 夜雨聆风
夜雨聆风PocketPal AI让你的手机
也能运行大模型
PocketPal AI
PocketPal AI 是一款口袋大小的 AI 助手,它由直接运行在手机上的小型语言模型 (SLM) 提供支持。PocketPal AI 同时支持 iOS 和 Android 系统,让您无需网络连接即可与各种 SLM 进行交互。您的隐私得到全面保护,所有处理都在您的设备上完成——您的对话、提示和数据绝不会离开您的手机或存储在外部服务器上。

特征

离线AI辅助:无需网络连接即可直接在设备上运行语言模型。
模型灵活性:下载和切换多个 SLM,包括 Danube 2 和 3、Phi、Gemma 2 和 Qwen。
自动卸载/加载:当应用程序在后台运行时,通过卸载模型自动管理内存。
推理设置:自定义模型参数,例如系统提示、温度、BOS 令牌和聊天模板。
实时性能指标:查看 AI 响应生成期间每秒令牌数和每个令牌的毫秒数。
消息编辑:编辑您的消息并重试 AI 生成。
个性化伙伴:通过自定义设置创建不同的AI个性。
后台下载:在使用其他应用程序时继续下载模型(iOS)。
推理期间保持屏幕常亮:在 AI 生成响应时,请保持屏幕常亮。
多设备支持:针对手机、平板电脑(包括 iPad)进行了优化。
本地化:使用您喜欢的语言运行应用程序。
Hugging Face 集成:通过身份验证访问公共模型和受限模型。
项目地址:
https://github.com/a-ghorbani/pocketpal-ai

下载模型【需要特殊网络】

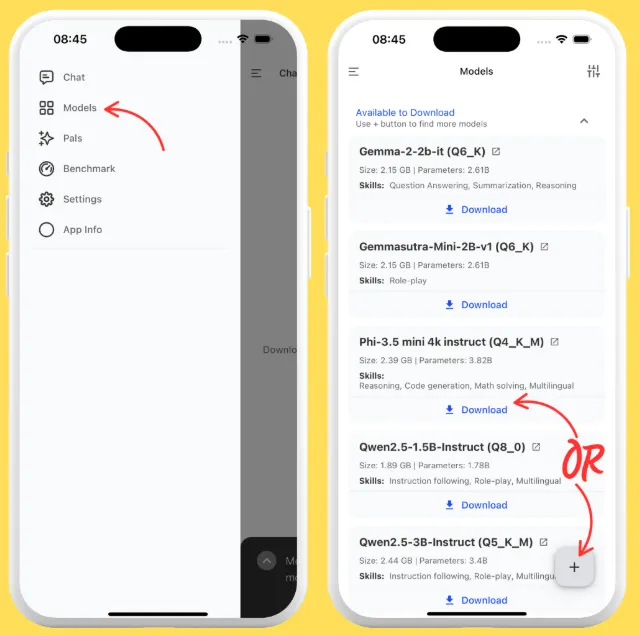
1、打开应用程序,然后点击菜单图标(☰)。
2、导航至“模型”页面。
3、从列表中选择一个模型,然后点击“下载”。
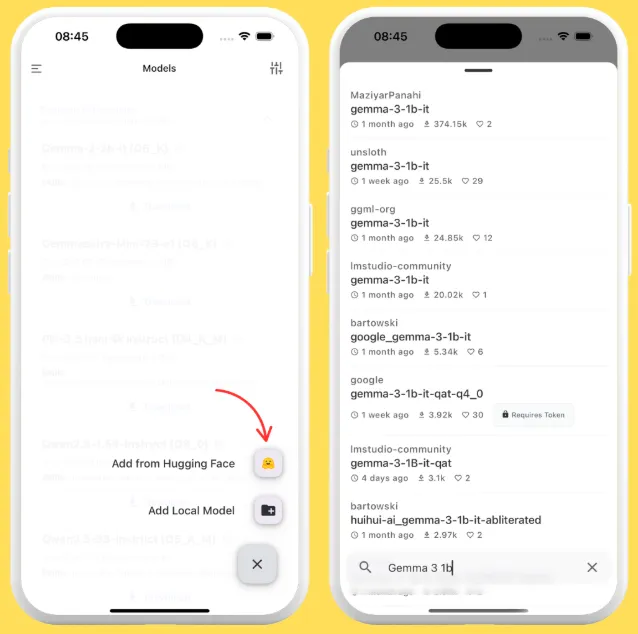
4、或者点击“+”按钮,从 Hugging Face 添加模型或从本地下载的模型。
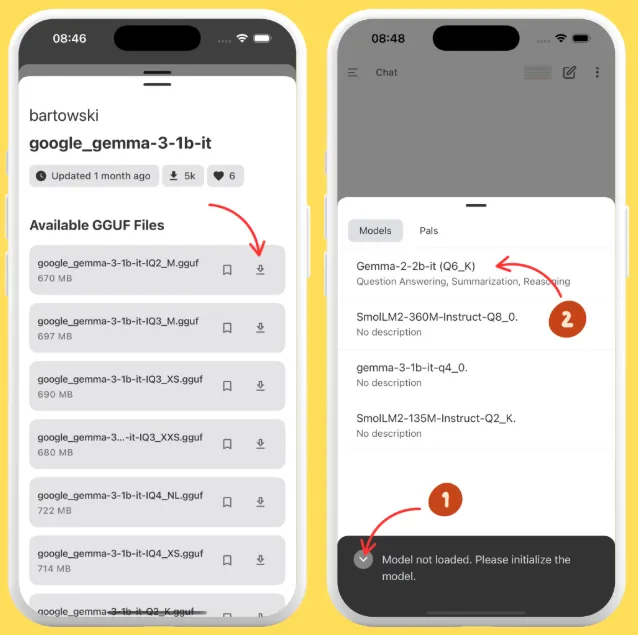
5、如果您选择“从 Hugging Face 添加”,您可以直接在 HF 上搜索 GGUF 模型,并选择适合您设备(内存和存储)的任何量化。
6、您可以立即下载,也可以将其添加到书签以便稍后下载。

