 夜雨聆风
夜雨聆风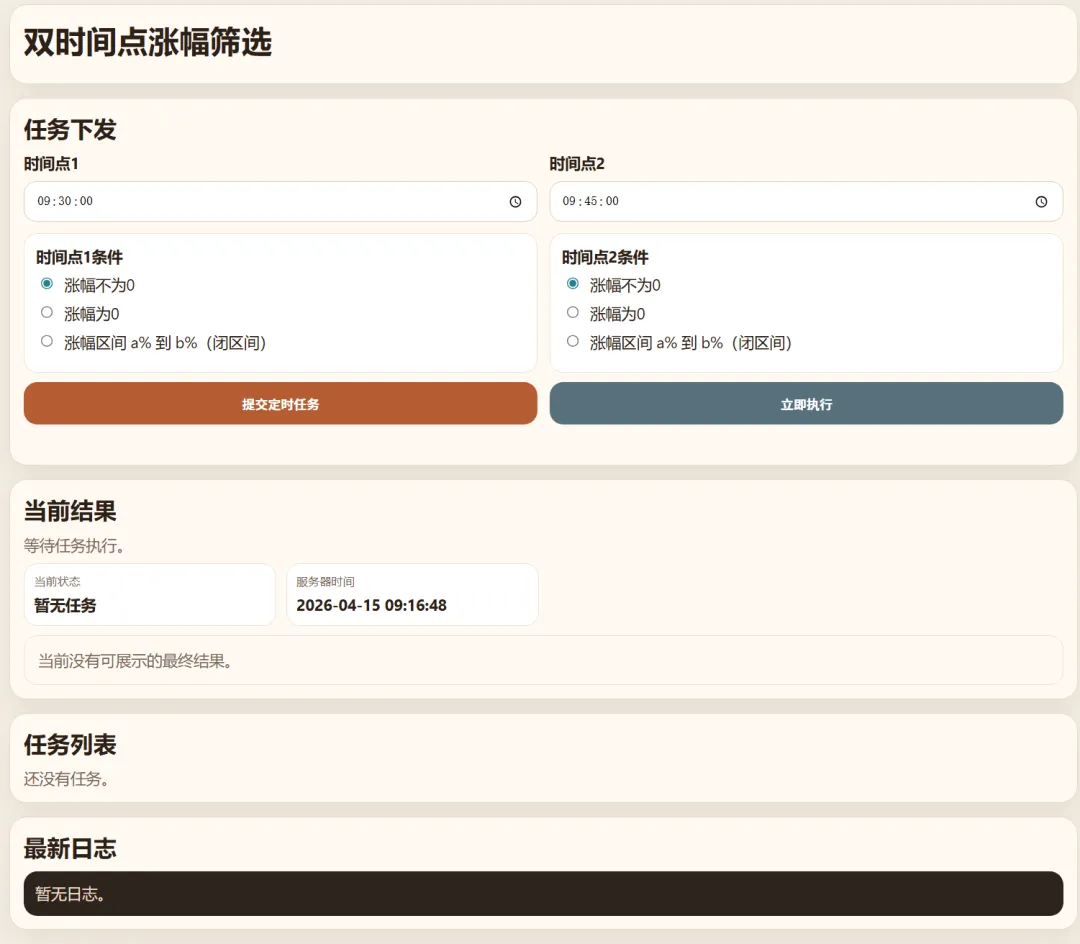
在做量化策略或者平时盯盘的时候,很多交易员都有一种经典的需求:早盘冲高回落过滤。
也就是说,我不想单纯找 9:30 涨停的票,我想找那些 9:30 涨幅在 2%~5% 之间,并且到了 9:45 依然能稳住这个涨幅,甚至继续走高的标的。这种“双时间点”的交叉验证,如果靠人工去翻 5000 多只 A 股,眼睛看瞎了也看不完。
市面上的现成软件要不就是收费昂贵,要不就是条件写死无法灵活定制。于是,周末我决定自己造个轮子,用 Python + Flask 写一套轻量级的双时间点涨幅筛选系统。
今天这篇文章,我就把这个系统的核心架构和几个关键模块剥丝抽茧,跟大家好好聊聊这里面的技术细节和踩过的坑。
一、 背景与真实需求拆解
老规矩,动手写代码前,先要把业务需求拆透。
全市场覆盖:需要能一次性拉取上交所、深交所、北交所(现在北交所的票也不能忽略了)的全量数据。 定时触发与状态保留:系统必须能定闹钟(比如设定 T1=09:30,T2=09:45)。T1 时间点拉完数据后,要把符合条件的标的“存进内存快照”;等 T2 到了,再拉一次数据,跟 T1 的快照做交集比对。 实时反馈:这是一个后端重逻辑的项目,但前端不能“干等”。后台在抓数据、在比对时,前端需要实时看到日志和进度(类似滚动输出的控制台)。
基于这些需求,整体的技术选型非常明确:Flask(Web框架) + ThreadPoolExecutor(并发抓取) + Server-Sent Events (SSE,实时推送) + 全局内存状态锁。
下面我们进入“深度模块化剖析”,看看这套系统是怎么转起来的。
二、 核心模块深度剖析
模块一:高并发的行情抓取(突破单线程瓶颈)
拉取全市场 5000+ 只股票,如果用单线程一页一页去请求新浪财经的 API,拉完一轮可能得花上十几秒。在早盘那种争分夺秒的时刻,这十几秒的延迟是致命的。
所以,这里必须上多线程。但我没有选择无脑拉满线程,而是采用了“分市场分节点 + 小批量分页并发”的策略。
我们来看这部分的核心源码片段:
deffetch_sina_node(node_name, node_desc, log_callback): all_stocks, page = [], 1 log_callback(f"行情中心:正在拉取 {node_desc} 行情数据...") batch_size = 4# 控制并发粒度,防封IPwhileTrue: current_pages = list(range(page, page + batch_size))# 针对当前批次的几页发起并发请求with ThreadPoolExecutor(max_workers=batch_size, thread_name_prefix=f"page-{node_name}") as executor: futures = { executor.submit(fetch_sina_node_page, node_name, current_page): current_pagefor current_page in current_pages } page_results = []for future in as_completed(futures): current_page = futures[future]try: page_results.append((current_page, future.result()))except Exception as exc: log_callback(f"行情中心:{node_desc} 第 {current_page} 页拉取失败,异常:{exc}")return all_stocks# 排序并合并数据,判断是否到达末页 should_stop = Falsefor current_page, data in sorted(page_results, key=lambda item: item[0]):ifnot data: should_stop = Truebreak all_stocks.extend(data)if should_stop:break page += batch_sizereturn all_stocks深入分析:
防止防爬拦截:我将 batch_size 设为 4,相当于一次只并发请求 4 页数据。如果直接 max_workers=100,不仅会把系统的连接池撑爆,极大几率会被新浪的安全策略直接封掉 IP。 顺序一致性保证:并发请求返回的数据是无序的(谁先下完谁先返回)。为了保证最终 DataFrame 数据的规整,代码里用 sorted(page_results, key=lambda item: item[0]) 按页码重新做了排序,然后再拼接到总列表里。 外层再度并发:除了对“页”进行并发,在外部的 get_absolute_full_a_shares 函数中,我还对 sh_a(沪)、sz_a(深)、bjs_a(北)三个大节点再次使用了 3 个线程的并发。这种“二维并发”直接把全市场拉取时间压缩到了 2-3 秒以内。
模块二:时间点状态机与任务调度(内存快照的艺术)
这个系统最复杂的地方在于状态转移。一个定时任务创建后,它有多个生命周期:等待T1 -> 执行T1 -> 等待T2 -> 执行T2 -> 完成。
传统的做法可能会搞个 Celery + Redis,但对于这种单机轻量级工具,引入庞大的中间件不仅加重部署负担,维护起来也让人头大。我直接用了一个后台死循环线程配合全局字典来做内存调度。
STATE_LOCK = threading.RLock() # 可重入锁,保护状态一致性TASKS = {} # 全局任务字典defscheduler_loop():whileTrue: s1, s2, now = [], [], datetime.now()with STATE_LOCK:for task_id in TASK_ORDER: task = TASKS[task_id]if task["mode"] != "scheduled":continue# 检查T1是否触发if task["status"] == "pending_t1"andnot task["stage1_started"] and task["t1_run_at"] and now >= task["t1_run_at"]: task["stage1_started"] = True s1.append(task_id)# 检查T2是否触发elif task["status"] == "waiting_t2"andnot task["stage2_started"] and task["t2_run_at"] and now >= task["t2_run_at"]: task["stage2_started"] = True s2.append(task_id)# 离开锁的作用域后再启动实际任务,防止阻塞调度器for task_id in s1: threading.Thread(target=run_stage1, args=(task_id,), daemon=True).start()for task_id in s2: threading.Thread(target=run_stage2, args=(task_id,), daemon=True).start() time.sleep(1)深入分析:
**可重入锁 (RLock)**:在这个应用中,不仅调度器需要读写 TASKS,HTTP 请求(比如用户强制取消、查询状态)也在操作它。如果不加锁,极易引发字典的 RuntimeError: dictionary changed size during iteration。 锁的颗粒度控制:注意看代码,我是先在 with STATE_LOCK 里把该触发的任务 ID 找出来(放入 s1, s2),然后退出锁的上下文,再去开启线程执行 run_stage1。如果在锁里面去发 HTTP 请求拉数据,整个 Web 都会被卡死。 内存快照隔离:在 run_stage1 结束后,会调用 save_snapshot 将当时的 Pandas DataFrame 挂载到对应 task 的字典里。等到 run_stage2 触发时,再从内存中把这块数据取出来做 .isin() 的交集计算。干净利落,无需落盘。
模块三:基于 SSE 的前端实时通讯(告别轮询)
既然是“盯盘”,用户界面的实时性必须拉满。我没有选择用 Ajax 每秒轮询(太浪费资源,且容易漏日志),也没有用 WebSocket(对于单向推送来说偏重了)。最终的杀手锏是 **Server-Sent Events (SSE)**。
