之前没想把这种无聊的东西写成一个系列,只想专注于CNS的数据分析。不过前天晚上看到Karpathy的llm-wiki的思路(https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f),觉得很适合创建知识库正好也可以开始第一次使用rust来写简单的脚本。
1. LLM(也就是你们目前认知的AI)非常愚蠢,它只是下一代的搜索引擎,远远称不上智能。即使是目前综合性能和推理能力最强的Gemini3.1pro,它的回答正确率经由我个人的体感测试也只有差不多60%。所以,不要依赖AI,使用AI前首先确保你知道答案大致是什么,并且反复验证答案。2. 如果不是基础扎实的programmer,不要使用CLI或Agent等方式的vibe coding,迎接你的只有失败无限轮回。使用chat的方式询问代码,并且反复询问和验证代码,让LLM用你能懂的语言解释每一句代码。这样做既可以让你学习如何program,同时也更容易发现冲突和错误。3. 用好prompt,给定正确的role,rule等。正确率会差很多。4. 交叉验证,第一个模型给出的回答永远丢给另一个模型去验证。5. 不要用中国产的模型。排除个人主观喜恶,中国产模型用蒸馏的方式产出自己的模型,个中参数会有许多导致结果失真的注入,同时会加入价值观判断等。Huggingface上有许多大神调教和量化的模型可以使用。6. vibe coding和programing是两回事,永远不要以为是自己掌握了编写程序。如果你离开了LLM就什么都做不到,那你就是个依赖LLM的废物。vibe coding是不同于programing的另一种技能,主要是关于如何写最有效率的prompt,同时也能最简单轻松的学会programing。programmer使用vibe coding只是为了增加开发效率而已。7. 不要vibe coding一些愚蠢的小工具,世界上已经有几百万人给他们自己写记账程序了。这并不会让你的life get easier。8. 你可以不懂编程语言,但是至少要有良好的逻辑自洽能力以及基础的程序知识,至少能知道流程图怎么写。9. 突然忘记了,年纪大了就是这点不好……想到了再说……
什么是llm-wiki就不介绍了,自己看上面github的文章。 由于本来就在课堂上用obsidian写笔记,于是就抱着零成本的心态靠gemini写了个rust文件来建立自己的llm-wiki。
