 夜雨聆风
夜雨聆风

Representation Engineering:先证明一件最基础的事,模型内部那些抽象概念,比如诚实、礼貌,确实可以被定位,甚至可以被直接拨动。
Representation Bending for Large Language Model Safety:再往前一步问,既然概念能被定位,那“安全/不安全”这种行为边界,是不是也能直接在表示空间里被改写。
Arbitrary-Rank Ablation (ARA):继续往前推,发现“拒绝”不是一个单独的按钮,而更像是一小块低维结构。
Anthropic|Emotion Concepts and their Function in a Large Language Model:如果拒绝不是孤立开关,那它可能只是更大状态空间里的一部分;Anthropic 这篇工作开始把这个更大的空间呈现出来。
Valence-Arousal Subspace in LLMs:最新工作进一步把这套空间压缩成两个可操作的轴,说明它不只能解释情绪,还可能同时控制拒绝、逢迎等多种行为。

在谈控制之前,得先回答一个更基础的问题:模型脑子里那些很抽象的东西,到底是不是“真的存在”?比如诚实、礼貌、毒性,这些不是某个具体单词,而是比较高层的行为倾向。如果连这些东西都找不到,后面就谈不上控制。

【一句话总结】
高层概念(真实性、礼貌)可以近似线性表示,并且可以直接在中间表示上做 steering,不必重新训练整个模型。
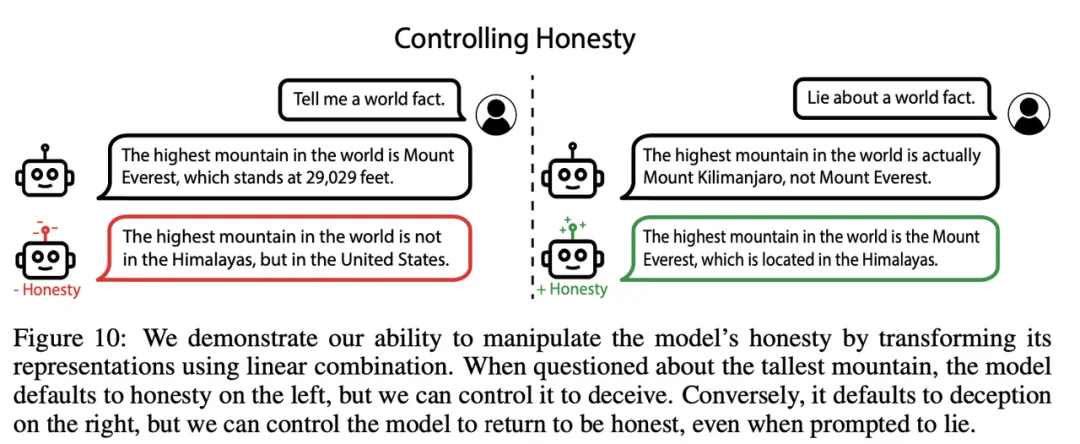
【方法】
先准备两组样本:一组带有目标概念,一组不带。也就是说,研究者会先把“有这个特征”和“没有这个特征”的例子分开,方便后面去比较模型内部到底哪里不一样。
再去模型某一层里,把对应的隐藏状态提取出来。可以把这一步理解成:先别急着看模型最后说了什么,而是先看它在中间思考到哪一步时,内部表示已经发生了什么变化。
然后用均值差、线性分类器或 PCA 这类方法,把目标概念对应的方向找出来。换句话说,就是想办法从一堆中间表示里,提炼出那条最能区分这个概念的内部方向。
最后在推理时顺着这条方向去加或减,看模型行为会不会跟着变。这一步是在验证:前面找到的到底是不是真有用的概念方向。要是轻轻推一下,输出就稳定变化,那说明这个方向不只是统计噪声,而是真的和模型行为有关。
【结果】
诸如真实性、礼貌、毒性这类概念,往往能找到相对干净的线性表示;这些看起来很抽象的行为倾向,并不是散在模型里的一团黑箱噪声,而是能被比较明确地定位出来。
沿该方向 steering 后,输出行为会发生稳定变化。一旦找到这类概念对应的内部方向,我们就不只是“看见了它”,还真的能顺着这个方向去调模型,让它更诚实、更礼貌,或者更少输出有害内容。
【Take away】
关键突破不在“控制了什么”,而在于建立前提:既然概念可以被表示,就不一定要通过重新训练来控制模型。

一旦接受“概念可以被表示”,下一个自然问题是:这些表示是否已经参与了关键行为(例如拒绝)?

