 夜雨聆风
夜雨聆风
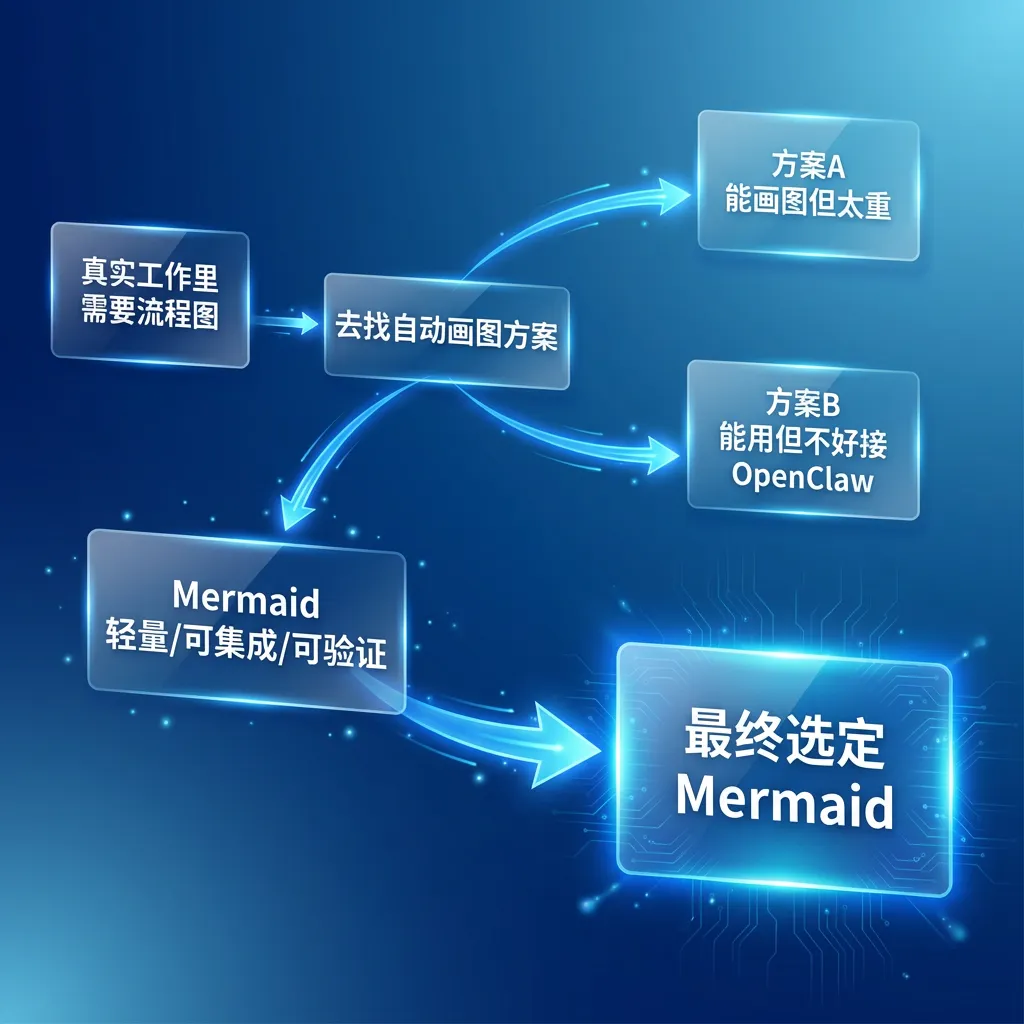
导读:很多 skill 不是“规划出来的”,而是在真实工作里被逼出来的。今天这篇,我想讲一个很典型的案例:一次团队讨论里,我脑子里突然冒出“这里应该有张流程图”,接着去 ChatGPT 网页端找轻量方案,最后把 Mermaid 真正落成了 OpenClaw 里的一个可复用 skill。
很多 skill 的起点,不是在技术,而是在工作现场
今天这件事的起点,其实不是“我要做一个 Mermaid 技能”。
真正的起点,是我在和团队小伙伴讨论一个具体工作时,反复讲到:
- 这个过程怎么走
- 哪几个关键节点最重要
- 哪一步在前,哪一步在后
- 哪些环节之间存在依赖关系
聊着聊着,一个感觉越来越强:
这个东西,光靠文字已经不够了,应该有一张流程图。
我觉得这类瞬间很重要。
因为很多能力的诞生,不是来自工具清单,不是来自“今天想做个新 skill”,而是来自一个很真实的工作判断:
当文字开始吃力时,结构就应该被看见。

下一步不是马上动手,而是先找一条足够轻的路
会后我没有立刻在 OpenClaw 里开干,也没有一上来就想“造一个图形系统”。
我先做了一件很务实的事:
去 ChatGPT 网页端问:有没有能自动画流程图的工具,而且最好能集成到 OpenClaw,不能太重。
这里面其实有三个筛选条件。
第一,要能自动画流程图
不是我要自己手工拖节点,而是最好可以让 AI 根据文字描述或结构描述直接产出流程图。
第二,要能接进 OpenClaw
也就是说,它不能只是一个独立网站工具,而是要有机会进入我现有的 AI 工作流。
第三,不能太重
这点特别关键。
很多工具看起来很强,但一旦落到真实工作里,问题就来了:
- 依赖太重
- GUI 太重
- 集成成本高
- 和现有链路不顺
这类工具短期可能好玩,长期未必适合进入自己的工作系统。
所以我找的不是“最炫的”,而是:
足够轻、足够稳、足够容易接进现有链路。
ChatGPT 推荐了几条路,最后为什么落到 Mermaid?
ChatGPT 确实推荐了几种符合条件的工具。
但最后真正留下来的,是 Mermaid。
原因很简单,Mermaid 几乎正好卡在一个特别舒服的位置:
- 它是文本定义图,天然适合 AI 生成
- 它很轻,不是一个庞大的图形系统
- 它有现成 CLI,可以本地执行
- PNG、SVG 都能直接出
- 特别适合“先把结构画对”这类需求
换句话说,Mermaid 不是那种特别强调视觉设计感的工具,
但它特别适合做一件事:
把流程结构快速、稳定、低摩擦地画出来。
对我来说,这已经非常够用了。
ChatGPT 给出的那段建议,其实已经把最短路径点出来了
当时 ChatGPT 给出的建议非常直接,核心就是:
使用 Mermaid 方式