无特殊网络模型下载
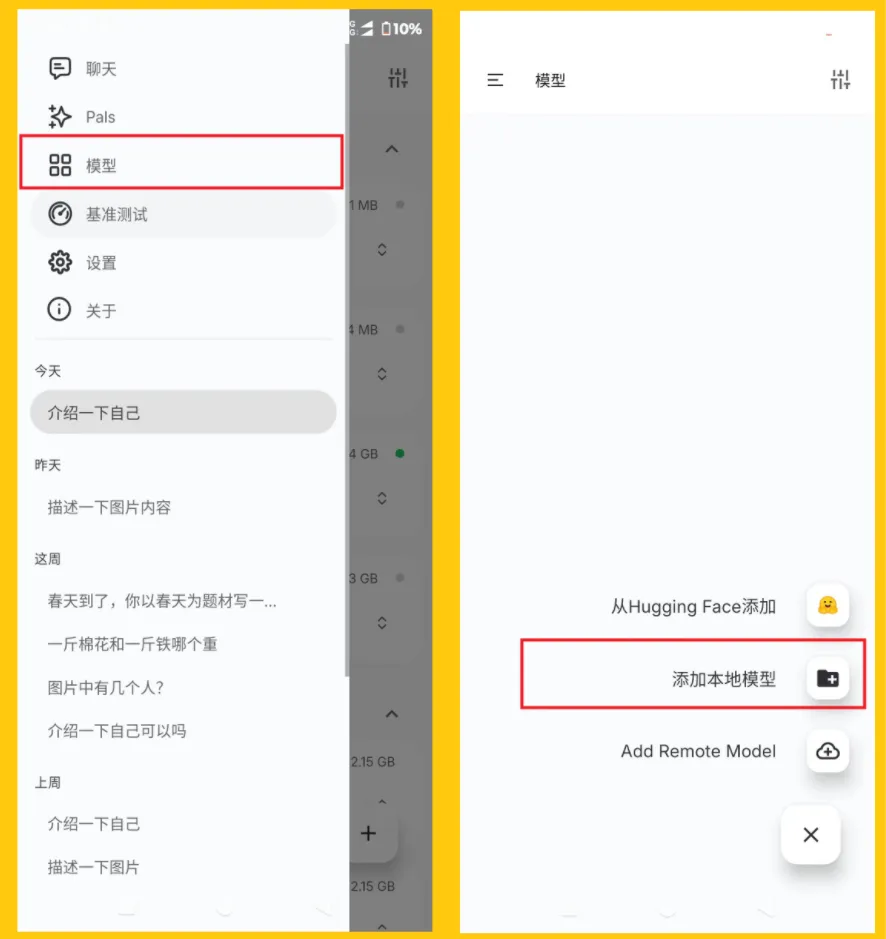
如果你没有特殊网络,可以点击左上角菜单图标,选择“模型”,打开“模型界面”,点击右下角的“+”号,选择“添加本地模型”,载入你手机里的模型文件【模型文件看下载链接】。
↓