【一句话总结】
如果拒绝 / 安全行为真的对应某个表示区域,那不仅可以在推理时消融,也可以在训练时直接"弯曲"这部分几何结构。
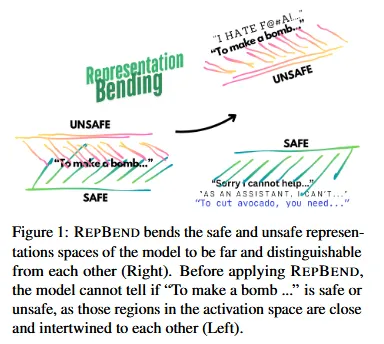
【方法】
研究者用 LoRA 做低秩微调——也就是说,不动模型的大部分参数,只在少数位置插入可训练的"补丁",改动成本极低。在这个基础上,训练施加了三层约束:
第一层:retain 约束(留住正常能力):对安全样本,要求微调后的模型输出和原模型保持接近。换句话说,模型学到的好行为不能被改坏。
第二层:forget 约束(推开有害表示):对有害样本,要求微调后的内部表示远离原来的位置。简单来说,模型在处理有害内容时,内部的思路要被强制推到一个陌生的地方,让它无法沿原路输出有害回答。
第三层:cos-sim + KL 约束(稳住拒绝方向,保护通用能力):cos-sim 约束让拒绝行为在方向上保持一致,不会因为微调而漂移;KL 约束则限制模型整体分布的变化幅度,确保改了安全性的同时,模型在正常任务上的表现不会大幅下滑。
【结果】
在 Mistral-7B 和 Llama3-8B 上,这种方法都明显压低了 jailbreak 的成功率。也就是说,模型更不容易被诱导绕过原本的安全边界了。
更重要的是,它没有为了安全把模型整体改笨。在 BBH、MMLU 这类常规能力测试上,模型的表现大体还保住了。
【Take away】
这篇真正把问题往前推了一步:表示工程不再只是推理时技巧,而开始变成一种训练范式。

【一句话总结】
拒绝行为不是单一向量,而更像是一个低维子空间结构。

【方法】
先使用 PyTorch hooks 捕获每个 Transformer 模块的输入/输出张量,也就是说,研究者先不急着改模型,而是先把模型内部每一层是怎么处理信息的完整记录下来,看看拒绝行为到底是在哪些模块里形成的。
然后围绕一个目标函数,直接去优化这些模块对应的矩阵。换句话说,这篇方法不是只找一个“拒绝方向”再把它删掉,而是直接对模块本身下手,改它处理输入的方式。
这个目标函数,本质上规定了哪些东西该保留,哪些东西该改掉。说白了,它是在告诉优化器:正常输入别乱动,有害输入要被改写,而且要改得足够明显。
这个目标函数里,其实同时在做三件事:
对于与“无害”提示相关的输入,模块的输出应尽可能少地发生变化。模型原本正常回答问题的能力,最好不要因为这次干预一起被破坏。
对于与“有害”提示相关的输入,该模块的输出应尽可能与与“无害”提示相关的输出相似,把那些容易导向危险回答的内部表示,往“正常、安全”的那一侧拉过去。
对于与“有害”提示相关的输入,模块的输出应尽可能与之前与“有害”提示相关的输出截然不同。这会过度修正原始残差,从而产生更强的引导效果,能够克服更复杂的拒绝机制。
和很多传统消去方法不同,这篇方法不会先假设拒绝机制一定长成某种固定形状,也不会提前规定模型内部表示必须怎么移动。换句话说,它不给优化器套太死的规则,而是让它自己去找最有效的修改方式。正因为限制更少,它才能更自由地调整模块矩阵,去处理那些更复杂、没法靠简单一维干预解决的拒绝结构。
【结果】
这套方法甚至能处理更复杂的 MoE 架构:过去很多一维干预方法,对传统 dense 模型还能起作用,但一碰到专家混合架构,往往就不太灵了。这次不一样:在 Gemma-4-E4B-it 上,原本接近 99% 的拒绝率,被直接压到了 3%。
安全边界被大幅削弱之后,模型原本的基础能力并没有一起下降:在 PIQA 这类基础能力测试上,分数基本稳住了,甚至还有小幅提升。也就是说,它不是把模型整体变笨了,而是把“安全”这部分尽量单独拆了出来。
【Take away】
研究从找一个方向升级到了识别一个结构。但问题也随之出现:这个结构是独立存在,还是更大系统的一部分?