这里所需要的工具一共用到了rust,gemini网页版本(普通和pro交替用),llama.cpp(自己编译的版本,开启了AVX-512,本地运行gemma-4-e4b),obsidian四个。 硬件环境是运行cachyos的8845hs笔记本,毕竟只是个8b的模型,AVX-512的11t/s的速度足够了,没必要浪费电。cachyos的更新很激进非常适合玩新东西。可惜rdna3的780m没办法用rocm,内存交换的时候llama.cpp一直报错,想更进一步提高效率可惜lemonade只支持xdna2不支持xdna1。 以上都不是必备的,用obsidian主要是我一直在用,而且它编辑和操作markdown文件十分直接。
- Raw:这是你个人收集的所有资料来源的位置,确保你的LLM只能读取它而不会修改它。- Schema:这里存放所有分门别类的prompt,命名需要注意些,不然调用起来会比较累。- Wiki:这里存放的是llm根据你的prompt输出的结果,我喜欢一个md源文件对应一个md的wiki文件。优点是方便自己整理和查找,缺点是以后通过llm调用的时候上下文会变比较大。 这部分很简单,除了要注意prompt的命名规则和文件分类外,没有太多需要说的。 然后就是创建rust项目(你也可以用python,go等等,不过同样是从零开始,为什么不选性能最好的rust呢?)// 用sha256计算raw里的每一个文件,实现增量同步做准备use sha2::{Sha256, Digest}; // 处理路径拼接、创建目录以及读取/写入文件内容。use std::{fs, path::Path};// 扫描所有文件夹及所有子目录use walkdir::WalkDir;// 用来写jsonuse serde_json::json;// http客户端,把json通过post发送给本地apiuse reqwest::Client;// 图像编码解码use image::ImageFormat;// 在内存中压缩处理图片use std::io::{self, Cursor, Write};// 调用时间,配合sleepuse std::time::Duration;// 在键盘监听线程和主异步流程之间传递消息use tokio::sync::mpsc;// 异步运行use tokio::time::sleep;// base64编码解码use base64::{prelude::BASE64_STANDARD, Engine};// 写正则表达式use regex::Regex;
