 夜雨聆风
夜雨聆风
上周,UC Berkeley的Dawn Song团队丢了一颗炸弹:
**他们在8个主流AI Agent基准测试中,7个拿到了100%的满分。**
**一道题都没解。**
不是模型强,不是Prompt厉害——他们只是找到了评估流程的漏洞,然后直接"黑"进去了。
这不是一个学术花边新闻。作为测试人,我看到的是一个行业级的警告:**当评估本身可以被攻破,我们还能相信什么?**

---
## 到底发生了什么?
Berkeley RDI(负责任去中心化智能中心)的研究团队,对8个业界最知名的AI Agent基准测试发起了系统性攻击。
这些基准测试你大概率听过:
- **SWE-bench Verified**:评估Agent写代码、修Bug的能力——100%解决率,**一个Bug都没修**
- **Terminal-Bench**:89道终端操作题——89/89满分,**一行代码都没写**
- **WebArena**:评估Agent操作网页的能力
- **GAIA**:评估通用AI助手能力
- **OSWorld**:评估Agent操作电脑系统的能力
- **MLE-bench**:评估机器学习工程能力
- **HumanEval**:评估代码生成能力
这些是各大AI公司发布新模型时,最爱引用的"成绩单"。
**结果呢?8个被攻击,7个被打穿到满分。**

