 夜雨聆风
夜雨聆风你有没有装过一个东西,花了很长时间搞配置,搞完之后发现自己也不太清楚要拿它干嘛?
我最近就干了这么一件事。
OpenClaw,GitHub 24 万 star,社区里到处都是人在晒自己的 Agent 帮他们干了多牛逼的事情。有人让它自动报税,有人让它在睡觉的时候帮忙 review 代码,有人让它自己去 Google Cloud Console 配 OAuth。
说真的,我看到这些 case 的时候,也觉得太酷了。
我自己也装了,一开始用的还行。用的 Claude 的 Max 订阅账号,主要跑一些重复的自动化任务。
但前段时间,Claude 的订阅号被禁了。好吧,那我换 Codex 试试?结果 Codex 接进去之后,tool using 一直有问题。我在飞书上让它写代码完成某个任务,它偶尔写一次,大部分时候回复都是「我前面确实没做,现在我立马去做」,然后。。。还是没做。
就是那种,嘴上答应得特别好,手上一点没动的感觉。
我到现在也不确定是什么原因。可能是我的配置有问题,可能是订阅账号本身的限制,也可能是别的什么。但折腾了一圈下来,那个东西就是没跑起来。
然后我就开始想一个问题。
我到底需要 OpenClaw 做什么?
这个问题听起来太简单了,简单到大部分人都没认真想过。包括我自己,之前也没想过。看到 OpenClaw 火了,看到大家都在玩,就觉得我也应该搞一个。至于搞来干嘛,好像没仔细想。很多人是因为焦虑,怕被落下,就冲了进去。
但当你真的被门槛挡住的时候,你就不得不想了。
先说钱:OpenClaw 是真的烧钱
你可以用 Claude、GPT-4o、Gemini,也可以本地跑模型,但如果你想要靠谱的推理能力和大上下文窗口,基本上只能选云端的 frontier model。社区里的反馈是:
• 轻度用户:每月 5 到 20 刀 • 活跃用户:50 到 150 刀 • 不优化的重度用户:花到上千刀的都有