SUB_LOCK = threading.Lock()SUBSCRIBERS = []defpublish_state():# 每次状态变更,序列化为JSON格式 payload = json.dumps(build_state(), ensure_ascii=False)with SUB_LOCK: dead = []for q in SUBSCRIBERS:try:# 非阻塞放入队列 q.put_nowait(payload)except queue.Full:# 队列满了说明客户端卡死或断开了 dead.append(q)for q in dead:if q in SUBSCRIBERS: SUBSCRIBERS.remove(q)@app.route("/stream")defstream(): q = queue.Queue(maxsize=20)with SUB_LOCK: SUBSCRIBERS.append(q)defgen():# 初次连接推送一次全量状态yieldf"data: {json.dumps(build_state(), ensure_ascii=False)}\n\n"try:whileTrue:# 阻塞等待事件发布yieldf"data: {q.get()}\n\n"except GeneratorExit:passfinally:with SUB_LOCK:if q in SUBSCRIBERS: SUBSCRIBERS.remove(q)return Response(gen(), mimetype="text/event-stream", headers={"Cache-Control": "no-cache", "X-Accel-Buffering": "no"})深入分析:
发布-订阅模式:每当有新用户打开网页,/stream 路由就会创建一个 queue.Queue 并塞进全局的 SUBSCRIBERS 列表里。后台的调度器、数据抓取模块只要产生了新日志,调用 publish_state() 就会往所有存活的队列里广播数据。 连接保活与自动清理(重点):SSE 经常遇到的坑是“僵尸连接”占用服务器内存。我们在 publish_state 中使用了 put_nowait,一旦捕捉到 queue.Full 异常,就断定该客户端已断开但还没走完整的挥手流程,果断将其列入 dead 列表并清除。 Nginx 兼容性:注意 Response 里的头信息 X-Accel-Buffering: no,如果你把这个应用部署在 Nginx 后面,没有这行代码,Nginx 会把 SSE 的流数据缓存起来,导致前端根本看不到实时逐行的日志,这个坑我替你们踩过了。
三、 难点与坑点总结
复盘整个开发过程,其实写业务逻辑花的时间很少,大部分时间都在处理并发与时序的边角料问题:
时间跨日问题:如果我在晚上 23:00 下发了一个明天早盘 09:30 的任务,时间解析器容易默认是“今天的 9:30”(这在时间戳上属于过去时间)。所以必须在 next_schedule 函数里计算当前时间与目标时间的差值,智能加上 timedelta(days=1)。 Pandas 数据清洗的容错性:新浪接口返回的个股数据,有时候停牌股的涨跌幅是空字符串 "",有时候退市股价格是 0。在做 DataFrame 处理时,必须严格使用 pd.to_numeric(df[col], errors="coerce"),否则在执行 s.between() 涨跌幅筛选时会直接报 TypeError 导致整个任务崩溃。 资源泄漏管控:用 Python 原生的 threading 跑后台任务,最忌讳异常没有 catch 住,导致僵尸线程。所有的 run_stage1 和 run_stage2 必须被 try...except 严丝合缝地包裹,并在 except 中调用 fail_task 释放资源。
四、 写在最后
这套系统算是一个比较典型的“麻雀虽小,五脏俱全”的 Python Web 实战案例。它没有用到极其高深的设计模式,但把多线程、锁、内存调度、长链接这些实打实的技术串联在了一个真实的业务场景里。
做量化也好,写工具也罢,很多时候我们不需要一开始就上微服务、上大数据中间件。用最精简的代码,稳健地解决当下最痛的需求,这种“掌控感”才是写代码最让人着迷的地方。
希望这篇文章对你有所启发。如果你有更好抓取全市场快照的思路,或者对状态机的写法有更优雅的方案,欢迎在评论区一起交流探讨!
