 夜雨聆风
夜雨聆风GitHub 项目地址: https://github.com/InternScience/InternAgent
一、开头
如果你是一个科研工作者,一定有过这样的经历:花了几周时间查阅文献,好不容易想出一个 idea,做实验又花了几个月,最后发现效果还不如 baseline——这种循环不知道消耗了多少科研人的青春。
InternAgent 1.5 试图打破这个循环。这不是又一个"用 AI 写论文"的玩具,而是一个真正能完成从假设生成到实验验证全流程的自主科研系统。它能像一个训练有素的研究生那样,独立完成文献调研、提出创新想法、写出代码、跑实验,甚至根据结果迭代改进。
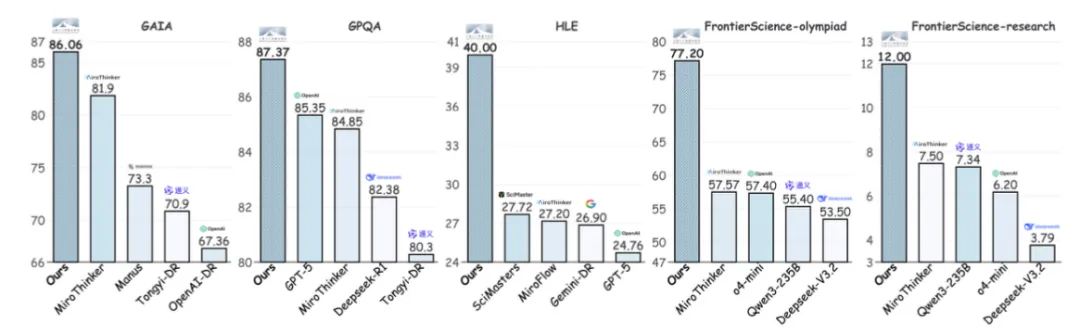
更重要的是,它已经在 GAIA、HLE、GPQA 等多个科学推理基准上取得了世界领先的成绩,而且真的能在化学、生物、地球科学等多个领域做出有价值的发现。
这篇文章,我想带你深入拆解这个项目——它是如何工作的?设计上有什么精妙之处?它真的能替代科研人员吗?
二、项目定位
技术分类
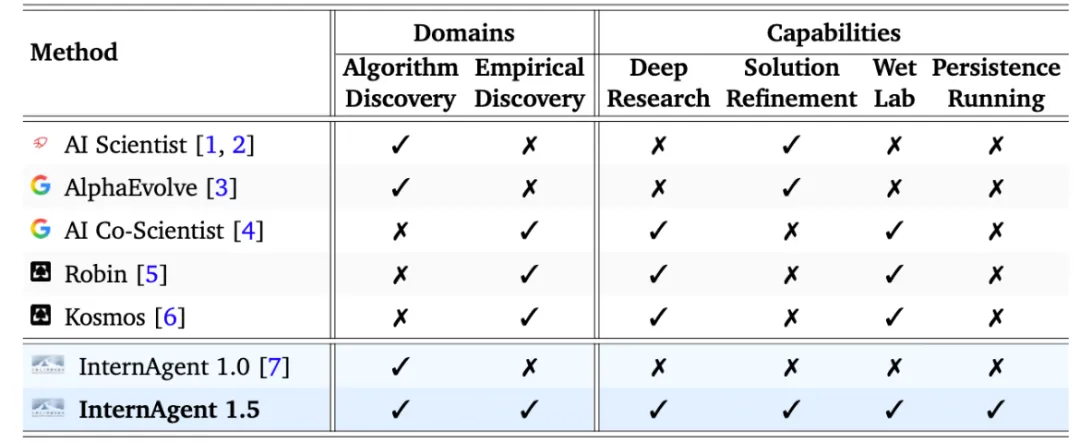
InternAgent 1.5 属于 Agentic RAG + 多智能体协作 的技术路线,但又有本质区别。
简单来说:
普通 RAG 是"查资料回答问题" 普通 Agent 是"按步骤执行任务" InternAgent 是"做科研"——它需要创造性思维、批判性思维、长期记忆和实验验证能力
在 AI 技术生态中,InternAgent 填补了一个重要空白:长周期、创造性的科学发现任务。
面向用户
这个项目的目标用户非常明确:
科研人员——需要快速探索 idea,验证假设 AI 算法工程师——需要优化模型和算法 企业研发团队——需要自动化的研发流程
它不是给小白用的"一键科研"工具,而是给专业人士用的"科研副驾驶"。
对标产品
市面上没有完全相同的产品,但可以做一些对比:
| LangChain | ||
| OpenAI GPT-5 | ||
| AI Scientist | ||
| AlphaEvolve |
我的判断是:InternAgent 代表了 AI for Science 的一个新范式——从"辅助工具"走向"自主主体"。
三、系统架构
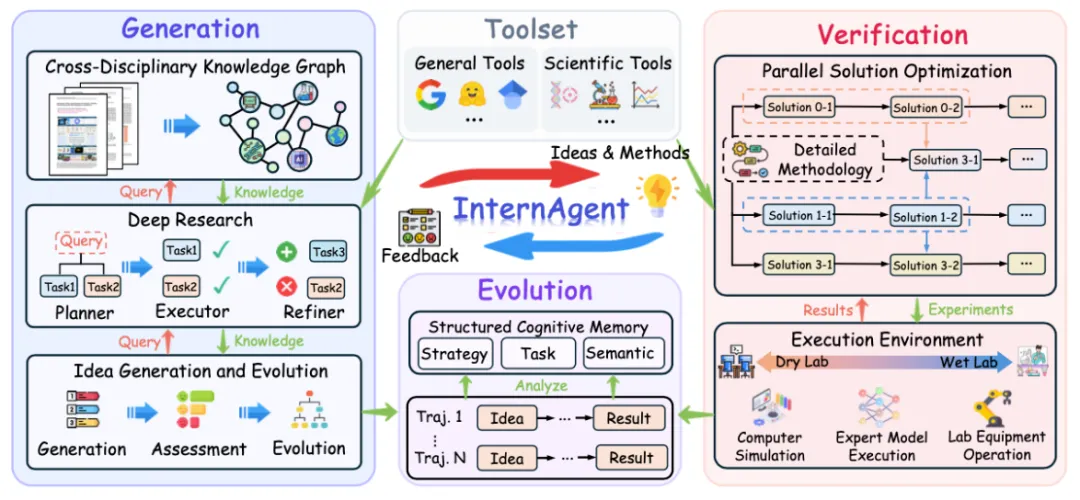
InternAgent 1.5 的架构设计非常优雅,核心是三个子系统的闭环协作:
整体流程
用户输入一个科研任务 → Generation 子系统(深度调研,生成假设)→ Verification 子系统(方案细化,实验验证)→ Evolution 子系统(长期记忆,迭代优化)→ 输出科研成果。
这个流程不是单向的,而是形成一个闭环——实验结果会反馈给 Generation,开始下一轮迭代。
分层架构
让我用更清晰的方式来解释:
1. 输入层
任务定义:用户通过 prompt.json描述目标、领域、背景、约束参考代码:可选的 baseline 代码(文件或整个项目) 配置参数:迭代次数、并发数、模型选择等
2. 调度层
核心是 Orchestration Agent(编排智能体),它像一个项目经理:
管理工作流状态机:INITIAL → GENERATING → REFLECTING → EXTERNAL_DATA → EVOLVING → RANKING → METHOD_DEVELOPMENT → REFINING → COMPLETED 协调各个专业智能体的协作 处理并发任务控制 维护会话持久化