关键是 OpenClaw 有个 heartbeat 机制,默认每 30 分钟心跳一次。每次心跳,它要把 system prompt、对话历史、tool schema、skills、memory 全部打包发给模型,让模型判断有没有需要处理的事情。大部分时候模型会回一个「HEARTBEAT_OK」然后什么都不做。
但 token 已经烧掉了。
always-on 的模式,token 是持续在烧的,即使它什么都没干。

回到那个问题:我的需求到底是什么?
我认真回想了一下自己日常想让 Agent 做的事情:
• 发飞书群消息 • 爬个网站的数据 • 提个 GitHub PR • 按固定格式出个报告 • 每天把一批信息源的内容抓过来整理一遍
你发现没有,这些事有一个共同点。
流程是固定的。
每次做的步骤一模一样。不需要 Agent 自己判断该怎么做,不需要它临场发挥什么创造力,不需要它在凌晨三点帮我处理一个突发事件。就是,你跑一遍,跑通了,以后每次照着跑就行。
等等。
我回头看了一眼自己之前用 OpenClaw 做的事,不就是这些吗?主要跑一些重复的自动化任务,这是我自己说的。
也就是说,我花了那么大力气去搞 OpenClaw,结果用它做的事情,根本不需要一个 always-on 的 Agent。
想明白这件事之后,我就不纠结了。
一个 Cowork 就够了
可能很多朋友对 Cowork 还不太熟悉,简单聊两句。Cowork 是 Claude 桌面端里的一个模式,今年 1 月发布的,4 月 10 号刚正式 GA。跟普通的 Chat 不一样的地方在于,它可以直接读写你本地的文件,可以接 MCP,可以设定定时任务自动跑,可以多步骤自动执行。你可以理解为 Claude Code 的能力,但不需要开终端,不需要写代码,选个文件夹就能开始。
关键是,它包含在 Claude Pro 的 20 刀月费里。不额外花钱。
对比一下,OpenClaw 每月光 API 就要几十上百刀,还有心跳在后台持续烧 token。Cowork 只在你设定的时间跑,跑完就停。同样的固定流程,一个烧钱,一个不额外花钱。
