷贝,且性能只受限于PCIe带宽和GPU显存带宽,从而减少了数据拷贝、缩短了传输路径、提高了传输带宽以及减少了传输延迟。
GPUDirect P2P通常需要依赖于硬件的DMA技术,所以就需要硬件支持,现在的硬件基本上都支持DMA,所以即使PCIe互联的GPU,也能享受到P2P带来的性能提升。
优点:比起共享内存方式,传输效率高
缺点:需要硬件支持,比如PCIe P2P,受限于PCIe的带宽限制。
在PCIe P2P加持下,GPU0到GPU1的数据传输直接通过PCIe完成,而不再需要系统内存和CPU的协调参与,效率进一步提升。
(3)GPUDirect Storage
随着AI、高性能并行计算的规模逐步变大,传统的存储访问方式也成为其瓶颈,GPU之间数据传输速率能达到双向1.8TB/s(第五代NVLink)的惊人速率,然而即使最先进的nvme盘也只能提供1.3TB/s的顺序读和6000MB/s顺序写带宽,所以数据存储成为计算的瓶颈,且传统的文件读写操作严重依赖CPU和系统内存的协助,会消耗CPU和系统内存资源。
GPUDirect Storage应运而生,它支持GPU显存与本地或者远端存储之间的直接数据通信,避免了CPU和系统内存的参与,大大提升了GPU与存储的传输速率。
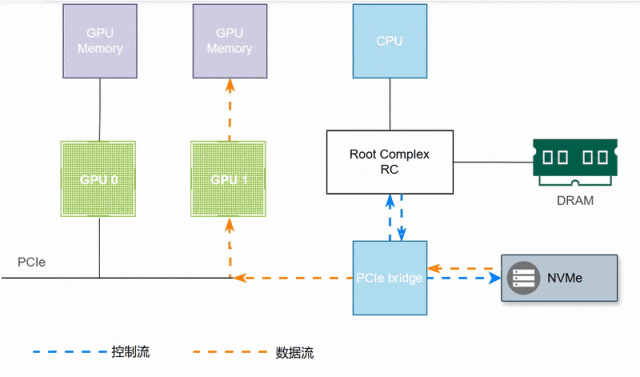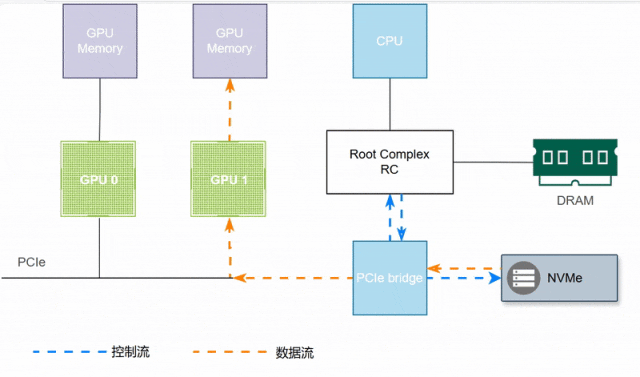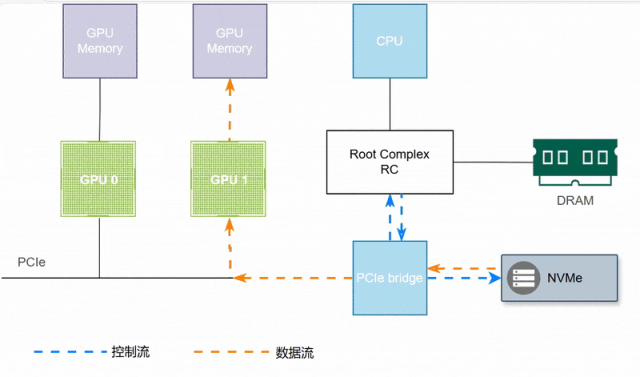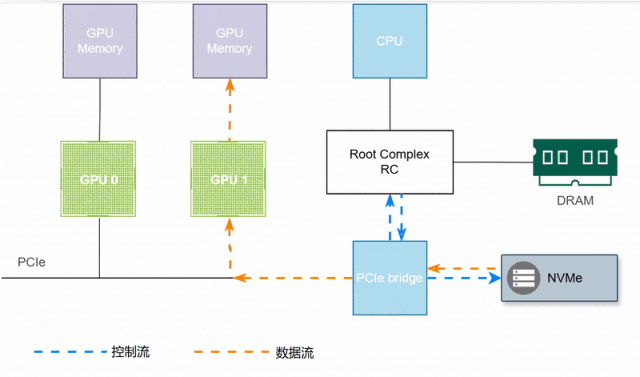
同一节点内,需要依赖于硬件的DMA技术,不同节点需要依赖于网络等环境。
如下图所示,GPU1访问NVMe盘数据,需要CPU和内存的参与,延迟较大。
(4)NVLink&NVSwitch
随着科学计算和大语言模型的飞速发展,对GPU之间的通信带宽和延迟提出了更高的要求,比如一个采用全精度浮点数的70B模型,需要的显存最少280G,单颗GPU无法加载整个模型权重。
这就需要使用模型并行技术来解决单块GPU无法运行单个模型的问题,单机内常用的就是TP技术,它将模型切分到多个GPU卡,每个卡执行部分计算任务,而后将计算结果发送给其他GPU(NCCL里allreduce),这里面就有大量的数据传输,例如Llama 3.1 70B(8K输入token和256个输出token)的单个查询需要从每个GPU传输多达20GB的TP同步数据,因此对于模型比较大的模型推理来说,单机内GPU的数据传输速率需要更高。模型推理需要的带宽如此之高,模型训练需要的带宽更高。