3. 核心层(三个子系统)
Generation 子系统(假设生成):
Generation Agent:生成创新假设 Survey Agent:文献调研 Scholar Agent:证据收集 Reflection Agent:批判性评估
Verification 子系统(验证优化):
Method Development Agent:方法细化 Refinement Agent:方案优化 Experiment Runner:代码生成与实验执行(支持 Aider/OpenHands 后端)
Evolution 子系统(进化迭代):
Evolution Agent:基于反馈进化想法 Ranking Agent:排序筛选 Memory Manager:长期记忆存储
4. 输出层
Top ideas 列表(带评分和理由) 可执行的方法细节 实验结果和日志 完整的科研轨迹可视化
架构图画法
如果你要画架构图,建议这样画:
┌─────────────────────────────────────────────────────────────────┐
│ 用户输入层 │
│ 任务描述 + 参考代码 + 约束条件 │
└─────────────────────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ Orchestration Agent │
│ 状态机管理 · 智能体调度 · 会话持久化 │
└─────────────┬────────────────────┬──────────────────┬───────────┘
│ │ │
▼ ▼ ▼
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ Generation │ │ Verification │ │ Evolution │
│ 假设生成子系统 │ │ 验证优化子系统 │ │ 进化迭代子系统 │
├──────────────────┤ ├──────────────────┤ ├──────────────────┤
│ Generation Agent │ │ Method Dev Agent │ │ Evolution Agent │
│ Survey Agent │ │ Refinement Agent │ │ Ranking Agent │
│ Scholar Agent │ │ Experiment Runner│ │ Memory Manager │
│ Reflection Agent │ │ │ │ │
└──────────────────┘ └──────────────────┘ └──────────────────┘
│ │ │
└────────────────────┼──────────────────┘
│
▼
┌──────────────────┐
│ 输出层 │
│ Ideas + 代码 + 结果│
└──────────────────┘
四、核心模块拆解
让我从工程视角来拆解 InternAgent 的核心模块。
1. Orchestration Agent:整个系统的"大脑"
这个模块在 internagent/mas/workflow/orchestration_agent.py,是整个系统的核心。
它解决什么问题?
多个智能体如何有序协作? 工作流卡住了怎么办? 如何支持人类反馈介入? 如何持久化长周期的科研过程?