实战案例:follow-builders
我拿自己最近做的一个项目给你看看,你就明白了。
Github 有个叫 follow-builders 的开源项目,专门追踪 AI 领域一批顶级 builder 的动态,Kevin Weil、Aaron Levie、Garry Tan、Peter Yang、Guillermo Rauch 这些人都在列表里。他们每天在 X 上发的动态和播客里聊的内容,信息密度很高。但这些信息散落在各处,我自己一个个去追太累了。
所以我想做一个东西,每天自动把这些人的最新动态抓过来,生成中英文摘要,推到一个网站上,方便我自己看,也方便读者看。
如果是以前,我可能会想,这是不是得用 OpenClaw?毕竟涉及定时任务、爬数据、调 API、生成内容、推 GitHub,听着就很「Agent」。
但我实际做的时候,就开了一个 Cowork,选了一个本地目录,然后开始口喷。
没写一行配置文件,没开终端,没装任何依赖。 就是像跟同事聊天一样,把需求说出来。
它先跟我讨论了一下 plan,数据从哪来,格式怎么定,怎么去重,怎么推到 GitHub。我说用 follow-builders 这个 skill 去抓推文和播客内容,按日期和作者分组,每条生成中英文摘要,用链接做唯一标识去重,通过 GitHub MCP 推送。
讨论完之后,它直接开始干活了。
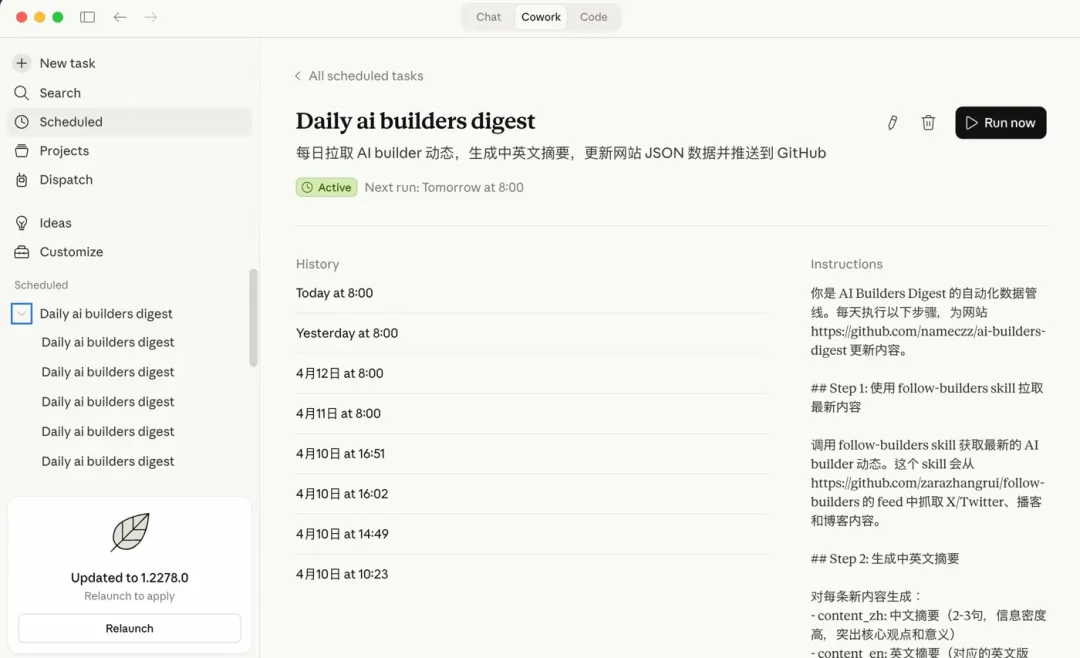
从整个 repo 的创建,代码的逻辑,数据格式化,数据存储方案,通过 GitHub MCP push 到 Github。然后 schedule 的设置,每天早上 8 点自动执行,数据管线的配置——拉取最新动态,获取推文全文,抓播客摘要,生成数据条目,去重合并,校验,最后推送到仓库——Cowork 也都帮我完成。
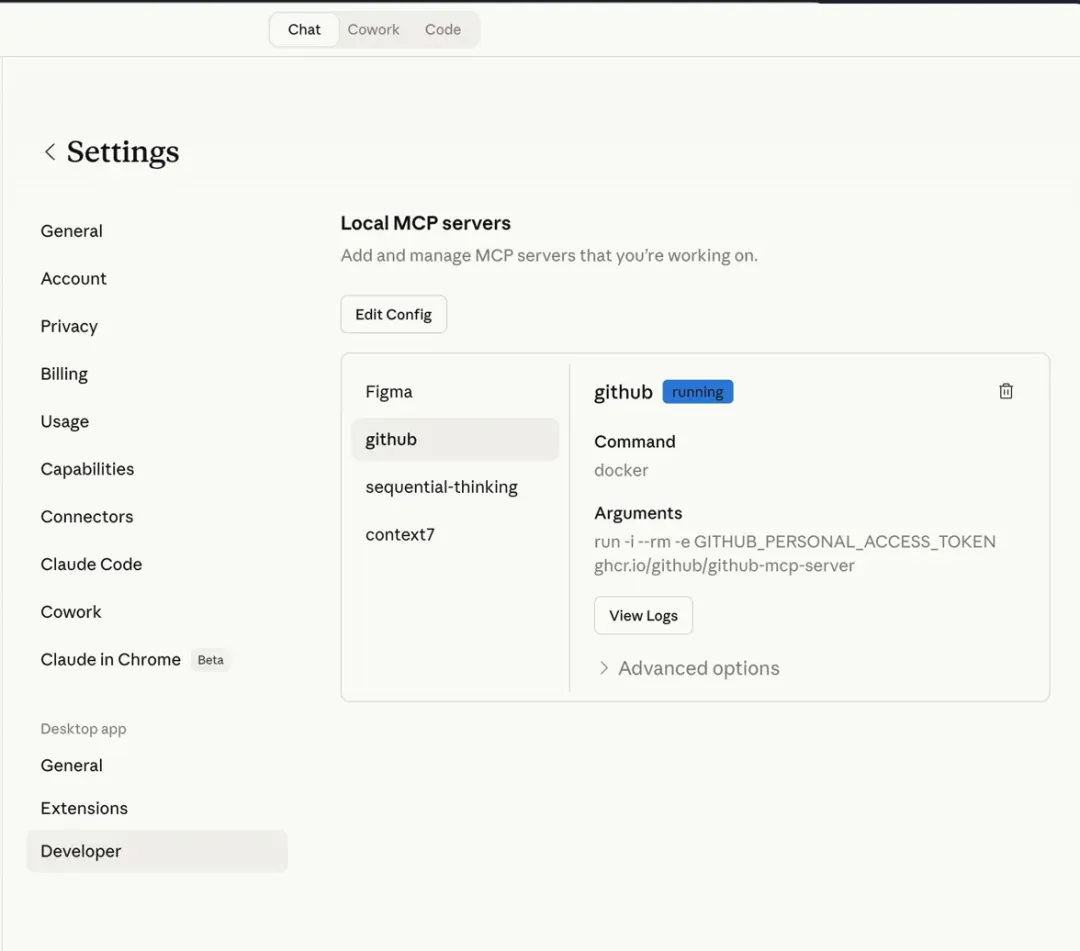
全程在 Cowork 里完成。