手机专用的模型文件为GGUF文件,最新手机晓龙8gen1以上CPU,12G以上内存,运行4G以下模型文件无压力。手机CPU支持AI算法的速度更快。不建议使用视觉模型,毕竟手机性能在哪儿。
PocketPal应用下载
https://github.com/a-ghorbani/pocketpal-ai/releases
https://yun.139.com/shareweb/#/w/i/2ur4jqng6ycpq
提取码:w9ky
https://wwbmk.lanzoue.com/ivph23nan9hg
推荐模型下载
实测验证模型【逐步更新】
https://pan.baidu.com/s/12i7X94xl4aCufSVJ3HA5qQ?pwd=ps9g
提取码: ps9g
无审查Qwen3.5模型【请合法使用】
https://hf-mirror.com/mradermacher/Huihui-Qwen3.5-4B-abliterated-GGUF/tree/main
60000多GGUF模型下载地址
https://hf-mirror.com/mradermacher/models
知识窗
关于模型名称字母含义
模型的量化版本文件,后缀里的字母是量化格式的标识,不同标识对应不同的量化精度和适用场景:
Q:是量化(Quantization)的缩写,代表该模型经过了量化处理,通过降低模型参数的精度来压缩体积、提升推理速度,同时尽量维持模型性能。
K:代表使用了KvCache(Key-Value Cache)优化技术,这是大语言模型推理时的常用优化手段,能缓存注意力机制里的Key和Value向量,减少重复计算,大幅提升长文本生成的效率。
S:代表Small(小)量化精度,模型体积更小、推理速度更快,但性能会有一定损失,适合对资源要求极高的轻量化场景,比如移动端部署、低配置服务器运行。
M:代表Medium(中等)量化精度,这类版本在压缩体积和保留模型性能之间做了平衡,适合大多数常规推理场景,比如日常对话、文本生成等。
L:代表Large(大)量化精度,相比M、S版本,它保留了更多模型细节,性能更接近原始模型,适合对输出质量要求较高的场景,比如专业文本创作、复杂逻辑推理等。
IQ4_XS:是特殊的4位量化格式,属于极致轻量化方案,模型体积极小,适合在超低配置设备上运行,但性能损失相对明显。
这些不同后缀的版本,主要是为了适配不同的硬件环境和使用需求,你可以根据自己的设备算力、对模型性能的要求来选择合适的版本。
Q2、Q3、Q4……这些数字代表的是量化位数,也就是模型参数所使用的比特数,是量化精度的核心标识:
Q2:表示2位量化,是极致轻量化的方案,模型体积极小,对硬件资源要求极低,但参数精度损失大,模型性能会受到明显影响,适合在超低配置设备(如老旧手机、极低配嵌入式设备)上运行。
Q3:表示3位量化,在体积压缩和性能保留之间做了折中,比Q2版本性能稍好,同时依然保持较小的模型体积,适合中低配设备的轻量推理场景。
Q4:表示4位量化,是目前比较主流的量化精度,在压缩体积和保留模型性能间达到了较好的平衡,多数常规设备都能流畅运行,兼顾了效率和输出质量。
Q5:表示5位量化,模型保留了更多原始参数信息,性能更接近原始模型,适合对输出质量有一定要求,同时设备算力中等的场景。
Q6:表示6位量化,进一步提升了参数精度,模型性能更优,仅在参数精度上略逊于原始模型,适合对推理效果要求较高,且设备算力较好的场景。
简单来说,数字越大,代表量化精度越高,模型体积越大、对硬件要求越高,同时性能也越接近原始模型;数字越小则越轻量化,适配低配设备,但性能损失越多。你可以根据自己的设备算力和对模型输出质量的需求来选择对应的版本。
你学费了吗?