设计逻辑:采用了状态机模式 + 回调机制。工作流被拆分成明确的状态,每个状态对应一个智能体的执行。状态转换是确定性的,但也支持通过 "AWAITING_FEEDBACK" 状态暂停,等待人类反馈。
数据流动:
创建会话 → 生成想法 → 反思批判 → 文献调研 → 想法进化 →
排序筛选 → 方法开发 → 方法细化 → 完成
↑_________________________________________________|
(迭代循环)
关键一点:每次迭代的想法都会保留父子关系——你能看到 idea A 进化成了 idea B,这个进化轨迹对科研来说非常重要。
2. Generation Agent:如何生成"靠谱"的创新想法?
代码在 internagent/mas/agents/generation_agent.py。
它解决什么问题?
普通 LLM 生成的想法要么太保守(重复现有工作),要么太天马行空(无法实现) 如何让想法既创新又 grounded in 文献? 如何保证想法的多样性?
设计逻辑:这个模块的设计很有意思——它不是直接让 LLM "想一个 idea",而是:
先做文献调研(可选):如果配置了 do_survey=True,会先调用 Survey Agent 收集相关文献再理解基线代码:如果提供了参考代码,会先分析代码的结构、方法、局限性 最后生成假设:结合目标、文献、代码、背景信息生成多个假设 强制多样性:通过 diversity_threshold确保想法不重复
关键参数:
creativity:0-1,越高越创新,但也越可能不靠谱generation_count:每次生成多少个想法temperature:模型采样温度
数据流动:
任务目标 + 文献 + 参考代码 → 结构化 Prompt → LLM →
JSON 格式的假设列表(包含 text + rationale)
3. Memory Manager:长期记忆是怎么实现的?
在 internagent/mas/memory/ 目录下。
它解决什么问题?
科研可能持续几周甚至几个月,会话不能丢失 需要记住之前尝试过什么、效果如何、为什么失败 跨轮次的知识积累
设计逻辑:采用了多层存储架构:
InMemoryMemoryManager:内存中的快速访问FileSystemMemoryManager:持久化到文件系统统一的 MemoryManager接口
存储的内容包括:
完整的会话状态 所有生成的想法(带父子关系、评分、 critiques) 文献证据 实验结果 人类反馈
设计亮点:每个想法都有 iteration 字段和 parent_id 字段——这意味着你可以完整追溯一个 idea 的进化谱系,这对科研来说太重要了。
4. Experiment Runner:代码生成与实验执行
在 internagent/stage.py 的 ExperimentRunner 类。
它解决什么问题?
想法再好,也要跑实验验证 如何把自然语言描述的方法变成可执行的代码? 实验失败了怎么办?
设计逻辑:这部分采用了双后端设计:
Aider:基于 AI 的代码编辑工具,能渐进式修改代码 OpenHands:另一个实验执行后端(当前版本部分实现)
执行流程:
为每个 idea 创建独立的实验文件夹 复制 baseline 代码 用 Aider 把 idea "翻译"成代码修改 运行实验 对比 baseline 结果
关键点:它不是从零生成代码,而是基于 baseline 进行修改——这大大提高了成功率,也让改进更可控。
五、关键技术点
InternAgent 有几个技术设计特别值得讲,我来分析一下背后的 trade-off。
1. 为什么用"多智能体协作"而不是"单智能体"?
问题: 为什么不让 GPT-5 一个人干所有事?
替代方案:
方案 A:单智能体 + ReAct 模式(思考-行动-观察-思考) 方案 B:多智能体,每个智能体专业化 方案 C:混合方案(InternAgent 选的这个)
InternAgent 的选择: 用多个专业化智能体,但通过 Orchestration Agent 统一调度。
优劣分析:
| 实现复杂度 | ||
| 任务能力 | ||
| Prompt 工程 | ||
| 可维护性 | ||
| 成本 |
我的理解:科研需要不同的思维模式——创造性思维(生成想法)、批判性思维(反思)、工程思维(写代码)。让一个 LLM 同时具备所有这些能力,不如让多个 LLM 各自专精一项,然后协作。
这就像科研团队——有人擅长想 idea,有人擅长做实验,有人擅长写论文——InternAgent 本质上是在模拟一个科研团队的分工。
2. 为什么用"状态机"来管理工作流?
问题: 工作流为什么不做成灵活的 Agent 对话,而是硬编码的状态机?
替代方案:
方案 A:完全自由的 Agent 对话(AutoGPT 早期的方式) 方案 B:固定的状态机(InternAgent 选的) 方案 C:基于规划的动态工作流
InternAgent 的选择: 固定的状态机,但支持人类反馈介入。
优劣分析:
| 灵活性 | ||
| 可靠性 | ||
| 可调试性 | ||
| 用户体验 |
我的理解:科研是一个有明确流程的工作——先调研,再想 idea,再做实验,再迭代。这个流程是相对固定的。
用状态机看起来"笨",但实际上是工程化的选择——它能保证系统不会在某个环节"发疯",也能让用户清楚地知道当前进展到哪一步了。
而且,InternAgent 留了一个"后门"——AWAITING_FEEDBACK 状态,用户可以在这个时候介入,提供反馈。这兼顾了可靠性和灵活性。
3. 为什么要保留"想法进化谱系"?