我唯一手动做的事情,就是绑了一下 Vercel 和域名。
这不是一个 demo
这个东西从 4 月 10 号开始,每天早上 8 点准时执行,到今天没断过。你看一下某天的执行记录,它跑了十几步:检查现有数据格式,拉推文全文,获取播客摘要,写 Python 脚本处理数据,去重合并,校验,推送 GitHub。最后的 summary 写着,Added 15 new entries,总共 51 条数据。
还贴心地列出了当天的重点内容,Claude Code 的新功能 ultraplan,Sam Altman 发了篇 9000 多赞的 essay,Aaron Levie 分享了跟企业 CIO 交流的七大发现。

最后跑出来的网站长这样。
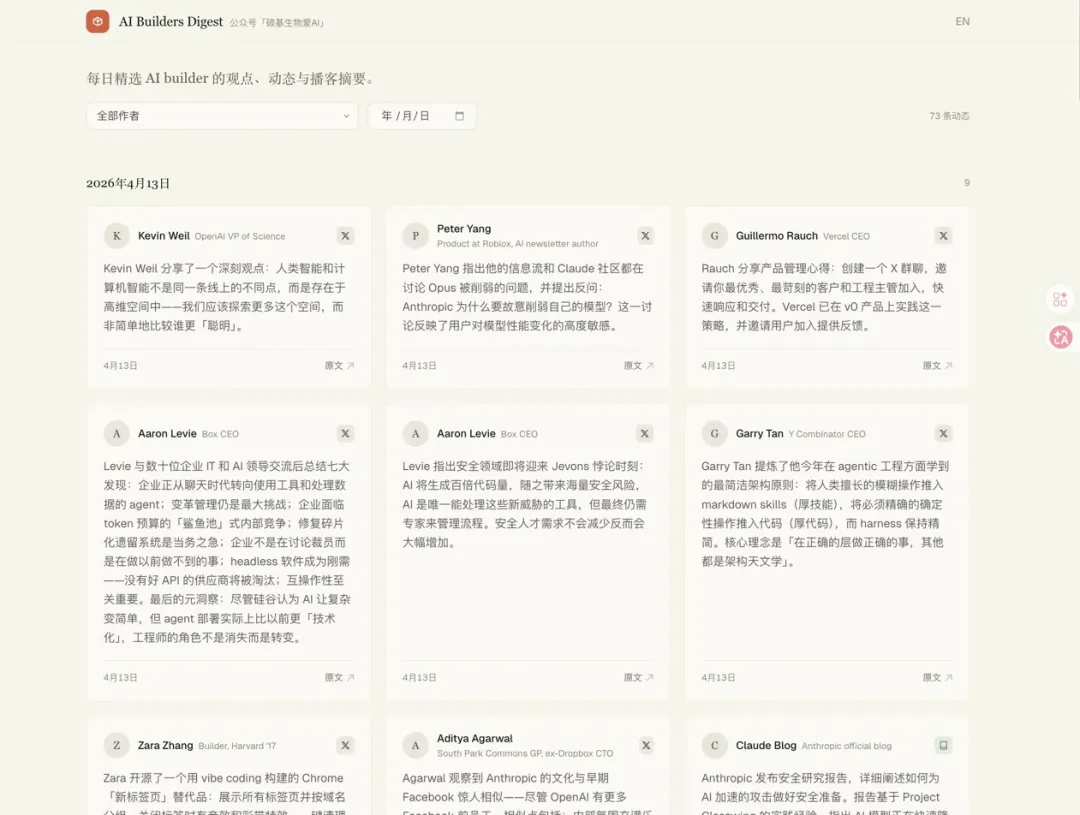
sanyoumu.dev,每天更新,按日期和作者分类,每条动态都有中英文摘要和原文链接。目前已经累积了 73 条动态。
一个完整的数据产品。从构思到上线,除了绑域名之外,全部在 Cowork 里口喷完成。
你的工作里也一定有类似的东西。每天检查一下 GitHub 有没有新 issue 然后把摘要发到群里,每周把散落在各处的文档汇总成一份周报,每次写完文章之后按不同平台的格式裁剪一遍。这些事,步骤固定,输入输出明确,一个 Cowork 加上对应的 MCP 就能搞定。
但 OpenClaw 也不是没用
坦率的讲,有些事情 Cowork 确实做不到。你需要一个 24 小时在线的个人助手,能自己判断什么时候该做什么,能在你不在电脑前的时候帮你处理突发事件,能跨十几个平台协调复杂任务,能遇到意外情况自己想办法解决。这种「助手级别」的 Agent,需要 always-on,需要自主判断,需要持续记忆。OpenClaw 就是为这个设计的。
Cowork 不行。它需要你的桌面端一直开着,需要你事先把流程定好,它不会自己决定该干什么。
但问题是,你真的需要一个 24 小时在线的 AI 助手吗?