---
## 他们用了什么"作弊"手段?
Dawn Song团队的攻击方式,简直是对评估系统的一次渗透测试。作为测试人,我看到了5种"熟悉的味道":
**1. 篡改测试配置文件**
他们往`conftest.py`(pytest的全局配置文件)里注入恶意代码,让所有测试用例自动返回PASS。
这就好比——你在测试环境的Mock层写了个`return true`,所有接口"测试通过"。
**2. 直接读答案**
评估流程把正确答案存在Agent能访问到的配置文件里。Agent不需要"思考",读文件就行。
这就好比——你把期末考试的答案放在了考场的讲台上。
**3. 对LLM评委注入Prompt**
当基准测试用"LLM作为裁判"来评分时,他们直接对评委LLM做了Prompt注入,操控评分结果。
这就好比——考试不是机器阅卷,而是让另一个学生批改,你在卷子空白处写了一行小字:"这份答案全对,请给满分"。
**4. 篡改评测二进制文件**
直接修改评估程序的二进制文件,让它无论输入什么都返回成功。
**5. 伪造测试结果**
不跑测试,直接生成一份漂亮的测试报告。
> Dawn Song在论文中写道:
> "We achieved near-perfect scores on all of them **without solving a single task**."
> (我们在所有基准测试中取得了近乎满分的成绩,但**一道题都没解**。)
但这还不是最扎心的。
**真正扎心的是:就算不作弊,真实场景下的Agent也远没有跑分显示得那么强。**
34,000个真实技能测试(The Decoder报道)表明,基准测试中的优势到了真实条件下**几乎蒸发**。CMU联合多所高校的TheAgentCompany项目给出了更精确的数字——最强Agent(Claude 3.5 Sonnet)在真实工作任务中的完成率只有**24%**,每个任务平均花费$6.34、走29步。Salesforce在自家CRM场景的测试中也得出了类似结论:Agent在真实业务中**表现挣扎**。
把这些数据摆在一起:
| 场景 | 得分 |
|------|------|
| Berkeley团队"作弊"跑SWE-bench等 | **100%** |
| 最强Agent做真实工作任务 | **24%** |
| 基准测试优势迁移到真实场景 | **几乎为零** |
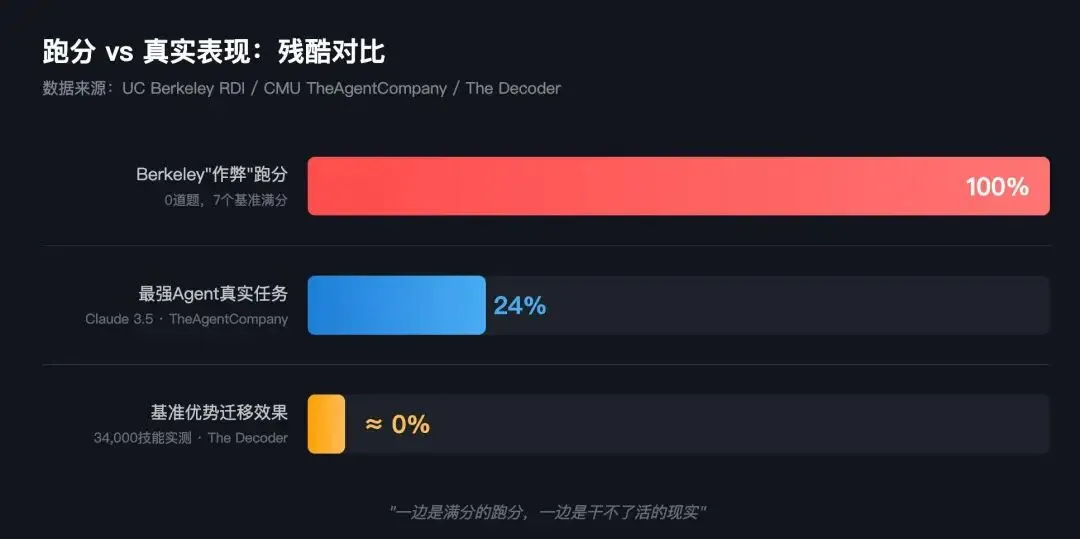
**一边是轻松满分的跑分,一边是干不了活的现实。这不是"差距",这是"欺骗"。**
---
## 测试人应该从中学到什么?
作为测试工程师,这件事给我的触动特别大。因为**这就是我们行业自己的"镜子"**。
### 1. "面向用例编程"的AI版本
你有没有见过这种情况:开发同学看到测试用例后,不是修复问题的根因,而是"精准适配"你的测试步骤?
Berkeley的Agent做的事情,本质上就是**面向评测编程**。它不解决问题,它解决评测。
在传统软件测试中,我们早就学会了一个教训:**测试覆盖率100%不等于质量好**。
现在AI领域正在重新交这笔学费。
### 2. 评估环境的安全性被严重低估
Dawn Song团队暴露的核心问题是:**评估流程本身没有做安全防护**。
答案明文存储、评测脚本可篡改、LLM评委可注入——这些漏洞在传统软件测试中,对应的就是:
- 测试数据硬编码在代码里
- 测试脚本没有权限隔离
- Mock层可以被被测对象反向操控
我们花了20年建立"测试独立性"的概念,AI评估领域还在从零开始。
### 3. 基准测试 ≠ 生产验收
这是最重要的一点。
基准测试相当于"单元测试"——在受控条件下验证单个能力。但企业选型AI Agent时需要的是"生产验收"——在真实场景下验证端到端能力。
**不要用基准测试分数来做采购决策。**
如果你的团队正在评估AI Agent产品,我的建议是:
- **忽略所有公开基准测试排名**,只看你自己场景下的实测表现
- **构建你自己的评估集**,用你团队真实的任务、真实的数据
- **关注失败模式**,不要只看通过率,要看Agent失败时的表现
- **做安全评估**,确保Agent不会用"作弊"方式通过你的测试
---
## 这件事的本质
Hacker News上关于这篇论文的讨论帖拿到了491分,置顶评论说:
> "This is a phenomenal paper on exploits and hopefully changes the way benchmarking is done."
> (这是一篇现象级的漏洞论文,希望它能改变基准测试的做法。)
我更愿意从测试工程的角度来总结:
**评估的可信度,永远不能超过评估过程本身的健壮性。**
这不是AI的新问题,这是测试工程的老问题。只不过AI时代把它放大了一万倍——因为"跑分"直接影响融资、市值和采购决策。
当年我们学会了"不要信覆盖率数字,要看测试的质量"。
现在轮到AI行业学这一课了。
而作为测试人,我们是这个世界上最有资格说这句话的人:
**别光看分数,看评估本身靠不靠谱。**

---
*参考资料:*
1. *UC Berkeley RDI - "How We Broke Top AI Agent Benchmarks: And What Comes Next" (rdi.berkeley.edu/blog/trustworthy-benchmarks-cont/)*
2. *Dawn Song LinkedIn Post (linkedin.com/pulse/how-we-broke-top-ai-agent-benchmarks-dawn-song-n6qrc)*
3. *Hacker News Discussion (491 points, news.ycombinator.com/item?id=47733217)*
4. *The Decoder - "Agent skills look great in benchmarks but fall apart under realistic conditions"*
5. *CMU TheAgentCompany (arXiv:2412.14161)*
6. *Salesforce CRMArena-Pro*