问题: 只保留最好的 idea 不就行了,为什么要记录所有中间版本?
替代方案:
方案 A:只保留最终结果 方案 B:保留完整的进化谱系(InternAgent 选的)
InternAgent 的选择: 每个 idea 都有 parent_id,记录完整的进化轨迹。
优劣分析:
我的理解:这是 InternAgent 最让我眼前一亮的设计之一。
科研的价值往往不在于最终结果,而在于探索过程——你尝试了什么,为什么失败了,怎么从失败中学到东西,最后怎么找到正确的方向。
保留进化谱系,意味着:
你能复盘整个科研过程 你能从失败的尝试中学到东西 人类科研人员能理解 AI 的"思路" 甚至能在某个中间节点分叉,探索另一条路
这才是真正的"AI 辅助科研",而不是"AI 替代科研"。
六、核心代码讲解
让我挑选几个最核心的模块,用精简的方式来讲。
1. Orchestration Agent:工作流编排
解决什么问题:多个智能体如何按正确的顺序协作,同时支持并发和持久化?
核心思路:用状态机定义工作流,每个状态对应一个智能体的执行,通过回调机制支持状态变更通知。
代码结构:
classOrchestrationAgent:
def__init__(self, config, memory_manager, model_factory, agent_registry):
# 加载配置:最大迭代次数、top idea 数量、并发限制
self.max_iterations = config["workflow"]["max_iterations"]
self.top_ideas_count = config["workflow"]["top_ideas_count"]
self.max_concurrent_tasks = config["workflow"]["max_concurrent_tasks"]
# 依赖注入
self.memory_manager = memory_manager
self.model_factory = model_factory
self.agent_registry = agent_registry
asyncdefrun_session(self, session_id, on_state_change=None):
"""运行会话直到完成"""
session = await self._get_session(session_id)
while session.state notin [COMPLETED, ERROR]:
# 执行当前阶段
await self._execute_current_phase(session)
# 保存状态
await self.memory_manager.store_session(session)
# 检查是否需要等待人类反馈
if session.state == AWAITING_FEEDBACK:
break
return session
asyncdef_execute_current_phase(self, session):
"""根据当前状态分发到对应的处理函数"""
phase_handlers = {
GENERATING: self._run_generation_phase,
REFLECTING: self._run_reflection_phase,
EVOLVING: self._run_evolution_phase,
RANKING: self._run_ranking_phase,
METHOD_DEVELOPMENT: self._run_method_development_phase,
REFINING: self._run_refinement_phase,
EXTERNAL_DATA: self._run_external_data_phase,
}
handler = phase_handlers.get(session.state)
if handler:
await handler(session)
设计亮点:
依赖注入:通过构造函数传入 memory_manager、model_factory、agent_registry,方便测试和扩展 状态机模式:用字典映射状态到处理函数,清晰易维护 持久化:每执行完一个阶段就保存状态,防止崩溃丢失进度
2. Generation Agent:想法生成
解决什么问题:如何生成既创新又靠谱、同时又多样化的科研假设?
核心思路:把文献调研、代码理解、假设生成拆成明确的步骤,通过结构化 Prompt 引导 LLM 输出 JSON 格式的结果。
代码结构:
classGenerationAgent(BaseAgent):
def__init__(self, model, config):
super().__init__(model, config)
self.do_survey = config.get("do_survey", False)
self.generation_count = config.get("generation_count", 5)
self.creativity = config.get("creativity", 0.9)
asyncdefexecute(self, context, params):
goal = context.get("goal", {})
iteration = context.get("iteration", 0)
feedback = context.get("feedback", [])
paper_lst = context.get("paper_lst", [])
# 1. 构建 Prompt(包含目标、文献、参考代码、反馈)
prompt = self._build_generation_prompt(
goal=goal,
count=self.generation_count,
iteration=iteration,
feedback=feedback,
paper_lst=paper_lst
)
# 2. 构建系统 Prompt(根据 creativity 调整语气)
system_prompt = self._build_system_prompt(self.creativity)
# 3. 调用模型,使用 JSON Schema 强制输出格式
output_schema = {
"type": "object",
"properties": {
"hypotheses": {
"type": "array",
"items": {
"type": "object",
"properties": {
"text": {"type": "string"},
"rationale": {"type": "string"}
},
"required": ["text", "rationale"]
}
},
"reasoning": {"type": "string"},
"baseline_summary": {"type": "string"}
},
"required": ["hypotheses", "reasoning"]
}
response = await self._call_model(
prompt=prompt,
system_prompt=system_prompt,
schema=output_schema
)
return {
"hypotheses": response.get("hypotheses", []),
"metadata": {
"count": len(response.get("hypotheses", [])),
"creativity": self.creativity,
"iteration": iteration
},
"baseline_summary": response.get("baseline_summary", "")
}
设计亮点:
JSON Schema 强制输出:用 schema 保证输出格式正确,这是工程化的关键 分层 Prompt 构建:把不同来源的信息(目标、文献、代码、反馈)分开处理 可配置的创造力:通过 creativity 参数和系统 Prompt 调整创新程度
3. Experiment Runner:实验执行
解决什么问题:如何把自然语言描述的方法变成可执行的代码,并自动运行实验?