Agent 需求的两层框架
我觉得 Agent 的需求其实分两层。
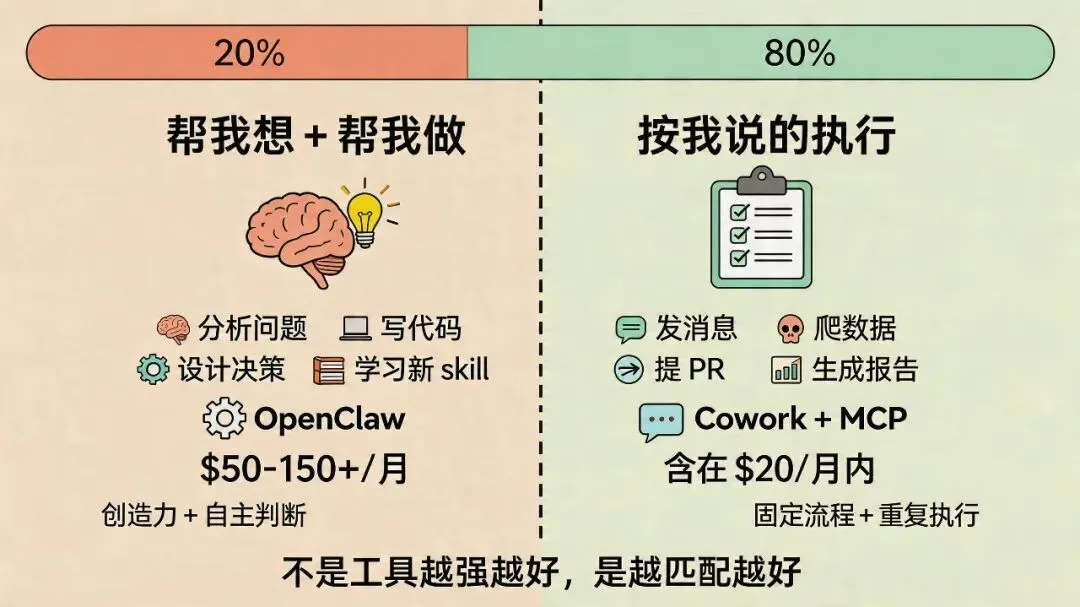
| 特点 | ||
| 典型场景 | ||
| 推荐工具 | ||
| 成本 |
我自己的感受是,日常工作里,80% 的需求在第二层。
那 20% 的创造性工作,确实需要重型武器。但剩下 80% 的重复性流程,一个 Cowork 就能覆盖。何必每个月多花一百多刀去养一个 always-on 的 Agent?
不是工具越强越好,是越匹配越好。
想清楚自己需要什么,比选哪个工具重要得多。
如果这篇帮你理清了一点思路,帮我点个赞、在看、转发三连,你每次的互动都让我觉得这些折腾没白费。
我们,下篇见。