不论是共享内存、P2P都依赖PCIe带宽,PCIe Gen3 x16双向带宽约31GB/s,PCIe Gen4 x16双向带宽63GB/s,也满足不了当前GPU通信带宽需求,成为GPU通信的瓶颈,NVIDIA于2016年发布了全新架构NVLink。
NVLink是一种纵向扩展互联(scale-up)技术,在节点内部提供GPU到GPU高带宽的通信链路,且支持直接点到点连接,具有比传统PCIe更高的传输速度和更低的时延,显著优化了模型训练、模型推理等。
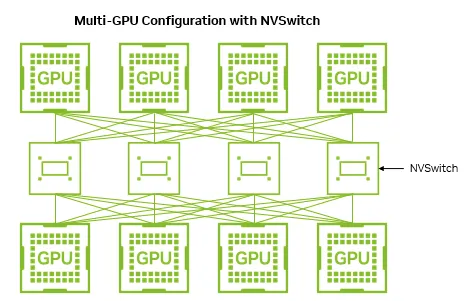
由于NVLink技术不能将节点内的GPU做到全互联,所以NVIDIA在2018年发布了NVSwitch,通过NVSwitch实现NVLink的全连接。
可以看到NVIDIA Hopper架构GPU的NVLink总带宽达900GB/s,是第四代PCIe的14倍:

对应的NVLink4交换机,支持GPU间带宽900GB/s,聚合带宽达7.2TB/s,支持单节点8块GPU:

以配置8块H20 GPU的服务器为例:
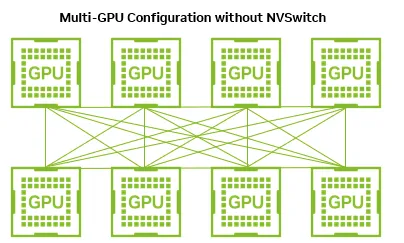
如果没有使用NVSwitch,直接通过NVLink点对点连接,每条链路仅128GB/s:
如果有4个NVSwitch的情况下,NVSwitch实现NVLink的全连接,GPU到GPU之间将提供900GB/s的带宽,仅需22ms就能传输20GB数据。
本文主要介绍了单个节点内,GPU-to-GPU通信依赖的技术,性能由低高依次是,GPU Direct Shared Memory、GPUDirect Peer to Peer、GPUDirect Storage、NVLink&NVSwitch。
GPU Direct Shared Memory是最原始的方案,依赖于系统内存进行数据交换,需要进行多次数据拷贝和CPU、内存等的参与,效率最低,但兼容性最高。
GPUDirect Peer to Peer需要依赖硬件,硬件需要支持DMA和P2P,GPU到GPU数据通信仅依赖PCIe完成,而不用CPU和内存参与,大大提高通信效率,但是受限于PCIe带宽限制,Gen3双向带宽31GB/s,Gen4双向带宽63GB/s,也成为制约GPU通信的瓶颈。
GPUDirect Storage是解决GPU访问存储的问题,科学计算和模型训练,需要加载数据到GPU或者将checkpoint数据存储到磁盘,所以低速的IO将会直接影响计算和训练效率,所以GPUDirect Storage解决了这个问题。
NVLink&NVSwitch是NVIDIA新设计的一套通信技术,GPU通过NVLink与NVSwitch全互联,大大提高了GPU间的通信带宽,相比PCIe提高了14倍,也是目前最主流的互联方案。