核心思路:用 Aider 作为代码编辑后端,基于 baseline 代码进行渐进式修改,每个 idea 在独立文件夹中运行。
代码结构:
classExperimentRunner:
def__init__(self, args, logger, config=None):
self.backend = args.exp_backend
self.config = config or {}
defrun_aider_experiment(self, base_dir, results_dir, idea):
# 1. 创建实验文件夹,复制 baseline 代码
folder_name, idea_name = self.setup_experiment_folder(
base_dir, results_dir, idea
)
# 2. 加载 baseline 结果用于对比
baseline_path = osp.join(base_dir, "run_0", "final_info.json")
if osp.exists(baseline_path):
with open(baseline_path, "r") as f:
baseline_results = json.load(f)
else:
baseline_results = {}
# 3. 初始化 Aider
exp_file = osp.join(folder_name, "experiment.py")
notes_file = osp.join(folder_name, "notes.txt")
io = InputOutput(
yes=True,
chat_history_file=osp.join(folder_name, f"{idea_name}_aider.txt")
)
experiment_model = self.config.get("experiment", {}).get("model")
main_model = Model(experiment_model)
coder = Coder.create(
main_model=main_model,
fnames=[exp_file, notes_file],
io=io,
use_git=False,
edit_format="diff"
)
# 4. 执行实验
success = perform_experiments_aider(
idea, folder_name, coder, baseline_results
)
return success
设计亮点:
基于 baseline 修改:不是从零生成代码,而是在现有代码基础上修改,成功率更高 隔离的实验环境:每个 idea 在独立文件夹运行,互不影响 双后端设计:支持 Aider 和 OpenHands,未来可以扩展更多后端
七、完整执行流程
让我用讲故事的方式,带你走一遍 InternAgent 的完整执行流程。
场景设定
假设我们要做一个任务:优化图像分割模型的 mIoU。我们有一个 baseline 实现,现在让 InternAgent 来帮我们改进它。
第一步:任务初始化
用户运行命令:
python launch_discovery.py --task AutoSeg --exp_backend aider
系统做了什么:
加载 tasks/AutoSeg/prompt.json,里面写着任务目标、领域、背景信息读取 tasks/AutoSeg/experiment.py作为 baseline 代码创建一个新的会话,状态设为 INITIAL在 results/AutoSeg/目录准备好输出位置
第二步:想法生成(Generation Phase)
状态:INITIAL → GENERATING
系统做了什么:
文献调研(如果配置了
do_survey=True):调用 Survey Agent 搜索相关论文 比如搜索"medical image segmentation"、"mIoU optimization" 收集最近 3-5 年的重要论文 代码理解:
分析 experiment.py的结构理解当前用的是什么模型(比如 UNet) 识别可能的局限性(比如注意力机制不够、数据增强太简单) 生成假设:
比如生成的想法可能是:
Idea 1:在 UNet 的跳层连接中加入交叉注意力机制,让高层特征指导低层特征 Idea 2:设计一个自适应的损失函数,根据每个类别的难度动态调整权重 Idea 3:用半监督学习的方式,利用未标注数据提升性能 ... 调用 Generation Agent,传入任务目标、文献、代码分析 设定 creativity=0.8(比较创新但不过分) 生成 5 个假设,每个都有 text 和 rationale 保存这 5 个想法,状态转移到
REFLECTING
第三步:反思批判(Reflection Phase)
状态:GENERATING → REFLECTING
系统做了什么:
调用 Reflection Agent,对每个想法进行批判性评估
从多个维度打分:创新性、可行性、科学价值、与目标的相关性
指出每个想法的潜在问题和风险
比如对 Idea 1 的 critique 可能是:
优点:注意力机制是当前的研究热点,有很多成功案例 缺点:计算复杂度会增加,可能影响推理速度 风险:如果注意力设计不好,可能反而降低性能 把 critiques 附加到每个 idea 上
状态转移到
EXTERNAL_DATA
第四步:文献证据收集(External Data Phase)
状态:REFLECTING → EXTERNAL_DATA
系统做了什么:
调用 Scholar Agent,为每个想法寻找支持性文献 对每个 idea,搜索相关的论文,提取证据 比如 Idea 1(交叉注意力),可能找到几篇用注意力机制做分割的论文 把证据和引用附加到 idea 上 状态转移到 EVOLVING
第五步:想法进化(Evolution Phase)
状态:EXTERNAL_DATA → EVOLVING
系统做了什么:
调用 Evolution Agent,基于 critiques 和证据来进化想法
对每个 idea,根据反思意见进行改进
比如 Idea 1 可能进化成:
原始想法:在跳层连接中加入交叉注意力 进化后:在跳层连接中加入轻量级交叉注意力,同时设计一个开关,在推理时可以选择是否启用 每个进化后的想法都有
parent_id指向原始想法把进化后的想法加入会话
状态转移到
RANKING
第六步:排序筛选(Ranking Phase)
状态:EVOLVING → RANKING
系统做了什么:
调用 Ranking Agent,对所有进化后的想法进行排序
从多个维度综合评分:
创新性(30%) 可行性(30%) 预期性能提升(20%) 实现难度(20%) 选出 top-3 想法
把分数和排名附加到每个 idea 上
iterations_completed加 1检查:是否达到最大迭代次数?