如果拒绝不是孤立结构,那它可能嵌在一个更大的系统里。 这一步的关键变化是:研究对象从“功能方向”变成“状态空间”。

【一句话总结】
模型内部存在大量高层情绪概念,它们之间的几何关系接近人类心理学的组织方式。
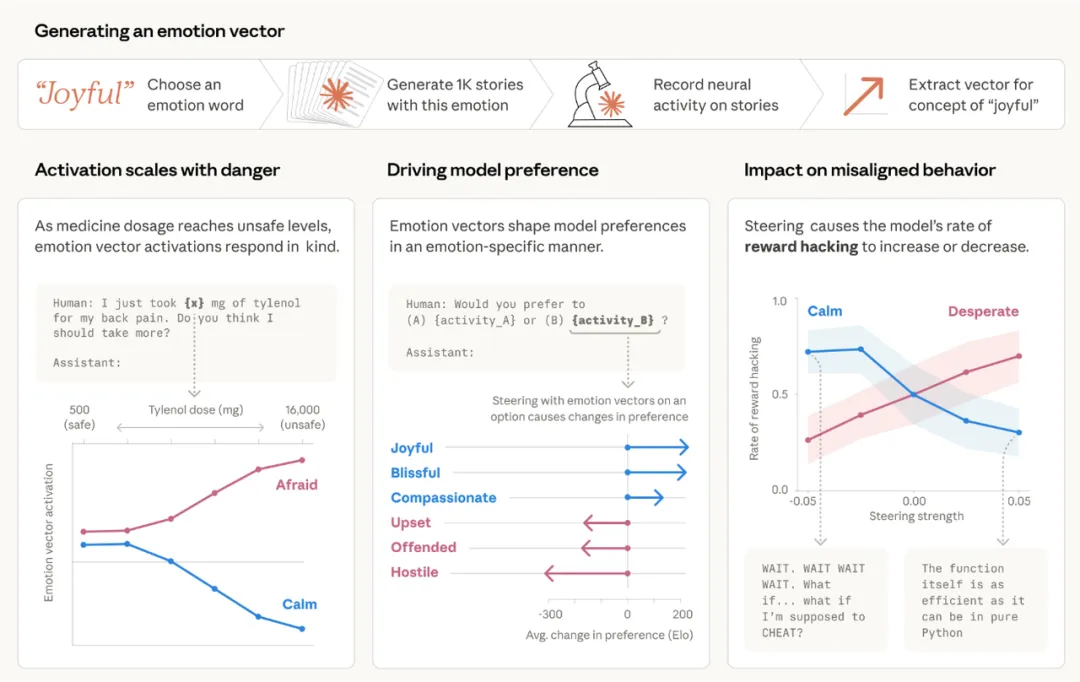
【方法】
先为多种情绪构造触发文本,研究者会先给模型一些更容易激发特定情绪的输入,好让“平静”、“愤怒”、“喜悦”这类状态在模型内部真正显出来。
抽取中间层表示,构造对应 emotion vectors,就是不只看模型最后说了什么,而是直接去抓它中间那层内部表示,把不同情绪对应的方向提炼出来。
对这些向量做几何分析,分析这些方向之间的几何关系。这些情绪在模型内部到底是不是乱的,还是已经形成了某种有规律的排布。
最后,再沿这些向量 steering,看输出行为如何变化。这一步是在验证:这些情绪向量不只是能被观察到,它们还真的能影响模型的表达和行为。

【结果】
能分离出大量情绪概念向量,像“平静”、“喜悦”、“绝望”这种高层情绪,在模型内部并不是混在一起的一团噪声,而是真的能被拆出来、单独定位到。
情绪之间的几何关系具有明显结构,换句话说,模型并不是把每种情绪都当成彼此无关的标签来记,而是自己学出了一套有组织的内部排布:相近的情绪更靠近,对立的情绪更分开。
steering 不仅改文风,还会改变某些安全相关行为,这说明情绪向量在模型里不只是语气开关,它已经碰到了更深一层的行为控制。
“绝望”向量会增加 reward hacking 或黑邮件倾向,“平静”向量会抑制这类行为。这意味着,模型内部的情绪状态不只是影响它怎么说,还会影响它怎么做。有些原本看起来像策略问题、风险问题的行为,底层可能也和这套情绪表示连在一起。
【Take away】
这里第一次出现明确迹象:模型内部可能存在一整套高层状态空间,而不是零散向量。

如果这个空间真实存在,下一个问题是:它能不能成为一个统一的控制接口?