最简单的推荐路径: 用 CLI(命令行工具)
安装:
npm install -g @mermaid-js/mermaid-cli使用:
mmdc -i input.mmd -o output.png只需要写一个 `.mmd` 文件,比如:
graph TD
A[开始] --> B[结束]然后就能直接生成图片(PNG / SVG)。
这段话看起来很短,但其实已经把路点得很清楚了:
- 工具明确了:`@mermaid-js/mermaid-cli`
- 输入格式明确了:`.mmd`
- 输出格式明确了:PNG / SVG
- 最小验证路径明确了:先跑一个最简单流程图
很多时候,一个能力能不能快速落地,不是因为想法有多大,
而是因为有没有这样一条:
足够短、足够明确、足够容易验证的路径。
而 Mermaid 正好就有。
我把这段贴给 OpenClaw,后面的事才真正开始有价值
接下来我的动作很简单:
把 ChatGPT 给出的 Mermaid 可行性步骤,直接贴给 OpenClaw。
但我不是把它当成“答案”,
而是把它当成:
一个足够清楚的实现起点。
这背后其实是一种我越来越喜欢的工作方式:
- 外部模型负责缩短搜索路径
- OpenClaw 负责本地落地、规则收口、能力沉淀
也就是说,前者帮我减少无效探索,
后者负责把“知道怎么做”变成“以后可以反复用”。
从这里开始,事情才真正进入最有价值的部分。
真正重要的,不是装成功,而是把它收成长期能力
如果只是装了一个 npm 包,其实这件事没什么含金量。
真正有价值的是后面这一整串动作。
第一步:先做最小可行验证
先确认本机到底能不能把 Mermaid 跑起来:
- 安装 CLI
- 写最小 `.mmd`
- 跑出 PNG / SVG
这一层的目标不是好看,
而是验证一句话:
这台机器已经具备 Mermaid 结构图生成能力。
第二步:再用真实案例验证,不停在 demo
很多东西最容易停在 `A --> B` 这种 demo 成功。
但 demo 成功,不等于真实工作可用。
所以后面很关键的一步,是把 Mermaid 用到真实案例里,生成真正有业务意义的流程图。
只有这一步跑通,才说明它不是“理论上可用”,
而是“工作里可用”。
第三步:把它正式收成 skill
这是最关键的一步。
因为如果只是“今天会用 Mermaid”,那它仍然只是一次性技巧;
只有当它被收成 skill,它才变成未来可复用的能力。
所以后面做的不是只保存命令,而是把整个能力系统化:
- 有 `SKILL.md`
- 有包装好的脚本
- 有本地说明
- 有输出目录规则
- 有分发安装包
到这一步,Mermaid 就不再只是一个 CLI 工具,
而变成了 OpenClaw 工作流里的一块正式能力模块。

为什么我最后把 Mermaid 的定位定成“结构层”?