如果没有 → 状态转移到 AWAITING_FEEDBACK(可以选择是否给人类反馈)如果达到 → 状态转移到 METHOD_DEVELOPMENT
假设我们设定的最大迭代次数是 2,现在是第 1 次迭代,所以进入 AWAITING_FEEDBACK。
(可选)人类反馈介入
状态:AWAITING_FEEDBACK
系统做了什么:
暂停工作流,等待人类反馈
用户可以查看当前的想法、critiques、分数
用户可以提供两种反馈:
全局反馈:比如"请更多关注推理速度" 局部反馈:比如"Idea 2 很好,但需要考虑显存占用" 如果用户提供了反馈 → 状态转移回
REFLECTING,开始下一轮迭代如果用户没有反馈 → 继续到
METHOD_DEVELOPMENT
假设我们没有提供反馈,直接进入方法开发阶段。
第七步:方法开发(Method Development Phase)
状态:RANKING → METHOD_DEVELOPMENT
系统做了什么:
只处理 top-3 想法
对每个想法,调用 Method Development Agent
把自然语言描述的想法转化成详细的、可实施的方法描述
包括:
比如 Idea 1 的方法细节可能是:
名称:Lightweight Cross-Attention UNet(LCA-UNet) 描述:在 UNet 的每个跳层连接中加入轻量级交叉注意力模块... 实现步骤:1. 定义 CrossAttention 模块;2. 修改 UNetDecoder,在跳层连接处插入注意力;... 方法名称 详细描述 技术原理 具体实现步骤 可能的超参数 把方法细节附加到 idea 上
状态转移到
REFLECTING(这次是反思方法细节)
第八步:方法细化(Refinement Phase)
状态:METHOD_DEVELOPMENT → REFLECTING → EXTERNAL_DATA → REFINING
系统做了什么:
再次调用 Reflection Agent,反思方法细节 再次调用 Scholar Agent,收集更多文献证据 调用 Refinement Agent,进一步细化和优化方法 生成 refined_method_details状态转移到 COMPLETED
第九步:实验执行
现在,想法生成阶段完成了,开始做实验!
系统做了什么:
对 top-3 想法中的每一个: a. 创建独立的实验文件夹,比如
results/AutoSeg/20260411_150000_LCA-UNet/b. 复制 baseline 代码到这个文件夹 c. 创建notes.txt,写下想法的描述和方法细节 d. 初始化 Aider,把experiment.py和notes.txt加入编辑列表 e. 让 Aider 根据想法修改代码 f. 运行实验 g. 保存结果和日志对比每个想法的结果和 baseline
生成总结报告
第十步:输出结果
最后,系统输出:
Top ideas 列表,带评分和理由 每个 idea 的完整进化轨迹 可执行的代码(在实验文件夹里) 实验结果对比 可视化的科研轨迹图
这就是 InternAgent 的完整执行流程——从一个模糊的任务描述,到有创新想法、有代码实现、有实验验证的完整科研过程。
八、业务应用分析
1. 应用场景
InternAgent 不是一个玩具,它有非常明确的业务应用场景。让我讲几个真实的使用场景:
场景 1:AI 算法优化团队
问题:某大厂的算法团队有 20 个算法工程师,每个人手里都有一堆任务要做——推荐系统要优化 CTR、广告系统要优化转化率、视觉系统要提升准确率。但人力有限,很多想法根本来不及验证。
InternAgent 怎么用:
每个算法工程师每周拿出 5 个 idea,喂给 InternAgent InternAgent 自动筛选出最有希望的 2 个,跑实验验证 算法工程师只需要看实验结果,决定要不要深入做
价值:
把"想 idea - 做实验"的周期从几周缩短到几天 能探索的 idea 数量提升 5-10 倍 算法工程师可以专注在最有价值的想法上
场景 2:制药公司的药物发现
问题:新药研发需要筛选大量的分子,成本高、周期长。一个候选分子从发现到上市可能需要 10 年、10 亿美元。
InternAgent 怎么用:
定义任务:"寻找能抑制靶点 X 的小分子" InternAgent 调研文献,生成候选分子假设 用计算模拟验证(dry-lab) 选出最有希望的分子,推荐给湿-lab 实验
价值:
前期筛选的效率提升 100 倍 减少湿-lab 实验的次数,降低成本 能发现人类可能忽略的候选分子
场景 3:材料科学实验室
问题:寻找新材料需要测试大量的配方组合——比如电池材料、催化剂材料。但测试一个配方可能需要几天甚至几周。
InternAgent 怎么用:
定义任务:"优化锂电池正极材料的能量密度" InternAgent 调研文献,提出新的配方假设 用已有的数据训练 surrogate 模型,预测性能 设计实验,推荐最有希望的配方测试
价值:
减少实验次数,加速材料发现 利用历史数据,避免重复造轮子 系统性地探索配方空间,而不是靠直觉