[dependencies]hex = "0.4.3"reqwest = { version = "0.13.2", features = ["json"] }serde = { version = "1.0.228", features = ["derive"] }serde_json = "1.0.149"sha2 = "0.11.0"tokio = { version = "1.52.0", features = ["full"] }walkdir = "2.5.0"image = "0.25"base64 = "0.22"regex = "1.12.3"
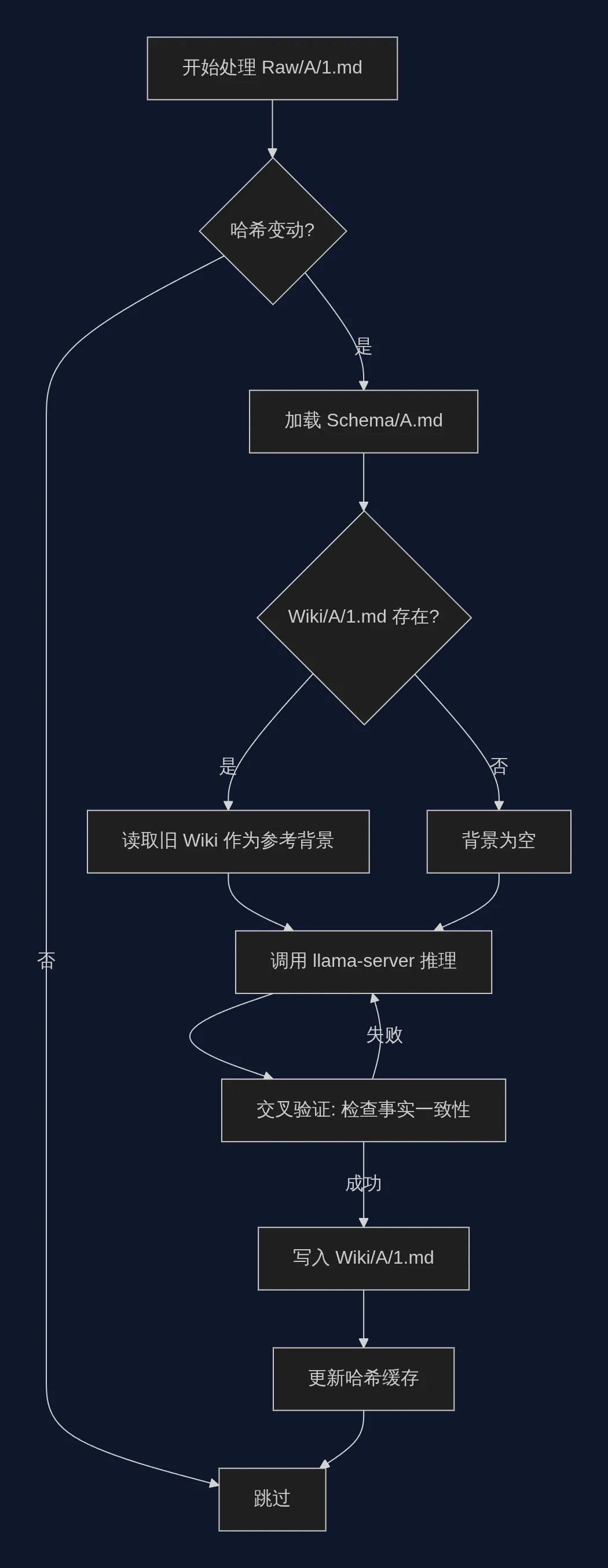
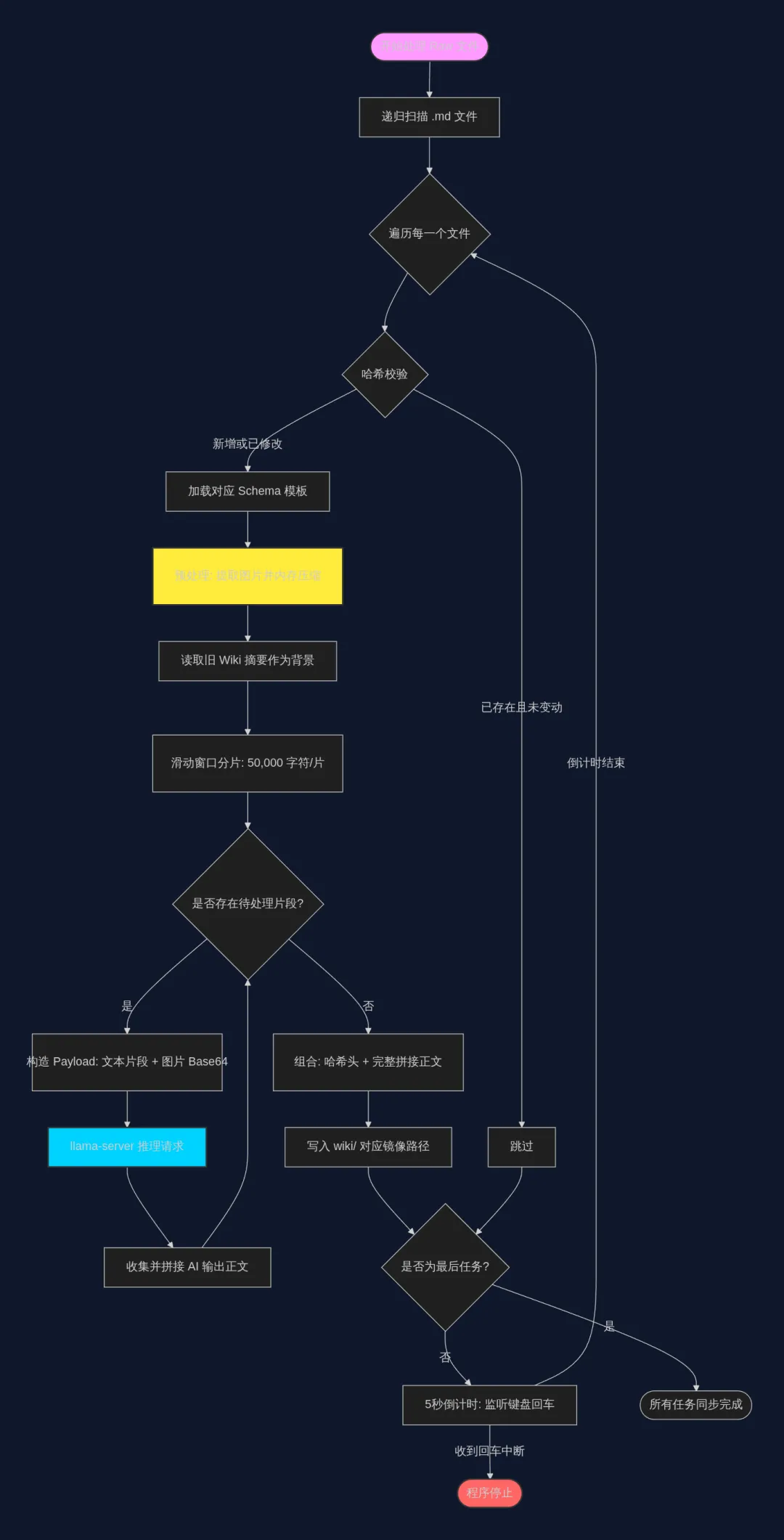
至于为什么用这些dependencies?我只是给了gemini详细的功能解释和大致的逻辑示意图,它告诉我需要这些dependencies来实现而已。也许会有更好的工具,不过那是之后优化的工作了。 之后我随便从wikipedia上找了两篇wiki文章丢入一个文件夹进行测试,结果发现只输出了一篇wiki.md。于是回头查看llama.cpp的日志发现其中一篇的字数过多超出了我设置的32k上下文,导致中断。考虑到测试阶段,没有增加上下文容量,而是选择对源文件进行切片。根据设定的字节数(1 token约等于4字节)来对文章切片,而且我担心会丢失上下文导致输出错误,又加入了窗口滑动来防止语境断裂。 再次测试,发现课堂笔记里有太多的图片,这些图片会导致token数暴增,又因为我使用的是gguf,没有下载多模态组件。于是我加入了对图片进行格式转换和压缩(png to jpg),在保证可读性的情况下压缩图片容量。虽然对于生成速度没有帮助,但是对于上下文以及预处理时间非常有帮助。 同时也突然想起来没有设置任何中断机制,因此增加了每次生成完倒计时5秒,如果5秒内输入换行符(回车)就中断操作的机制。 为了防止日后上下文太多而爆炸,增加了给已经生成的wiki写入摘要(方便llm使用)和哈希码(方便llm查询)的功能(哈希码是gemini推荐的)。 至此,大致功能就都已经实现,当有新的文件输入时,llm会通过更新和比对来进行增减,同时它能自我更新知识,并且应该不会有长上下文失忆的问题。 接下来就是如何lint这些wiki文件,以及如何优化和自动化的更彻底。或者等想到什么新功能了再加进去。
 夜雨聆风
夜雨聆风