这件事我后来想得很清楚。
Mermaid 最大的价值,不是让图“特别美”,
而是让图:
- 结构清楚
- 定义快
- 易改
- 易复用
- 易自动化
所以它最适合扮演的角色,不是海报设计器,
而是:
结构表达层。
也就是说:
- 先用 Mermaid 把结构画对
- 如果后面需要更强的视觉效果,再交给图像生成链路做二次美化
这个定位特别重要。
因为一旦定位清楚,后面就不会拿 Mermaid 去做它不擅长的事,
也不会因为它不够“花”就误判它没价值。
一个 skill 真正落地,还要解决两个现实问题
做到这里,其实还不够。
今天这条线后面又顺手暴露出了两个非常现实的问题。
第一个问题:文件落哪?
一旦 Mermaid 开始真正跑起来,马上就会出现:
- `.mmd` 源文件放哪
- 原始渲染图放哪
- 二次美化图放哪
如果没有目录规则,文件很快就会到处乱飞。
所以这条 Mermaid 线,最后还顺手推动了目录治理。
最终规则被定成:
- `.mmd` 源文件 → `workspace-docs/diagrams/`
- 原始结构图 → `images-out/mermaid/raw/`
- 二次美化图 → `images-out/mermaid/styled/`
第二个问题:默认输出清晰度不够
最开始虽然跑通了,但很快发现默认 PNG 并不够清楚。
这也是一个很典型的问题:
很多工具在“能跑”和“能交付”之间,差的往往就是这一小步。
所以后面又把 Mermaid 的输出质量规则补上了:
- 不再吃默认小尺寸 PNG
- PNG 默认走高清基线
- 同时保留 SVG 作为结构层交付
这样它才真正配得上“长期可用”。
这个案例真正值得写的,不是命令,而是方法
如果只看表面,这个案例像是在讲:
- 找了个工具
- 装了个 CLI
- 做了个 skill
但我觉得它真正值得记录的,是背后的方法。
这个方法大概是这样的:
1)从真实工作触发,而不是为了做 skill 而做 skill
需求不是空想出来的,而是在一次真实讨论里被逼出来的。
2)先找轻量、可接入、可验证的方案
不是追求最强,而是优先找能快速进入现有链路的路线。
3)借助外部模型缩短搜索路径
ChatGPT 不是替代执行,而是帮我快速锁定方向,减少无效探索。
4)把“可行”收成“可复用”
从 npm 包,到脚本,到 skill,到目录规则,到输出质量标准,这一步才是真正的落地。
5)把能力放进长期系统,而不是停在一次性技巧
只有当它进入规则、路径、分发和默认执行层,它才算真正进入工作系统。
最后一句话
今天这个 Mermaid skill 的价值,不只是“会自动画流程图了”。
更重要的是,它让我再次确认一件事:
一个能力真正有价值,不在于它第一次能不能跑通,而在于它能不能被收进长期工作系统。
从团队讨论里冒出“这里应该有张图”,
到 ChatGPT 帮我锁定 Mermaid 这条轻路径,
再到 OpenClaw 把它真正落成一个可复用 skill,
这整条链路其实特别像现在很多 AI 工作方式的真实缩影:
- 想法来自真实场景
- 方案通过外部模型加速搜索
- 落地靠本地工作系统收口
- 最终目标不是“做出来一次”,而是“以后可以反复用”
这,才是我觉得这个案例最有意思的地方。