场景 4:中小企业的研发部门
问题:中小企业没有大厂那么多研发资源,但同样需要创新。一个小团队可能只有 2-3 个研发人员,既要做产品又要做研发,根本忙不过来。
InternAgent 怎么用:
把 InternAgent 当成"虚拟研发人员" 研发人员定义好任务,InternAgent 自动探索 每周看一次结果,决定下一步方向
价值:
小团队也能做"大研发" 降低研发门槛,不需要庞大的团队 让有限的人力资源专注在决策上
场景 5:教育和培训
问题:教学生做科研很难——你没法让每个学生都完整经历"查文献-想 idea-做实验"的全过程,因为太费时间了。
InternAgent 怎么用:
作为教学工具,展示完整的科研流程 学生可以观察 InternAgent 怎么想 idea、怎么迭代 学生可以和 InternAgent 协作,提供反馈,一起做科研
价值:
让学生更快理解科研的本质 提供沉浸式的科研训练 激发学生的创新思维
2. 业务价值
InternAgent 的业务价值可以从三个维度来看:
维度 1:效率提升
提升什么:
idea 探索速度:从"几周验证一个 idea"到"一天验证多个 idea" 文献调研效率:从"花几周查文献"到"几分钟完成调研" 实验自动化:从"人工跑实验"到"自动执行和对比"
替代什么:
替代初级科研人员的重复性劳动 替代文献调研的机械工作 替代实验执行的手动操作
是否真的有价值:非常有价值。科研中 80% 的工作是重复性的——查文献、写代码、跑实验、做对比。这些工作完全可以自动化,让人类专注在最有创造力的部分。
维度 2:创新可能性
提升什么:
idea 多样性:AI 能想到人类可能忽略的方向 跨领域创新:AI 能把领域 A 的方法应用到领域 B 系统性探索:AI 能系统性地探索整个假设空间,而不是靠人类直觉
替代什么:
替代"靠灵感想 idea"的模式 替代"只追热点"的跟风式研究 替代"基于直觉筛选"的决策模式
是否真的有价值:非常有价值。历史上很多重大发现都来自"意外"或"跨界"——AI 能系统性地创造这种"意外"。
维度 3:知识沉淀
提升什么:
科研过程可追溯:完整记录 idea 的进化轨迹 失败经验可复用:记录"什么不行",避免重复踩坑 团队知识可传承:新成员能看到之前的探索过程
替代什么:
替代"只记录成功"的论文发表模式 替代"经验装在脑子里"的知识管理 替代"新人重新踩坑"的团队传承
是否真的有价值:非常有价值。科研中最重要的知识往往不是"什么成功了",而是"什么失败了,为什么"。这些知识之前很难沉淀,但 InternAgent 能完整记录下来。
3. 落地难度
是否容易接入?
对于有技术能力的团队:容易
代码开源,文档完整 依赖都是标准的 Python 库 有现成的任务模板可以参考 支持自定义配置
对于没有技术能力的团队:有门槛
需要配置 API keys(OpenAI、Claude 等) 需要理解如何定义任务 需要一定的 Python 基础来调试问题 实验执行需要相应的环境(比如 GPU、科学计算库)
是否适合中小团队?
适合,但需要一些条件
有利条件:
不需要庞大的团队,1-2 个人就能用 不需要自建大模型,用 API 就行 有现成的任务可以直接跑 可以从小规模开始,逐步扩大
需要的条件:
至少有一个懂 Python 的人 需要购买 LLM API(有成本,但不贵) 需要明确的研发目标(知道自己要优化什么) 需要有 baseline 代码或数据
我的建议:中小团队可以从一个具体的小任务开始——比如"优化我们现有的推荐模型"。跑通一个任务后,再扩展到更多任务。
九、优势 & 不足
优势
InternAgent 有几个明显的优势:
1. 架构清晰,工程化程度高
这不是一个研究原型,而是一个真正可用的工程系统。代码结构清晰,模块划分合理,有完整的错误处理和日志记录。
2. 完整的闭环系统
从假设生成到实验验证再到迭代优化,形成了一个完整的闭环。这是很多竞品没有做到的——它们要么只做想法生成,要么只做代码生成。
3. 支持长周期科研
有完整的记忆系统,能持久化整个科研过程。这对需要几周甚至几个月的科研任务来说至关重要。
4. 多智能体协作的设计
模拟科研团队的分工,让不同的智能体专精不同的任务。这种设计既符合科研的实际流程,也能充分发挥 LLM 的能力。
5. 保留完整的进化谱系
这是我最喜欢的设计——能看到每个 idea 的进化过程,知道它从哪里来、为什么变成现在这样。这对科研来说太重要了。
不足
这部分很重要,我会讲得比较直接。
1. 成本不便宜
InternAgent 需要多次调用 LLM,而且是调用能力强的模型(GPT-4、Claude 3 等)。一次完整的科研流程可能需要几十甚至上百美元。
对于小团队或个人来说,这是一个不可忽视的成本。
2. 速度不够快
一次完整的流程可能需要几个小时甚至更长。这是因为:
需要多次调用 LLM 需要等待实验执行 很多步骤是串行的
对于需要快速迭代的场景,这个速度可能不够理想。
3. 对任务定义的要求很高
InternAgent 不是"一键科研"——你需要非常清楚地定义任务:目标是什么?领域是什么?有什么约束?baseline 是什么?