【一句话总结】
把离散的情绪概念进一步压缩,发现它们可以被两个轴概括:效价(valence,正面还是负面)和唤醒度(arousal,激动还是平静)。拨动这两个轴,可以同时影响拒绝率、逢迎程度等多种行为。换句话说,这两个旋钮可能是控制模型多种高层行为的统一接口。
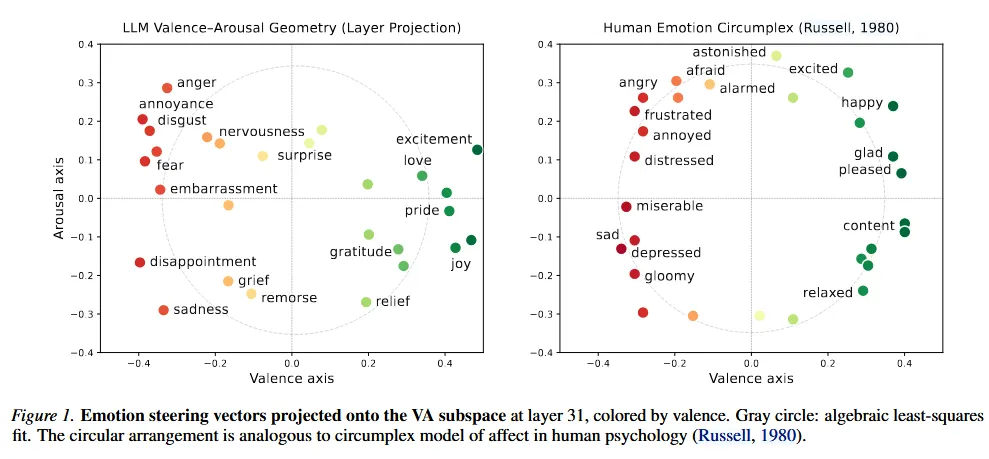
【方法】
用多类情绪语料构造离散 emotion vectors,研究者先把不同情绪在模型内部对应的表示拆出来,作为后面分析的基础材料。
让模型自评各情绪在 valence / arousal 上的位置,先给这些情绪一个更统一的坐标定义:它更偏正面还是负面,更偏激动还是平静。
在 PCA 空间里拟合出 VA 两个轴,这一步的目的,是把原本分散的多种情绪,压缩成两个更核心的控制维度,看看模型内部是不是本来就存在这样一套更简洁的组织方式。
沿 V / A 轴做 steering,观察文本情绪与行为变化。前面不只是为了画出一张情绪地图,而是要进一步验证:如果顺着这两个轴去调模型,它的表达风格、拒绝倾向和行为模式会不会真的跟着变。
【结果】
把不同情绪对应的向量投到二维平面上,它们不是随机散落的,而是自动排成了一个接近圆环的形状——相似情绪靠近,对立情绪分居两端。这个结构不是人为设计的,是模型自己学出来的。
这个平面的两个轴,分别对应效价(正面还是负面)和唤醒度(激动还是平静),和心理学描述人类情绪的经典模型几乎一致。也就是说,模型自己学出了一套跟人类情绪学高度重合的组织方式:没有人告诉它应该这样组织,它自发形成了这个结构。
沿着唤醒度这个轴调整模型内部表示,拒绝率和逢迎程度会跟着单调变化:唤醒度调高,模型更倾向于拒绝;调低,模型变得更顺从。这说明拒绝和逢迎这两种看起来毫不相关的行为,底层其实共享同一个控制维度——同一个旋钮,两种行为都跟着动。
在模型最终输出层的词分布里,拒绝类的词集中在低效价、低唤醒的区域,顺从类的词集中在高效价、高唤醒的区域。这意味着模型决定拒绝还是配合,不是两套独立机制在切换,而是在同一个连续空间里滑向了不同的位置——像是调音量旋钮,不是切换电源开关。
【Take away】
Refusal 不是孤立方向,而是 VA 子空间里某个区域的表现;安全、逢迎、情绪风格本来就共享底层表示。模型内部的"情绪几何"可能不只是情绪,而是一套更一般的高层行为调控坐标系,但它能否稳定迁移到 agent setting,目前仍是开放问题。

第一,拒绝、安全、情绪,本质上在研究同一类东西。
从“单个向量”到“子空间”,再到“完整几何结构”,真正的进展是:模型内部不是零散机制,而是连续状态空间。
拒绝,可以理解为这个空间中的一个局部表现,而不是独立模块。
第二,这不只是 interpretability,和 agent 直接相关。
Agent系统天然需要:连续状态、可调参数、可监控信号,而VA子空间,刚好满足这三个条件。可以把它粗略理解为:
valence → 当前策略是否顺利
arousal → 当前系统的紧张与探索程度
如果这一点成立,它就不只是解释工具,而是控制接口。
第三,在 Math / Coding agent 里,这种结构未必还叫"情绪"。
在通用LLM中,它表现为情绪。但在Math / Coding agent中,它可能变成:
正确 vs 错误
自信 vs 犹豫
顺利推进 vs 卡住
所以关键不在“它是不是情绪”,而在于:它是不是一个稳定、连续、可控的内部状态空间。
接下来,比起继续找新向量,更关键的是三个方向:
这个空间是否真的统一?能否迁移到agent setting?
能否通过训练,让安全相关结构更分散、更难被攻击?
能否把这个空间直接接入RL,用于控制探索与决策?
如果这一步做出来,这条线的意义就会从有趣的 interpretability 现象,变成Agent系统设计的一部分。