如果任务定义得不好,结果可能会很差。
4. 实验执行的成功率有限
虽然 InternAgent 用 Aider 来做代码生成,但复杂的代码修改还是可能失败。如果代码有 bug,实验跑不起来,整个流程就卡住了。
5. 缺乏真正的"理解"
InternAgent 能生成想法、写代码、跑实验,但它并不真正"理解"自己在做什么。如果遇到完全超出训练数据分布的情况,它可能会给出非常离谱的结果。
6. 业务场景还比较局限
当前版本主要面向算法优化和计算科学,对于需要湿-lab 实验的场景(比如生物、化学),还需要和实际的实验室设备集成,这会增加很多复杂度。
十、对比主流方案
让我们把 InternAgent 和几个主流方案做一个对比。
InternAgent vs LangChain
| 定位 | ||
| 灵活性 | ||
| 易用性 | ||
| 适用场景 | ||
| 学习曲线 |
差异在哪:LangChain 是"乐高积木"——给你一堆积木,你可以拼出任何东西。InternAgent 是"现成的科研机器"——已经拼好了,直接用就行。
如果你需要做一个通用的 Agent 应用,用 LangChain。如果你需要做科研,用 InternAgent。
InternAgent vs OpenAI GPT-5
| 定位 | ||
| 能力 | ||
| 使用方式 | ||
| 需要的工作 | ||
| 成本 |
差异在哪:GPT-5 是"最强大脑"——聪明,但你需要告诉它怎么做。InternAgent 是"完整的科研团队"——不仅有大脑,还有分工、有流程、有记忆。
你可以把 InternAgent 看成是 GPT-5(或其他大模型)的"超级应用"——它把大模型的能力封装成了一个完整的科研工作流。
InternAgent vs AI Scientist
| 覆盖范围 | ||
| 深度调研 | ||
| 方案细化 | ||
| 湿-lab 实验 | ||
| 长周期记忆 |
差异在哪:AI Scientist 是 InternAgent 的前身(或者说竞品),但 InternAgent 1.5 是一个更完整的系统。
AI Scientist 只做算法发现,InternAgent 1.5 覆盖算法发现和实证发现;AI Scientist 没有深度调研,InternAgent 有;AI Scientist 没有长期记忆,InternAgent 有。
简单来说,AI Scientist 是"研究员",InternAgent 1.5 是"完整的科研团队"。
十一、总结
这个项目值不值得关注?
非常值得关注,理由有三:
它代表了 AI for Science 的一个新范式
从"辅助工具"到"自主主体"——这是一个质的飞跃。之前的 AI for Science 工具是"你让它做什么,它就做什么",而 InternAgent 是"你告诉它目标,它自己想办法完成"。
它的工程化程度很高
很多 AI for Science 的项目是研究原型,不好用。但 InternAgent 是一个真正的工程系统——代码清晰、文档完整、有错误处理、有日志记录。拿来就能用。
它已经在真实场景中验证了效果
在 GAIA、HLE、GPQA、FrontierScience 等多个基准上取得了领先成绩,而且已经有实际的科研应用案例。这不是纸上谈兵。
适合谁?
适合这些人:
科研人员——需要快速探索 idea,验证假设 AI 算法工程师——需要优化模型和算法 企业研发团队——需要自动化研发流程 AI for Science 研究者——想了解这个领域的最新进展
不适合这些人:
想"一键得诺贝尔奖"的人——它是辅助工具,不是魔法 完全没有技术基础的人——有一定的使用门槛 预算非常有限的个人——API 成本需要考虑 追求速度的人——一次完整流程需要几小时
最后想说的话
InternAgent 最让我兴奋的不是它的技术有多炫,而是它代表的可能性。
想象一下:未来的科研人员不再需要花几周查文献、几个月做实验——他们只需要定义好问题,AI 就能自动探索成千上万种可能,然后把最有希望的结果呈现在他们面前。
这不是要替代科研人员,而是要解放科研人员——让他们从重复性劳动中解脱出来,专注在最有创造力的部分:定义问题、做出判断、理解结果。
当然,InternAgent 还不完善——成本高、速度慢、有时会失败。但重要的是,它证明了这条路是走得通的。
AI for Science 的未来,可能比我们想象的来得更快。
GitHub 项目地址: https://github.com/InternScience/InternAgent
